Extração de informação de documentos
Observação
Consulte a guia Texto e imagens para obter mais detalhes!
Os processos de negócio atuais dependem fortemente dos dados contidos em documentos como formulários, recibos e faturas. O processamento manual pode introduzir atrasos e erros, tornando a automação da extração de dados mais importante do que nunca.
Como funciona o Azure Content Understanding
O Azure Content Understanding segue um fluxo de trabalho de extração orientado por modelos, no qual conteúdos não estruturados são ingeridos, analisados e devolvidos como dados estruturados.
Ingerir conteúdo: Submete conteúdo ao Azure Content Understanding.
Análise alimentada por IA: O serviço utiliza uma combinação de: Reconhecimento Ótico de Caracteres (OCR), reconhecimento de voz, compreensão de linguagem natural e modelos multimodais de IA para analisar o conteúdo.
Saída estruturada: O serviço devolve resultados estruturados (por exemplo, em JSON) que correspondem ao seu modelo — tornando os dados fáceis de armazenar, pesquisar ou integrar em sistemas a jusante.
Observação
JSON (JavaScript Object Notation) é um formato de dados baseado em texto utilizado para armazenar e trocar dados estruturados entre sistemas. É fácil para os humanos lerem e escreverem, e fácil para as máquinas analisarem e gerarem.
Compreender esquemas
O OCR (reconhecimento ótico de caracteres) permite a um computador 'ler' texto de imagens, como documentos digitalizados, fotografias de recibos ou imagens de páginas impressas, e transformar esse texto em texto digital editável e pesquisável. O OCR básico ajuda a reconhecer texto impresso, foca-se na extração de texto e não compreende significado, contexto ou relações entre palavras.
As capacidades de análise de documentos do Azure Content Understanding vão além da simples extração de texto baseada em OCR, incluindo a extração de campos e valores baseada em esquemas . A abordagem orientada por esquemas é o que diferencia o Azure Content Understanding dos serviços básicos de OCR ou transcrição.
Um esquema descreve que informação pretende extrair e como essa informação deve ser estruturada. Quando defines um esquema, especificas campos a extrair. Um esquema lista os campos ou entidades específicas que lhe interessam.
Por exemplo, suponha que você defina um esquema que inclua os campos comuns normalmente encontrados em uma fatura, como:
- Nome do fornecedor
- Número da fatura
- Data da fatura
- Nome do cliente
- Endereço personalizado
- Itens - os itens encomendados, cada um dos quais inclui:
- Descrição do item
- Preço unitário
- Quantidade encomendada
- Total do item de linha
- Subtotal da fatura
- Imposto
- Taxa de envio
- Total da fatura
Agora suponha que você precise extrair essas informações da seguinte fatura:
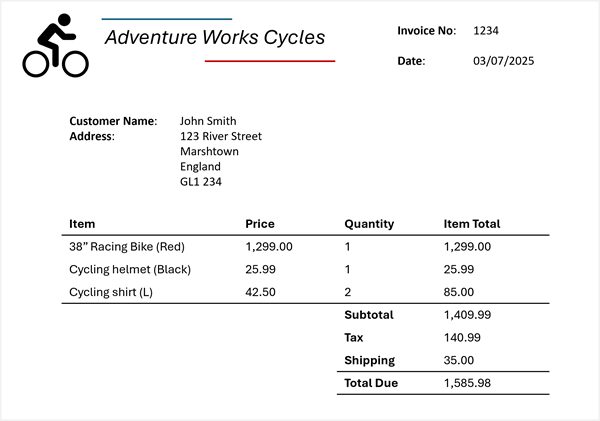
O Azure Content Understanding pode aplicar o esquema da fatura à sua fatura e identificar os campos correspondentes, mesmo quando estão rotulados com nomes diferentes (ou nem sequer estão rotulados). A análise resultante produz um resultado como este:

O esquema também define a estrutura do campo. Os esquemas suportam campos estruturados e aninhados, não apenas texto plano. Por exemplo:
-
Itemsé uma coleção - Cada item tem
description,unit price,quantity, eline total
Identificar campos estruturados permite que o Azure Content Understanding compreenda as relações entre valores, algo que o OCR sozinho não consegue fazer.
No exemplo da fatura, para cada campo detetado, pode extrair valores aninhados:
- Nome do fornecedor: Adventure Works Cycles
- Número da fatura: 1234
- Data da fatura: 03/07/2025
- Nome do cliente: John Smith
- Endereço personalizado: 123 River Street, Marshtown, England, GL1 234
-
Itens:
- Ponto 1:
- Descrição do artigo: 38" Racing Bike (Vermelho)
- Preço unitário: 1299.00
- Quantidade encomendada: 1
- Total de itens da linha: 1299,00
- Ponto 2:
- Descrição do artigo: Capacete de ciclismo (preto)
- Preço unitário: 25.99
- Quantidade encomendada: 1
- Total de itens da linha: 25,99
- Ponto 3:
- Descrição do artigo: Camisa de ciclismo (L)
- Preço unitário: 42.50
- Quantidade encomendada: 2
- Total de itens de linha: 85,00
- Ponto 1:
- Subtotal da fatura: 1409,99
- Imposto: 140,99
- Taxa de envio: 35.00
- Total da fatura: 1585,98
O Azure Content Understanding extrai o significado esperado, não apenas os rótulos. Os esquemas são aplicados semanticamente, o que significa:
- Os campos podem ser extraídos mesmo que os rótulos sejam diferentes
- Os campos podem ser extraídos mesmo que faltem rótulos
Por exemplo, número de fatura, fatura # ou um número não rotulado podem todos corresponder a InvoiceNumber se o analisador determinar que representam o mesmo conceito.
Compreender os analisadores
Um analisador é uma unidade no Azure Content Understanding que recebe inputs, aplica análise de IA e produz resultados estruturados. Os analisadores aplicam consistentemente a mesma lógica de extração a todo o conteúdo recebido. Depois de configurado, um analisador assegura que um esquema é reutilizado de forma consistente para cada pedido de análise. Os analisadores também produzem resultados JSON previsíveis. Os resultados estruturados facilitam o processamento a jusante (armazenamento, pesquisa, automação).
O Azure Content Understanding oferece analisadores pré-construídos para cenários comuns e suporta analisadores personalizados adaptados às suas necessidades. A um nível elevado:
- Escolhe ou cria um analisador.
- O analisador inclui um esquema que define campos e estrutura.
- Submetes conteúdo para análise
- O serviço aplica o esquema
- Recebe resultados JSON estruturados que correspondem ao esquema
Utilização do Azure Content Understanding no portal Foundry
Observação
O portal Foundry tem uma interface de utilizador clássica (UI) e uma nova interface.
Depois de criar um recurso Microsoft Foundry, pode usar a interface clássica do portal Foundry para testar o Azure Content Understanding. O portal Foundry fornece exemplos de conteúdo e permite-lhe carregar o seu próprio material para análise.
Pode usar a interface visual para selecionar um documento de origem e extrair campos de informação padrão. Por exemplo, quando experimenta o Azure Content Understanding numa imagem de um documento, o serviço devolve o texto do documento e a informação de layout do texto.

Os analisadores do Azure Content Understanding identificam valores de texto nos documentos e os mapeiam para campos específicos. Por exemplo, dada uma fatura, o serviço retorna os campos (como morada do fornecedor) e os dados nos campos (como 123 456th Street).

No portal Foundry, também pode ver os resultados JSON do processamento.

Construir uma aplicação cliente com Azure Content Understanding
Pode usar a API de Compreensão de Conteúdo para construir uma aplicação cliente leve que extrai dados programaticamente.
Observação
Uma aplicação cliente é um programa de software que corre no dispositivo do utilizador e solicita serviços ou dados a outro sistema, tipicamente um servidor, através de uma rede. O cliente é a parte da aplicação com que os utilizadores interagem, enquanto o servidor faz o trabalho pesado nos bastidores. As aplicações podem solicitar dados ou ações a um serviço e receber uma resposta estruturada através de uma API.
Quando utiliza a API de Compreensão de Conteúdo, pode escolher um analisador pré-construído ou criar um analisador personalizado. Os analisadores pré-construídos incluem: prebuilt-invoice, prebuilt-imageSearch, prebuilt-audioSearch, e prebuilt-videoSearch. Quando submetes conteúdo para análise ao analisador, a análise é assíncrona, o que significa que recebes o resultado mais tarde, quando estiver pronto. Como a análise é assíncrona, é necessário consultar a URL Operation-Location (ou analyzerResults) até que o trabalho tenha sucesso.
Utilização do Azure Content Understanding Python SDK
Vamos analisar o processo de utilização do SDK Python para analisar uma fatura a partir de uma URL.
- Instale o Azure Content Understanding Python SDK.
python -m pip install azure-ai-contentunderstanding
Identifique o endpoint do seu recurso Foundry e a chave API ou o ID do Microsoft Entra. O seu endpoint normalmente é o seguinte:
https://<your-resource-name>.services.ai.azure.com/Cria e executa o código da aplicação cliente. Este
analzyer_idé o ID do analisador pré-construído. Pode encontrar uma lista de IDs de analisadores pré-construídos aqui.
import os
from azure.ai.contentunderstanding import ContentUnderstandingClient
from azure.core.credentials import AzureKeyCredential
endpoint = os.environ["FOUNDRY_ENDPOINT"]
key = os.environ["FOUNDRY_KEY"]
client = ContentUnderstandingClient(endpoint=endpoint, credential=AzureKeyCredential(key))
# 1) start analysis with analyzer id + inputs
analyzer_id = "prebuilt-invoice"
inputs = [
{"url": "https://github.com/Azure-Samples/azure-ai-content-understanding-python/raw/refs/heads/main/data/invoice.pdf"}
]
# 2) wait for the Long Running Operation (LRO) to complete
poller = client.begin_analyze(analyzer_id=analyzer_id, inputs=inputs) # starts LRO
result = poller.result() # waits for completion (polling handled by SDK)
# 3) read structured fields + markdown
# The result typically includes extracted "fields" and "markdown" per input content item.
for content in result.contents:
print(content.markdown)
print(content.fields)
A saída resultante é JSON que mostra a marcação extraída, os campos, os dados nos campos e a pontuação de confiança. Por exemplo:
{
"status": "Succeeded",
"result": {
"analyzerId": "prebuilt-invoice",
"apiVersion": "2025-05-01-preview",
"contents": [
{
"markdown": "# INVOICE\n\nCONTOSO LTD.\n\nContoso Headquarters\n123 456th St\nNew York, NY, 10001\n\nINVOICE: INV-100\n\nINVOICE DATE: 11/15/2019\n\nDUE DATE: 12/15/2019\n\nCUSTOMER NAME: MICROSOFT CORPORATION\n",
"fields": {
"CustomerName": {
"type": "string",
"valueString": "MICROSOFT CORPORATION",
"confidence": 0.95,
},
"InvoiceDate": {
"type": "date",
"valueDate": "2019-11-15",
"confidence": 0.994,
}
}
}
]
}
}
De seguida, aprenda a usar analisadores Azure Content Understanding para extrair dados estruturados de áudio e vídeo.