Ingerir dados com o Azure Databricks
Antes de poder trabalhar com dados no Azure Databricks, você precisa ingerir dados na plataforma. Uma vez na plataforma, a computação baseada em nuvem permite processar grandes volumes de dados de forma eficiente.
Os dados no Azure Databricks são armazenados usando o Apache Delta Lake, um sistema de código aberto para gerenciar arquivos de dados nos quais tabelas relacionais podem ser definidas e consultadas. O local de armazenamento real para os arquivos do lago delta pode variar. O Azure Databricks dá suporte à conexão com serviços de armazenamento de dados em nuvem, como o Armazenamento do Azure e o Azure Data Lake. O Azure Databricks também fornece o Unity Catalog como uma solução de governança para gerenciar e rastrear o acesso a dados e a linhagem em vários armazenamentos de dados conectados.
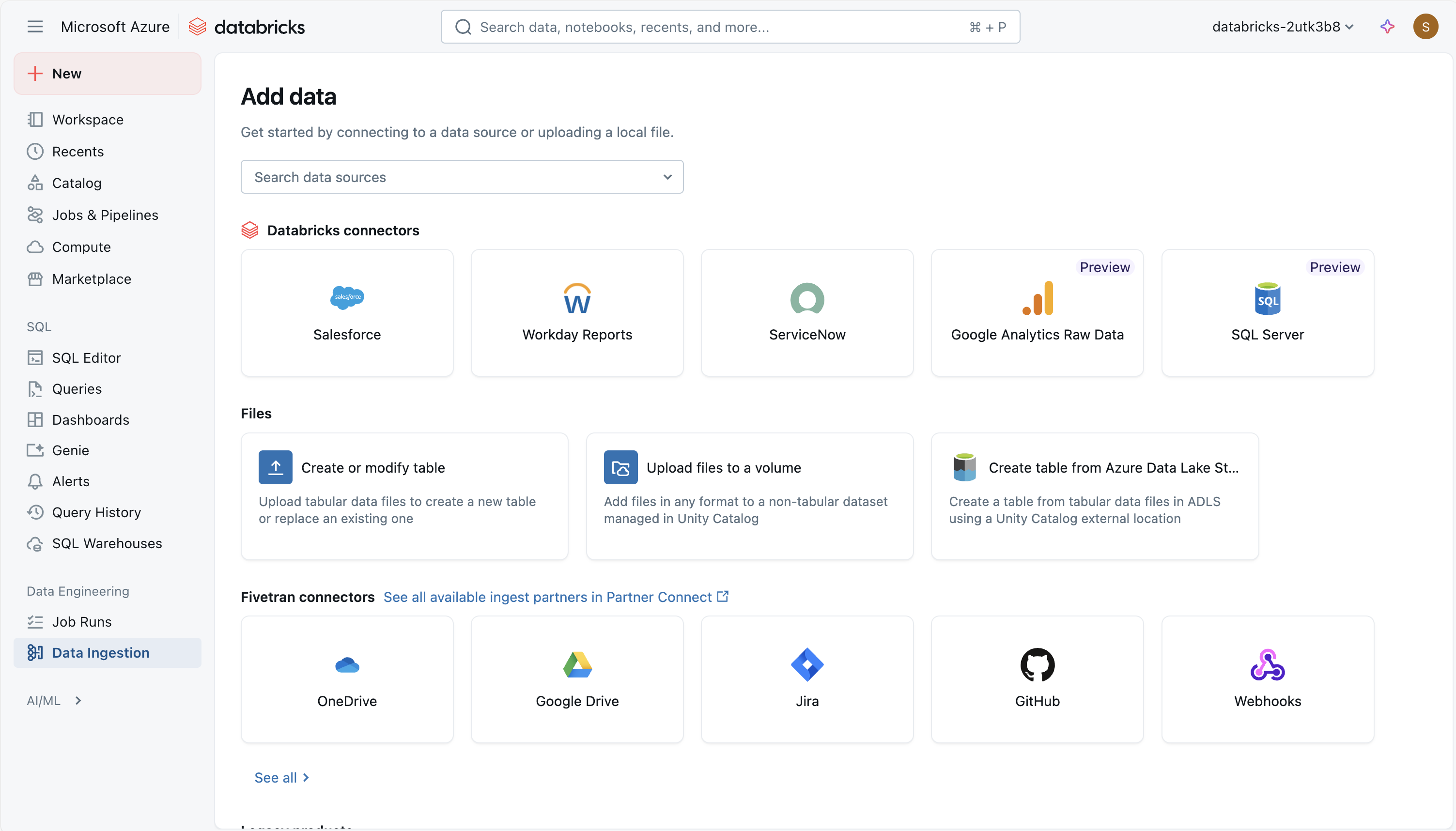
Há várias maneiras de ingerir dados no Azure Databricks, tornando-o uma ferramenta versátil e poderosa para análise de dados, incluindo:
Usando um conector Databricks gerenciado no Lakeflow Connect
O Azure Databricks Lakeflow Connect fornece uma estrutura para ingerir dados de aplicativos SaaS, bancos de dados e outras fontes na lakehouse usando conectores gerenciados. Esses conectores definem como a autenticação, os pipelines e as tabelas de destino são configurados e mantidos. Para fontes SaaS, as partes principais são uma conexão (para autenticação), um pipeline de ingestão sem servidor e tabelas Delta que armazenam os dados ingeridos. Os conectores de banco de dados incluem os mesmos elementos, mas também dependem de um gateway de ingestão que é executado em computação clássica e uma área de armazenamento de preparo no Unity Catalog para armazenar temporariamente os dados extraídos. A orquestração é tratada por meio de trabalhos do Databricks, e o controle de acesso e a auditoria são gerenciados por meio do Unity Catalog.
O uso de conectores geridos permite que os pipelines de dados sejam agendados, reiniciados e dimensionados sem a necessidade de escrever código personalizado de integração de dados. A ingestão incremental é suportada, o que ajuda a reduzir a carga nos sistemas de origem, mantendo as tabelas atualizadas. A abordagem enfatiza a governança consistente, o tratamento de esquemas e o monitoramento em diferentes fontes de dados.
Os seguintes conectores gerenciados estão disponíveis:
- Google Analytics
- Salesforce
- Relatórios de dias úteis
- SQL Server
- ServiceNow
- SharePoint
Carregar ficheiros para o Azure Databricks
Você pode importar arquivos locais CSV, TSV, JSON, XML, Avro, Parquet ou texto simples para o Databricks para gerar uma tabela Delta. Esta abordagem destina-se a ficheiros mais pequenos (menos de 2 GB) transferidos diretamente do seu computador. Arquivos compactados como ZIP ou TAR não são suportados. Durante o processo de carregamento, o Databricks fornece uma visualização de até 50 linhas e você pode ajustar as configurações de formatação para garantir que as colunas e os tipos de dados em arquivos CSV ou JSON sejam reconhecidos corretamente.
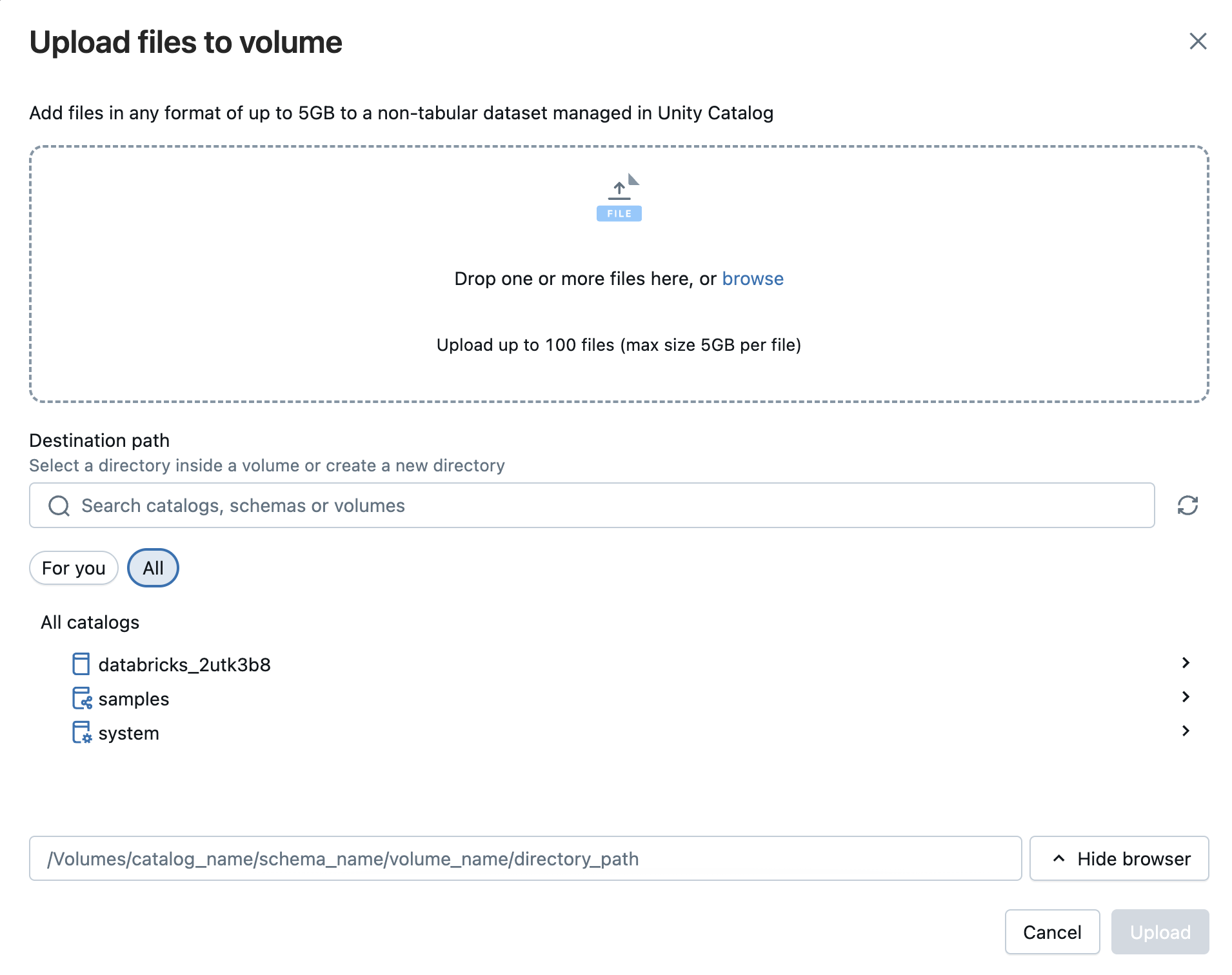
Você também pode carregar arquivos de qualquer formato — estruturado, semiestruturado ou não estruturado — em um volume. Um volume é um objeto Unity Catalog que fornece governança para conjuntos de dados não tabulares e representa um espaço de armazenamento lógico dentro de um armazenamento de objetos na nuvem. Os volumes permitem acessar, armazenar, organizar e aplicar governança aos arquivos. Existem dois tipos de volumes:
- Volumes gerenciados: armazenamento gerenciado por Databricks para casos de uso simples.
- Volumes externos: governança aplicada a locais de armazenamento de objetos em nuvem existentes.
Observação
A opção DBFS permite que o utilizador use o envio de ficheiros do antigo sistema de arquivos Databricks. Isso não é mais suportado.
Ingerir arquivos usando a API do Apache Spark
O Apache Spark é a plataforma de computação nativa para o Azure Databricks e suporta APIs para várias linguagens de programação, como Scala, Java, PySpark (uma variante otimizada para Spark do Python) e SQL. Para uma ingestão simples de dados no armazenamento remoto, você pode escrever código que se conecta e importa os dados necessários.
Aqui está um exemplo usando wget para puxar um arquivo remoto para /tmp/ no nó do driver, use o Spark para lê-lo do caminho local e salve-o como uma tabela Delta no Databricks:
# Step 1: Use wget to download the file (e.g., a CSV from a public URL)
# In Databricks, prefix shell commands with "!"
!wget https://<location>/airtravel.csv -O /tmp/airtravel.csv
# Step 2: Load the downloaded file into a Spark DataFrame
df = spark.read.format("csv") \
.option("header", "true") \
.option("inferSchema", "true") \
.load("file:/tmp/airtravel.csv")
# Step 3: Preview the data
df.show(5)
# Step 4: Save as a Delta table
df.write.format("delta").mode("overwrite").saveAsTable("default.airtravel")
Carregar dados com um principal de serviço usando COPY INTO
Você pode usar COPY INTO o comando para carregar dados de um contêiner do Azure Data Lake Storage (ADLS) em sua conta do Azure em uma tabela no Databricks SQL.
COPY INTO my_json_data
FROM 'abfss://container@storageAccount.dfs.core.windows.net/jsonData'
FILEFORMAT = JSON;
Oleodutos Declarativos Lakeflow
Lakeflow Declarative Pipelines é uma estrutura declarativa para desenvolver e executar pipelines de dados em lote e streaming em SQL e Python. Ele suporta orquestração automatizada, tentativas, isolamento de erros, evolução de esquema, processamento incremental e CDC Change Data Capture tipo 1 e 2.
Um fluxo é o conceito fundamental de processamento de dados no Lakeflow Declarative Pipelines, que suporta semântica de streaming e batch. Um fluxo lê dados de uma fonte, aplica a lógica de processamento definida pelo usuário e grava o resultado em um destino.
Você também pode gerenciar a qualidade dos dados com as expectativas do pipeline, o que permite definir regras de validação que garantem que os dados atendam aos padrões exigidos antes de serem gravados em seu destino.
Aqui está um exemplo de um pipeline declarativo:
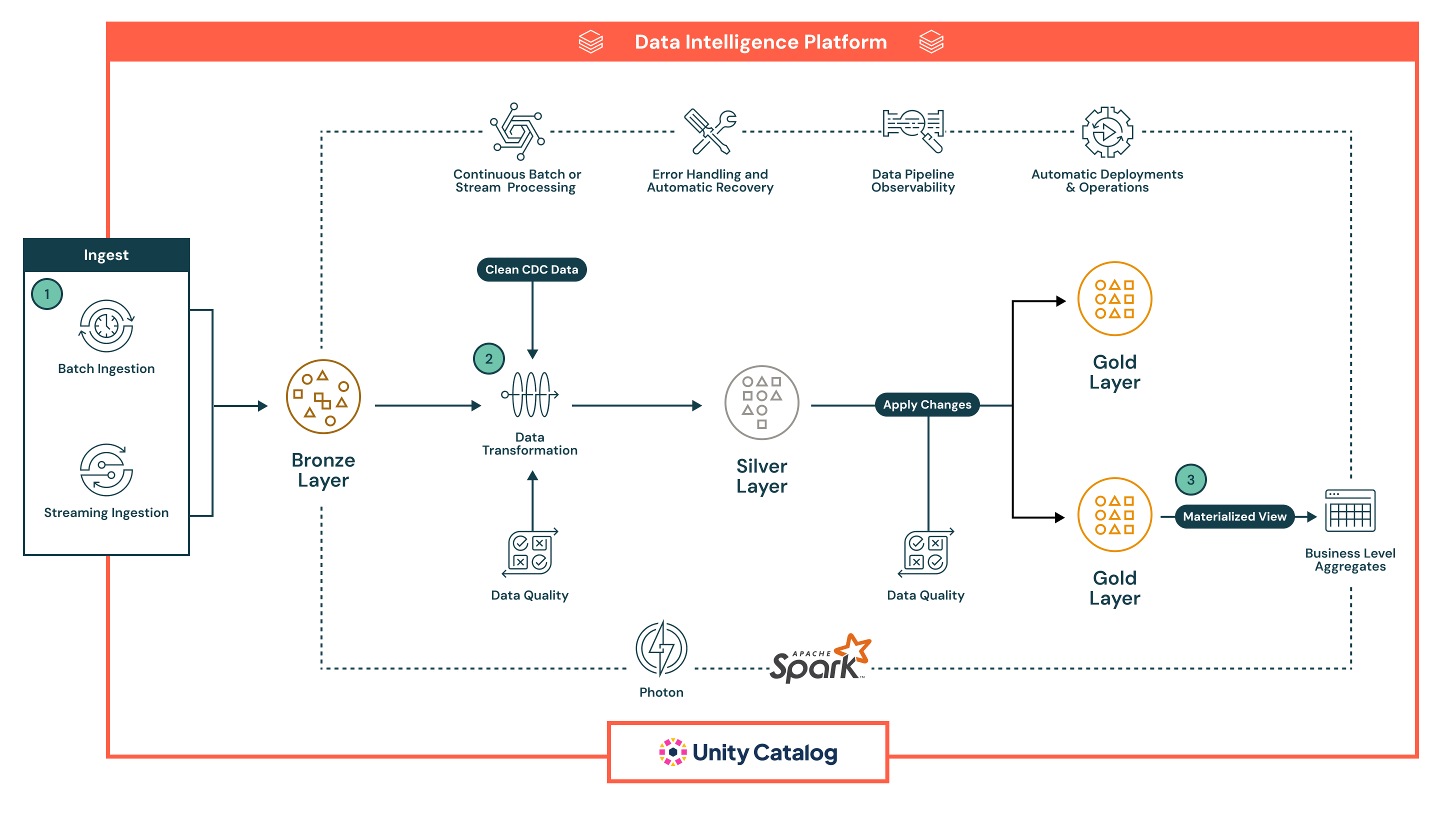
Neste exemplo, os dados primeiro aterrissam na camada Bronze em forma bruta para linhagem e reprocessamento seguro, depois progridem para a camada Silver , onde são limpos, enriquecidos, validados com verificações de qualidade em linha e processados em escala com o Spark, antes de chegar à camada Gold , que fornece conjuntos de dados selecionados e prontos para negócios para BI, aprendizado de máquina e casos de uso avançados, como rastreamento histórico.
Azure Data Factory
O Azure Data Factory (ADF) permite copiar dados de e para o Azure Databricks Delta Lake usando sua atividade de Cópia interna. Ao atuar como uma fonte, o ADF pode extrair dados de tabelas Delta no Databricks e movê-los para coletores suportados; ao atuar como um coletor, ele pode carregar dados em tabelas Delta Lake de fontes suportadas.
A movimentação de dados é orquestrada invocando seu cluster Databricks para lidar com a transferência, e o ADF dá suporte aos tempos de execução de integração do Azure e aos tempos de execução de integração auto-hospedados, dependendo do ambiente.
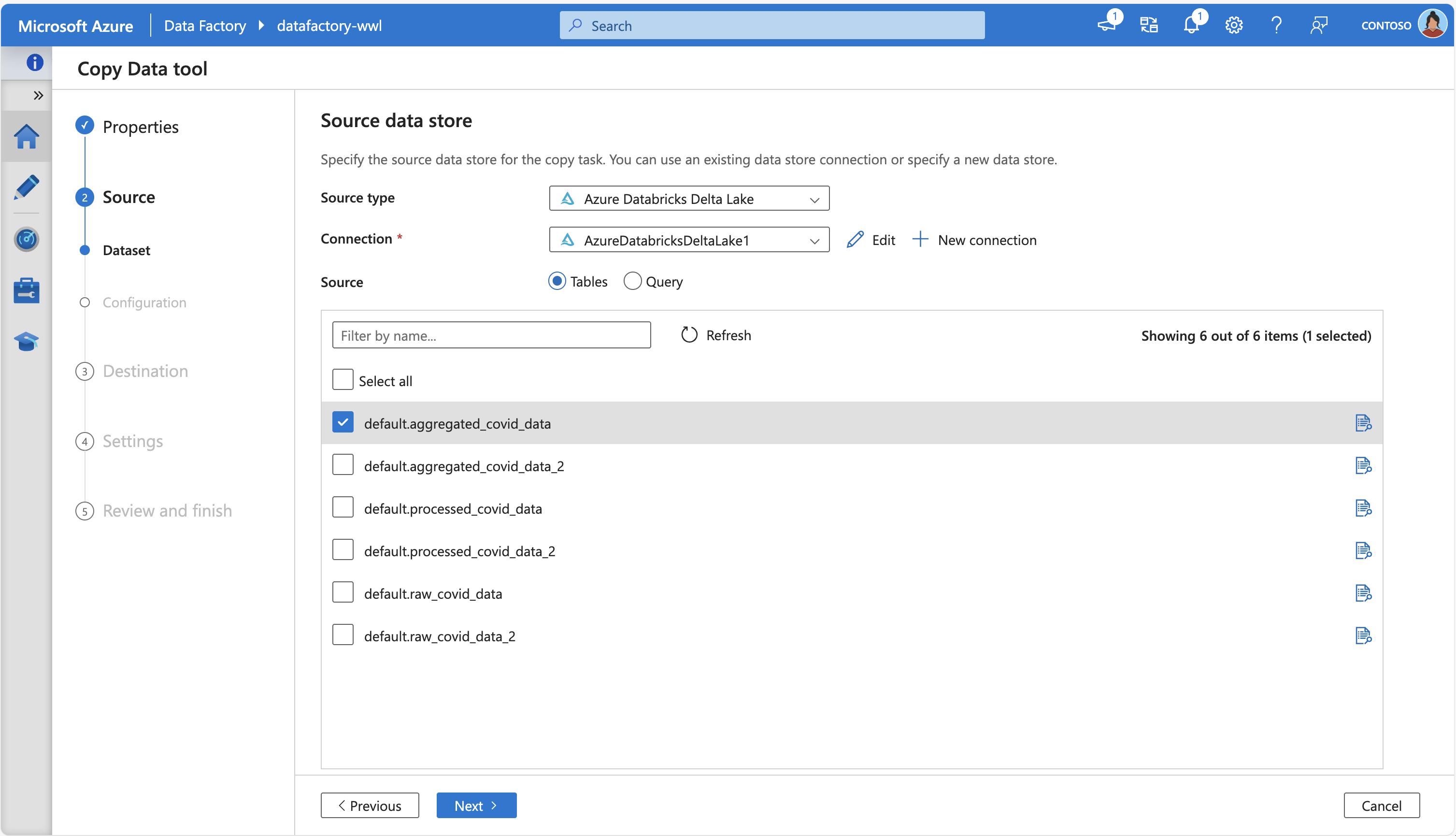
A captura de tela a seguir mostra a Ferramenta de Cópia de Dados do Azure Data Factory, conectando-se ao Azure Databricks Delta Lake para buscar algumas tabelas de origem:
Além disso, os Fluxos de Dados de Mapeamento do ADF oferecem uma experiência de ETL livre de código: eles podem originar e coletar dados no formato Delta no Armazenamento do Azure, permitindo transformações sem escrever código, executando no Tempo de Execução de Integração do Azure gerenciado.
Hubs de Eventos do Azure e Hubs IoT
Para ingestão de dados em tempo real, os Hubs de Eventos do Azure e os Hubs IoT são as opções mais adequadas. Eles permitem que você transmita dados diretamente para o Azure Databricks, permitindo que você processe e analise dados à medida que eles chegam. A ingestão e análise de dados em tempo real é útil para cenários como o monitoramento de eventos ao vivo ou o rastreamento de dados de dispositivos da Internet das Coisas (IoT).
Os Hubs de Eventos do Azure têm um ponto de extremidade compatível com Kafka que funciona com o conector Kafka de Streaming Estruturado no Databricks Runtime. Você pode configurar o Lakeflow Declarative Pipelines para se conectar numa instância do Event Hubs e consumir eventos de um tópico.