Treinando uma rede neural densa
- 10 minutos
O reconhecimento de dígitos manuscritos é um problema de classificação. Começamos com a abordagem mais simples possível para a classificação de imagens – uma rede neural totalmente conectada com uma única camada treinável (também chamada perceptrão de camada única; versões de múltiplas camadas são conhecidas como perceptrões multicamadas). Primeiro, vamos começar por carregar e normalizar rapidamente o conjunto de dados, como fizemos na unidade anterior:
import keras
import matplotlib.pyplot as plt
import numpy as np
(x_train, y_train), (x_test, y_test) = keras.datasets.mnist.load_data()
x_train = x_train.astype(np.float32) / 255.0
x_test = x_test.astype(np.float32) / 255.0
Redes neurais densas totalmente conectadas
Uma rede neural básica consiste em muitas camadas. A rede mais simples incluiria apenas uma camada totalmente ligada, chamada camada densa , com 784 entradas (uma entrada para cada pixel da imagem de entrada) e 10 saídas (uma saída para cada classe). Chama-se denso porque contém todas as possíveis ligações entre 784 entradas e 10 saídas, dando 7.840 pesos de ligação mais 10 termos de polarização, totalizando 7.850 parâmetros treináveis.
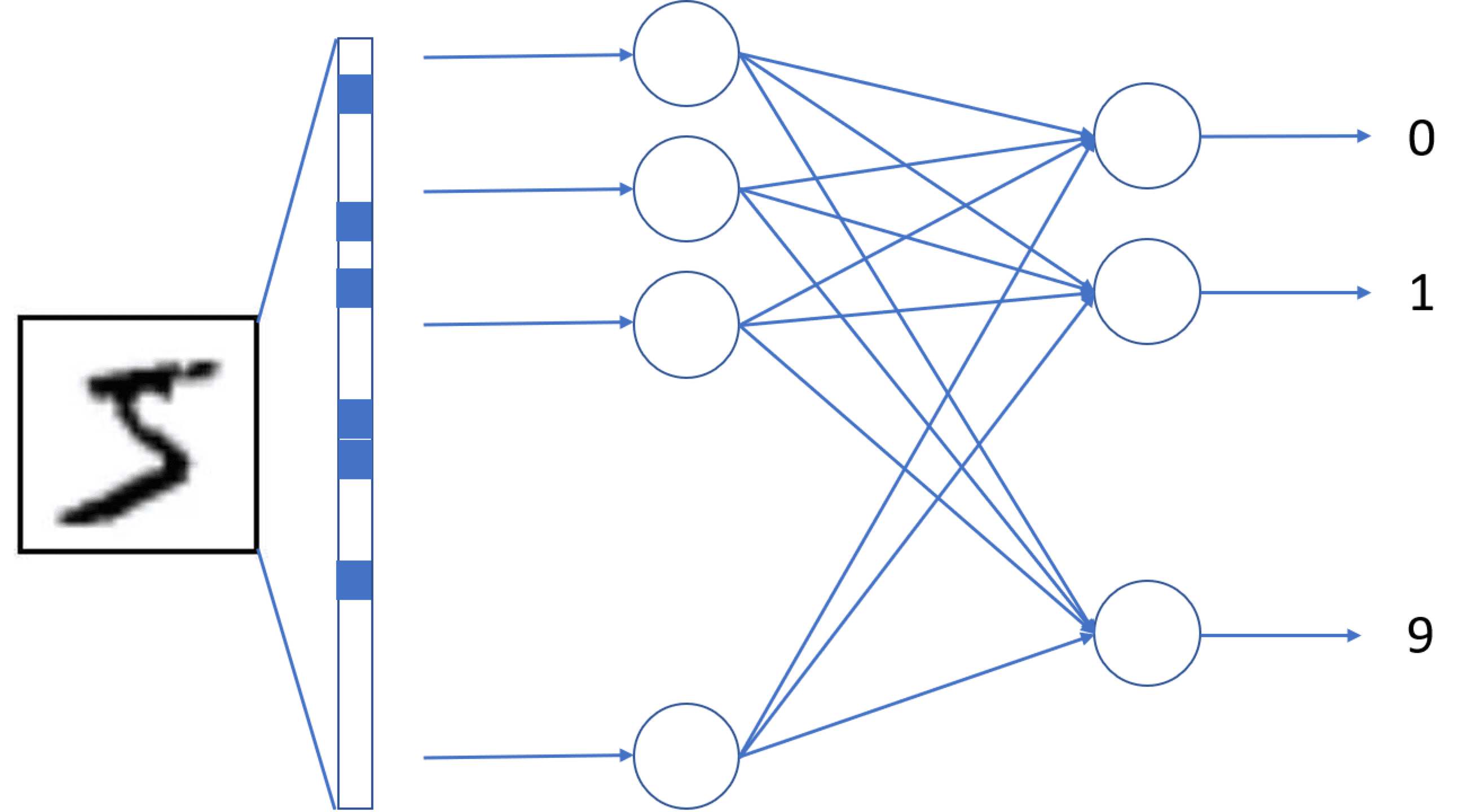
No entanto, os nossos dados de entrada surgem sob a forma de matrizes 28×28, enquanto uma entrada de rede precisa de ser um vetor unidimensional com comprimento 784. Assim, a primeira camada da rede seria uma Flatten camada que converte 28×28 píxeis num vetor.
A saída da rede deve ser de 10 números, um para cada classe. Cada número representa a probabilidade de o dígito de entrada ser da classe correspondente. A função final de ativação chamada Softmax é usada para garantir que o vetor de saída é normalizado, ou seja, a soma de todos os valores é igual a 1.
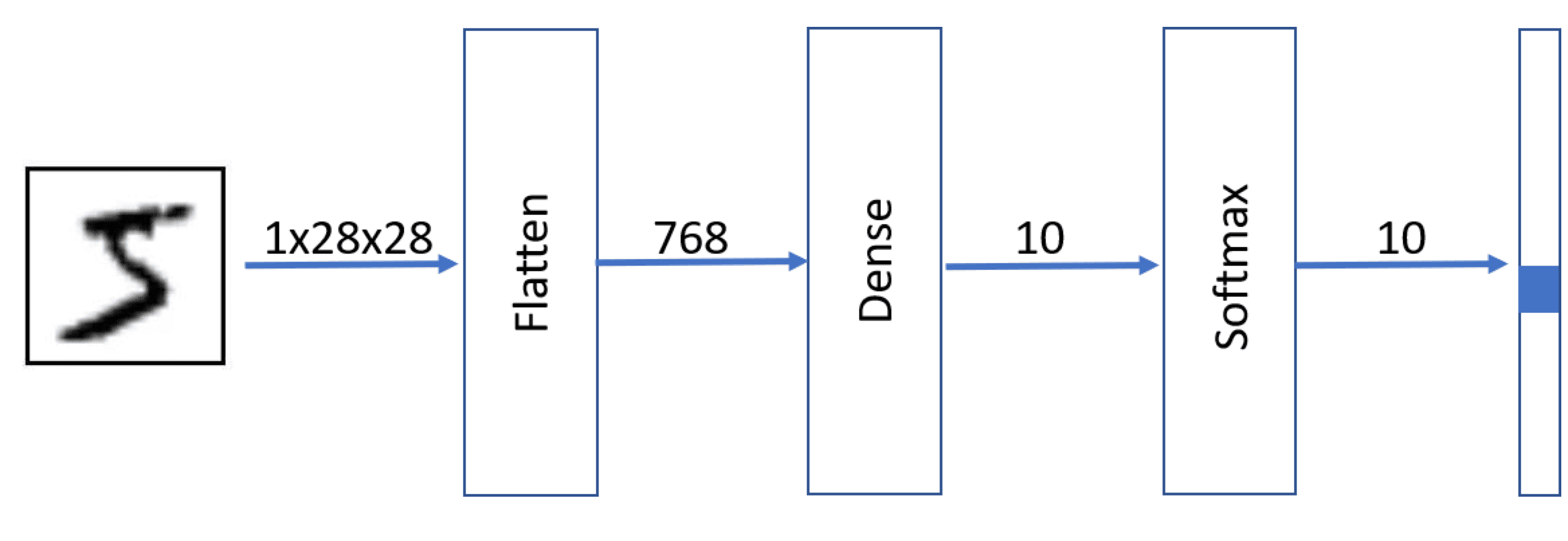
Pode ser definido em Keras da seguinte forma, usando Sequential sintaxe:
model = keras.Sequential([
keras.layers.Input(shape=(28, 28)),
keras.layers.Flatten(),
keras.layers.Dense(10, activation='softmax')
])
model.summary()
# Expected output: a model summary table showing the Flatten and Dense layers
# Total params: 7,850 (784 inputs * 10 outputs + 10 biases)
# Note: the Input and Flatten layers have zero trainable parameters
O summary método imprime a arquitetura da rede, incluindo as suas camadas, formas de saída e número de parâmetros. As camadas Input e Flatten contribuem com zero parâmetros treináveis. Todos os 7.850 parâmetros pertencem à camada única Dense . O Input parâmetro da shape camada indica à rede as dimensões esperadas dos dados de entrada.
Anatomia de uma camada densa
Repare que o modelo tem 7.850 parâmetros. Isto deve-se ao facto de a camada densa implementar uma função linear y = W×x + b, onde W é uma matriz de pesos 784×10 e b é um vetor de viés de 10 dimensões. Cada ligação entre um neurónio de entrada e um de saída tem um peso correspondente em W, e cada neurónio de saída tem um termo de viés adicional.
Pode inspecionar estes pesos diretamente:
model.layers[1].weights
# Expected output: a list containing two tensors:
# - kernel (weight matrix) of shape (784, 10)
# - bias vector of shape (10,)
A weights propriedade devolve o núcleo (matriz de pesos) e o vetor de viés da camada.
Formação da rede
Antes de treinar, vamos ver o que acontece quando passamos uma imagem por uma rede não treinada:
print('Digit to be predicted: ', y_train[0])
model(np.expand_dims(x_train[0], 0))
# Expected output: the true label of the first training image (e.g., 5),
# followed by a tensor of 10 roughly equal probabilities (~0.1 each)
Como a rede ainda não está treinada, as probabilidades de saída são aproximadamente iguais para todas as classes. O resultado é devolvido como um tensor.
Para treinar a rede, primeiro precisamos de preparar os nossos rótulos e compilar o modelo.
A função de perda que usamos, categorical_crossentropy, requer que as etiquetas sejam codificadas one-hot, o que significa que cada etiqueta é representada como um vetor de zeros com um único um na posição da classe correta. Na unidade seguinte veremos sparse_categorical_crossentropy, que aceita etiquetas inteiras diretamente e evita este passo de conversão. Vamos primeiro converter os nossos rótulos:
y_train_onehot = keras.utils.to_categorical(y_train)
y_test_onehot = keras.utils.to_categorical(y_test)
print("First 3 training labels:", y_train[:3])
print("One-hot-encoded version:\n", y_train_onehot[:3])
# Expected output: the first 3 integer labels (e.g., [5, 0, 4])
# and their one-hot representations as 10-element vectors
Agora compilamos o modelo, especificando o otimizador e a função de perda:
model.compile(optimizer='sgd', loss='categorical_crossentropy')
O otimizador (sgd = Descida Estocástica do Gradiente) controla como os pesos são ajustados durante o treinamento. A função de perda (categorical_crossentropy) mede a distância entre as probabilidades previstas e os verdadeiros rótulos one-hot.
Para realizar o treino propriamente dito, chamamos a função fit.
model.fit(x_train, y_train_onehot)
# Expected output: one epoch of training with loss decreasing over batches
Formação em monitorização
Por defeito, o modelo treina para uma época (uma passagem por todo o conjunto de treino). Para treinar para mais iterações e monitorizar o desempenho nos dados de teste, passamos validation_data e epochs:
Observação
Neste módulo, passamos o conjunto de testes como validation_data por simplicidade. Na prática, deve dividir os seus dados em três conjuntos (treino, validação e teste) para que o conjunto de teste permaneça invisível até à avaliação final.
hist = model.fit(x_train, y_train_onehot,
validation_data=(x_test, y_test_onehot),
epochs=3)
# Expected output: training and validation loss printed for each of the 3 epochs
A fit função devolve um history objeto que contém métricas de treino e validação para cada época, que podem ser usadas para visualização:
for x in ['loss', 'val_loss']:
plt.plot(hist.history[x])
# Expected output: a plot showing training and validation loss curves over epochs
Métricas e minibatches
Para além da perda, muitas vezes queremos monitorizar a precisão, a fração de exemplos corretamente classificados:
model.compile(optimizer='sgd', loss='categorical_crossentropy', metrics=['accuracy'])
hist = model.fit(x_train, y_train_onehot,
validation_data=(x_test, y_test_onehot),
epochs=3, batch_size=128)
# Expected output: training/validation loss and accuracy printed for each epoch
O batch_size parâmetro controla quantos exemplos de treino são processados antes de cada atualização de peso. Em vez de calcular o gradiente ao longo de todo o conjunto de dados, o treino utiliza minilotes (pequenos subconjuntos dos dados). Isto permite atualizações de peso mais frequentes e uma paralelização eficiente da GPU. O tamanho do lote é um dos hiperparâmetros que podes ajustar para melhorar o treino.
Especificação dos parâmetros do otimizador
O otimizador SGD básico pode ser melhorado ao adicionar momentum, o que ajuda a acelerar a descida do gradiente na direção relevante e a amortecer oscilações.
model = keras.Sequential([
keras.layers.Input(shape=(28, 28)),
keras.layers.Flatten(),
keras.layers.Dense(10, activation='softmax')
])
model.compile(optimizer=keras.optimizers.SGD(momentum=0.5),
loss='categorical_crossentropy',
metrics=['accuracy'])
hist = model.fit(x_train, y_train_onehot,
validation_data=(x_test, y_test_onehot),
epochs=5, batch_size=64)
# Expected output: training over 5 epochs with improving accuracy,
# momentum should help the model converge faster
for x in ['accuracy', 'val_accuracy']:
plt.plot(hist.history[x])
# Expected output: a plot showing training and validation accuracy curves over 5 epochs
Visualização de pesos de rede
Como a nossa rede mapeia 784 píxeis de entrada diretamente para 10 classes de saída, podemos remodelar a matriz de pesos de volta para 28×28 imagens, uma por classe de dígitos. Estas visualizações mostram que "padrão" a rede aprendeu a procurar em cada aula:
weight_tensor = model.layers[1].weights[0].numpy().reshape(28, 28, 10)
fig, ax = plt.subplots(1, 10, figsize=(15, 4))
for i in range(10):
ax[i].imshow(weight_tensor[:, :, i])
ax[i].axis('off')
# Expected output: 10 images showing the learned weight patterns for digits 0-9,
# each resembling a blurry version of the corresponding digit
Conclusão
Com uma única camada densa, podemos alcançar cerca de 91% de precisão no conjunto de dados MNIST. Embora esta seja uma base razoável, na próxima unidade exploraremos como adicionar mais camadas à rede pode melhorar os nossos resultados.