Vetores de uma só vez
Até agora, cobrimos a codificação contínua de dados (números de ponto flutuante), a codificação de dados ordinais (geralmente inteiros) e a codificação de dados categóricos binários (sobreviveu/morreu, homem/mulher, etc.).
Agora vamos aprender como codificar dados e vamos explorar recursos de dados categóricos que têm mais de duas classes. Também exploraremos os efeitos potencialmente nocivos de nossas decisões de melhoria do modelo no desempenho do modelo.
Os dados categóricos não são numéricos
Os dados categóricos não funcionam com números da mesma forma que outros tipos de dados funcionam com números. Com dados ordinais ou contínuos (numéricos), valores mais altos implicam um aumento na quantidade. Por exemplo, no Titanic, um preço de bilhete de £30 é mais dinheiro do que um preço de bilhete de £12.
Em contraste, os dados categóricos não têm ordem lógica. Teremos problemas se tentarmos codificar, como números, características categóricas que tenham mais de duas classes.
Por exemplo, o Porto de Embarque tem três valores, C (Cherbourg), Q (Queenstown) e S (Southampton). Não podemos substituir esses símbolos por números. Se o fizermos, isso implicará que um desses portos é "menor" do que os outros portos, enquanto outro é "maior que" os outros portos. Esta substituição não faz sentido.
Como exemplo deste problema, vamos lançar a cautela ao vento e modelar a relação entre Porto de Embarque e Classe de Bilhetes, tratando Porto de Embarque como um número. Primeiro, definimos C < S < Q:
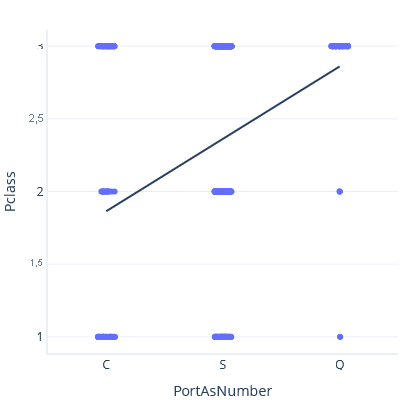
Neste gráfico, a linha prevê uma classe de ~3 para a porta Q.
Agora, se definirmos S < C < Q, obtemos uma linha de tendência e previsão diferentes:
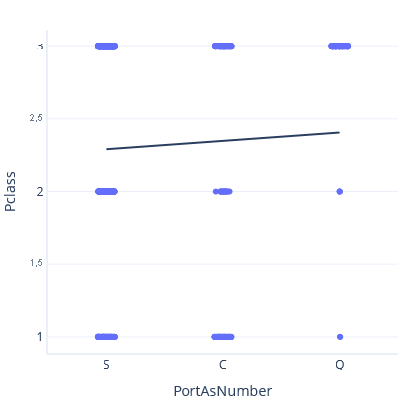
Nenhuma dessas linhas de tendência está correta. Não faz sentido tratar as categorias como características contínuas. Como, então, trabalhamos com categorias?
Codificação one-hot
A codificação one-hot pode codificar dados categóricos de uma forma que evita esse problema. Cada categoria disponível obtém sua própria coluna única, e uma determinada linha contém apenas um único valor 1 na categoria à qual pertence.
Por exemplo, podemos codificar o valor da porta em três colunas, uma para Cherbourg, uma para Queenstown, uma para Southampton (a ordem exata aqui não tem relevância). Alguém que embarcasse em Cherbourg teria um 1 na coluna Port_Cherbourg, assim:
| Port_Cherbourg | Port_Queenstown | Port_Southampton |
|---|---|---|
| 1 | 0 | 0 |
Alguém que embarcasse em Queenstown teria um 1 na segunda coluna:
| Port_Cherbourg | Port_Queenstown | Port_Southampton |
|---|---|---|
| 0 | 1 | 0 |
Alguém que embarcasse em Southampton teria um 1 na terceira coluna
| Port_Cherbourg | Port_Queenstown | Port_Southampton |
|---|---|---|
| 0 | 0 | 1 |
Codificação a quente, limpeza de dados e poder estatístico
Antes de usarmos a codificação a quente, devemos entender que seu uso pode ter impactos positivos ou negativos no desempenho real de um modelo.
O que é o poder estatístico?
O poder estatístico refere-se à capacidade de um modelo de identificar de forma confiável relações reais entre características e rótulos. Por exemplo, um modelo poderoso pode relatar uma relação entre o preço do bilhete e a taxa de sobrevivência, com um alto grau de certeza. Por outro lado, um modelo com baixo poder estatístico pode relatar uma relação com um baixo grau de certeza, ou pode nem mesmo encontrar essa relação.
Vamos evitar a matemática aqui, mas lembre-se que as escolhas que fazemos podem influenciar o poder dos nossos modelos.
A remoção de dados reduz o poder estatístico
Mencionámos várias vezes que a limpeza de dados - em parte - envolve a remoção de amostras de dados incompletas. Infelizmente, a limpeza de dados pode reduzir o poder estatístico. Por exemplo, vamos fingir que queremos prever a sobrevivência da viagem do Titanic, tendo em conta os seguintes dados:
| Preço do Bilhete | Sobrevivência |
|---|---|
| £4 | 0 |
| £8 | 0 |
| £10 | 1 |
| £25 | 1 |
Poderíamos supor que alguém com um bilhete no valor de £ 15 sobreviveria, porque as pessoas com ingressos que custam pelo menos £ 10 sobreviveram. Se tivéssemos menos dados, porém, esse palpite se tornaria mais difícil:
| Preço do Bilhete | Sobrevivência |
|---|---|
| £4 | 0 |
| £8 | 0 |
| £25 | 1 |
Colunas inúteis reduzem o poder estatístico
Recursos que têm pouco valor também podem danificar o poder estatístico, especialmente quando o número de recursos (ou colunas) começa a se aproximar do número de amostras (ou linhas).
Por exemplo, digamos que queremos ser capazes de prever a sobrevivência com os seguintes dados:
| Preço do Bilhete | Sobrevivência |
|---|---|
| £4 | 0 |
| £4 | 0 |
| £25 | 1 |
| £25 | 1 |
Poderíamos prever com confiança que alguém com um bilhete de cabine A sobreviveria, porque todos com bilhetes de £ 25 sobreviveram.
No entanto, agora temos outra característica (Cabine):
| Preço do Bilhete | Cabine | Sobrevivência |
|---|---|---|
| £4 | A | 0 |
| £4 | A | 0 |
| £25 | N | 1 |
| £25 | N | 1 |
Cabine não fornece informações úteis, porque simplesmente corresponde ao preço do bilhete. Não está claro se alguém com um bilhete de £ 25 Cabine A sobreviveria. Perecem, como outros da Cabine A, ou sobrevivem como aqueles com bilhetes de 25 libras?
A codificação a quente pode reduzir o poder estatístico
A codificação a quente reduz o poder estatístico mais do que dados contínuos ou ordinais, porque requer várias colunas – uma para cada valor categórico possível. Por exemplo, se codificarmos a porta de embarque, adicionaremos três entradas de modelo (C, S e Q).
Uma variável categórica torna-se útil se o número de categorias for substancialmente menor do que o número de amostras (linhas do conjunto de dados). Uma variável categórica também se torna útil se fornecer informações ainda não disponíveis para o modelo através de outras entradas.
Por exemplo, vimos que a probabilidade de sobrevivência diferia para as pessoas que embarcavam em portos diferentes. Esta variação provavelmente reflete o fato de que a maioria das pessoas no porto de Queenstown tinha bilhetes de terceira classe. Portanto, o embarque provavelmente reduz um pouco o poder estatístico, sem adicionar informações relevantes ao nosso modelo.
Por outro lado, Cabin provavelmente tem uma forte influência na sobrevivência. Isso ocorre porque as cabines inferiores do navio teriam se enchido de água antes que as cabines mais próximas do convés superior do navio se enchessem de água. Dito isto, o conjunto de dados do Titanic contém 147 cabines diferentes. Isso reduz o poder estatístico do nosso modelo se os incluirmos. Talvez precisemos experimentar incluir ou excluir dados da cabine em nosso modelo, para ver se os dados da cabine podem nos ajudar.
Em nosso próximo exercício, finalmente construímos nosso modelo que prevê a sobrevivência da viagem do Titanic, e praticaremos a codificação a quente enquanto o fazemos.