Compreender os armazéns de dados no Fabric
O Fabric's Lakehouse é uma coleção de arquivos, pastas, tabelas e atalhos que agem como um banco de dados sobre um data lake. Ele é usado pelo mecanismo Spark e pelo mecanismo SQL para processamento de big data e tem recursos para transações ACID ao usar as tabelas formatadas Delta de código aberto.
A experiência de data warehouse do Fabric permite que você faça a transição da visualização do lago do Lakehouse (que suporta engenharia de dados e Apache Spark) para as experiências SQL que um data warehouse tradicional forneceria. O Lakehouse oferece a capacidade de ler tabelas e usar o ponto de extremidade de análise SQL, enquanto o data warehouse permite manipular os dados.
Na experiência de data warehouse, você modelará dados usando tabelas e exibições, executará T-SQL para consultar dados no data warehouse e no Lakehouse, usará T-SQL para executar operações DML em dados dentro do data warehouse e servirá camadas de relatórios como o Power BI.
Agora que você entende os princípios básicos de arquitetura para um esquema de data warehouse relacional, vamos explorar como criar um data warehouse.
Descrever um data warehouse no Fabric
Na experiência de data warehouse no Fabric, você pode criar uma camada relacional sobre dados físicos no Lakehouse e expô-los a ferramentas de análise e relatórios. Você pode criar seu data warehouse diretamente no Fabric a partir do hub de criação ou dentro de um espaço de trabalho. Depois de criar um armazém vazio, você pode adicionar objetos a ele.
Depois que o depósito for criado, você poderá criar tabelas usando T-SQL diretamente na interface do Fabric.
Ingerir dados no seu armazém de dados
Há algumas maneiras de ingerir dados em um data warehouse de malha, incluindo Pipelines, Fluxos de dados, consulta entre bancos de dados e o comando COPY INTO. Após a ingestão, os dados ficam disponíveis para análise por vários grupos de negócios, que podem usar recursos como consulta e compartilhamento entre bancos de dados para acessá-los.
Criar tabelas
Para criar uma tabela no data warehouse, você pode usar o SQL Server Management Studio (SSMS) ou outro cliente SQL para se conectar ao data warehouse e executar uma instrução CREATE TABLE. Você também pode criar tabelas diretamente na interface do usuário do Fabric.
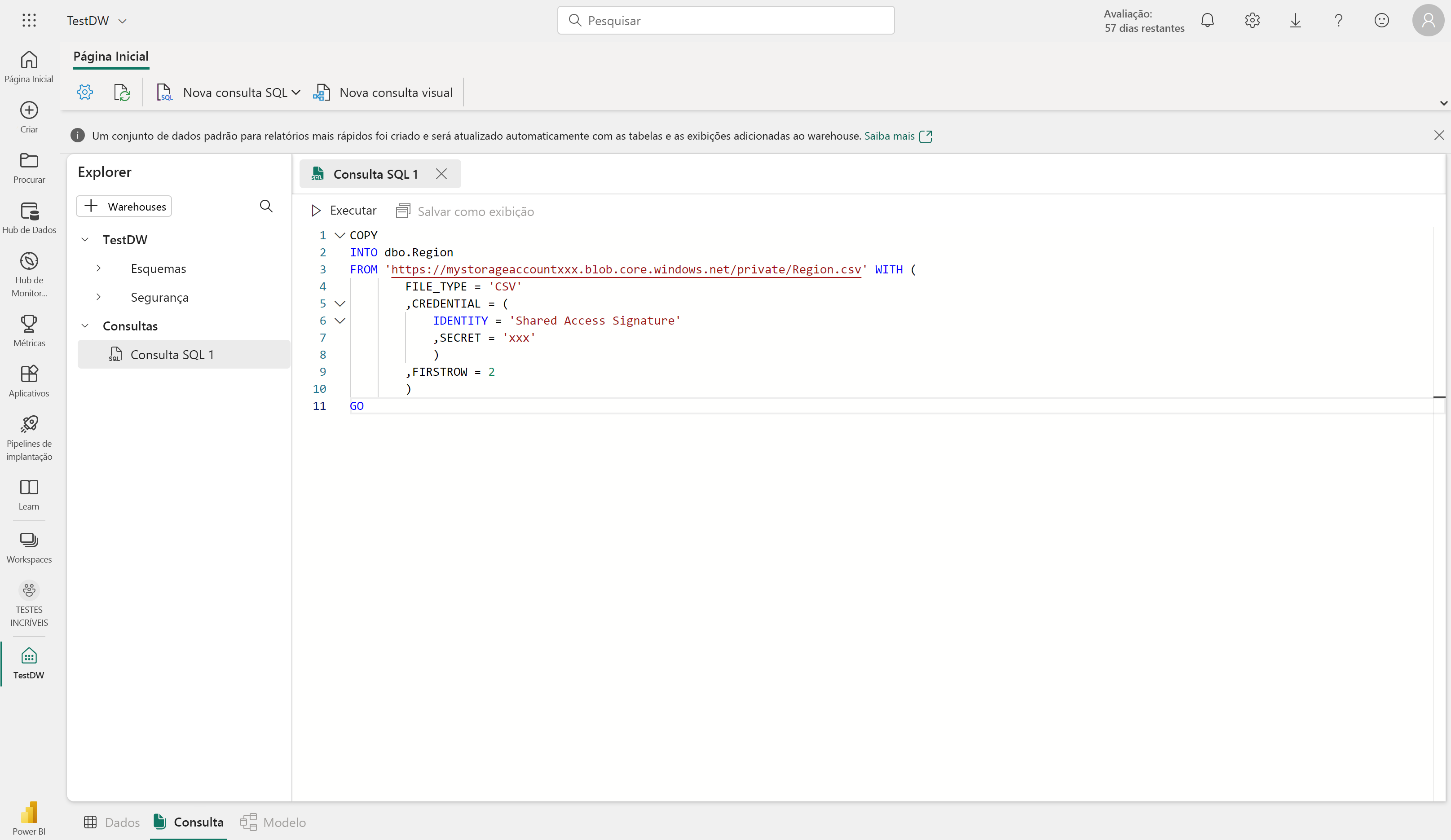
Você pode copiar dados de um local externo para uma tabela no data warehouse usando a COPY INTO sintaxe. Por exemplo:
COPY INTO dbo.Region
FROM 'https://mystorageaccountxxx.blob.core.windows.net/private/Region.csv' WITH (
FILE_TYPE = 'CSV'
,CREDENTIAL = (
IDENTITY = 'Shared Access Signature'
, SECRET = 'xxx'
)
,FIRSTROW = 2
)
GO
Essa consulta SQL carrega dados de um arquivo CSV armazenado no Armazenamento de Blobs do Azure em uma tabela chamada "Região" no data warehouse da Malha.
Considerações sobre a tabela
Depois de criar tabelas em um data warehouse, é importante considerar o processo de carregamento de dados nessas tabelas. Uma abordagem comum é usar tabelas de preparo. No Fabric, você pode usar comandos T-SQL para carregar dados de arquivos em tabelas de preparo no data warehouse.
As tabelas de preparo são tabelas temporárias que podem ser usadas para executar limpeza de dados, transformações de dados e validação de dados. Você também pode usar tabelas de preparo para carregar dados de várias fontes em uma única tabela de destino.
Normalmente, o carregamento de dados é realizado como um processo em lote periódico no qual inserções e atualizações para o data warehouse são coordenadas para ocorrer em um intervalo regular (por exemplo, diariamente, semanalmente ou mensalmente).
Geralmente, você deve implementar um processo de carga de data warehouse que execute tarefas na seguinte ordem:
- Ingerir os novos dados a serem carregados em um data lake, aplicando limpeza ou transformações pré-carga, conforme necessário.
- Carregue os dados de arquivos em tabelas de preparo no data warehouse relacional.
- Carregue as tabelas de dimensão a partir dos dados de dimensão nas tabelas de preparo, atualizando linhas existentes ou inserindo novas linhas e gerando valores de chave substitutos conforme necessário.
- Carregue as tabelas de fatos a partir dos dados de fatos nas tabelas de preparo, procurando as chaves substitutas apropriadas para dimensões relacionadas.
- Execute a otimização pós-carga atualizando índices e estatísticas de distribuição de tabelas.
Se você tiver tabelas na casa do lago e quiser poder consultá-las em seu armazém - mas não fazer alterações - com um data warehouse do Fabric, não será necessário copiar dados da casa do lago para o data warehouse. Você pode consultar dados na casa do lago diretamente do data warehouse usando consultas entre bancos de dados.
Importante
Trabalhar com tabelas no data warehouse do Fabric atualmente tem algumas limitações. Consulte Tabelas em data warehousing no Microsoft Fabric para obter mais informações.