Modelar pequenas entidades de pesquisa
Nosso modelo de dados inclui duas pequenas entidades ProductCategory de dados de referência e ProductTag. Essas entidades são usadas para valores de referência e estão relacionadas a outras entidades através de um 1:Many relationshiparquivo .
Nesta unidade, modelaremos as ProductCategory entidades e ProductTag em nosso modelo de documento.
Categorias de modelos de produtos
Em primeiro lugar, para as categorias, vamos modelar os dados com suas colunas id e name como as únicas propriedades e colocá-los em um novo contêiner chamado ProductCategory.
Em seguida, precisamos escolher uma chave de partição. Vamos explorar as operações que precisamos realizar nesses dados.
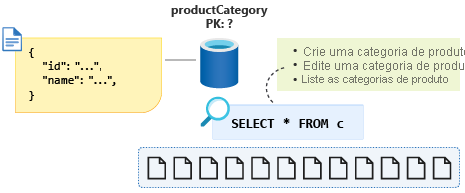
Criaremos uma nova categoria de produto, editaremos uma categoria de produto e, em seguida, listaremos todas as categorias de produtos. Criar e editar categorias de produtos não são operações executadas com frequência. Nosso aplicativo de comércio eletrônico geralmente lista todas as categorias de produtos quando os clientes visitam o site. Portanto, a última operação é a que mais executaremos.
A consulta para esta última operação terá esta aparência: SELECT * FROM c.
Com id como a chave de partição selecionada, esta consulta agora será entre partições, embora queiramos tentar otimizar essas operações de leitura pesada usando apenas uma única partição, se possível. Também sabemos que os dados para a categoria de produto nunca crescerão perto de 20 GB de tamanho, então como essas informações nos ajudariam na modelagem dos dados de uma forma que resultará em uma única consulta de partição quando listarmos todas as categorias de produtos.
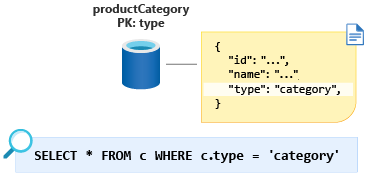
Para coagir essa pequena quantidade de dados de volta em uma única partição, podemos adicionar uma propriedade discriminadora de entidade ao nosso esquema e usá-la como a chave de partição para esse contêiner. Ao atribuir a essa propriedade um valor constante para todos os documentos desse tipo no contêiner, garantimos que agora temos uma única consulta de partição. Neste caso, chamaremos a propriedade type e daremos um valor constante de category. Nossa consulta agora seria parecida com: SELECT * FROM c WHERE c.type = ”category”.
Etiquetas de produto do modelo
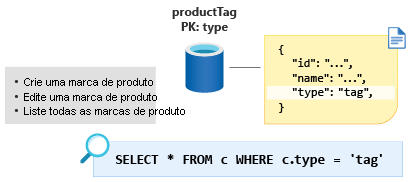
Segue-se a ProductTag entidade. Esta entidade é quase idêntica em função à ProductCategory entidade que discutimos na seção anterior. Vamos adotar a mesma abordagem aqui e modelar o documento para conter propriedades ID e name e criar uma propriedade discriminadora de entidade chamada type, neste caso com um valor constante de tag. Vamos criar um novo contêiner chamado ProductTag e fazer type a nova chave de partição.
Algumas pessoas acham estranha esta técnica para modelar pequenas tabelas de pesquisa. No entanto, modelar os nossos dados desta forma dá-nos a oportunidade de fazer uma otimização adicional no próximo módulo.