Transmita dados com o Apache Kafka
O Apache Kafka foi criado pelo LinkedIn em 2010, com o objetivo de mover dados em uma escala muito alta com latência muito baixa com um alto nível de tolerância a falhas. O LinkedIn então doou o projeto para a fundação Apache em 2012, mas o LinkedIn ainda usa Kafka em todo o seu ecossistema para rastrear a atividade do usuário, trocar mensagens e coletar métricas.
Kafka é uma plataforma de streaming distribuída que foi projetada para:
- Simplifique os pipelines de dados
- Lidar com grandes quantidades de dados em um padrão de streaming
- Suporte em tempo real e sistemas em lote
- Escala maciça horizontalmente
Vamos primeiro aprender sobre o Apache Kafka puro e, em seguida, sobre o Kafka no Azure HDInsight.
Componentes Kafka
Antes de entendermos como Kafka funciona, vamos olhar para os papéis de alguns dos principais componentes de Kafka e como eles se unem para fornecer um sistema de mensagens altamente escalável e tolerante a falhas.
Mediador
Kafka é um serviço agrupado e um único cluster Kafka também é chamado de corretor. Os corretores recebem mensagens dos produtores e armazenam essas mensagens no disco. O corretor também responde aos pedidos de busca dos consumidores. Dentro de um grupo de corretores, um corretor serve como controlador e é responsável por operações administrativas e atribuição de partições aos corretores.
Mensagem
Uma unidade de dados em um cluster de Kafka. As mensagens, na maioria dos casos, são pares de valores de chave.
Tópicos e partições
Tópicos e partições são categorias de mensagens em Kafka. Os tópicos são normalmente divididos em várias partições para melhorar por toda parte, com um mínimo recomendado de três partições. As mensagens são gravadas em uma partição de tópico de forma somente acréscimo. As partições são replicadas em vários brokers para melhorar a redundância em caso de falhas do broker. As partições permitem que os tópicos sejam lidos em paralelo porque permitem que os dados sejam divididos em vários brokers. Há uma réplica de líder que lida com todas as solicitações de leitura-gravação, e os seguidores são replicados do líder. Se um líder falhar, uma das réplicas torna-se o líder.
Produtores e consumidores
Produtores e consumidores são os clientes que produzem e consomem mensagens do sistema Kafka. Os produtores publicam novas mensagens e direcionam-nas para um tópico específico. Os consumidores também podem ser projetados para gravar em uma partição de tópico específica. Os consumidores, por sua vez, subscrevem um ou mais tópicos e leem mensagens desses tópicos.
Grupo de Consumidores
Um ou mais consumidores podem trabalhar juntos como um grupo e consumir mensagens como um grupo. Se o número de consumidores for igual ao número de partições de tópico, cada consumidor consome de uma única partição de tópico, criando paralelismo.
Retenção
As mensagens em Kafka podem ser mantidas de forma duradoura no cluster Kafka por um período de tempo predefinido. Depois que os limites de retenção forem atingidos, Kafka pode expirar e excluir essas mensagens.
Desvio
Um deslocamento é simplesmente a posição de uma mensagem em uma partição. A atualização da posição atual em uma partição à medida que as mensagens estão sendo processadas é chamada de confirmação. Depois que uma mensagem é processada, Kafka confirma o deslocamento da mensagem para um tópico interno especial de Kafka. Quando um produtor publica uma mensagem para uma partição, ela é encaminhada para o líder. O líder adiciona a mensagem ao log de confirmação e incrementa o deslocamento da mensagem. O deslocamento de mensagem é como as mensagens são identificadas dentro do tópico. A mensagem só estará disponível para o consumidor depois que a mensagem tiver sido confirmada no cluster.
Zookeeper
O Zookeeper é um serviço de coordenação e, em um cluster Kafka, o Zookeeper fornece uma visão sincronizada do estado do cluster. Kafka usa o Zookeeper para a eleição de líderes entre partições de corretores e tópicos. Kafka usa o Zookeeper para gerenciar a descoberta de serviços para corretores Kafka que formam o cluster. O Zookeeper envia alterações da topologia para Kafka, para que cada nó no cluster saiba quando um novo broker entrou, um broker morreu, um tópico foi removido ou um tópico foi adicionado.
Como é que tudo se conjuga?
Os aplicativos (também conhecidos como produtores) enviam mensagens para um corretor Kafka e essas mensagens são processadas por um ou vários consumidores. As mensagens em um cluster são categorizadas por tópicos. Por exemplo, um cliente pode criar um tópico "Vendas" para enviar todas as mensagens relevantes para as vendas e assim por diante. À medida que os tópicos crescem em tamanho com o aumento das mensagens, eles são divididos em partições e essas partições são replicadas em todos os corretores Kafka para redundância. As partições são categorizadas como líderes e seguidores. A partição do líder é escrita e lida enquanto as partições do seguidor são simplesmente réplicas, que alcançam o estado do líder. Para determinar em qual partição escrever e ler, os produtores e consumidores precisam saber quais partições são líderes projetadas. Os nós de zookeepers gerenciam o estado, o cluster de Kafka e, entre outras coisas, elegem líderes de partição e fornecem essas informações aos produtores e consumidores.
Kafka fornece garantias de que as mensagens com uma partição são ordenadas na mesma sequência em que entraram. Uma mensagem específica pode ser distintamente identificada através do seu deslocamento, que é a sua posição dentro de uma partição. O consumidor leu mensagens de partições e pós-processamento, confirme o deslocamento indicando que a mensagem foi processada com êxito. Kafka armazena todos os seus registros em disco e mantém a persistência da mensagem. Caso o consumidor seja interrompido por algum motivo e o processamento pare, Kafka retém essas mensagens por um período de retenção predeterminado e, depois de voltar a ficar online, o consumidor pode reiniciar o processamento a partir do offset comprometido de onde parou antes da interrupção.
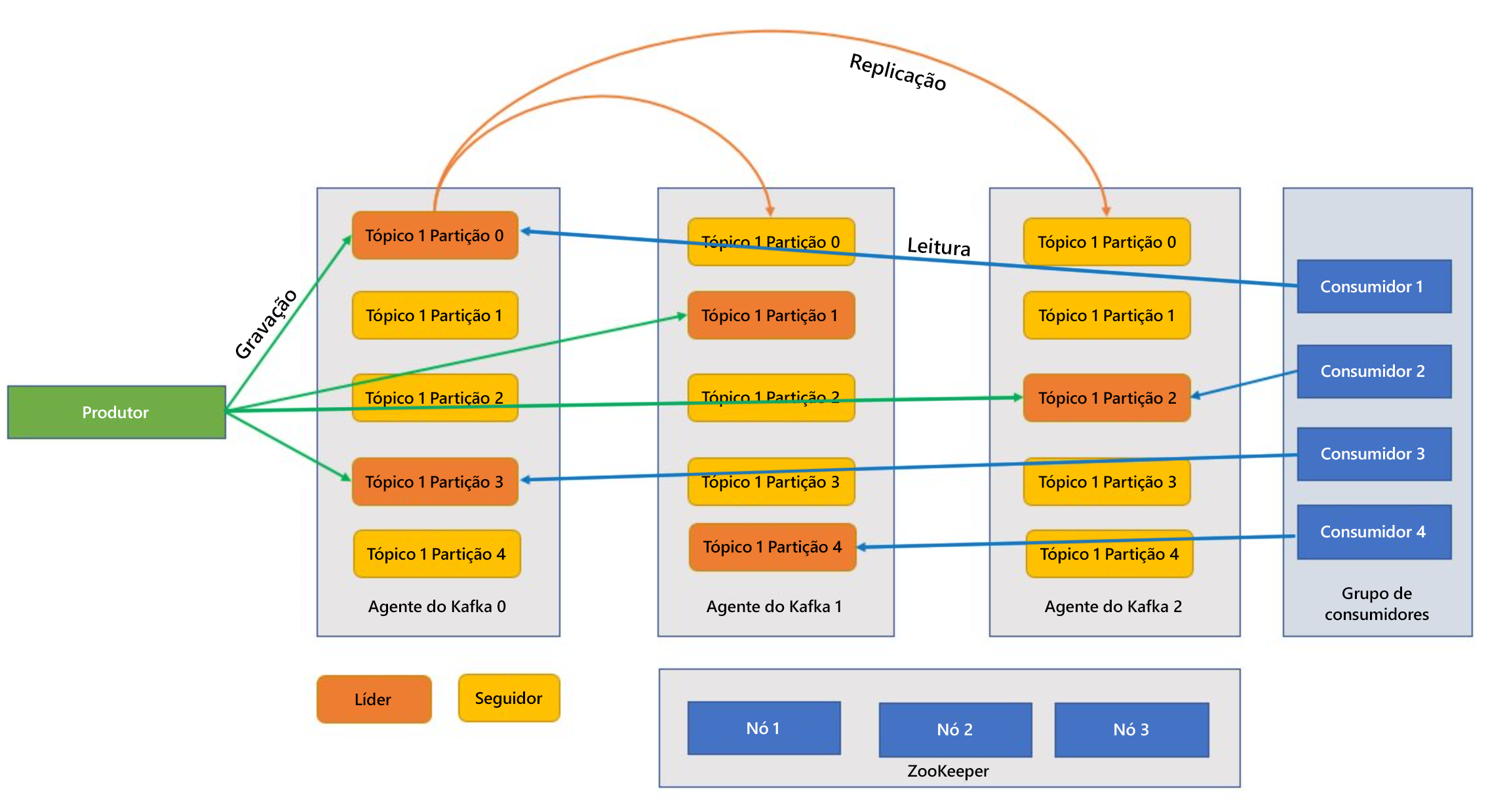
Tópicos de Kafka
Um tópico Kafka é um feed ou uma fila onde as mensagens são armazenadas e publicadas. Os produtores enviam mensagens para os tópicos e os consumidores leem os tópicos. Cada nó em um corretor Kafka pode conter vários tópicos.
Quais são os benefícios do Kafka no Azure HDInsight?
A versão de código aberto do Kafka oferece muitos recursos, mas há muito trabalho envolvido na sua configuração. O Azure HDInsight traz o melhor das estruturas de análise de código aberto para o Azure e torna mais fácil para os clientes configurarem seus clusters de código aberto em minutos, em vez de passar semanas ou meses configurando esses clusters, e você pode usá-los imediatamente. O HDInsight também está preparado para empresas com os seguintes benefícios:
- É um serviço gerido que fornece um processo de configuração simplificado. O resultado é uma configuração que é testada e suportada pela Microsoft.
- A Microsoft fornece um Acordo de Nível de Serviço (SLA) de 99,9% sobre o tempo de atividade do Spark e do Kafka.
- Utiliza os Managed Disks do Azure como arquivo de cópias de segurança do Kafka. Os Managed Disks podem fornecer até 16 TB de armazenamento por broker Kafka, com vários brokers Kafka.
- O HDInsight oferece a melhor segurança empresarial com redes virtuais, segurança refinada com Apache Ranger e criptografia Bring Your Own Key (BYOK) para dados em repouso
- Conformidade para HIPAA, SOC e PCI
- A capacidade de implantar pipelines de streaming de ponta a ponta com o Spark e o Armazenamento por meio de modelos automatizados do Azure Resource Manager (ARM) na mesma VNet.
- A alta disponibilidade pode ser alcançada com o Kafka MirrorMaker, que pode consumir registros de tópicos no cluster primário e, em seguida, criar uma cópia local no cluster secundário.
- O HDInsight permite-lhe alterar o número de nós de trabalho (que alojam o mediador Kafka) após a criação do cluster. O escalonamento pode ser executado a partir do portal do Azure, do Azure PowerShell e de outras interfaces de gestão do Azure. Para o Kafka, deve reequilibrar as réplicas de partições após as operações de dimensionamento. Reequilibrar partições permite ao Kafka tirar partido do novo número de nós de trabalho.
- Os logs do Azure Monitor podem ser usados para monitorar o Kafka no HDInsight. O Azure Monitor registra informações de superfície no nível da máquina virtual, como métricas de disco e NIC e métricas JMX do Kafka.