Compreender o processamento em lote e fluxo
O processamento de dados é simplesmente a conversão de dados não processados em informações relevantes através de um processo. Existem duas formas gerais de processar dados:
- Processamento em lote, no qual vários registros de dados são coletados e armazenados antes de serem processados juntos em uma única operação.
- Processamento de fluxo, no qual uma fonte de dados é constantemente monitorada e processada em tempo real à medida que novos eventos de dados ocorrem.
Compreender o processamento em lotes
No processamento em lote, os elementos de dados recém-chegados são recolhidos e armazenados, e todo o grupo é processado em conjunto como um lote. O momento exato em que cada grupo é processado pode ser determinado de várias maneiras. Pode processar dados de acordo com um intervalo de tempo agendado (por exemplo, a cada hora) ou podem ser acionados quando chegar uma determinada quantidade de dados ou como resultado de outro acontecimento.
Por exemplo, suponha que você queira analisar o tráfego rodoviário contando o número de carros em um trecho da estrada. Uma abordagem de processamento em lote para isso exigiria que você coletasse os carros em um estacionamento e, em seguida, os contasse em uma única operação enquanto eles estão em repouso.

Se a estrada estiver movimentada, com um grande número de carros circulando em intervalos frequentes, essa abordagem pode ser impraticável; E note que você não obtém nenhum resultado até ter estacionado um lote de carros e contado.
Um exemplo real de processamento em lote é a forma como as empresas de cartão de crédito lidam com a faturação. O cliente não recebe uma fatura para cada compra individual com o cartão de crédito, mas sim uma fatura mensal de todas as compras do mês.
| Aspect | Vantagens do processamento em lote | Desvantagens do processamento em lote |
|---|---|---|
| Capacidade de Processamento | Grandes volumes de dados podem ser processados de forma eficiente em momentos convenientes. | Todos os dados de entrada devem estar totalmente preparados antes de o processamento poder começar. |
| Utilização do Sistema | Os trabalhos podem ser agendados durante horas ociosas ou fora de pico (como durante a noite), melhorando a utilização dos recursos. | Há frequentemente um atraso entre a introdução dos dados e a receção dos resultados. |
| Fiabilidade e Gestão de Erros | — | Erros nos dados, falhas ou falhas de programa podem parar todo o processo em lote. |
| Validação de Dados | — | Os dados de entrada devem ser cuidadosamente verificados antes de voltar a executar o trabalho em lote. |
| Impacto de Erros Menores | — | Mesmo pequenos erros de dados podem impedir que todo o trabalho em lote corra com sucesso. |
Compreender o processamento de fluxo
No processamento de fluxos, cada novo dado é processado quando chega. Ao contrário do processamento por lote, não há necessidade de esperar até ao próximo intervalo de processamento por lote — os dados são processados em unidades individuais em tempo real , em vez de serem processados por lote de cada vez. O processamento de dados de fluxo é benéfico em cenários em que novos dados dinâmicos são gerados continuamente.
Por exemplo, uma abordagem melhor para o nosso hipotético problema de contagem de carros pode ser aplicar uma abordagem de streaming , contando os carros em tempo real à medida que passam:
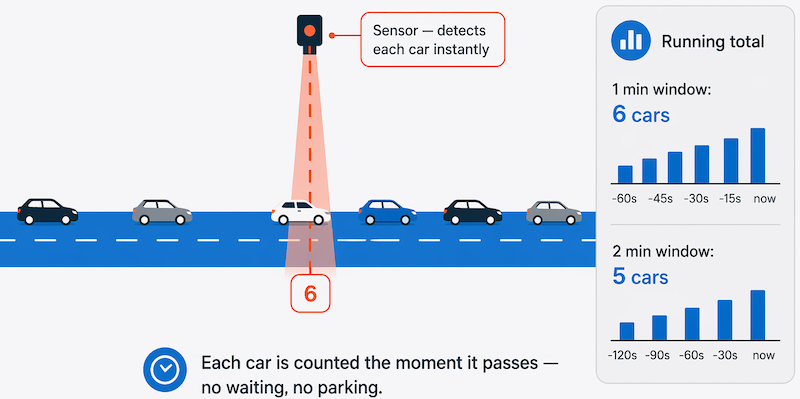
Nessa abordagem, você não precisa esperar até que todos os carros tenham estacionado para começar a processá-los, e você pode agregar os dados em intervalos de tempo; por exemplo, contando o número de carros que passam a cada minuto.
Exemplos reais de streaming de dados incluem:
- Uma instituição financeira que monitoriza as alterações no mercado de ações em tempo real, calcula o valor em risco e reequilibra automaticamente os portefólios com base nos movimentos do preço das ações.
- Uma empresa de jogos online que recolhe dados em tempo real das interações dos jogadores com o jogo e fornece os dados à respetiva plataforma de jogos. Em seguida, analisa os dados em tempo real, oferece incentivos e experiências dinâmicas para cativar os jogadores.
- Um site imobiliário que rastreia um subconjunto de dados de dispositivos móveis e faz recomendações de propriedades em tempo real para visitar com base em sua localização geográfica.
O processamento em fluxo é ideal para operações críticas em tempo que requerem uma resposta instantânea em tempo real. Por exemplo, um sistema que monitoriza fumo e calor num edifício necessita de acionar alarmes e destrancar portas para permitir que os moradores consigam fugir imediatamente em caso de incêndio.
Compreender as diferenças entre dados em lote e em fluxo contínuo
Para além da forma como o processamento em lotes e o processamento de transmissão em fluxo processam dados, existem outras diferenças:
Escopo de dados: o processamento em lote pode processar todos os dados no conjunto de dados. O processamento de fluxo normalmente tem acesso apenas aos dados mais recentes recebidos ou dentro de uma janela de tempo móvel (por exemplo, nos últimos 30 segundos).
Tamanho dos dados: O processamento em lote é adequado para lidar com grandes conjuntos de dados de forma eficiente. O processamento de transmissão em fluxo destina-se a registos individuais ou micro lotes com poucos registos.
Desempenho: Latência é o tempo necessário para que os dados sejam recebidos e processados. a latência do processamento em lotes é normalmente de algumas horas. O processamento de transmissão em fluxo geralmente ocorre no imediato, com uma latência de segundos ou milissegundos.
Análise: Normalmente, você usa o processamento em lote para executar análises complexas. O processamento de transmissão em fluxo é utilizado para funções de resposta mais simples, agregações ou cálculos como médias móveis.
Combinar processamento em lote e por fluxo
Muitas soluções de análise de grande escala incluem uma combinação de processamento em lote e fluxo, permitindo a análise de dados históricos e em tempo real. É comum que as soluções de processamento de fluxo capturem dados em tempo real, processem-nos filtrando-os ou agregando-os e apresentem-nos através de painéis e visualizações em tempo real (por exemplo, mostrando o total de carros que passaram por uma estrada dentro da hora atual), enquanto também persistem os resultados processados em um armazenamento de dados para análise histórica ao lado de dados processados em lote (por exemplo, para permitir a análise dos volumes de tráfego ao longo do último ano).
Mesmo quando não é necessária análise ou visualização em tempo real dos dados, as tecnologias de streaming são frequentemente usadas para capturar dados em tempo real e armazená-los num armazenamento de dados para processamento em lote subsequente (isto equivale a redirecionar todos os carros que circulam por uma estrada para um parque de estacionamento antes de os contar).
O diagrama seguinte mostra uma arquitetura lambda — um padrão comum para combinar processamento em lote e fluxo numa solução de análise de dados em grande escala.
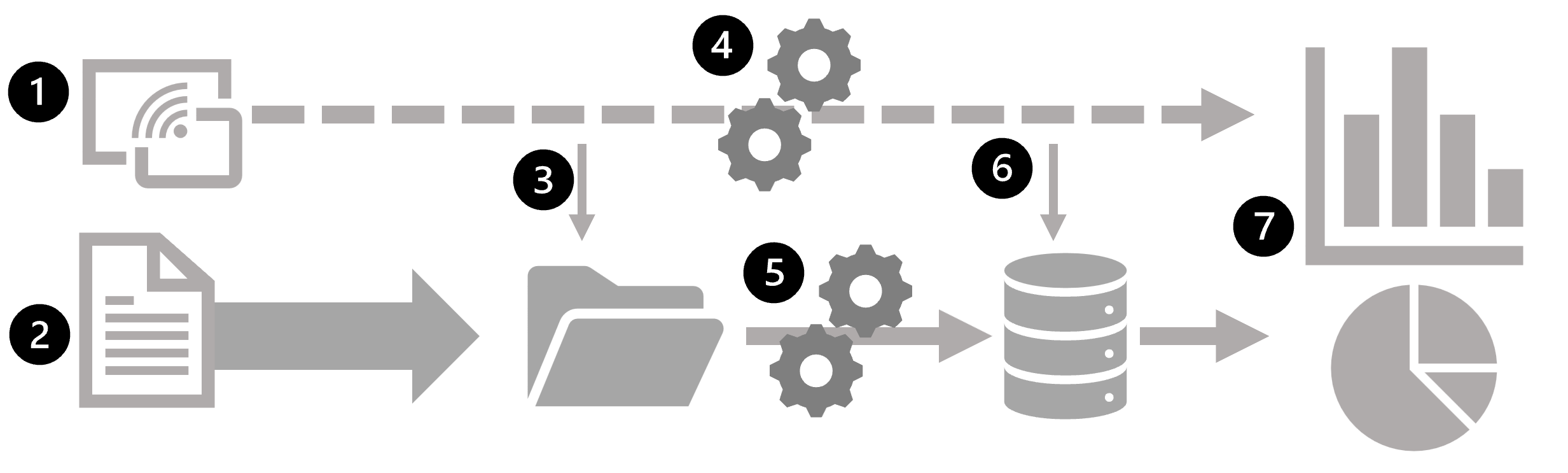
- Os eventos de dados de uma fonte de dados de streaming são capturados em tempo real.
- Os dados de outras fontes são ingeridos em um armazenamento de dados (geralmente um data lake) para processamento em lote.
- Se não for necessária análise em tempo real, os dados capturados em streaming são escritos para o armazenamento de dados para processamento em lote subsequente.
- Quando a análise em tempo real é necessária, uma tecnologia de processamento de fluxo é usada para preparar os dados de streaming para análise ou visualização em tempo real; muitas vezes filtrando ou agregando os dados em janelas temporais.
- Os dados não transmitidos são periodicamente processados em lote para os preparar para análise, e os resultados são mantidos num armazenamento de dados analíticos (frequentemente referido como armazém de dados) para análise histórica.
- Os resultados do processamento de fluxo também podem ser mantidos no armazenamento de dados analíticos para dar suporte à análise histórica.
- Ferramentas analíticas e de visualização são usadas para apresentar e explorar os dados históricos e em tempo real.
Nota
As arquiteturas de solução comumente usadas para processamento combinado de dados em lote e fluxo incluem arquiteturas lambda e delta . A arquitetura kappa é uma alternativa mais simples que elimina completamente a camada em lote separada — tratando todos os dados como um fluxo contínuo e reproduzindo-os quando é necessário reprocessamento histórico. Plataformas modernas como a Microsoft Fabric e a Apache Kafka tornam as soluções ao estilo kappa cada vez mais práticas. Os detalhes destas arquiteturas estão fora do âmbito deste curso.