Compreender a normalização
Normalização é um termo usado por profissionais de banco de dados para um processo de design de esquema que minimiza a duplicação de dados e impõe a integridade dos dados.
Embora existam muitas regras complexas que definem o processo de refatoração de dados em vários níveis (ou formas) de normalização, uma definição simples para fins práticos é:
- Separe cada entidade em sua própria tabela.
- Separe cada atributo discreto em sua própria coluna.
- Identifique exclusivamente cada instância de entidade (linha) usando uma chave primária.
- Utilize colunas de chave estrangeira para ligar entidades relacionadas.
Para entender os princípios fundamentais da normalização, suponha que a tabela a seguir represente uma planilha que uma empresa usa para acompanhar suas vendas.
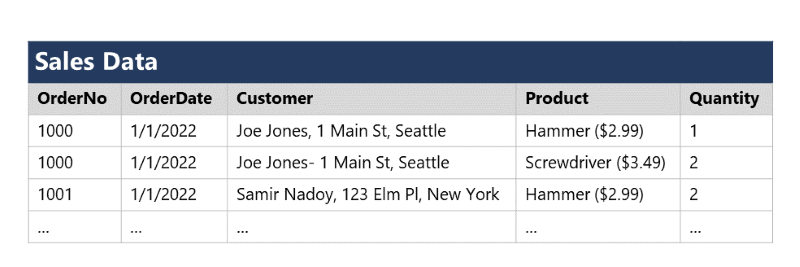
Observe que os detalhes do cliente e do produto são duplicados para cada item individual vendido; e que o nome do cliente e o endereço postal, bem como o nome e o preço do produto, sejam combinados nas mesmas células da planilha.
Agora vamos ver como a normalização muda a maneira como os dados são armazenados.
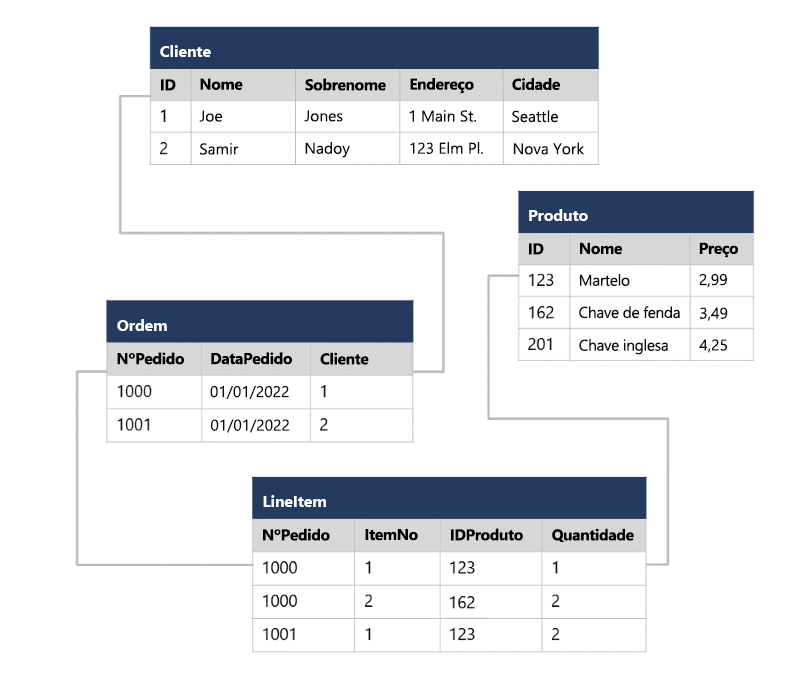
Cada entidade representada nos dados (cliente, produto, ordem de venda e item de linha) é armazenada em sua própria tabela e cada atributo discreto dessas entidades está em sua própria coluna.
Registrar cada instância de uma entidade como uma linha em uma tabela específica da entidade remove a duplicação de dados. Por exemplo, para alterar o endereço de um cliente, você só precisa modificar o valor em uma única linha.
A decomposição de atributos em colunas individuais garante que cada valor seja restrito a um tipo de dados apropriado - por exemplo, os preços dos produtos devem ser valores decimais, enquanto as quantidades de itens de linha devem ser números inteiros. Além disso, a criação de colunas individuais fornece um nível útil de granularidade nos dados para consulta - por exemplo, você pode facilmente filtrar clientes para aqueles que moram em uma cidade específica.
As instâncias de cada entidade são identificadas exclusivamente por um ID ou outro valor de chave, conhecido como chave primária; e quando uma entidade faz referência a outra (por exemplo, uma ordem tem um cliente associado), a chave primária da entidade relacionada é armazenada como uma chave estrangeira. Você pode procurar o endereço do cliente (que é armazenado apenas uma vez) para cada registro na tabela Pedido , fazendo referência ao registro correspondente na tabela Cliente . Normalmente, um sistema de gerenciamento de banco de dados relacional (RDBMS) pode impor integridade referencial para garantir que um valor inserido em um campo de chave estrangeira tenha uma chave primária correspondente existente na tabela relacionada – por exemplo, impedindo pedidos de clientes inexistentes.
Em alguns casos, uma chave (primária ou estrangeira) pode ser definida como uma chave composta com base em uma combinação única de várias colunas. Por exemplo, a tabela LineItem no exemplo acima usa uma combinação exclusiva de OrderNo e ItemNo para identificar um item de linha de uma ordem individual.