Redes neurais convolucionais
- 15 minutos
Na unidade anterior aprendemos a definir uma rede neural genérica de múltiplas camadas. Nesta unidade vamos aprender sobre Redes Neurais Convolucionais (CNNs), que são concebidas para visão computacional.
A visão computacional é diferente da classificação genérica, porque quando tentamos encontrar um determinado objeto na imagem, estamos a escanear a imagem à procura de padrões específicos e das suas combinações. Por exemplo, ao estarmos à procura de um gato, podemos primeiro procurar linhas horizontais, que podem formar bigodes, e depois, certas combinações de bigodes podem indicar-nos que se trata realmente de uma imagem de um gato. A posição e a presença de certos padrões são importantes. Para extrair padrões, vamos usar a noção de filtros convolucionais.
Mas primeiro, vamos carregar todas as dependências e definir as funções auxiliares que vamos usar:
import keras
import tensorflow as tf
import matplotlib.pyplot as plt
import numpy as np
def plot_convolution(data, t, title=''):
t = tf.constant(t, dtype=tf.float32)
t = tf.reshape(t, [*t.shape, 1, 1])
fig, ax = plt.subplots(len(data), 2)
fig.suptitle(title, fontsize=16)
for i in range(len(data)):
d = tf.reshape(tf.constant(data[i], dtype=tf.float32), [1, *data[i].shape, 1])
ax[i][0].imshow(data[i])
ax[i][1].imshow(tf.nn.conv2d(d, t, [1, 1, 1, 1], 'SAME')[0, ..., 0])
def plot_results(hist):
plt.figure(figsize=(12, 4))
plt.subplot(1, 2, 1)
plt.plot(hist.history['accuracy'], label='Training acc')
plt.plot(hist.history['val_accuracy'], label='Validation acc')
plt.legend()
plt.subplot(1, 2, 2)
plt.plot(hist.history['loss'], label='Training loss')
plt.plot(hist.history['val_loss'], label='Validation loss')
plt.legend()
def display_dataset(dataset, labels=None, n=10, classes=None):
fig, ax = plt.subplots(1, n)
for i in range(n):
ax[i].imshow(dataset[i])
ax[i].axis('off')
if labels is not None:
# Handle both scalar labels (e.g. MNIST) and array labels (e.g. CIFAR-10)
lbl = int(labels[i][0]) if np.ndim(labels[i]) > 0 else int(labels[i])
ax[i].set_title(classes[lbl] if classes is not None else str(lbl))
Agora vamos carregar o conjunto de dados MNIST:
(x_train, y_train), (x_test, y_test) = keras.datasets.mnist.load_data()
x_train = x_train.astype(np.float32) / 255.0
x_test = x_test.astype(np.float32) / 255.0
Filtros convolucionais
Os filtros convolucionais são pequenas janelas que percorrem cada pixel da imagem e calculam a média ponderada dos píxeis vizinhos. São definidos por matrizes de coeficientes de peso. Vamos ver exemplos de aplicação de dois filtros convolucionais diferentes sobre os nossos dígitos manuscritos do MNIST:
plot_convolution(x_train[:5], [[-1., 0., 1.], [-1., 0., 1.], [-1., 0., 1.]], 'Vertical edge filter')
plot_convolution(x_train[:5], [[-1., -1., -1.], [0., 0., 0.], [1., 1., 1.]], 'Horizontal edge filter')
# Expected output: Two sets of images showing original digits alongside the result of applying vertical and horizontal edge filters
O primeiro filtro chama-se filtro de borda vertical, e é definido pela seguinte matriz: $$ \left( \begin{matrix} -1 & 0 & 1 \ -1 & 0 & 1 \ -1 & 0 & 1 \ \ end {matrix} \right) $$ Quando este filtro desliza por uma região relativamente uniforme de píxeis, a soma ponderada produzida pela convolução é próxima de 0, porque os pesos positivo e negativo se anulam. Quando encontra uma aresta vertical (onde as intensidades dos píxeis mudam bruscamente da esquerda para a direita), a convolução produz um valor positivo ou negativo elevado. É por isso que, nas imagens acima, podes ver as bordas verticais realçadas por valores altos e baixos, enquanto as arestas horizontais são suavizadas.
Acontece o contrário quando aplicamos um filtro de borda horizontal – as linhas horizontais são amplificadas e as verticais são mediadas.
Na visão computacional clássica, múltiplos filtros eram aplicados à imagem para gerar características, que depois eram usadas por algoritmos de aprendizagem automática para construir um classificador. Na aprendizagem profunda, construímos redes que aprendem os melhores filtros convolucionais para resolver problemas de classificação por si só.
Para isso, introduzimos camadas convolucionais.
Camadas convolucionais
Camadas convolucionais são definidas usando Conv2D classes. Precisamos de especificar o seguinte:
-
filters- Número de filtros a usar. Vamos usar 9 filtros diferentes, o que dará à rede muitas oportunidades para explorar quais os filtros que funcionam melhor para o nosso cenário. -
kernel_sizeé o tamanho da janela deslizante. Normalmente são usados filtros 3x3 ou 5x5.
A CNN mais simples contém apenas uma camada convolucional. Dado o tamanho de entrada 28x28, depois de aplicar nove filtros 5x5 acabaremos com um tensor de 24x24x9. A dimensão espacial é menor porque o padrão padding='valid' significa que não é adicionado preenchimento e existem apenas 24 posições onde uma janela deslizante de tamanho 5 pode caber dentro de 28 píxeis (28 − 5 + 1 = 24). Usar padding='same' preservaria as dimensões espaciais ao adicionar zero-padding à volta da entrada.
Após a convolução, achatamos o tensor 24×24×9 num único vetor de tamanho 5184, depois adicionamos uma camada densa para produzir 10 classes. A relu função de ativação é aplicada após a camada convolucional para introduzir a não linearidade.
model = keras.Sequential([
keras.layers.Input(shape=(28, 28, 1)),
keras.layers.Conv2D(filters=9, kernel_size=(5, 5), activation='relu'),
keras.layers.Flatten(),
keras.layers.Dense(10)
])
model.compile(loss=keras.losses.SparseCategoricalCrossentropy(from_logits=True), metrics=['accuracy'])
model.summary()
# Expected output: Model summary showing a Conv2D layer, Flatten, and Dense(10) with ~52k parameters
Pode ver que esta rede contém cerca de 52k parâmetros treináveis (234 na camada convolucional + 51.850 na camada densa), comparado com cerca de 80k em redes totalmente conectadas e multicamadas. As redes convolucionais generalizam melhor, o que nos permite obter bons resultados em conjuntos de dados mais pequenos.
Observação
Na maioria dos casos práticos, queremos aplicar camadas convolucionais a imagens a cores. Assim, Conv2D a camada espera que a entrada tenha a forma $H×W×C$, onde $H$ e $W$ são a altura e largura da imagem, e $C$ é o número de canais de cor. Para imagens em tons de cinza, precisamos da mesma forma com $C=1$.
Precisamos de reformular os nossos dados antes de começar o treino:
x_train_c = np.expand_dims(x_train, 3)
x_test_c = np.expand_dims(x_test, 3)
hist = model.fit(x_train_c, y_train, validation_data=(x_test_c, y_test), epochs=3)
# Expected output: Training for 3 epochs showing loss and accuracy for training and validation sets
plot_results(hist)
# Expected output: Plots showing training and validation accuracy and loss over 3 epochs
Como pode ver, conseguimos alcançar maior precisão com menos épocas em comparação com as redes totalmente conectadas da unidade anterior. No entanto, o treino em si requer mais recursos e pode ser mais lento em computadores sem GPU.
Visualização de camadas convolucionais
Também podemos visualizar os pesos das nossas camadas convolucionais treinadas para tentar compreender melhor o que está a acontecer:
fig, ax = plt.subplots(1, 9)
l = model.layers[0].weights[0]
for i in range(9):
ax[i].imshow(l[..., 0, i])
ax[i].axis('off')
# Expected output: 9 small images showing the learned 5x5 convolutional filter weights
Pode ver que alguns desses filtros parecem reconhecer traços oblíquos, enquanto outros parecem aleatórios.
CNNs multicamadas e camadas de pooling
Primeiro, as camadas convolucionais procuram padrões primitivos, como linhas horizontais ou verticais. Podemos aplicar camadas convolucionais adicionais por cima delas para procurar padrões de nível superior, como formas primitivas. Depois, camadas mais convolucionais podem combinar essas formas em algumas partes da imagem, até ao objeto final que estamos a tentar classificar.
Ao fazê-lo, podemos também aplicar um truque: reduzir o tamanho espacial da imagem. Depois de detetarmos que há um traço horizontal dentro da janela deslizante 3x3, já não é tão importante em qual pixel exato ocorreu. Assim, podemos "reduzir" o tamanho da imagem, o que é feito usando uma das camadas de pooling:
- Average Pooling usa uma janela deslizante (por exemplo, 2x2 píxeis) e calcula a média dos valores dentro da janela
- Max Pooling substitui a janela pelo valor máximo. A ideia por trás do max pooling é detectar a presença de um determinado padrão dentro da janela deslizante.
Assim, numa CNN típica haveria várias camadas convolucionais, com camadas de acumulação entre elas para diminuir as dimensões da imagem. Também aumentaríamos o número de filtros, porque à medida que os padrões se tornam mais avançados, há mais combinações interessantes possíveis que precisamos de procurar.
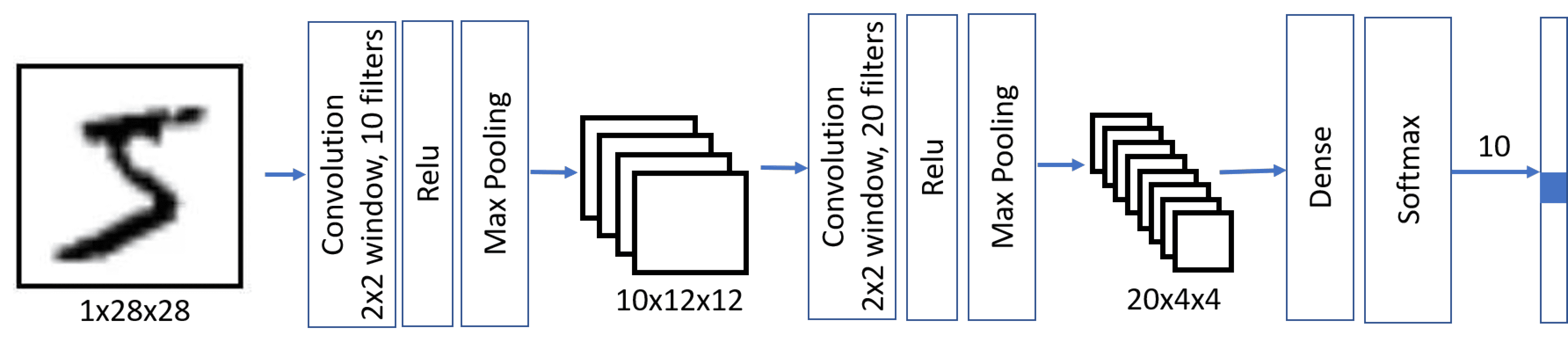
Esta arquitetura é também chamada arquitetura de pirâmide devido à diminuição das dimensões espaciais e ao aumento das dimensões das características/filtros.
model = keras.Sequential([
keras.layers.Input(shape=(28, 28, 1)),
keras.layers.Conv2D(filters=10, kernel_size=(5, 5), activation='relu'),
keras.layers.MaxPooling2D(),
keras.layers.Conv2D(filters=20, kernel_size=(5, 5), activation='relu'),
keras.layers.MaxPooling2D(),
keras.layers.Flatten(),
keras.layers.Dense(10)
])
model.compile(loss=keras.losses.SparseCategoricalCrossentropy(from_logits=True), metrics=['accuracy'])
model.summary()
# Expected output: Model summary showing Conv2D, MaxPooling, Conv2D, MaxPooling, Flatten, Dense with ~8.5k parameters
Note-se que o número de parâmetros treináveis (~8,5K) é dramaticamente menor do que nos casos anteriores. Isto acontece porque as camadas convolucionais, em geral, têm poucos parâmetros, e a dimensionalidade da imagem antes de aplicar a camada densa final é reduzida.
hist = model.fit(x_train_c, y_train, validation_data=(x_test_c, y_test), epochs=3)
# Expected output: Training for 3 epochs showing loss and accuracy for training and validation sets
plot_results(hist)
# Expected output: Plots showing training and validation accuracy and loss over 3 epochs
Observe que conseguimos alcançar maior precisão com mais do que uma camada, e que é necessário um número menor de épocas. Significa que uma arquitetura de rede mais sofisticada precisa de menos dados para perceber o que se passa e extrair padrões genéricos das nossas imagens. No entanto, cada época envolve mais computação devido às operações convolucionais adicionais, pelo que o treino é mais rápido com uma GPU.
Brincando com imagens reais do conjunto de dados CIFAR-10
Embora o nosso problema de reconhecimento de dígitos escritos à mão possa parecer um problema de brinquedo, agora estamos prontos para algo mais sério. Vamos explorar um conjunto de dados mais avançado de imagens de diferentes objetos, chamado CIFAR-10. Contém 60k imagens 32x32, divididas em 10 classes.
Observação
A partir deste ponto, recarregamos x_train, y_train, x_test, e y_test com o conjunto de dados CIFAR-10, substituindo os dados MNIST usados anteriormente nesta unidade. As variáveis "expanded-dims" x_train_c e x_test_c já não são necessárias.
(x_train, y_train), (x_test, y_test) = keras.datasets.cifar10.load_data()
x_train = x_train.astype(np.float32) / 255.0
x_test = x_test.astype(np.float32) / 255.0
classes = ('plane', 'car', 'bird', 'cat',
'deer', 'dog', 'frog', 'horse', 'ship', 'truck')
display_dataset(x_train, y_train, classes=classes)
# Expected output: A row of 10 CIFAR-10 images with their class labels
Uma arquitetura clássica da CNN é a LeNet, proposta originalmente por Yann LeCun para reconhecimento manuscrito de dígitos. Vamos adaptá-lo para CIFAR-10. Segue os mesmos princípios que descrevemos acima, sendo a principal diferença 3 canais de cor de entrada em vez de 1.
model = keras.Sequential([
keras.layers.Input(shape=(32, 32, 3)),
keras.layers.Conv2D(filters=6, kernel_size=5, strides=1, activation='relu'),
keras.layers.MaxPooling2D(pool_size=2, strides=2),
keras.layers.Conv2D(filters=16, kernel_size=5, strides=1, activation='relu'),
keras.layers.MaxPooling2D(pool_size=2, strides=2),
keras.layers.Flatten(),
keras.layers.Dense(120, activation='relu'),
keras.layers.Dense(84, activation='relu'),
keras.layers.Dense(10)
])
model.summary()
# Expected output: Model summary showing the LeNet architecture with Conv2D, MaxPooling, Dense layers
Treinar esta rede corretamente demora um tempo significativo e deve ser feito com computação com GPU.
model.compile(optimizer='adam', loss=keras.losses.SparseCategoricalCrossentropy(from_logits=True), metrics=['accuracy'])
hist = model.fit(x_train, y_train, validation_data=(x_test, y_test), epochs=10)
# Expected output: Training for 10 epochs showing loss and accuracy for training and validation sets
plot_results(hist)
# Expected output: Plots showing training and validation accuracy and loss over 10 epochs
A precisão que conseguimos alcançar com apenas algumas épocas de treino é simplesmente aceitável. Lembre-se que o nosso problema é significativamente mais difícil do que a classificação de dígitos MNIST. Ultrapassar 60% de precisão é uma boa conquista num tempo de treino tão curto, embora modelos de última geração possam alcançar mais de 95% no CIFAR-10 usando arquiteturas mais profundas, aumento de dados e treino mais longo.
Conclusões
Nesta unidade, aprendemos o conceito principal por trás das redes neurais de visão computacional – redes convolucionais. As arquiteturas reais que alimentam a classificação de imagens, deteção de objetos e até redes de geração de imagens são todas baseadas em CNNs, apenas com mais camadas e alguns truques de treino adicionais.