Explore o processamento de dados analíticos
O processamento de dados analíticos normalmente usa sistemas de leitura apenas (ou de leitura predominante) que armazenam grandes volumes de dados históricos ou métricas de negócios. As análises podem ser baseadas num instantâneo dos dados num determinado momento ou numa série de instantâneos.
Os detalhes específicos de um sistema de processamento analítico podem variar entre soluções, mas uma arquitetura comum para análise em escala empresarial tem esta aparência:
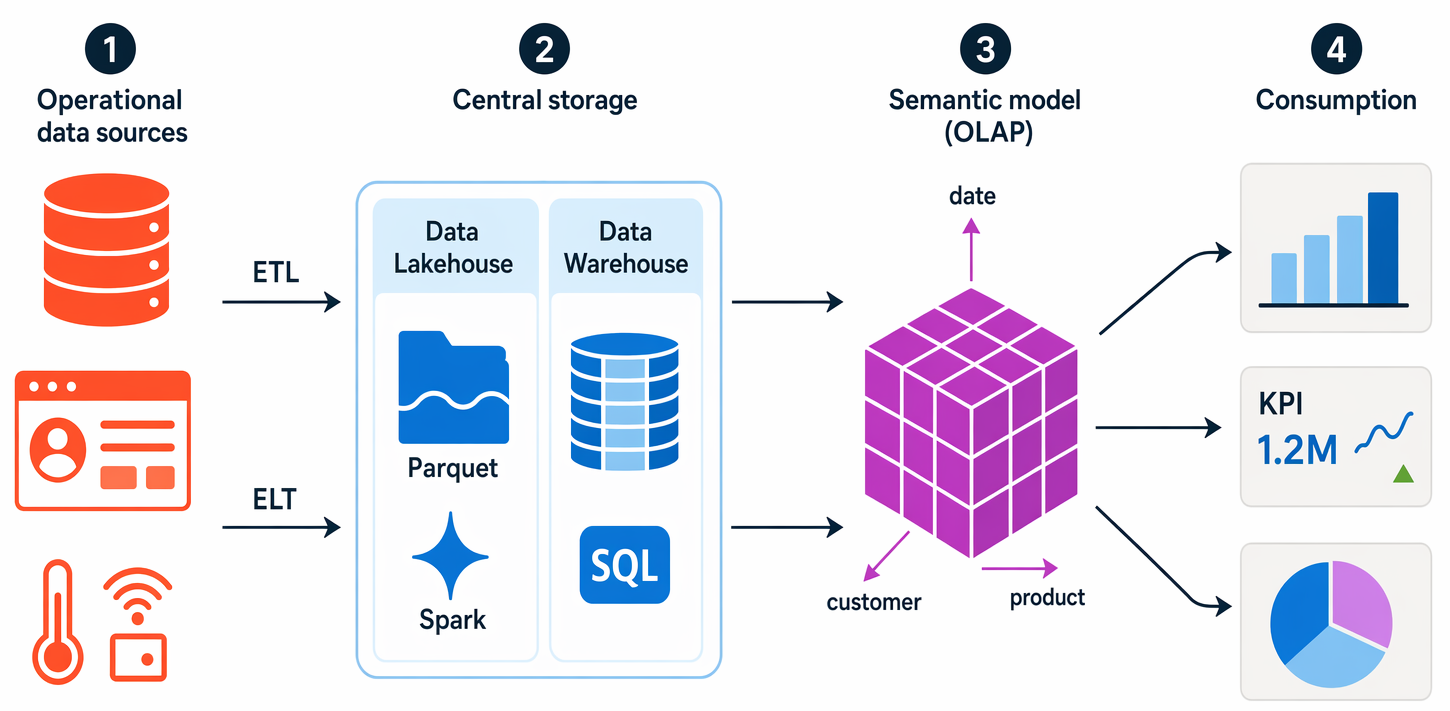
Os dados operacionais são extraídos, transformados e carregados (ETL) num lago de dados para análise — ou extraídos e carregados primeiro com transformações aplicadas depois, um padrão chamado ELT comum nas casas de lago modernas.
Os dados são carregados num esquema de tabelas – tipicamente num data lakehouse com abstrações tabulares sobre ficheiros no data lake, ou num data warehouse com um motor SQL totalmente relacional.
Os dados no armazém de dados podem ser agregados e carregados num modelo de processamento analítico em linha (OLAP) — hoje mais comummente designado por modelo semântico (e, historicamente, um cubo). Os valores numéricos agregados (medidas) das tabelas de fatos são calculados para interseções de dimensões a partir de tabelas de dimensões. Por exemplo, a receita de vendas pode ser totalizada por data, cliente e produto. Os modelos semânticos do Power BI são o exemplo mais comum que vais encontrar.
Os dados no data lake, data warehouse e modelo analítico podem ser consultados para produzir relatórios, visualizações e painéis.
Os data lakes são comuns em cenários de processamento analítico de dados em grande escala, onde um grande volume de dados em formato de ficheiro devem ser recolhidos e analisados.
Os armazéns de dados são uma forma estabelecida de armazenar dados num esquema relacional otimizado para operações de leitura – principalmente consultas para suportar relatórios e visualização de dados.
Os Data Lakehouses são uma inovação mais recente que combina o armazenamento flexível e escalável de um data lake com a semântica de consulta relacional de um data warehouse. O esquema de tabela pode exigir alguma desnormalização de dados em uma fonte de dados OLTP (introduzindo alguma duplicação para tornar as consultas mais rápidas).
Um modelo OLAP (ou modelo semântico) é um tipo agregado de armazenamento de dados otimizado para cargas de trabalho analíticas. As agregações de dados ocorrem entre dimensões em diferentes níveis, permitindo-lhe aprofundar para cima e para baixo para visualizar agregações em múltiplos níveis hierárquicos; por exemplo, para encontrar vendas totais por região, por cidade ou para um endereço individual. Como os dados são pré-agregados, as consultas para devolver os resumos que contêm podem ser executadas rapidamente.
Diferentes tipos de usuários podem realizar trabalho analítico de dados em diferentes estágios da arquitetura geral. Por exemplo:
- Os cientistas de dados podem trabalhar diretamente com arquivos de dados em um data lake para explorar e modelar dados.
- Os analistas de dados podem consultar tabelas diretamente no data warehouse para produzir relatórios e visualizações complexos.
- Os utilizadores empresariais podem consumir dados pré-agregados num modelo analítico sob a forma de relatórios ou dashboards.
Plataformas modernas de análise
O Azure disponibiliza vários serviços geridos que cobrem todo o pipeline de análise — desde a ingestão de dados brutos até relatórios interativos. Duas plataformas "tudo-em-um" reúnem a maioria destas capacidades num único espaço de trabalho. Microsoft Fabric e Azure Databricks são essas duas plataformas; um terceiro serviço, Microsoft Purview, foca-se na governação de dados em todas as suas fontes. Não precisa de conhecer ainda nenhum destes serviços — as descrições seguintes dão-lhe uma ideia geral do que cada um faz.
Microsoft Fabric é uma plataforma unificada de análise de software como serviço (SaaS) que reúne capacidades de armazenamento, engenharia de dados, armazenamento de dados e relatórios num único espaço de trabalho. Azure Databricks é uma plataforma de análise em nuvem construída para engenharia de dados e ciência de dados em grande escala, utilizando Delta Lake—Parquet mais um registo de transações que permite versionamento e transações ACID—como formato padrão de armazenamento. Microsoft Purview fornece segurança, governação e conformidade unificadas dos dados, ajudando-o a descobrir, classificar, proteger e gerir dados em todas as suas fontes de dados.
Diagrama 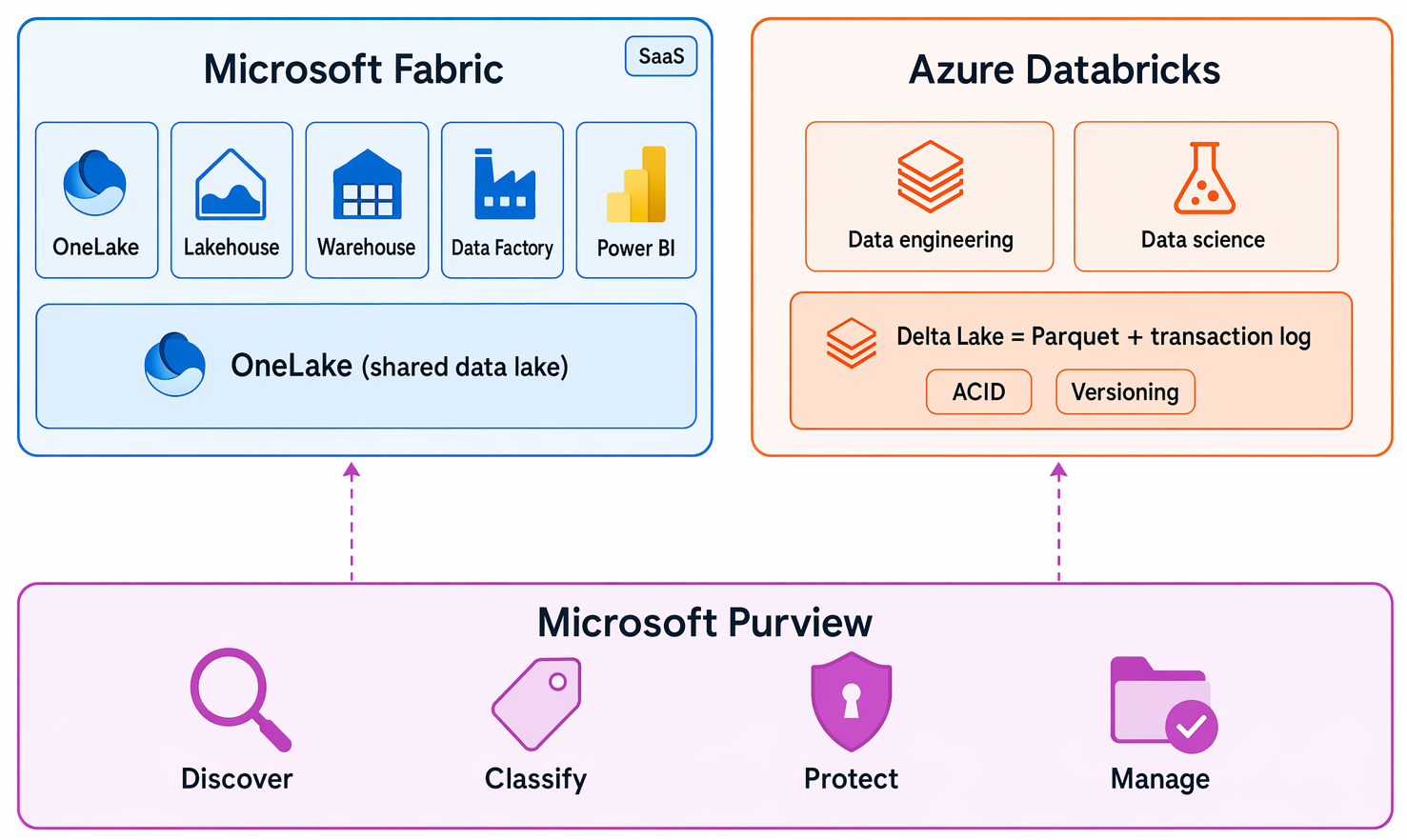
Organização de dados com a arquitetura em medalhão
Um padrão comum para organizar dados numa casa de lago é a arquitetura do medalhão, que utiliza três camadas:
- Bronze: dados brutos ingeridos tal como são dos sistemas de origem, sem transformações aplicadas, preservando os registos originais para reprocessamento.
- Prata: dados limpos e conformados, com duplicados removidos e tipos de dados padronizados.
- Ouro: dados agregados, prontos para negócios, modelados para casos específicos de relatórios e análises.
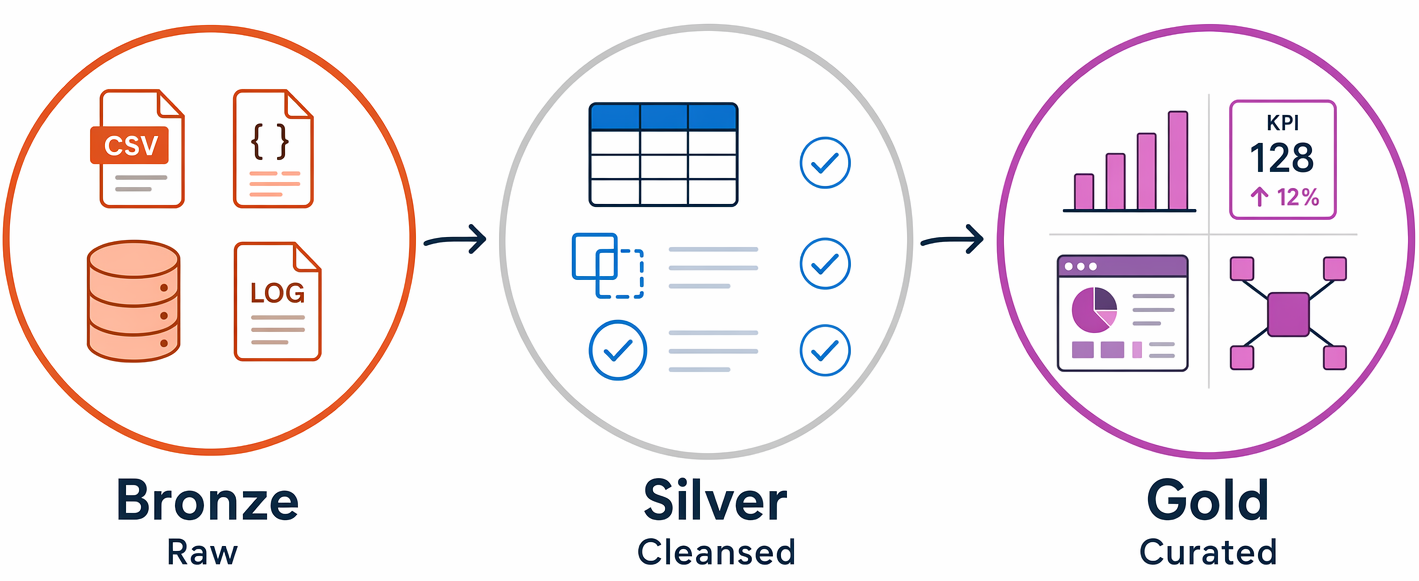
As equipas usam este padrão porque cria limites claros de qualidade em cada camada, e podes sempre reprocessar dados dos registos Bronze originais se os requisitos mudarem.
Tanto o Fabric como o Databricks incluem experiências Copilot que permitem explorar dados usando linguagem natural.