Capture padrões com redes neurais recorrentes
Na unidade anterior, abordámos representações semânticas ricas do texto. A arquitetura que temos usado capta o significado agregado das palavras numa frase, mas não tem em conta a ordem das palavras, porque a operação de agregação que segue os embeddings remove esta informação do texto original. Como estes modelos não conseguem representar a ordem das palavras, não conseguem resolver tarefas mais complexas ou ambíguas, como geração de texto ou resposta a perguntas.
Para captar o significado de uma sequência de texto, utilizamos uma arquitetura de rede neural chamada rede neural recorrente, ou RNN. Ao usar uma RNN, passamos a frase pela rede um token de cada vez, e a rede produz um estado, que depois passamos novamente para a rede com o próximo token.
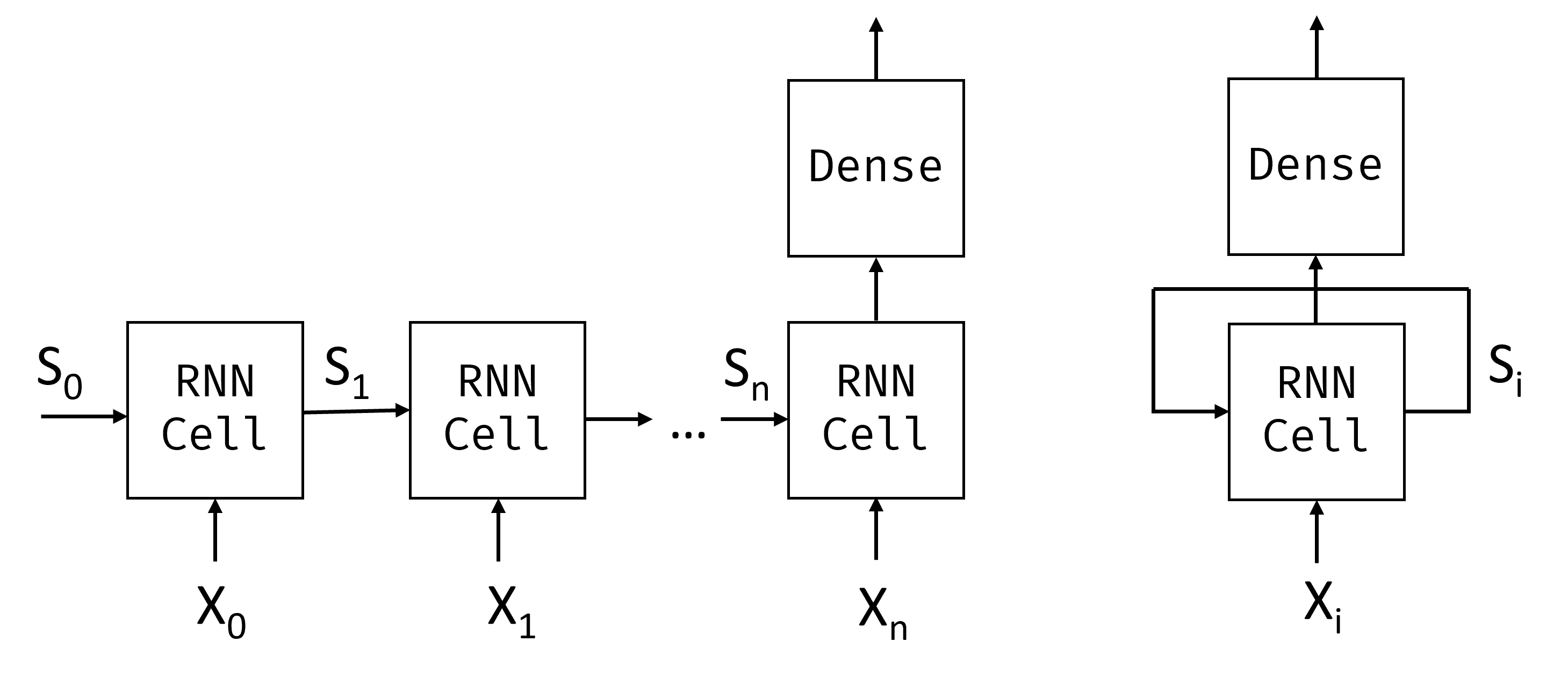
Dada a sequência de entrada de tokens $X_0,\dots,X_n$, a RNN cria uma sequência de blocos de rede neural e treina essa sequência de ponta a ponta usando retropropagação. Cada bloco de rede recebe um par $(X_i,S_i)$ como entrada, e produz $S_{i+1}$ como resultado. O estado final $S_n$ ou saída $Y_n$ vai para um classificador linear para produzir o resultado. Todos os blocos de rede partilham os mesmos pesos e são treinados de ponta a ponta usando uma passagem de retropropagação.
Como os vetores de estado $S_0,\dots,S_n$ são passados pela rede, a RNN consegue aprender dependências sequenciais entre palavras. Por exemplo, quando a palavra não aparece algures na sequência, pode aprender a negar certos elementos dentro do vetor de estado.
No interior, cada célula RNN contém duas matrizes de pesos: $W_H$ e $W_I$, e o viés $b$. Em cada passo RNN, dada a entrada $X_i$ e o estado de entrada $S_i$, o estado de saída é calculado como $S_{i+1} = f(W_H \times S_i + W_I \times X_i + b)$, onde $f$ é uma função de ativação (geralmente $\tanh$).
Observação
Com problemas como geração de texto ou tradução automática, também queremos obter algum valor de saída em cada passo RNN. Neste caso, existe também outra matriz $W_O$, e a saída é calculada como $Y_i=f(W_O\times S_{i+1}+b_O)$, onde $S_{i+1}$ é o estado atualizado a partir do passo atual.
Vamos ver como as redes neuronais recorrentes nos podem ajudar a classificar o nosso conjunto de dados de notícias com o seguinte código:
import tensorflow as tf
import keras
import tensorflow_datasets as tfds
import numpy as np
# We are going to be training pretty large models. In order not to face errors, we need
# to set tensorflow option to grow GPU memory allocation when required
physical_devices = tf.config.list_physical_devices('GPU')
if len(physical_devices)>0:
tf.config.set_memory_growth(physical_devices[0], True)
dataset = tfds.load('ag_news_subset')
ds_train = dataset['train']
ds_test = dataset['test']
Ao treinar modelos grandes, a alocação de memória da GPU pode tornar-se um problema. Também podemos precisar de experimentar diferentes tamanhos de minibatch, para que os dados caibam na memória da nossa GPU e o treino seja suficientemente rápido. Se estiveres a correr este código na tua própria máquina GPU, podes experimentar ajustar o tamanho do minibatch para acelerar o treino.
Observação
Sabe-se que certas versões dos drivers nVidia não libertam a memória após o treino do modelo. Estamos a executar vários exemplos nesta unidade, e isso pode fazer com que a memória se esgote em certas configurações, especialmente se estiveres a fazer as tuas próprias experiências. Se encontrar alguns erros invulgares ao começar a treinar o modelo, pode querer reiniciar o seu ambiente Python.
batch_size = 16
embed_size = 64
Classificador RNN simples
No caso de uma RNN simples, cada unidade recorrente é uma rede linear simples, que recebe um vetor de entrada e um vetor de estado, e produz um novo vetor de estado. Em Keras, isto pode ser representado pela SimpleRNN camada.
Embora possamos passar tokens codificados como one-hot diretamente para a camada RNN, isto não é uma boa ideia devido à sua elevada dimensionalidade. Por isso, usaremos uma camada de embedding para diminuir a dimensionalidade dos vetores de palavra, seguida de uma camada RNN e, finalmente, um Dense classificador.
Observação
Em casos em que a dimensionalidade não é tão elevada, por exemplo ao usar tokenização ao nível do caractere, pode fazer sentido utilizar tokens com codificação one-hot diretamente na célula RNN.
# We use a smaller vocabulary (20,000) here than in previous units because
# RNN models have more parameters per token, and a smaller vocabulary
# helps keep training time and memory usage manageable.
vocab_size = 20000
vectorizer = keras.layers.TextVectorization(max_tokens=vocab_size)
model = keras.Sequential([
keras.Input(shape=(1,), dtype=tf.string),
vectorizer,
keras.layers.Embedding(vocab_size, embed_size),
keras.layers.SimpleRNN(16),
keras.layers.Dense(4,activation='softmax')
])
model.summary()
Executar este código produz a seguinte saída:
Model: "sequential"
┏━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━┓
┃ Layer (type) ┃ Output Shape ┃ Param # ┃
┡━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━┩
│ text_vectorization │ (None, None) │ 0 │
│ (TextVectorization) │ │ │
├──────────────────────────────┼───────────────────────────┼───────────────┤
│ embedding (Embedding) │ (None, None, 64) │ 1,280,000 │
├──────────────────────────────┼───────────────────────────┼───────────────┤
│ simple_rnn (SimpleRNN) │ (None, 16) │ 1,296 │
├──────────────────────────────┼───────────────────────────┼───────────────┤
│ dense (Dense) │ (None, 4) │ 68 │
└──────────────────────────────┴───────────────────────────┴───────────────┘
Total params: 1,281,364 (4.89 MB)
Trainable params: 1,281,364 (4.89 MB)
Non-trainable params: 0 (0.00 B)
Observação
Estamos a usar aqui uma camada de embedding não treinada para simplificar, mas para melhores resultados podemos usar uma camada de embedding pré-treinada usando Word2Vec, como descrito na unidade anterior. Seria um bom exercício adaptares este código para funcionar com embeddings pré-treinados.
Agora vamos treinar a nossa RNN. As RNNs em geral são difíceis de treinar, porque, uma vez que as células RNN são desenroladas ao longo do comprimento da sequência, o número resultante de camadas envolvidas na retropropagação é grande. Assim, precisamos de selecionar uma taxa de aprendizagem menor e treinar a rede com um conjunto de dados maior para produzir bons resultados. Isto pode demorar bastante tempo, por isso é preferível usar uma GPU.
Para acelerar as coisas, vamos treinar o modelo RNN apenas em títulos de notícias, omitindo a descrição. Podes tentar treinar com descrição e ver se consegues que o modelo treine.
def extract_title(x):
return x['title']
def tupelize_title(x):
return (extract_title(x),x['label'])
print('Training vectorizer')
vectorizer.adapt(ds_train.take(2000).map(extract_title))
model.compile(loss='sparse_categorical_crossentropy',metrics=['acc'], optimizer='adam')
model.fit(ds_train.map(tupelize_title).batch(batch_size),validation_data=ds_test.map(tupelize_title).batch(batch_size))
Observação
A precisão provavelmente será menor aqui, porque estamos a treinar apenas com títulos de notícias.
Revisitar sequências de variáveis
Lembre-se que a TextVectorization camada irá automaticamente preencher sequências de comprimento variável num minibatch com tokens de pad. Acontece que esses tokens também participam do treinamento, e podem complicar a convergência do modelo.
Existem várias abordagens que podemos adotar para minimizar a quantidade de almofadamento. Uma delas é reordenar o conjunto de dados por comprimento de sequência e agrupar todas as sequências por tamanho. Isto pode ser feito usando a tf.data.bucket_by_sequence_length função (ver documentação).
Outra abordagem é usar mascaramento. Nos Keras, algumas camadas suportam entrada adicional que mostra quais os tokens que devem ser tidos em conta durante o treino. Para incorporar o mascaramento no nosso modelo, podemos incluir uma camada separada Masking (docs), ou podemos especificar o mask_zero=True parâmetro da nossa Embedding camada.
Observação
Ao usar mask_zero=True, o índice do token 0 é tratado como preenchimento e não é uma entrada válida no vocabulário. Isto significa que todos os índices de palavras do vocabulário são deslocados em uma unidade. A camada TextVectorization já reserva o índice 0 para preenchimento por padrão, por isso funciona perfeitamente quando ambas são usadas em conjunto.
def extract_text(x):
return x['title']+' '+x['description']
def tupelize(x):
return (extract_text(x),x['label'])
model = keras.Sequential([
keras.Input(shape=(1,), dtype=tf.string),
vectorizer,
keras.layers.Embedding(vocab_size,embed_size,mask_zero=True),
keras.layers.SimpleRNN(16),
keras.layers.Dense(4,activation='softmax')
])
model.compile(loss='sparse_categorical_crossentropy',metrics=['acc'], optimizer='adam')
model.fit(ds_train.map(tupelize).batch(batch_size),validation_data=ds_test.map(tupelize).batch(batch_size))
Agora que estamos a usar mascaramento, podemos treinar o modelo com todo o conjunto de dados de títulos e descrições.
LSTM: Long Short-Term Memory
Um dos principais problemas das RNNs são os gradientes que desaparecem. As RNNs podem ser longas e podem ter dificuldade em propagar os gradientes até à primeira camada da rede durante a retropropagação. Quando isto acontece, a rede não consegue aprender as relações entre tokens distantes. Uma forma de evitar este problema é introduzir uma gestão explícita de estados usando portas. As duas arquiteturas mais comuns que introduzem portas são a memória de curta e longa duração (LSTM) e a unidade recorrente com portas (GRU). Aqui cobrimos LSTMs.

Uma rede LSTM está organizada de forma semelhante a uma RNN, mas existem dois estados que são passados de camada em camada: o estado real $c$ e o vetor oculto $h$. Em cada unidade, o vetor oculto $h_{t-1}$ é combinado com a entrada $x_t$, e juntos controlam o que acontece ao estado $c_t$ e a saída $h_{t}$ através das portas. Cada porta tem ativação sigmoide (saída no intervalo $[0,1]$), que pode ser vista como uma máscara de bits quando multiplicada pelo vetor de estado. Os LSTM têm os seguintes portões (da esquerda para a direita na imagem acima, seguindo a convenção do blogue de Olah):
- porta de esquecimento , que determina quais componentes do vetor $c_{t-1}$ precisamos de esquecer e por quais passar.
- porta de entrada que determina quanta informação do vetor de entrada e do vetor oculto anterior deve ser incorporada no vetor de estado.
- porta de saída que toma o novo vetor de estado e decide quais dos seus componentes serão usados para produzir o novo vetor oculto $h_t$.
Os componentes do estado $c$ podem ser pensados como flags que podem ser ligados ou desligados. Por exemplo, quando encontramos o nome Alice na sequência, supõemos que se refere a uma mulher, e levantamos a bandeira no estado que diz que temos um substantivo feminino na frase. Quando encontrarmos as palavras e Tom, levantamos a bandeira que diz que temos um substantivo plural. Assim, ao manipular o estado, podemos acompanhar as propriedades gramaticais da frase.
Embora a estrutura interna de uma célula LSTM possa parecer complexa, o Keras esconde esta implementação dentro da LSTM camada, pelo que a única coisa que precisamos de fazer no exemplo acima é substituir a camada recorrente:
model = keras.Sequential([
keras.Input(shape=(1,), dtype=tf.string),
vectorizer,
keras.layers.Embedding(vocab_size, embed_size),
keras.layers.LSTM(8),
keras.layers.Dense(4,activation='softmax')
])
model.compile(loss='sparse_categorical_crossentropy',metrics=['acc'], optimizer='adam')
model.fit(ds_train.map(tupelize).batch(batch_size),validation_data=ds_test.map(tupelize).batch(batch_size))
Observação
Treinar LSTMs também é lento, e pode não se notar um grande aumento de precisão no início do treino. Pode ser necessário continuar a treinar durante algum tempo para alcançar boa precisão.
RNNs bidirecionais e multicamadas
Nos nossos exemplos até agora, as redes recorrentes operam desde o início até ao fim de uma sequência. Isto parece-nos natural porque segue a mesma direção em que lemos ou ouvimos a fala. No entanto, para cenários que requerem acesso aleatório à sequência de entrada, faz mais sentido executar o cálculo recorrente em ambas as direções. As RNNs que permitem cálculos em ambas as direções são chamadas RNNs bidirecionais , e podem ser criadas envolvendo a camada recorrente com uma camada especial Bidirectional .
Observação
A Bidirectional camada faz duas cópias da camada dentro dela e define a go_backwards propriedade de uma dessas cópias para True, fazendo-a seguir na direção oposta ao longo da sequência.
Redes recorrentes, unidirecionais ou bidirecionais, capturam padrões dentro de uma sequência e armazenam-nos em vetores de estado ou devolvem-nos como saída. Tal como nas redes convolucionais, podemos construir outra camada recorrente após a primeira para captar padrões de nível superior, construídos a partir de padrões de nível inferior extraídos pela primeira camada. Isto leva-nos à noção de RNN multicamada, que consiste em duas ou mais redes recorrentes, onde a saída da camada anterior é passada para a camada seguinte como entrada.
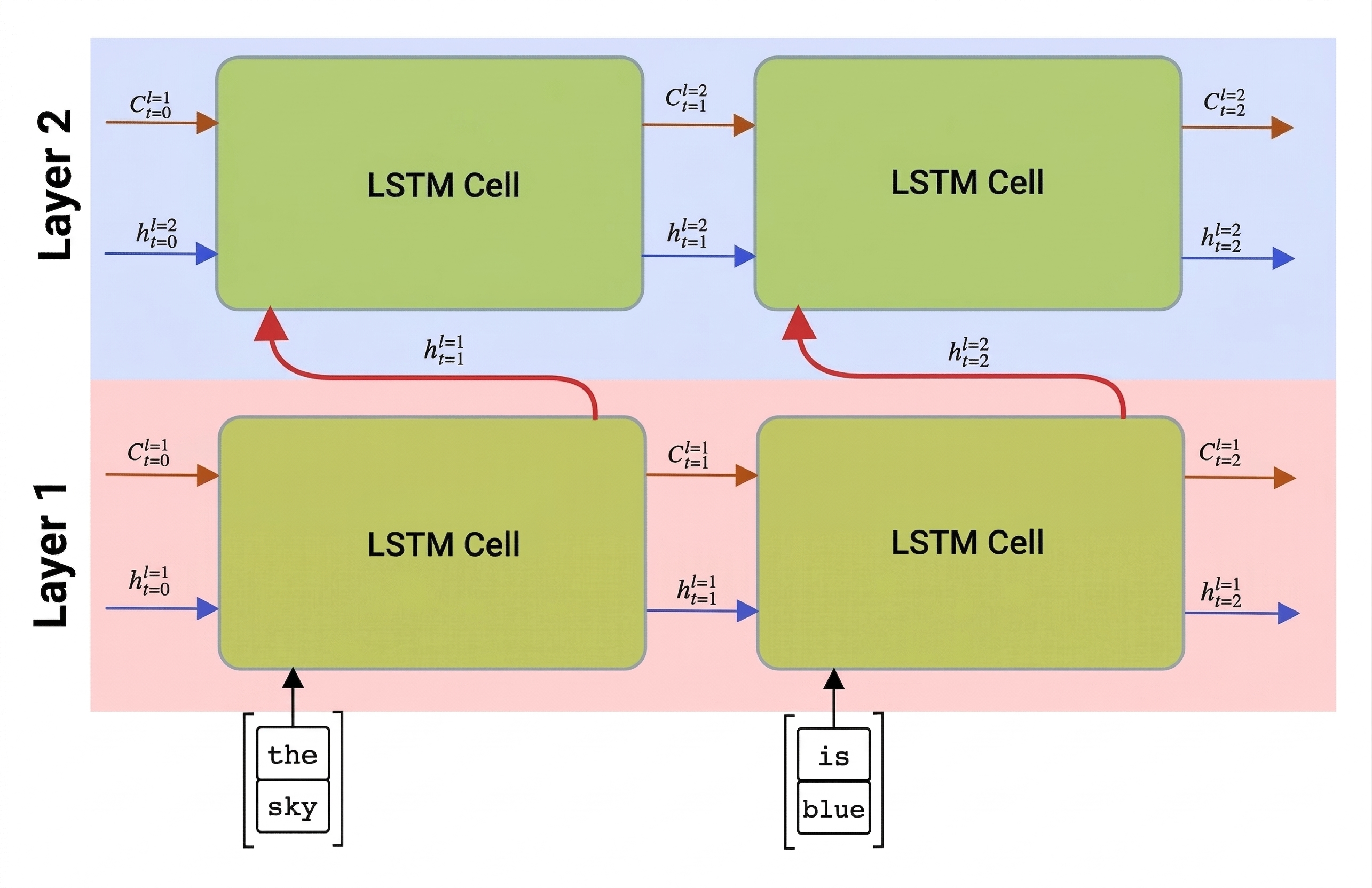
Imagem deste artigo sobre LSTMs multicamada por Fernando López.
O Keras facilita a construção destas redes, porque só precisa de adicionar mais camadas recorrentes ao modelo. Para todas as camadas, exceto a última, precisamos de especificar return_sequences=True o parâmetro, porque precisamos que a camada devolva todos os estados intermédios, e não apenas o estado final do cálculo recorrente.
O código seguinte implementa um LSTM bidirecional de duas camadas para o nosso problema de classificação.
model = keras.Sequential([
keras.Input(shape=(1,), dtype=tf.string),
vectorizer,
keras.layers.Embedding(vocab_size, 128, mask_zero=True),
keras.layers.Bidirectional(keras.layers.LSTM(64,return_sequences=True)),
keras.layers.Bidirectional(keras.layers.LSTM(64)),
keras.layers.Dense(4,activation='softmax')
])
model.compile(loss='sparse_categorical_crossentropy',metrics=['acc'], optimizer='adam')
model.fit(ds_train.map(tupelize).batch(batch_size),
validation_data=ds_test.map(tupelize).batch(batch_size))