Usar o Azure Data Lake Storage Gen2 em cargas de trabalho de análise de dados
O Azure Data Lake Store Gen2 é uma tecnologia habilitadora para vários casos de uso de análise de dados. Vamos explorar alguns tipos comuns de carga de trabalho analítica e identificar como o Azure Data Lake Storage Gen2 funciona com outros serviços do Azure para dar suporte a eles.
Processamento e análise de grandes volumes de dados
Os cenários de Big Data geralmente se referem a cargas de trabalho analíticas que envolvem grandes volumes de dados em uma variedade de formatos que precisam ser processados em uma velocidade rápida - os chamados "três v's". O Azure Data Lake Storage Gen 2 fornece um armazenamento de dados distribuído escalável e seguro no qual serviços de big data, como Azure Synapse Analytics, Azure Databricks e Azure HDInsight, podem aplicar estruturas de processamento de dados, como Apache Spark, Hive e Hadoop. A natureza distribuída do armazenamento e da computação de processamento permite que as tarefas sejam executadas em paralelo, resultando em alto desempenho e escalabilidade, mesmo ao processar grandes quantidades de dados.
Armazenamento de dados
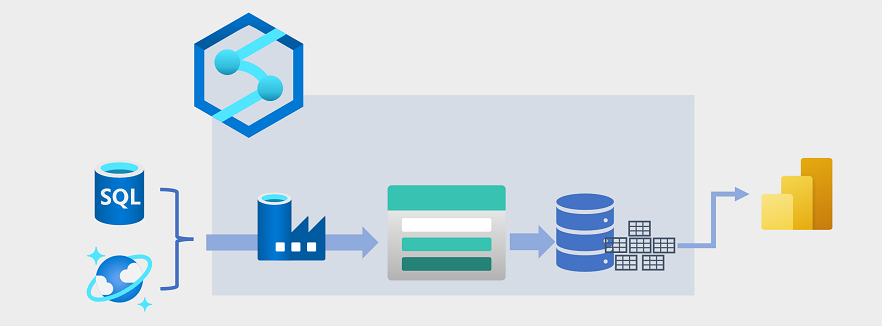
O armazenamento de dados evoluiu nos últimos anos para integrar grandes volumes de dados armazenados como arquivos em um data lake com tabelas relacionais em um data warehouse. Em um exemplo típico de uma solução de data warehousing, os dados são extraídos de armazenamentos de dados operacionais, como o banco de dados SQL do Azure ou o Azure Cosmos DB, e transformados em estruturas mais adequadas para cargas de trabalho analíticas. Muitas vezes, os dados são preparados em um data lake para facilitar o processamento distribuído antes de serem carregados em um data warehouse relacional. Em alguns casos, o data warehouse usa tabelas externas para definir uma camada de metadados relacionais sobre arquivos no data lake e criar uma arquitetura híbrida de "data lakehouse" ou "lake database". O data warehouse pode então dar suporte a consultas analíticas para geração de relatórios e visualização.
Há várias maneiras de implementar esse tipo de arquitetura de armazenamento de dados. O diagrama mostra uma solução na qual o Azure Synapse Analytics hospeda pipelines para executar processos de extração, transformação e carregamento (ETL) usando a tecnologia Azure Data Factory. Esses processos extraem dados de fontes de dados operacionais e os carregam em um data lake hospedado em um contêiner do Azure Data Lake Storage Gen2. Os dados são então processados e carregados em um data warehouse relacional em um pool SQL dedicado do Azure Synapse Analytics, de onde podem dar suporte à visualização de dados e relatórios usando o Microsoft Power BI.
Análise de dados em tempo real
Cada vez mais, as empresas e outras organizações precisam capturar e analisar fluxos perpétuos de dados e analisá-los em tempo real (ou o mais próximo possível do tempo real). Estes fluxos de dados podem ser gerados a partir de dispositivos conectados (muitas vezes referidos como dispositivos Internet das Coisas ou dispositivos IoT) ou a partir de dados gerados por utilizadores em plataformas de redes sociais ou outras aplicações. Ao contrário das cargas de trabalho tradicionais de processamento em lote, o streaming de dados requer uma solução que possa capturar e processar um fluxo ilimitado de eventos de dados à medida que ocorrem.
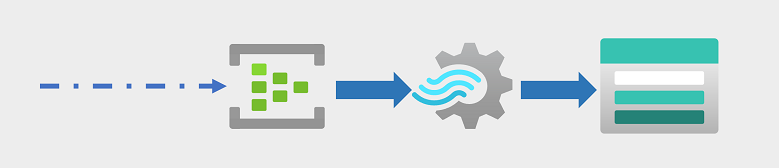
Os eventos de streaming geralmente são capturados em uma fila para processamento. Há várias tecnologias que você pode usar para executar essa tarefa, incluindo Hubs de Eventos do Azure, conforme mostrado na imagem. A partir daqui, os dados são processados, muitas vezes para agregar dados em janelas temporais (por exemplo, para contar o número de mensagens de mídia social com uma determinada tag a cada cinco minutos, ou para calcular a leitura média de um sensor conectado à Internet por minuto). O Azure Stream Analytics permite criar trabalhos que consultam e agregam dados de eventos à medida que eles chegam e gravam os resultados em um coletor de saída. Um desses coletores é o Azure Data Lake Storage Gen2; a partir de onde os dados capturados em tempo real podem ser analisados e visualizados.
Ciência de dados e aprendizado de máquina

A ciência de dados envolve a análise estatística de grandes volumes de dados, muitas vezes usando ferramentas como Apache Spark e linguagens de script como Python. O Azure Data Lake Storage Gen 2 fornece um armazenamento de dados baseado em nuvem altamente escalável para os volumes de dados necessários em cargas de trabalho de ciência de dados.
O aprendizado de máquina é uma subárea da ciência de dados que lida com o treinamento de modelos preditivos. O treinamento de modelos requer grandes quantidades de dados e a capacidade de processar esses dados de forma eficiente. O Azure Machine Learning é um serviço de nuvem no qual os cientistas de dados podem executar código Python em blocos de anotações usando recursos de computação distribuídos alocados dinamicamente. A computação processa dados em contêineres do Azure Data Lake Storage Gen2 para treinar modelos, que podem ser implantados como serviços Web de produção para dar suporte a cargas de trabalho analíticas preditivas.