Identificar os principais componentes dos aplicativos LLM
Os Grandes Modelos de Linguagem (LLMs) são projetados para entender e gerar linguagem humana, e sua eficácia depende de quatro componentes-chave:
- Tarefas: As diversas funções relacionadas à linguagem que esses modelos podem executar, como classificação de texto, tradução e geração de diálogos.
- Tokenizador: Pré-processe o texto dividindo-o em unidades gerenciáveis, permitindo que o modelo lide com a linguagem de forma eficiente.
- Modelo: Normalmente baseado na arquitetura do transformador, utiliza mecanismos de auto-atenção para processar texto e gerar respostas contextualmente relevantes.
- Prompt: As entradas fornecidas ao modelo, orientando-o para produzir a saída desejada.
Juntos, esses componentes permitem que os LLMs executem uma ampla gama de tarefas linguísticas com alta precisão e fluência.
Compreender as tarefas que os LLMs executam
Os LLMs são projetados para executar uma ampla gama de tarefas relacionadas ao idioma. Os LLMs são ideais para tarefas de processamento de linguagem natural, ou PNL (1), devido à sua profunda compreensão de texto e contexto.

Uma categoria de tarefas de PNL inclui compreensão de linguagem natural, ou NLU (2), tarefas como análise de sentimento, reconhecimento de entidade nomeada (NER) e classificação de texto, que envolvem extrair significado e identificar elementos específicos dentro do texto.
Outro conjunto de tarefas de PNL se enquadra na geração de linguagem natural, ou NLG (3), incluindo preenchimento de texto, sumarização, tradução e criação de conteúdo, onde o modelo gera texto coerente e contextualmente apropriado com base em determinadas entradas.
Os LLMs também são usados em sistemas de diálogo e agentes de conversação, onde podem se envolver em conversas semelhantes às humanas, fornecendo respostas relevantes e precisas às consultas dos usuários.
Entenda a importância do tokenizador
A tokenização é uma etapa vital de pré-processamento em LLMs, onde o texto é dividido em unidades gerenciáveis chamadas tokens. Esses tokens podem ser palavras, subpalavras ou até mesmo caracteres individuais, dependendo da estratégia de tokenização empregada.
Os tokenizadores modernos, como Byte Pair Encoding (BPE) e WordPiece, dividem palavras raras ou desconhecidas em unidades de subpalavras, permitindo que o modelo lide com termos fora do vocabulário de forma mais eficaz.
Por exemplo, considere a seguinte frase:
I heard a dog bark loudly at a cat
Para tokenizar esse texto, você pode identificar cada palavra discreta e atribuir IDs de token a elas. Por exemplo:
- I (1)
- heard (2)
- a (3)
- dog (4)
- bark (5)
- loudly (6)
- at (7)
- a (3)
- cat (8)
A frase agora pode ser representada com os tokens:
{1 2 3 4 5 6 7 3 8}
A tokenização ajuda o modelo a manter um equilíbrio entre o tamanho do vocabulário e a eficiência representacional, garantindo que ele possa processar diversas entradas de texto com precisão.
A tokenização também permite que o modelo converta texto em formatos numéricos que podem ser processados de forma eficiente durante o treinamento e a inferência.
Compreender a arquitetura do modelo subjacente
A arquitetura do modelo em LLMs é tipicamente baseada no modelo do transformador , que utiliza mecanismos de auto-atenção para processar e entender o texto.
Os transformadores consistem em camadas de codificadores e decodificadores que trabalham juntos para analisar o texto de entrada e gerar saídas. O mecanismo de auto-atenção permite que o modelo pese a importância de diferentes palavras em uma frase, permitindo capturar dependências de longo alcance e contexto de forma eficaz.
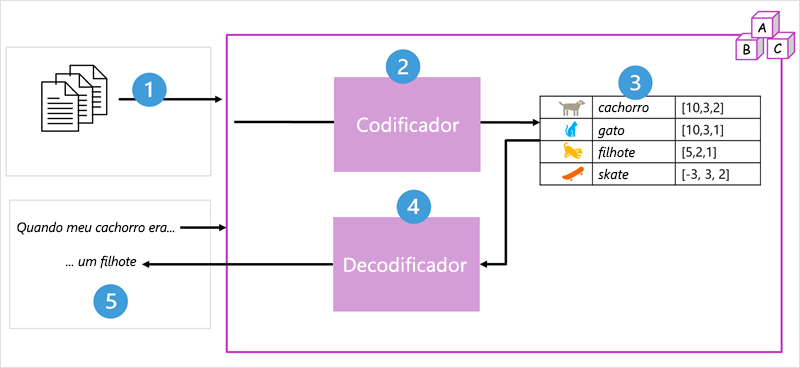
- O modelo é treinado em um grande volume de texto em linguagem natural.
- Os dados de treinamento são divididos em tokens e o bloco codificador processa sequências de token usando a atenção para determinar relações entre tokens.
- A saída do codificador é uma coleção de vetores (matrizes numéricas de vários valores) em que cada elemento do vetor representa um atributo semântico dos tokens. Esses vetores são chamados de incorporações.
- O bloco decodificador funciona em uma nova sequência de tokens de texto e usa as incorporações geradas pelo codificador para gerar uma saída de linguagem natural apropriada.
- Por exemplo, dada uma sequência de entrada como
When my dog waso modelo pode usar o mecanismo de atenção para analisar os tokens de entrada e os atributos semânticos codificados nas incorporações para prever uma conclusão apropriada da frase, comoa puppy.
Essa arquitetura é altamente paralelizável, tornando-a eficiente para treinamento em grandes conjuntos de dados. O tamanho do modelo, muitas vezes definido pelo número de parâmetros, determina sua capacidade de armazenar conhecimentos linguísticos e executar tarefas complexas. Grandes modelos, como GPT-3 e GPT-4, contêm bilhões de parâmetros, que contribuem para seu alto desempenho e versatilidade.
Entenda a importância do prompt
Os prompts são as entradas iniciais dadas aos LLMs para orientar suas respostas.
A criação de prompts eficazes é crucial para obter a saída desejada do modelo. Os prompts podem variar de instruções simples a consultas complexas, e o modelo gera texto com base no contexto e nas informações fornecidas no prompt.
Por exemplo, um prompt pode ser:
Translate the following English text to French: "Hello, how are you?"
A qualidade e a clareza do prompt influenciam significativamente o desempenho do modelo, pois um prompt bem estruturado pode levar a respostas mais precisas e relevantes.
Além dos prompts padrão, técnicas como engenharia de prompts envolvem refinamento e otimização de prompts para melhorar a saída do modelo para tarefas ou aplicativos específicos.
Um exemplo de engenharia rápida, onde instruções mais detalhadas são fornecidas:
Generate a creative story about a time-traveling scientist who discovers a new planet. Include elements of adventure and mystery.
A interação entre tarefas, tokenização, modelo e prompts é o que torna os LLMs tão poderosos e versáteis. A capacidade do modelo de executar várias tarefas é melhorada quando você tem uma tokenização eficaz, o que garante que as entradas de texto sejam processadas com precisão. A arquitetura baseada em transformador permite que o modelo compreenda e gere texto com base nos tokens e no contexto fornecido pelos prompts.