Identificar cargas de trabalho do Azure Databricks
O Azure Databricks é uma plataforma abrangente que oferece muitos recursos de processamento de dados. Embora você possa usar o serviço para dar suporte a qualquer carga de trabalho que exija processamento de dados escalável, o Azure Databricks oferece suporte particular aos seguintes tipos de carga de trabalho de dados:
- Ciência e Engenharia de Dados
- Machine Learning
- SQL*
*As cargas de trabalho SQL só estão disponíveis em espaços de trabalho de camada premium.
Ciência e Engenharia de Dados
O Azure Databricks fornece ingestão, processamento e análise baseados no Apache Spark de grandes volumes de dados em um data lakehouse. Engenheiros de dados, cientistas de dados e analistas de dados podem usar blocos de anotações interativos para executar código em Python, Scala, SparkSQL ou outras linguagens para limpar, transformar, agregar e analisar dados.
Machine Learning
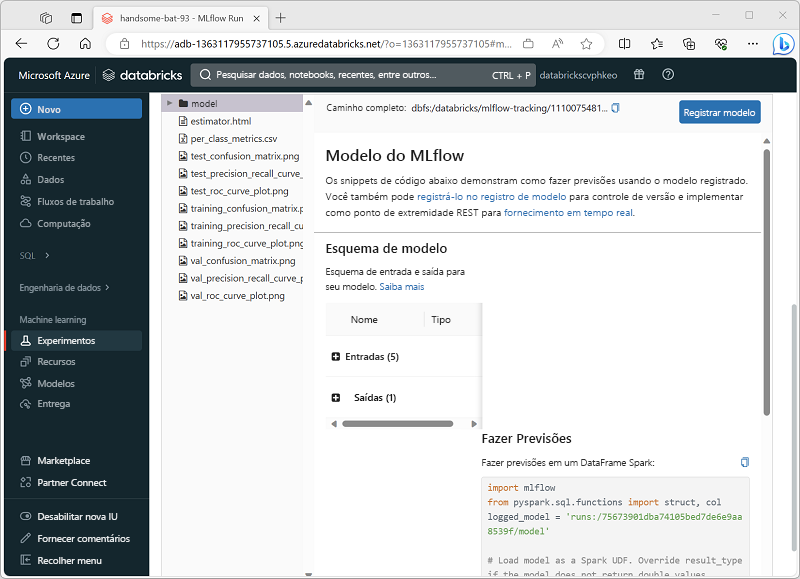
O Azure Databricks dá suporte a cargas de trabalho de aprendizado de máquina que envolvem exploração e preparação de dados, treinamento e avaliação de modelos de aprendizado de máquina e fornecimento de modelos para gerar previsões para aplicativos e análises. Cientistas de dados e engenheiros de ML podem usar o AutoML para treinar rapidamente modelos preditivos ou aplicar suas habilidades com estruturas comuns de aprendizado de máquina, como SparkML, Scikit-Learn, PyTorch e Tensorflow. Eles também podem gerenciar o ciclo de vida de aprendizado de máquina de ponta a ponta com MLFlow.
Armazenamento de dados
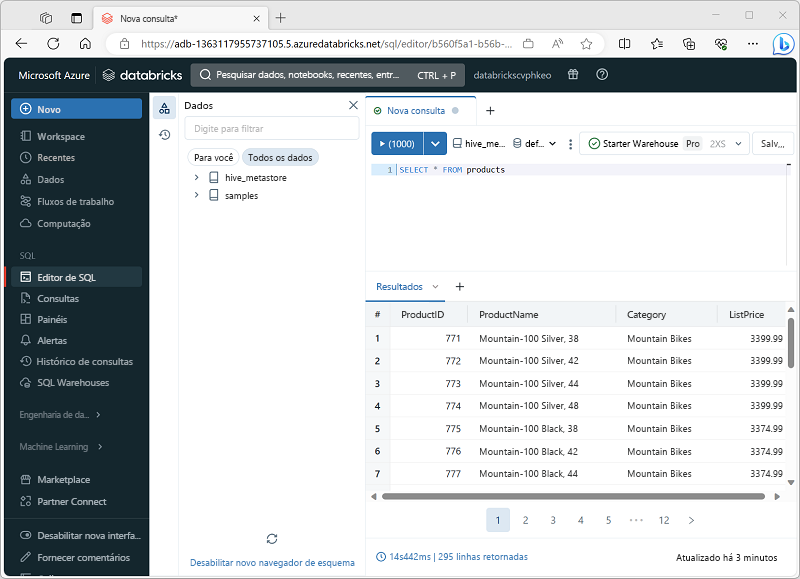
O Azure Databricks dá suporte à consulta baseada em SQL para dados armazenados em tabelas em um SQL Warehouse. Esse recurso permite que os analistas de dados consultem, agreguem, ressumam e visualizem dados usando sintaxe SQL familiar e uma ampla gama de ferramentas de análise e visualização de dados baseadas em SQL.
Nota
Os SQL Warehouses só estão disponíveis em espaços de trabalho premium do Azure Databricks.