Funções de custo versus métricas de avaliação
Nas últimas unidades, começamos a ver uma divisão nas funções de custo, que ensinam o modelo, e nas métricas de avaliação, que é como nós mesmos avaliamos o modelo.
Todas as funções de custo podem ser métricas de avaliação
Todas as funções de custo podem ser métricas de avaliação, embora não necessariamente intuitivas. Perda de log, por exemplo: os valores não são intuitivos.
Algumas métricas de avaliação não podem ser funções de custo
- É difícil que algumas métricas de avaliação se tornem funções de custo
- Isto deve-se a restrições práticas e matemáticas
- Às vezes, as coisas não são fáceis de calcular (por exemplo, "como algo é cachorrinho")
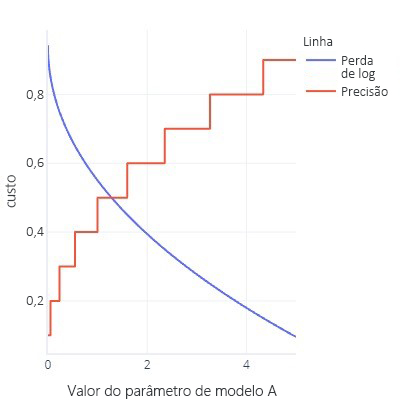
- As funções de custo são idealmente suaves. Por exemplo, a precisão é útil, mas se mudarmos ligeiramente o nosso modelo, ele não vai notar. Dado que o ajuste é um procedimento com muitas pequenas alterações, isso dá a impressão de que as alterações não levarão a melhorias.
- Gráfico de função de custo com muitos bits planos
- Atualize as curvas ROC anteriores. Isso requer alterar o limite para todos os tipos de valores, mas no final do dia, nosso modelo terá apenas um (0,5)
Não é de todo ruim!
Pode ser frustrante descobrir que não podemos usar métricas favoritas como uma função de custo. Há um lado positivo, no entanto, que está relacionado ao fato de que todas as métricas são simplificações do que queremos alcançar; nenhum é perfeito. O que isso significa é que modelos complexos muitas vezes "trapaceiam": eles encontram uma maneira de obter custos baixos sem realmente encontrar uma regra geral que resolva nosso problema. Ter uma métrica que não está agindo como a função de custo nos dá uma "verificação de sanidade" de que o modelo não encontrou uma maneira de trapacear. Se soubermos que um modelo está a tomar atalhos, podemos repensar a nossa estratégia de formação.
Já vimos essa "trapaça" algumas vezes agora. Por exemplo, quando os modelos superajustam fortemente os dados de treinamento, eles estão essencialmente "memorizando" as respostas corretas em vez de encontrar uma regra geral que podemos aplicar com sucesso a outros dados. Usamos conjuntos de dados de teste como nossa "verificação de sanidade" para avaliar e verificar se o modelo não fez apenas isso. Também vimos que, com dados desequilibrados, os modelos às vezes podem simplesmente aprender a dar sempre a mesma resposta (como "falso") sem olhar para os recursos, porque em média isso é correto e dá um pequeno erro.
Modelos complexos também encontram atalhos de outras maneiras. Os modelos complexos podem, por vezes, sobrepor-se à própria função de custo. Por exemplo, imagine que estamos tentando construir um modelo que possa desenhar cães. Temos uma função de custo que verifica se a imagem é marrom, mostra uma textura peluda e contém um objeto do tamanho certo. Com esta função de custo, um modelo complexo pode aprender a criar uma bola de pele castanha, não porque se pareça com um cão, mas porque dá um baixo custo e é fácil de gerar. Se tivermos uma métrica externa que conte o número de pernas e cabeças (que não pode ser facilmente usada como uma função de custo porque não são métricas suaves), notaremos rapidamente se nosso modelo está trapaceando e repensaremos como estamos treinando-o. Por outro lado, se nossa métrica alternativa pontuar bem, podemos ter alguma confiança de que o modelo compreendeu a ideia de como um cão deve parecer, em vez de apenas enganar a função de custo para obter um valor baixo.