Exercício - Trabalhar com arquivos de dados no Armazenamento de Blobs do Azure diretamente do Azure Cosmos DB para PostgreSQL
Neste exercício, você usará a pg_azure_storage extensão para ingerir dados de arquivos armazenados com segurança em um contêiner privado no Armazenamento de Blobs do Azure.
Importante
Este exercício depende do banco de dados do Azure Cosmos DB para PostgreSQL e das tabelas distribuídas que você criou na Unidade 3.
Criar uma conta de Armazenamento de Blob do Azure
Para concluir este exercício, você deve criar uma conta de Armazenamento do Azure, recuperar sua chave de acesso, criar um contêiner e copiar os arquivos de dados históricos do Woodgrove Bank para o contêiner. Nesta tarefa, você cria a conta de armazenamento.
Abra um navegador da Web e navegue até o portal do Azure.
Selecione Criar uma conta de recurso, armazenamento e armazenamento. Você também pode usar a funcionalidade Pesquisar para localizar o recurso.
No separador Informações Básicas, introduza as seguintes informações:
Parâmetro Valor Detalhes do projeto Subscrição Escolha a sua subscrição do Azure. Grupo de recursos Selecione o grupo de learn-cosmosdb-postgresqlrecursos criado no exercício anterior.Detalhes da instância Nome da conta de armazenamento Insira um nome globalmente exclusivo, como stlearnpostgresql.Região Selecione a mesma região escolhida para seu cluster de banco de dados do Azure Cosmos DB para PostgreSQL. Desempenho selecione Standard. Redundância Selecione Armazenamento com redundância local (LRS). 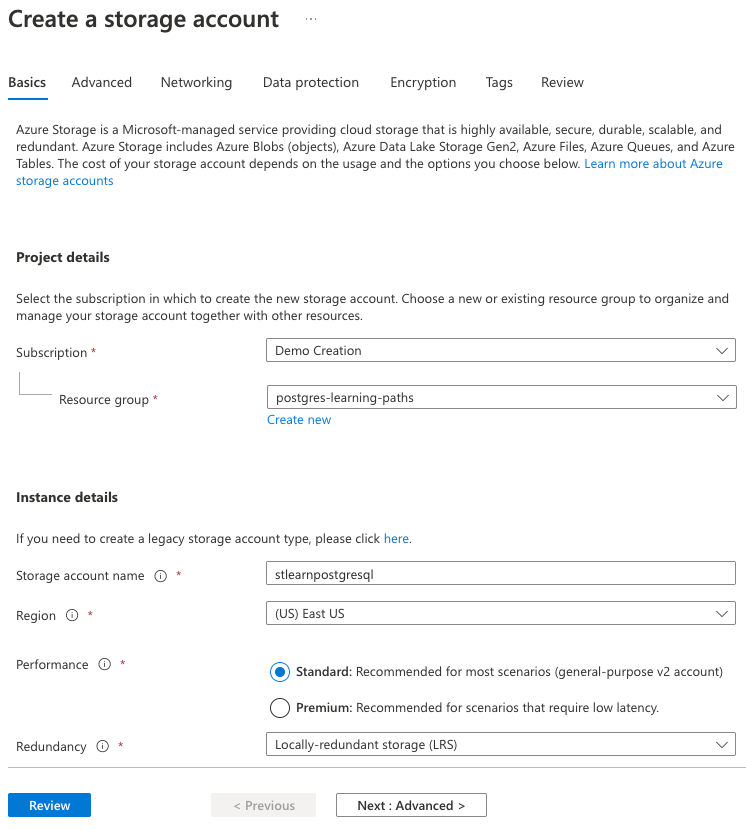
Você usará as configurações padrão para as guias restantes da configuração da conta de armazenamento, portanto, selecione o botão Revisão .
Selecione o botão Criar na guia Revisão para criar a conta de armazenamento.
Criar um contêiner de armazenamento de blob e carregar arquivos de dados
O Woodgrove Bank forneceu-lhe os seus ficheiros de dados históricos em formato CSV. Crie um contêiner nomeado historical-data na nova conta de armazenamento e carregue esses arquivos nele usando a CLI do Azure.
Navegue até sua nova conta de armazenamento no portal do Azure.
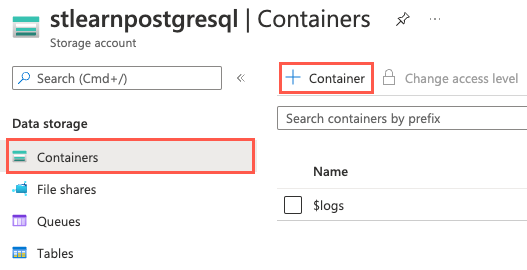
No menu de navegação à esquerda, selecione Contêineres em Armazenamento de dados e, em seguida, selecione + Contêiner na barra de ferramentas.
Na caixa de diálogo Novo contêiner, digite
historical-datano campo Nome, deixe Privado (sem acesso anônimo) selecionado para a configuração Nível de acesso público e selecione Criar.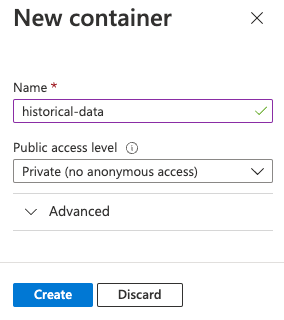
Ao definir o nível de acesso do contêiner como Privado (sem acesso anônimo), você está impedindo o acesso público ao contêiner e seu conteúdo. Abaixo, você fornecerá a extensão com o nome da conta e a
pg_azure_storagechave de acesso, permitindo que ela acesse os arquivos com segurança.Você precisará do nome e da chave associados à sua conta de armazenamento para carregar os arquivos de dados usando a CLI do Azure. No menu de navegação à esquerda, selecione Teclas de acesso em Segurança + rede.
Com a página Teclas de acesso aberta, selecione o ícone do Cloud Shell na barra de ferramentas do portal do Azure para abrir um novo painel do Cloud Shell na parte inferior da janela do navegador.
No prompt do Azure Cloud Shell, execute os seguintes
curlcomandos para baixar os arquivos fornecidos pelo Woodgrove Bank.curl -O https://raw.githubusercontent.com/MicrosoftDocs/mslearn-create-connect-postgresHyperscale/main/users.csv curl -O https://raw.githubusercontent.com/MicrosoftDocs/mslearn-create-connect-postgresHyperscale/main/events.csvOs arquivos serão adicionados à conta de armazenamento do Cloud Shell.
Em seguida, você usará a CLI do Azure para carregar os arquivos no
historical-datacontêiner criado em sua conta de armazenamento. Comece criando variáveis para manter o nome da conta de armazenamento e os valores-chave para facilitar as coisas.Copie o nome da sua conta de armazenamento selecionando o botão Copiar para a área de transferência ao lado do nome da conta de armazenamento na página Teclas de acesso acima do Cloud Shell:
Agora, execute o seguinte comando para criar uma variável para o nome da sua conta de armazenamento, substituindo o token pelo nome da
{your_storage_account_name}sua conta de armazenamento:ACCOUNT_NAME={your_storage_account_name}Em seguida, selecione o botão Mostrar ao lado da tecla para key1 e, em seguida, selecione o botão Copiar para área de transferência ao lado do valor da chave.
Em seguida, execute o seguinte comando, substituindo o
{your_storage_account_key}token pelo valor da chave que você copiou:ACCOUNT_KEY={your_storage_account_key}Para carregar os arquivos, você usará o comando da CLI
az storage blob uploaddo Azure. Execute os seguintes comandos para carregar os arquivos no contêiner da sua conta dehistorical-dataarmazenamento:az storage blob upload --account-name $ACCOUNT_NAME --account-key $ACCOUNT_KEY --container-name historical-data --file users.csv --name users.csv --overwrite az storage blob upload --account-name $ACCOUNT_NAME --account-key $ACCOUNT_KEY --container-name historical-data --file events.csv --name events.csv --overwriteNeste exercício, você está trabalhando com alguns arquivos. Você provavelmente trabalhará com muito mais arquivos em cenários do mundo real. Nessas circunstâncias, você pode revisar diferentes métodos para migrar arquivos para uma conta de Armazenamento do Azure e selecionar a técnica que funcionará melhor para sua situação.
Para verificar os arquivos carregados com êxito, você pode navegar até a página Contêineres da sua conta de armazenamento selecionando Contêineres no menu de navegação à esquerda. Selecione o contêiner na lista de contêineres e observe que o
historical-datacontêiner agora contém arquivos nomeadosevents.csveusers.csv.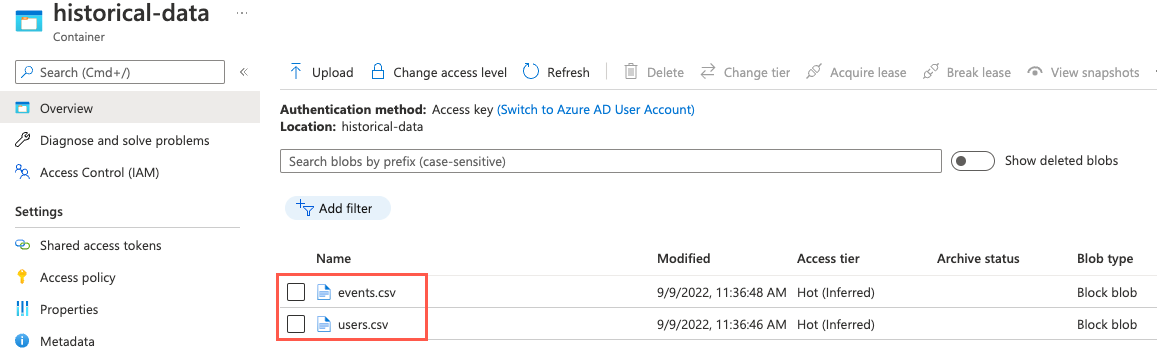
Conectar-se ao banco de dados usando psql no Azure Cloud Shell
Com os arquivos agora armazenados com segurança no armazenamento de blobs, é hora de configurar a pg_azure_storage extensão em seu banco de dados. Você usará o psql utilitário de linha de comando do Azure Cloud Shell para realizar essa tarefa.
Usando a mesma guia do navegador onde o Cloud Shell está aberto, navegue até o recurso do Azure Cosmos DB para PostgreSQL no portal do Azure.
No menu de navegação esquerdo do banco de dados, selecione Cadeias de conexão em Configurações e copie a cadeia de conexão rotulada psql.
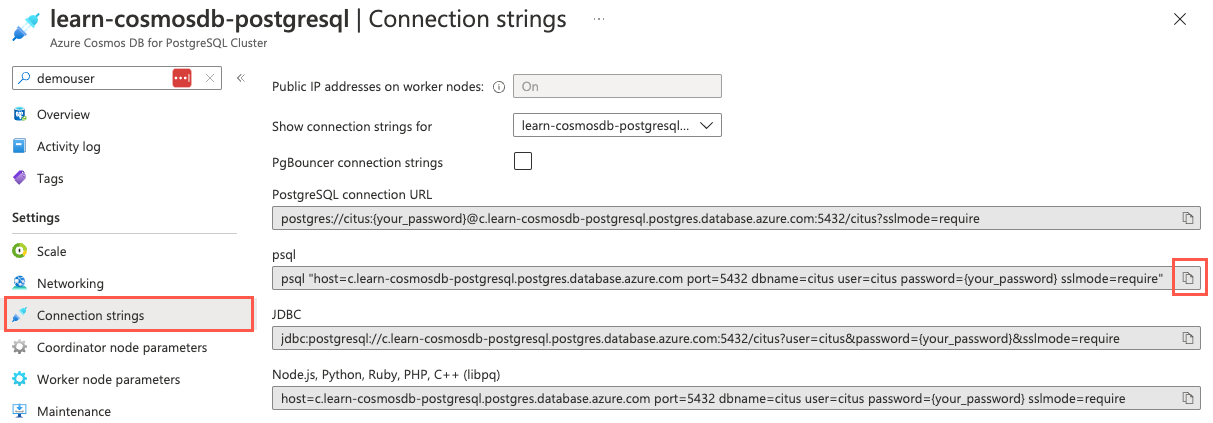
Cole a cadeia de conexão em um editor de texto, como o Bloco de Notas, e substitua o token pela senha atribuída ao usuário ao criar o
{your_password}cituscluster. Copie a cadeia de conexão atualizada para uso abaixo.No painel aberto do Cloud Shell, verifique se o Bash está selecionado para o ambiente e use o utilitário de linha de comando psql para se conectar ao banco de dados. Cole sua cadeia de conexão atualizada (aquela que contém sua senha correta) no prompt no Cloud Shell e execute o comando, que deve ser semelhante ao seguinte comando:
psql "host=c.learn-cosmosdb-postgresql.postgres.database.azure.com port=5432 dbname=citus user=citus password=P@ssword.123! sslmode=require"
Instale a extensão pg_azure_storage
Agora que você está conectado ao seu banco de dados, você pode instalar a pg_azure_storage extensão.
No prompt do Cloud Shell Citus, execute o seguinte comando SQL para carregar a extensão em seu banco de dados:
SELECT create_extension('azure_storage');O nome da extensão é abreviado para
azure_storageao criar e trabalhar com a extensão em seu banco de dados.
Conceder acesso a uma conta de armazenamento de blob
O próximo passo é conceder acesso à sua conta de armazenamento depois de instalar a pg_azure_storage extensão. Lembre-se de que o contêiner foi criado com um nível de acesso Privado (sem acesso anônimo), portanto, você deve fornecer o historical-data nome e a chave associados à sua conta de armazenamento para conceder a extensão para acessar arquivos no contêiner.
Usando a mesma guia do navegador onde o Cloud Shell está aberto, navegue até o recurso da sua conta de armazenamento no portal do Azure.
No menu de navegação à esquerda, selecione Teclas de acesso em Segurança + rede.
Execute a consulta abaixo para dar à
pg_azure_storageextensão acesso à sua conta de armazenamento, substituindo os{storage_account_name}tokens e{storage_account_key}pelos seus valores, que você pode copiar da página Chaves de acesso da sua conta de armazenamento.SELECT azure_storage.account_add('{storage_account_name}', '{storage_account_key}');Se desejar visualizar a lista de contas que foram adicionadas ao seu banco de dados, você pode usar a função da
account_list()seguinte maneira:SELECT azure_storage.account_list();Esta consulta fornecerá a seguinte saída:
account_list ------------------------ (stlearnpostgresql,{})Observe que você pode remover contas do banco de dados usando a
account_remove('ACCOUNT_NAME')função, mas não faça isso aqui, porque você precisa da conta conectada para o restante do exercício.
Listar arquivos em um contêiner de armazenamento de blob
Agora que você está conectado com segurança à conta de armazenamento, pode usar a blob_list() função para produzir uma lista dos blobs dentro de um contêiner nomeado.
Para exibir os arquivos no
historical-datacontêiner, execute a seguinte consulta:SELECT path, content_type, pg_size_pretty(bytes) FROM azure_storage.blob_list('stlearnpostgresql', 'historical-data');A
blob_list()função produz todos os blobs dentro do contêiner especificado:path | content_type | pg_size_pretty ------------+--------------+---------------- events.csv | text/csv | 17 MB users.csv | text/csv | 29 MB
Inspecione o arquivo .csv usuários
Antes de tentar ingerir dados de qualquer arquivo, você deve entender a estrutura dos dados dentro do arquivo. A maneira mais simples de entender a estrutura é visualizar o arquivo no portal do Azure, mas esse recurso é limitado a arquivos menores que 2,1 MB. A saída da blob_list() função revela que ambos os arquivos fornecidos pelo Woodgrove Bank são maiores do que o limite. Para rever os ficheiros, terá de os transferir e abrir localmente.
No portal do Azure, navegue até o recurso da conta de armazenamento, selecione Navegador de armazenamento no menu de navegação à esquerda e selecione Contêineres de Blob na página Navegador de armazenamento.
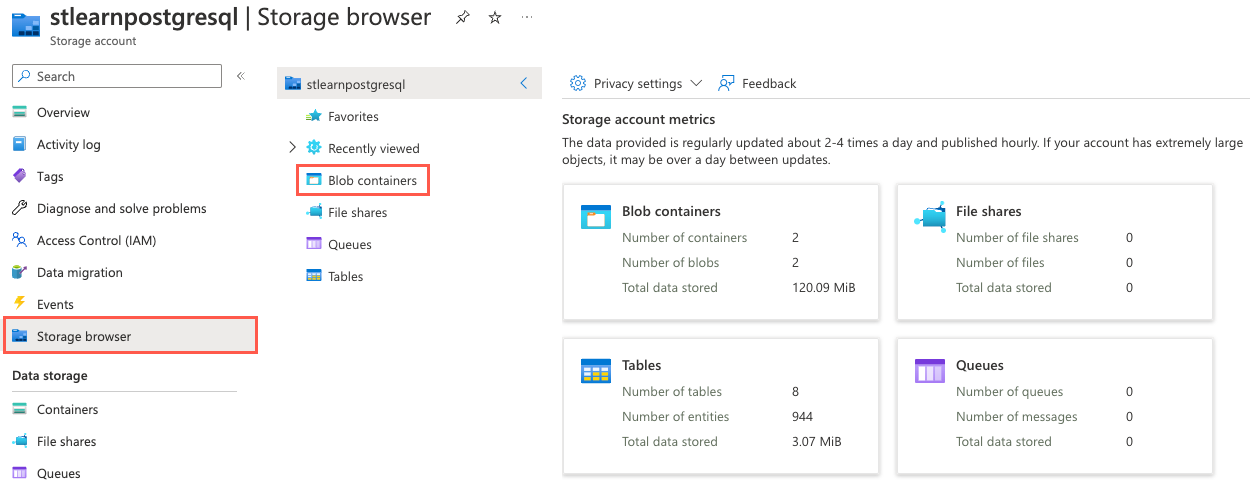
Na lista de contêineres, selecione dados históricos.
Selecione o botão de reticências (...) à direita do arquivo e selecione Download no menu de
users.csvcontexto.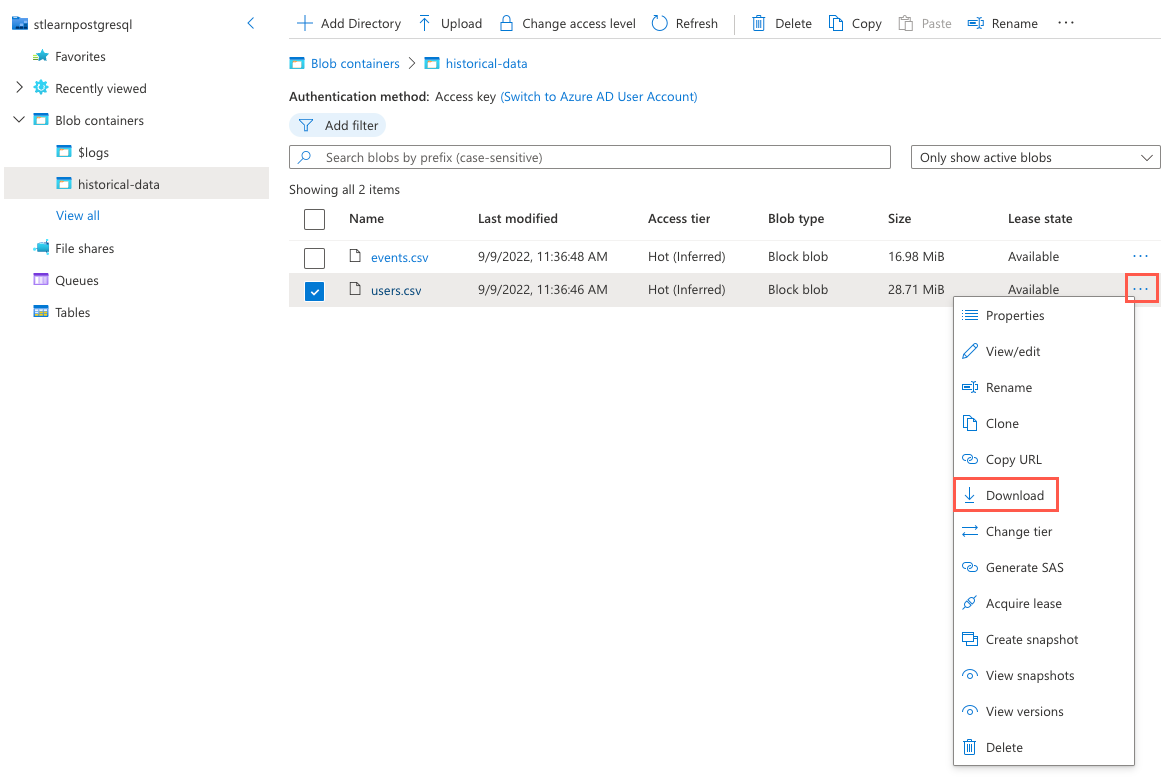
Após a conclusão do download, abra o arquivo usando o Microsoft Excel (ou outro editor de texto que possa abrir arquivos CSV) e observe a estrutura dos dados contidos no arquivo, que se assemelha ao exemplo a seguir das primeiras 10 linhas do
users.csvarquivo.user_idurlloginavatar_url21https://api.woodgrove.com/users/technoweenietechnoweeniehttps://avatars.woodgroveusercontent.com/u/21?22https://api.woodgrove.com/users/macournoyermacournoyerhttps://avatars.woodgroveusercontent.com/u/22?38https://api.woodgrove.com/users/atmosatmoshttps://avatars.woodgroveusercontent.com/u/38?45https://api.woodgrove.com/users/mojodnamojodnahttps://avatars.woodgroveusercontent.com/u/45?69https://api.woodgrove.com/users/rsanheimrsanheimhttps://avatars.woodgroveusercontent.com/u/69?78https://api.woodgrove.com/users/indirectindirecthttps://avatars.woodgroveusercontent.com/u/78?81https://api.woodgrove.com/users/engineyardengineyardhttps://avatars.woodgroveusercontent.com/u/81?82https://api.woodgrove.com/users/jsierlesjsierleshttps://avatars.woodgroveusercontent.com/u/82?85https://api.woodgrove.com/users/brixenbrixenhttps://avatars.woodgroveusercontent.com/u/85?87https://api.woodgrove.com/users/tmorninitmorninihttps://avatars.woodgroveusercontent.com/u/87?Observe que o arquivo contém quatro colunas. A primeira coluna contém valores inteiros e as colunas restantes contêm texto. Também é crucial observar que o arquivo não inclui uma linha de cabeçalho. Essas informações alterarão a forma como você configura o
COPYcomando para ingerir os dados do arquivo em seu banco de dados.Você criou a
payment_userstabela na Unidade 3. Recorde-se que a estrutura desse quadro é a seguinte:/* -- Table structure and distribution details provided for reference CREATE TABLE payment_users ( user_id bigint PRIMARY KEY, url text, login text, avatar_url text ); SELECT created_distributed_table('payment_users', 'user_id'); */Com base na estrutura observada do arquivo, os dados parecem estar alinhados com o
users.csvesperado, e você deve ser capaz de carregar apayment_userstabela sem problemas.
Extrair dados de arquivos no armazenamento de blob
Agora que você entende os dados contidos no arquivo, pode atender à solicitação do Woodgrove Bank para carregar em massa seus dados históricos de arquivos em uma conta de Armazenamento de Blob do Azure. A pg_azure_storage extensão fornece recursos de carregamento em massa estendendo o comando nativo do PostgreSQL COPY para torná-lo capaz de lidar com URLs de recursos do Armazenamento de Blob do Azure. Esse recurso é habilitado por padrão e você pode gerenciá-lo usando a azure_storage.enable_copy_command configuração.
Usando o comando extended
COPY, execute o seguinte comando para ingerir dados dausers.csvtabelapayment_users, certificando-se de substituir o{STORAGE_ACCOUNT_NAME}token pelo nome exclusivo da conta de armazenamento criada acima.-- Bulk load data from the user.csv file in Blob Storage into the payment_users table copy payment_users FROM 'https://{STORAGE_ACCOUNT_NAME}.blob.core.windows.net/historical-data/users.csv';A saída do
COPYcomando especificará o número de linhas copiadas na tabela. Você deve ver o resultado para ousers.csvarquivo:COPY 264197.Suponha que o
users.csvarquivo contivesse uma linha de cabeçalho. Para lidar com isso usando oCOPYcomando e a extensão, você precisa especificar a opção após apg_azure_storageWITH (header)URL do recurso. Por exemplo,copy payment_users FROM 'https://{STORAGE_ACCOUNT_NAME}.blob.core.windows.net/historical-data/users.csv' WITH (header);.Em seguida, execute uma
COUNTconsulta napayment_userstabela para verificar o número de registros copiados na tabela:SELECT COUNT(*) FROM payment_users;Você deve ver os seguintes resultados, que correspondem ao resultado do
COPYcomando:count -------- 264197Parabéns! Você estendeu com êxito seu banco de dados do Azure Cosmos DB para PostgreSQL e usou a
pg_azure_storageextensão para ingerir dados de arquivo de um contêiner seguro no Armazenamento de Blobs do Azure em uma tabela distribuída.No Cloud Shell, execute o seguinte comando para se desconectar do banco de dados:
\q
Limpeza
É crucial que limpe todos os recursos não utilizados. Você é cobrado pela capacidade configurada, não por quanto o banco de dados é usado. Use o procedimento a seguir para excluir seu grupo de recursos junto com os recursos criados para este módulo.
Abra um navegador da Web e navegue até o portal do Azure.
No menu de navegação à esquerda, selecione Grupos de Recursos e, em seguida, selecione o grupo de recursos que criou como parte do exercício na Unidade 4.
No painel Descrição geral, selecione Eliminar grupo de recursos.
Introduza o nome do grupo de recursos que criou para confirmar e, em seguida, selecione Eliminar.
Selecione Excluir novamente para confirmar a exclusão.