Usar tabelas e exibições de metadados do coordenador para entender a distribuição de dados
O Woodgrove Bank pediu que você revisasse e otimizasse a execução de consultas para as tabelas distribuídas em seu banco de dados Azure Cosmos DB for PostgreSQL. Você pode consultar tabelas de metadados que residem no nó coordenador para exibir informações detalhadas sobre os nós e fragmentos em seu banco de dados distribuído. Você pode usar essas tabelas para obter informações sobre a estrutura, a utilização do nó, a distribuição de dados e o desempenho do banco de dados.
O coordenador mantém essas tabelas e as usa para rastrear estatísticas e informações sobre a integridade e a localização dos fragmentos nos nós. Essas tabelas, prefixadas com pg_dist_*, contêm diversos metadados sobre seu banco de dados distribuído e o coordenador os usa ao criar planos de execução de consulta nos nós de trabalho.
Esta unidade destaca algumas das tabelas abaixo, mas você pode visualizar a lista completa de tabelas de metadados, saber mais sobre elas e visualizar seus esquemas lendo a documentação de tabelas e exibições do sistema.
Localizar a coluna de distribuição de uma tabela distribuída
Cada tabela distribuída tem uma coluna de distribuição. Quando você está ingerindo dados e escrevendo consultas em seu banco de dados, é essencial saber qual coluna é. Por exemplo, ao ingressar ou filtrar tabelas, você pode ver mensagens de erro com dicas como "adicionar um filtro à coluna de distribuição".
Você pode usar a exibição de tabelas distribuídas, chamada citus_tables, no nó coordenador para exibir o nome da coluna de distribuição, juntamente com outros detalhes sobre cada tabela distribuída em seu banco de dados.
Aqui está um exemplo usando a payment_events tabela do aplicativo de pagamento sem contato do Woodgrove Bank:
SELECT table_name, distribution_column, table_size FROM citus_tables WHERE table_name = 'payment_events'::regclass;
table_name | distribution_column | table_size
----------------+---------------------+------------
payment_events | user_id | 5256 kB
Essa citus_tables exibição também fornece outras informações úteis, como a contagem de estilhaços, o tamanho e o tipo de cada tabela distribuída.
Descubra informações sobre os nós em seu cluster
As informações sobre nós de trabalho no cluster estão contidas na tabela de nós de trabalho, pg_dist_node. Para exibir informações sobre os nós no cluster do Woodgrove Bank, você pode executar o seguinte comando:
-- Turn on extended display to pivot results of wide tables
\x
O \x comando gira resultados de consulta ampla para evitar rolagem horizontal e saída mal formatada.
-- Retrieve node information
SELECT * FROM pg_dist_node;
-[ RECORD 1 ]----+-----------------------------------------------------------------
nodeid | 2
groupid | 2
nodename | private-w1.learn-cosmosdb-postgresql.postgres.database.azure.com
nodeport | 5432
noderack | default
hasmetadata | t
isactive | t
noderole | primary
nodecluster | default
metadatasynced | t
shouldhaveshards | t
-[ RECORD 2 ]----+-----------------------------------------------------------------
nodeid | 3
groupid | 3
nodename | private-w0.learn-cosmosdb-postgresql.postgres.database.azure.com
nodeport | 5432
noderack | default
hasmetadata | t
isactive | t
noderole | primary
nodecluster | default
metadatasynced | t
shouldhaveshards | t
-[ RECORD 3 ]----+-----------------------------------------------------------------
nodeid | 4
groupid | 0
nodename | private-c.learn-cosmosdb-postgresql.postgres.database.azure.com
nodeport | 5432
noderack | default
hasmetadata | t
isactive | t
noderole | primary
nodecluster | default
metadatasynced | t
shouldhaveshards | f
A revisão da saída da consulta revela detalhes, incluindo a ID, o nome e a porta associados a cada nó. Além disso, você pode ver se o nó está ativo e deve conter fragmentos, entre outros bits de informação. Você pode usar nomes de nó e números de porta para se conectar diretamente aos trabalhadores, o que é uma prática comum ao ajustar o desempenho da consulta.
Inspecione a distorção de dados para entender a utilização do nó
A equipe do Woodgrove está preocupada que, com o tempo, a distribuição de dados em seu banco de dados se torne enviesada, resultando em menor desempenho de consulta. Eles pediram que você fornecesse a eles uma consulta que lhes permitiria avaliar rapidamente a distorção de dados e uma maneira de resolvê-la quando identificada.
A distorção de dados refere-se à forma como os dados são distribuídos uniformemente entre os nós de trabalho. A seleção adequada das colunas de distribuição deve resultar em uma utilização relativamente consistente dos recursos de armazenamento e computação entre os nós de trabalho. Os clusters são executados de forma mais eficiente quando os dados são colocados uniformemente entre nós e os dados relacionados são colocalizados nos mesmos trabalhadores. Você pode usar o modo de exibição para consultar o citus_shards tamanho dos dados em cada fragmento. Esta consulta fornece informações sobre como os dados são distribuídos uniformemente entre fragmentos.
Das mesas distribuídas associadas ao aplicativo de pagamento sem contato do Woodgrove Bank, a mais provável de se tornar distorcida ao longo do tempo é a payment_events tabela. As tabelas de comerciantes e usuários são distribuídas em suas chaves primárias, portanto, essas tabelas sempre terão uma linha por coluna de distribuição. Eles devem permanecer uniformemente distribuídos à medida que novos registros são adicionados. Por outro lado, a tabela de eventos pode potencialmente ver um número ímpar de linhas inseridas para cada user_id, que é a coluna de distribuição selecionada. Se alguns usuários enviarem muito mais eventos do que outros, isso resultará em alguns fragmentos contendo maiores quantidades de dados do que outros. Quando os tamanhos de dados de estilhaços são diferentes, isso indica que você tem distorção de dados.
Para exibir os tamanhos de dados em cada fragmento payment_events da tabela, você pode usar a seguinte consulta:
SELECT shardid, shard_name, shard_size
FROM citus_shards
WHERE table_name = 'payment_events'::regclass
LIMIT 10;
shardid | shard_name | shard_size
---------+-----------------------+------------
102232 | payment_events_102232 | 770048
102233 | payment_events_102233 | 614400
102234 | payment_events_102234 | 647168
102235 | payment_events_102235 | 622592
102236 | payment_events_102236 | 638976
102237 | payment_events_102237 | 638976
102238 | payment_events_102238 | 598016
102239 | payment_events_102239 | 622592
102240 | payment_events_102240 | 729088
102241 | payment_events_102241 | 630784
A saída da consulta permite comparar o tamanho de cada fragmento. Quando os fragmentos são de tamanho aproximadamente igual, como na saída da tabela anterior payment_events , você pode inferir que os nós de trabalho mantêm um número aproximadamente igual de linhas.
Para minimizar a distorção de dados, a coluna de distribuição selecionada deve:
- Possuem muitos valores distintos maiores ou iguais ao número de fragmentos (32 por padrão).
- Ter um número semelhante de linhas associadas a cada valor exclusivo.
Qualquer escolha de tabela e coluna de distribuição em que qualquer uma das propriedades não atenda a esses critérios resultará em distorção de dados. Quando você tem distorção de dados, isso pode resultar em consultas de menor desempenho, pois alguns nós de trabalho terão que executar mais trabalho do que outros, e as consultas paralelizadas não funcionarão com tanta eficiência.
Corrigir distorção de dados com o rebalanceador Shard
Para fornecer um método livre de código de avaliação de distorção de dados para o Woodgrove Bank, você pode recomendar que eles usem o portal do Azure para ver se os dados são distribuídos igualmente entre nós de trabalho no cluster. No portal do Azure, selecione o item Rebalanceador de estilhaços no menu de navegação à esquerda.
Se os dados estiverem distorcidos entre trabalhadores, você verá a mensagem Rebalanceamento é recomendado e uma lista do tamanho de cada nó. Caso contrário, você verá a mensagem Rebalanceamento não é recomendado no momento.
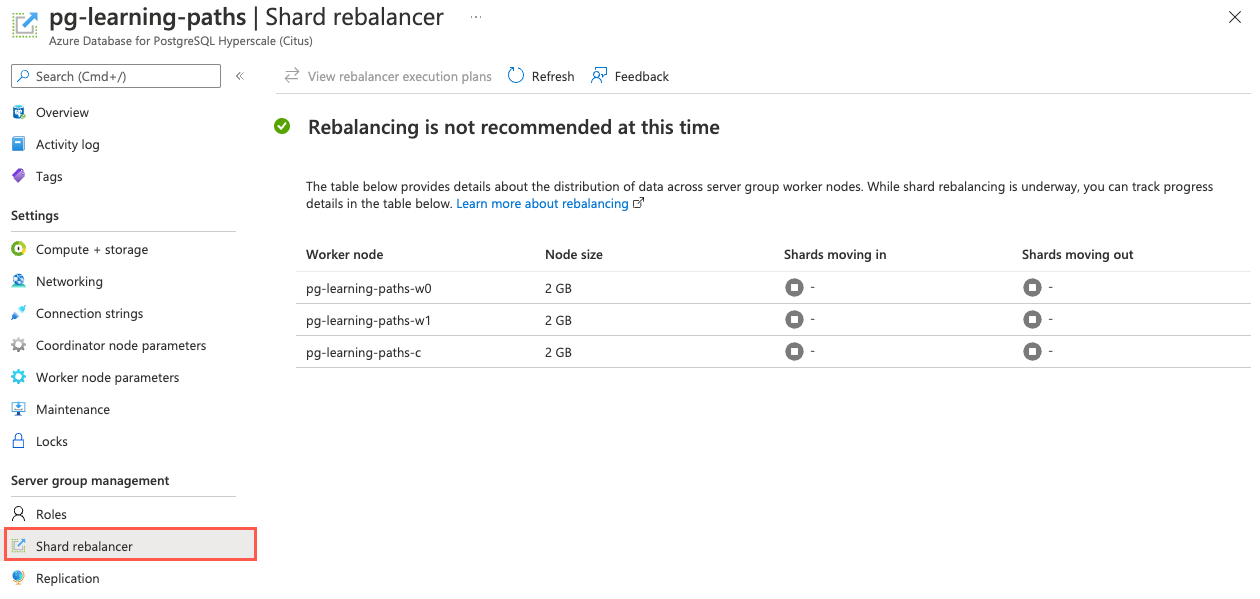
Se a distorção de dados for encontrada, você poderá iniciar o rebalanceador de estilhaços conectando-se ao nó coordenador do cluster e executando a rebalance_table_shards função SQL em tabelas distribuídas.
A função reequilibra todas as tabelas no grupo de colocation da tabela nomeada em seu argumento. Você não precisa chamar a função para cada tabela distribuída. Em vez disso, chame-o em uma tabela representativa de cada grupo de colocation.
Por exemplo, executar o seguinte contra a tabela também reequilibrará a payment_eventspayment_users tabela, à medida que eles forem colocalizados.
SELECT rebalance_table_shards('payment_events');
Em seguida, você pode monitorar o progresso do rebalanceador no portal do Azure, onde verá uma mensagem informando que o Rebalanceamento está em andamento, juntamente com detalhes sobre o número de fragmentos entrando ou saindo de um nó e o progresso por tabela de banco de dados.
Identificar posicionamentos de estilhaços
O Azure Cosmos DB para PostgreSQL atribui cada linha a um fragmento com base no valor da coluna de distribuição especificada. Cada linha estará em precisamente um fragmento, e cada fragmento pode conter várias linhas. Você pode usar a pg_dist_placement tabela para exibir detalhes dos posicionamentos de estilhaços.
A tabela de posicionamento de estilhaços rastreia a localização de réplicas de estilhaços em nós de trabalho. Cada réplica de um fragmento atribuído a um nó específico é chamada de posicionamento de estilhaço. Esta tabela também armazena informações sobre a integridade e a localização de cada colocação de estilhaços. Determinar qual nó de trabalho tem as linhas para uma coluna de distribuição específica pode ser útil em muitos casos.
Suponha que o Woodgrove Bank tenha pedido que você encontre qual nó de trabalhador contém os dados de 5 no aplicativo de user_id pagamento sem contato. Em outras palavras, você deseja identificar o posicionamento do estilhaço que contém linhas cuja coluna de distribuição tem um valor de 5:
SELECT shardid, nodename, placementid
FROM pg_dist_placement AS p,
pg_dist_node AS n
WHERE p.groupid = n.groupid
AND n.noderole = 'primary'
AND shardid = (
SELECT get_shard_id_for_distribution_column('payment_users', 5)
);
A consulta retorna o que contém os dados para o shardiduser_id com um valor de 5.
shardid | nodename | placementid
---------+------------------------------------------------------------------+-------------
102014 | private-w0.learn-cosmosdb-postgresql.postgres.database.azure.com | 7
Consultas de diagnóstico úteis
Além das tabelas e exibições de metadados, há muitas consultas de diagnóstico úteis que são benéficas para entender o desempenho do banco de dados e solucionar problemas.
Consultas ativas
A citus_stat_activity exibição mostra quais consultas estão sendo executadas no momento. Você pode filtrar para encontrar os que estão sendo executados ativamente, juntamente com o ID do processo de seu back-end:
SELECT pid, query, state
FROM citus_stat_activity
WHERE state != 'idle';
Saiba por que as consultas estão esperando
Você também pode consultar os motivos mais comuns pelos quais consultas não ociosas estão esperando. Para explicar os motivos, consulte a documentação do PostgreSQL.
SELECT wait_event || ':' || wait_event_type AS type, count(*) AS number_of_occurrences
FROM pg_stat_activity
WHERE state != 'idle'
GROUP BY wait_event, wait_event_type
ORDER BY number_of_occurrences DESC;
Exibir atividade de consulta distribuída
Os documentos da Microsoft fornecem muitos exemplos de como as exibições de metadados podem ser usadas para observar consultas e bloqueios em todo o cluster. Leia a documentação da atividade de consulta distribuída para saber mais sobre como você pode usar essas exibições para entender melhor as consultas distribuídas em seu banco de dados.