Compreender a execução de consultas distribuídas
Antes de otimizar o desempenho da consulta para o Woodgrove Bank, você deve entender como as consultas distribuídas são executadas no Azure Cosmos DB para PostgreSQL. Você também deve entender os parâmetros do servidor que você pode usar para ajustar a execução da consulta. Cada cluster consiste em um único nó coordenador e vários nós de trabalho. Essa arquitetura permite que a computação, a memória e o armazenamento sejam dimensionados em vários servidores PostgreSQL na nuvem, mas também adiciona complexidade à execução de consultas.

O diagrama também apresenta setas à direita e à esquerda, mostrando como você pode adicionar mais nós para dimensionar.
O coordenador usa um pipeline de processamento de consultas que consiste em um planejador de consultas distribuído e um executor de consulta distribuído. Para cada consulta emitida para o cluster, o coordenador consulta as tabelas de metadados para criar um plano de execução e, em seguida, passa esse plano para o executor para execução.
Compreender o planejamento de execução de consultas distribuídas
O planejador de consultas distribuídas no coordenador leva todas as consultas emitidas para o cluster e gera o plano para execução distribuída. Esse plano é então paralelizado entre nós de trabalho. As otimizações são aplicadas para garantir que as consultas sejam executadas de forma escalável e que a E/S de rede seja minimizada.
Para consultas que contêm uma WHERE cláusula de filtragem para um valor de coluna de distribuição específico, o coordenador usa tabelas de metadados para determinar para qual fragmento encaminhar a consulta por hash da coluna de distribuição da linha ou linhas envolvidas na consulta. Essas consultas atingirão apenas um fragmento, então o processo de planejamento é ligeiramente diferente.
Depois que o planejador de execução tiver identificado o fragmento ou fragmentos corretos, ele reescreve o plano de consulta para fazer referência a tabelas de fragmentos em vez da tabela original. As tabelas de estilhaços combinam o nome da tabela original com o shardid. Por exemplo, suponha que você emita uma UPDATE consulta na tabela do Woodgrove Bank e é determinado que a 102104 de estilhaços payment_events contém a linha a ser atualizada. Nesse caso, a consulta na payment_events tabela será reescrita para o destino payment_events_102027 em vez de payment_events.
O planejador divide a consulta em uma consulta de coordenador (que é executada no coordenador) e fragmentos de consulta de trabalho (que são executados em fragmentos individuais). Os fragmentos de consulta são atribuídos aos trabalhadores para permitir que seus recursos sejam usados de forma eficiente.

O fragmento de consulta modifica o nome da tabela na consulta original para adicionar um sublinhado seguido pelo ID do estilhaço. Os fragmentos de consulta são então enviados para os nós de trabalho para execução.
A etapa final é o coordenador passar o plano de consulta distribuída para o executor distribuído para execução.
O que é o executor de consulta distribuída?
O Azure Cosmos DB para PostgreSQL usa um executor de consulta distribuída para dividir consultas SQL regulares e executá-las em paralelo em nós de trabalho próximos aos dados. O executor de consulta distribuída é responsável por executar planos de consulta distribuída e lidar com quaisquer falhas.
O executor de consulta distribuída é otimizado para obter respostas rápidas a consultas que envolvem filtros, agregações e junções colocalizadas e executar consultas de locatário único com cobertura SQL completa. A execução de consultas de vários estilhaços requer o equilíbrio dos ganhos do paralelismo com a sobrecarga de gerenciamento de conexões de banco de dados. O executor de consulta cria um pool de conexões para cada sessão, abre uma conexão por fragmento para os trabalhadores, conforme necessário, e envia todas as consultas de fragmento para eles. Em seguida, ele busca os resultados de cada consulta de fragmento, mescla-os e envia os resultados finais de volta para o usuário.

No diagrama, as sessões de consulta são fragmentadas pelo nó coordenador e adicionadas a uma fila de tarefas. Os fragmentos de consulta são então enviados para pools de conexões de sessão para execução em nós de trabalho.
Use EXPLAIN para entender a execução da consulta
O coordenador particiona uma consulta de entrada em consultas de fragmento e as envia aos trabalhadores para processamento paralelo. Os trabalhadores são apenas servidores PostgreSQL e aplicam a lógica padrão de planejamento e execução do PostgreSQL para essas consultas. Para entender melhor como os planos de execução são gerados e executados, você pode usar o EXPLAIN comando.
EXPLAIN pode ajudá-lo a obter informações sobre o desempenho da consulta e exibir informações sobre o planejamento da execução da consulta. A EXPLAIN saída mostra como cada trabalhador processa a consulta e fornece alguns detalhes sobre como o nó coordenador combina seus resultados.
Para seu painel, o Woodgrove Bank gostaria de uma consulta que lhes permitisse visualizar o número de eventos por tipo por usuário, que eles também podem filtrar no event_type. O exemplo a seguir explica o plano para a consulta que você criou. Você também pode ver as consultas reais enviadas aos nós de trabalho incluindo o VERBOSE sinalizador.
EXPLAIN VERBOSE
SELECT e.user_id, login, event_type, COUNT(event_id) AS event_count
FROM payment_events AS e
LEFT JOIN payment_users AS u ON e.user_id = u.user_id
WHERE event_type = 'GiftFunds'
GROUP BY e.user_id, login, event_type
ORDER BY event_count DESC
LIMIT 10;
A saída da instrução fornece detalhes sobre como a consulta é executada entre nós que você pode usar para otimizar a consulta usando parâmetros de servidor da EXPLAIN VERBOSE seguinte maneira:
Limit (cost=2160.96..2160.99 rows=10 width=80)
Output: remote_scan.user_id, remote_scan.login, remote_scan.event_type, remote_scan.event_count
-> Sort (cost=2160.96..2410.96 rows=100000 width=80)
Output: remote_scan.user_id, remote_scan.login, remote_scan.event_type, remote_scan.event_count
Sort Key: remote_scan.event_count DESC
-> Custom Scan (Citus Adaptive) (cost=0.00..0.00 rows=100000 width=80)
Output: remote_scan.user_id, remote_scan.login, remote_scan.event_type, remote_scan.event_count
Task Count: 32
Tasks Shown: One of 32
-> Task
Query: SELECT worker_column_1 AS user_id, worker_column_2 AS login, worker_column_3 AS event_type, count(worker_column_4) AS event_count FROM (SELECT e.user_id AS worker_column_1, u.login AS worker_column_2, e.event_
type AS worker_column_3, e.event_id AS worker_column_4 FROM (public.payment_events_102232 e LEFT JOIN public.payment_users_102264 u ON ((e.user_id OPERATOR(pg_catalog.=) u.user_id))) WHERE (e.event_type OPERATOR(pg_catalog.=) 'GiftFunds'
::text)) worker_subquery GROUP BY worker_column_1, worker_column_2, worker_column_3 ORDER BY (count(worker_column_4)) DESC LIMIT '10'::bigint
Node: host=private-w0.learn-cosmosdb-postgresql.postgres.database.azure.com port=5432 dbname=citus
-> Limit (cost=498.14..498.16 rows=10 width=37)
Output: e.user_id, u.login, e.event_type, (count(e.event_id))
-> Sort (cost=498.14..498.88 rows=298 width=37)
Output: e.user_id, u.login, e.event_type, (count(e.event_id))
Sort Key: (count(e.event_id)) DESC
-> HashAggregate (cost=488.72..491.70 rows=298 width=37)
Output: e.user_id, u.login, e.event_type, count(e.event_id)
Group Key: e.user_id, u.login, e.event_type
-> Hash Left Join (cost=334.93..485.74 rows=298 width=37)
Output: e.user_id, u.login, e.event_type, e.event_id
Inner Unique: true
Hash Cond: (e.user_id = u.user_id)
-> Seq Scan on public.payment_events_102232 e (cost=0.00..150.03 rows=298 width=27)
Output: e.event_id, e.event_type, e.user_id, e.merchant_id, e.event_details, e.created_at
Filter: (e.event_type = 'GiftFunds'::text)
-> Hash (cost=231.08..231.08 rows=8308 width=18)
Output: u.login, u.user_id
-> Seq Scan on public.payment_users_102264 u (cost=0.00..231.08 rows=8308 width=18)
Output: u.login, u.user_id
A EXPLAIN saída da instrução revela várias coisas sobre o plano de execução da consulta. Começando com a linha de verificação personalizada, você pode ver que o planejador escolheu o executor Citus Adaptive para executar essa consulta. A contagem de tarefas revela que há 32 fragmentos e você está visualizando uma das 32 tarefas na saída.
-> Custom Scan (Citus Adaptive) (cost=0.00..0.00 rows=100000 width=80)
Output: remote_scan.user_id, remote_scan.login, remote_scan.event_type, remote_scan.event_count
Task Count: 32
Tasks Shown: One of 32
Em seguida, EXPLAIN seleciona um dos trabalhadores e mostra um exemplo representativo de como a consulta se comporta nos nós de trabalho. Ele indica o nó de trabalho (host, porta e nome do banco de dados) e inclui o fragmento de consulta executado pelo trabalhador:
-> Task
Query: SELECT worker_column_1 AS user_id, worker_column_2 AS login, worker_column_3 AS event_type, count(worker_column_4) AS event_count FROM (SELECT e.user_id AS worker_column_1, u.login AS worker_column_2, e.event_ type AS worker_column_3, e.event_id AS worker_column_4 FROM (public.payment_events_102232 e LEFT JOIN public.payment_users_102264 u ON ((e.user_id OPERATOR(pg_catalog.=) u.user_id))) WHERE (e.event_type OPERATOR(pg_catalog.=) 'GiftFunds'::text)) worker_subquery GROUP BY worker_column_1, worker_column_2, worker_column_3 ORDER BY (count(worker_column_4)) DESC LIMIT '10'::bigint
Node: host=private-w0.learn-cosmosdb-postgresql.postgres.database.azure.com port=5432 dbname=citus
Após os detalhes do nó de trabalho, você pode exibir os resultados da execução de um comando PostgreSQL EXPLAIN padrão nesse trabalhador para a consulta de fragmento:
-> Limit (cost=498.14..498.16 rows=10 width=37)
Output: e.user_id, u.login, e.event_type, (count(e.event_id))
-> Sort (cost=498.14..498.88 rows=298 width=37)
Output: e.user_id, u.login, e.event_type, (count(e.event_id))
Sort Key: (count(e.event_id)) DESC
-> HashAggregate (cost=488.72..491.70 rows=298 width=37)
Output: e.user_id, u.login, e.event_type, count(e.event_id)
Group Key: e.user_id, u.login, e.event_type
-> Hash Left Join (cost=334.93..485.74 rows=298 width=37)
Output: e.user_id, u.login, e.event_type, e.event_id
Inner Unique: true
Hash Cond: (e.user_id = u.user_id)
-> Seq Scan on public.payment_events_102232 e (cost=0.00..150.03 rows=298 width=27)
Output: e.event_id, e.event_type, e.user_id, e.merchant_id, e.event_details, e.created_at
Filter: (e.event_type = 'GiftFunds'::text)
-> Hash (cost=231.08..231.08 rows=8308 width=18)
Output: u.login, u.user_id
-> Seq Scan on public.payment_users_102264 u (cost=0.00..231.08 rows=8308 width=18)
Output: u.login, u.user_id
Movimentação de dados para execução de subconsultas
O Azure Cosmos DB para PostgreSQL também pode coletar resultados de subconsultas e CTEs (expressões de tabela comuns) no nó coordenador e, em seguida, enviá-los de volta entre os trabalhadores para uso por uma consulta externa. Esse recurso fornece suporte para uma maior variedade de construções SQL.
Para saber mais sobre como você pode usar a instrução para exibir consultas com subplanos distribuídos, consulte a EXPLAIN documentação do Citus Query Processing.
Alcance o máximo desempenho de consulta ajustando os parâmetros do servidor
Vários parâmetros de servidor afetam o comportamento do seu banco de dados. Você pode usar esses parâmetros para ajustar seu cluster para obter o máximo desempenho. Você pode manipular os valores dos parâmetros do servidor usando instruções SQL ou no portal do Azure. Na categoria Definições, escolha os parâmetros do Nó de trabalho ou do Nó de coordenação. Essas páginas permitem que você defina parâmetros para todos os nós de trabalho ou apenas para o nó coordenador.
Você pode encontrar informações detalhadas sobre todos os parâmetros de servidor disponíveis na documentação de parâmetros do servidor. A documentação da API do Azure Cosmos DB para PostgreSQL também fornece agrupamentos lógicos de parâmetros de servidor por função.
A primeira etapa no processo de ajuste é executar o EXPLAIN comando do nó coordenador em consultas de representantes para inspecionar seu desempenho. As informações derivadas podem EXPLAIN ajudá-lo a entender quais parâmetros ajustar. O ajuste dos parâmetros do nó de trabalho geralmente é o local para começar ao tentar otimizar o desempenho da consulta. Você pode alterar valores de parâmetros em nós de trabalho usando a página Parâmetros do nó de trabalho no portal do Azure ou conectando-se diretamente ao nó de trabalho usando o nome de domínio e a porta totalmente qualificados do trabalhador.
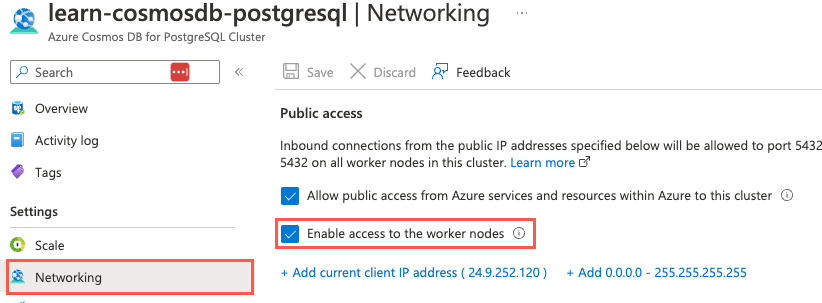
Nota
A conexão direta aos nós de trabalho exige que você marque a caixa de seleção Habilitar acesso aos nós de trabalho na página Rede do seu recurso do Azure Cosmos DB para PostgreSQL no portal do Azure.
O ajuste dos parâmetros do servidor requer experimentação e, muitas vezes, requer várias tentativas para alcançar um desempenho aceitável. Ao fazer alterações, execute EXPLAIN novamente a partir do coordenador ou diretamente no trabalhador para avaliar o efeito da modificação. Como recomendação geral, é melhor ajustar iterativamente seu banco de dados usando apenas uma pequena parte dos dados. Depois de ajustar um trabalhador para atingir o desempenho desejado, você deve aplicar manualmente essas alterações aos outros trabalhadores do cluster.
Os clusters no Azure Cosmos DB para PostgreSQL são configurados com configurações de recursos conservadoras por padrão. Entre essas configurações, shared_buffers e work_mem são provavelmente os parâmetros mais críticos na otimização do desempenho de leitura. Esses parâmetros são brevemente discutidos abaixo. Além dessas configurações, vários outros parâmetros de configuração podem afetar o desempenho da consulta. Você pode saber mais sobre essas configurações com mais detalhes na documentação da Microsoft.
Otimize o desempenho de leitura
O shared_buffers parâmetro PostgreSQL define a quantidade de memória alocada ao banco de dados para armazenar dados em cache. O valor padrão para essa configuração é 128 MB. Se você tiver um nó de trabalho com 1 GB ou mais de RAM, um valor inicial razoável para shared_buffers é 25% da memória do sistema. Existem algumas cargas de trabalho em que configurações ainda maiores são shared_buffers vantajosas. No entanto, dado que o Azure Cosmos DB para PostgreSQL também depende do cache do sistema operacional, é improvável que você descubra que usar mais de 25% da RAM oferece benefícios extras de desempenho.
Aumentar a memória de trabalho
Se seus padrões de consulta comuns incluírem muitas classificações complexas, aumentar a work_mem permitirá que o banco de dados execute classificações maiores na memória, o que é mais rápido do que equivalentes baseados em disco. O work_mem parâmetro define a quantidade de memória usada por operações de classificação internas e tabelas de hash antes de gravar em arquivos de disco temporários. Se você tiver alta atividade de E/S de disco no nó de trabalho, apesar de ter uma quantidade razoável de memória, aumentar work_mem para um valor mais alto pode ser benéfico. Aumentar work_mem ajudará a gerar planos de consulta mais eficientes e permitirá que mais operações ocorram na memória.
Além das shared_buffers configurações e work_mem parâmetros, o planejador de execução de consultas se baseia em informações estatísticas sobre o conteúdo das tabelas para gerar bons planos. Estas estatísticas são recolhidas quando ANALYZE é executada. Esta funcionalidade está ativada por predefinição.
Ajuste o gerenciamento de conexões
O número de conexões simultâneas que podem ser abertas por consultas individuais é restrito pelo parâmetro server citus.max_adaptive_executor_pool_size (integer) . O valor padrão para essa configuração é 16, mas é configurável no nível da sessão para gerenciamento de prioridades. Você deve definir citus.max_adaptive_executor_pool_size (integer) como um valor baixo, como 1 ou 2, para cargas de trabalho transacionais com consultas de execução curta (por exemplo, < 20 ms de latência). Deixe essa configuração em seu valor padrão para cargas de trabalho analíticas onde o paralelismo é crítico.
É mais rápido executar tarefas sequencialmente na mesma conexão para tarefas curtas em vez de estabelecer novas conexões para serem executadas em paralelo. As tarefas de longa duração, por outro lado, beneficiam de um paralelismo mais imediato. Para equilibrar as necessidades de tarefas de curta e longa execução, o Azure Cosmos DB para PostgreSQL usa o citus.executor_slow_start_interval (integer) parâmetro. Essa configuração especifica um atraso entre as tentativas de conexão para as tarefas em uma consulta de vários estilhaços. Quando uma consulta enfileira tarefas pela primeira vez, as tarefas podem adquirir apenas uma conexão. No final de cada intervalo em que há conexões pendentes, o coordenador aumenta o número de conexões abertas simultâneas. Você deve definir citus.executor_slow_start_interval (integer) um valor alto como 100 ms para cargas de trabalho transacionais compostas por consultas curtas vinculadas à latência da rede em vez de paralelismo. Para cargas de trabalho analíticas, deixe essa configuração em seu valor padrão de 10 ms. Você também pode desativar totalmente o comportamento de inicialização lenta definindo seu valor como 0.
Quando uma tarefa termina usando uma conexão, o pool de sessões mantém a conexão aberta para acelerar os comandos subsequentes. Armazenar em cache a conexão evita a sobrecarga do restabelecimento da conexão entre o coordenador e o trabalhador. No entanto, cada pool não manterá mais do que conexões ociosas abertas de uma só vez, para limitar o uso de citus.max_cached_conns_per_worker (integer) recursos de conexão ociosa no trabalhador. Aumentar esse valor reduz a latência de consultas de vários estilhaços, mas também aumentará a sobrecarga sobre os trabalhadores. O valor padrão de 1 for citus.max_cached_conns_per_worker (integer) é razoável. Um valor maior, como 2, pode ser útil para clusters que usam algumas sessões simultâneas, mas não é recomendado ir muito além (por exemplo, 16 seria muito alto). Se definidas como muito altas, as sessões mantêm desnecessariamente conexões ociosas e usam recursos de trabalho.
O banco de dados do Woodgrove Bank é usado para cargas de trabalho transacionais e analíticas. A maneira mais eficaz de ajustar os parâmetros de conexão é seguir uma abordagem iterativa, modificar valores de parâmetros e observar o efeito da alteração. Para cada caso de uso, você observará o efeito que a alteração tem nas consultas e identificará as configurações que melhor atendem às suas necessidades.