Implantar modelos em endpoints
Depois de selecionar um modelo do catálogo, implementa-o para o tornar acessível através de endpoints que as suas aplicações podem usar. O portal Microsoft Foundry guia-o durante o processo de implementação e fornece ferramentas para testar imediatamente o seu modelo implementado.
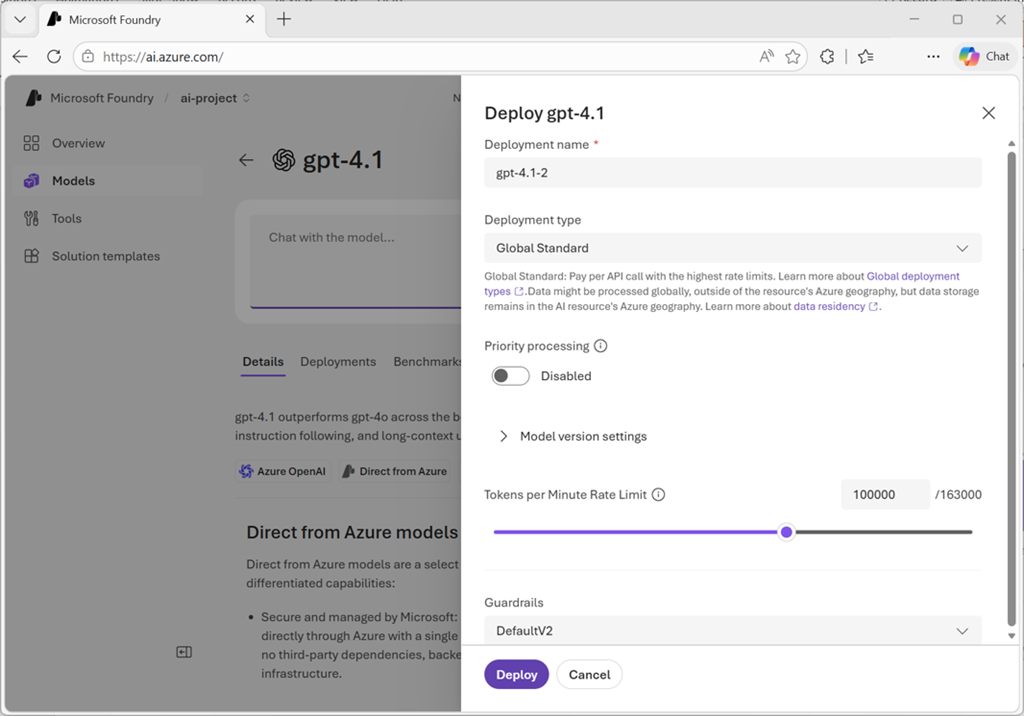
Compreender os tipos de implementação
O Microsoft Foundry suporta vários tipos de implementação, cada um oferecendo diferentes características para residência de dados, escalabilidade e faturação:
- As implementações do Modelo Global Standard podem usar qualquer região Azure com base em pagamento por token. São melhores para cargas de trabalho gerais e oferecem a quota mais alta.
- As implementações Global Provisioned podem usar qualquer região Azure, e a sua utilização baseia-se numa base de unidades de débito de provisão reservada (PTU) para proporcionar um alto débito previsível.
- As implementações Global Batch podem usar qualquer região Azure com um desconto de 50% para trabalhos assíncronos grandes dentro de 24 horas.
- As implementações do Padrão de Zona de Dados garantem que os dados permaneçam dentro de uma zona de dados específica numa base de pagamento por token. São melhores para cenários onde é exigida conformidade com zonas de dados UE/EUA.
- As implantações com Zona de Dados Provisionada proporcionam um débito previsível baseado em PTUs reservadas dentro de uma zona de dados.
- As implementações Data Zone Batch são concebidas para grandes processos em lote assíncronos dentro de uma zona de dados.
- As implementações padrão são implementadas numa única região com base em pagamento por token. São ótimos quando precisas de conformidade com residência regional de dados ou para cenários de baixo volume.
- As implantações Regional Provisionadas fornecem PTUs reservadas dentro de uma única região.
- Desenvolvedor As implementações de programadores utilizam qualquer região Azure com base em pagamento por token e destinam-se apenas à avaliação de modelos afinados.
Cada modelo no catálogo indica que tipos de implementação suporta. O portal seleciona automaticamente a melhor opção de implementação com base no seu ambiente e nos requisitos do modelo. As implementações de Global Standard nos recursos da Foundry devem ser usadas sempre que possível para maximizar as capacidades.
Implementar um modelo
Para implementar um modelo a partir do portal Microsoft Foundry:
Primeiro, navegue até ao modelo que selecionou no catálogo de modelos. Na página inicial do portal Foundry, selecione Descobrir na navegação, depois Modelos no painel esquerdo. Abra a placa do modelo para rever as suas especificações e tipos de implementação suportados.
Selecione Implementar para iniciar o processo de implementação. Pode escolher:
- Definições padrão para implementar rapidamente com configurações recomendadas
- Definições personalizadas para personalizar as opções de implementação
Se o modelo exigir uma subscrição do Azure Marketplace (comum para modelos de parceiros e da comunidade), vê os termos de utilização. Veja estes termos e selecione Concordar e Prossiga para os aceitar. Modelos vendidos diretamente pelo Azure, como os modelos OpenAI do Azure como o GPT-4o-mini, não exigem subscrições do marketplace.
Configure as suas definições de implantação:
-
Nome da implementação: Por defeito, o sistema usa o nome do modelo. Pode modificar isto para criar nomes significativos para múltiplas implementações do mesmo modelo. Durante a inferência, o seu código usa este nome de implementação no
modelparâmetro para encaminhar pedidos. - Tipo de implementação: O portal seleciona automaticamente o tipo de implementação adequado com base no modelo e no seu ambiente. Cada modelo suporta diferentes tipos de implementação, oferecendo diferentes garantias de residência de dados ou de rendimento.
Para implementações de computação gerida, também se configura:
- SKU de máquina virtual: Escolha entre tipos de VM suportados. Precisa da quota de computação do Azure Machine Learning para o SKU selecionado na sua subscrição.
- Contagem de instâncias: Especifique quantas instâncias implementar para distribuição de carga e redundância.
Depois de configurar todas as definições, selecione Implementar. Quando a implementação termina, aterras no Foundry Playground, onde podes testar o modelo de forma interativa. Verifique se o estado de implementação mostra Bem-sucedido na sua lista de implementação.
Gerir modelos implementados
Após a implementação, gere os seus modelos a partir da secção Build no portal Microsoft Foundry. Selecione Construir na navegação, depois Modelos no painel esquerdo para ver a lista de implementações no seu recurso.
Da lista de implementação, selecione um modelo específico para visualizar os seus detalhes:
- Configuração e estado da implantação
- URL do endpoint para acesso API
- Chaves ou tokens de autenticação
- Monitorização e métricas de utilização
- Opção para ajustar as definições de implementação ou eliminar a implementação
A página de detalhes da implementação fornece a informação de que as suas aplicações precisam para se ligar e usar o modelo.
Teste no recreio
O portal Microsoft Foundry inclui playgrounds interativos onde se testam os modelos implementados imediatamente, sem escrever código. Após a conclusão do deployment, aterras automaticamente no playground, ou podes selecionar um deployment da tua lista de modelos para abrir o playground.
O playground pré-seleciona a sua implantação, para que possa começar a testar imediatamente. Na interface de chat:
Introduza os prompts na caixa de mensagens e observe as respostas. O ambiente interativo mostra tanto a sua entrada como a saída gerada pelo modelo, ajudando a compreender o comportamento e a qualidade.
Experimente diferentes tipos de prompts para testar várias capacidades:
- Perguntas simples para verificar a compreensão básica
- Problemas complexos de raciocínio em múltiplos passos
- Pedidos para formatos ou estilos específicos
- Casos extremos que podem revelar limitações
Ajustar as mensagens do sistema para guiar o comportamento do modelo. As mensagens do sistema definem contexto, tom e instruções que se aplicam a todas as entradas do utilizador. Por exemplo, pode instruir o modelo a "responder como representante de customer service" ou "fornecer explicações concisas e técnicas."
Modificar parâmetros como temperatura (criatividade vs. consistência), tokens máximos (limites de comprimento de resposta) e top-p (amostragem do núcleo) para ajustar o comportamento de geração.
Selecione o separador Código para ver exemplos de como aceder programaticamente ao seu modelo implementado. Os exemplos de código mostram autenticação, configuração de endpoints e formatação de pedidos em linguagens como Python, C# e JavaScript. Pode copiar estes exemplos diretamente para a sua candidatura.
O playground serve como o seu ambiente de desenvolvimento para engenharia rápida e testes antes de integrar o modelo na sua aplicação.
Aceder a modelos de forma programática
Quando estiver pronto para integrar o modelo na sua aplicação, precisa de três informações-chave dos detalhes da implementação:
URL do endpoint: O endpoint da API onde a sua aplicação envia pedidos. O Microsoft Foundry suporta endpoints de projeto para funcionalidades específicas da Foundry, e endpoints OpenAI v1 para ampla compatibilidade com APIs de modelos OpenAI.
Chave de autenticação: A chave secreta ou token que a sua aplicação apresenta para autenticar pedidos. Em alternativa, pode usar a autenticação Microsoft Entra ID e fazer com que a sua aplicação apresente um token de autenticação baseado na sua identidade. A autenticação por ID Entra é recomendada para cenários de produção.
Nome da implementação: O nome que especificou durante a implementação, usado no model parâmetro dos pedidos de API para encaminhar para a sua implementação específica.
A sua aplicação utiliza estes detalhes para construir pedidos de API. O portal Microsoft Foundry fornece SDKs e documentação da API REST para várias linguagens de programação, juntamente com exemplos de código que mostram formatação de pedidos, autenticação e gestão de respostas.
Com o seu modelo implementado e testado, está pronto para o integrar nas aplicações ou avançar para uma avaliação mais abrangente usando métricas automatizadas e conjuntos de dados de teste.