Conjuntos de dados de teste e treinamento
Os dados que usamos para treinar um modelo são frequentemente chamados de conjunto de dados de treinamento. Já vimos isso em ação. Frustrantemente, quando usamos o modelo no mundo real, após o treinamento, não sabemos ao certo como nosso modelo funcionará. Essa incerteza ocorre porque é possível que nosso conjunto de dados de treinamento seja diferente dos dados do mundo real.
O que é overfitting?
Um modelo é sobreadequado se funcionar melhor nos dados de treinamento do que em outros dados. O nome refere-se ao fato de que o modelo foi tão bem ajustado que memorizou detalhes do conjunto de treinamento, em vez de encontrar regras amplas que se aplicarão a outros dados. O overfitting é comum, mas não desejável. No final do dia, só nos preocupamos com o quão bem nosso modelo funciona em dados do mundo real.
Como podemos evitar o overfitting?
Podemos evitar o sobreajuste de várias maneiras. A maneira mais simples é ter um modelo mais simples, ou usar um conjunto de dados que seja uma representação melhor do que é visto no mundo real. Para entender esses métodos, considere um cenário em que os dados do mundo real tenham essa aparência:
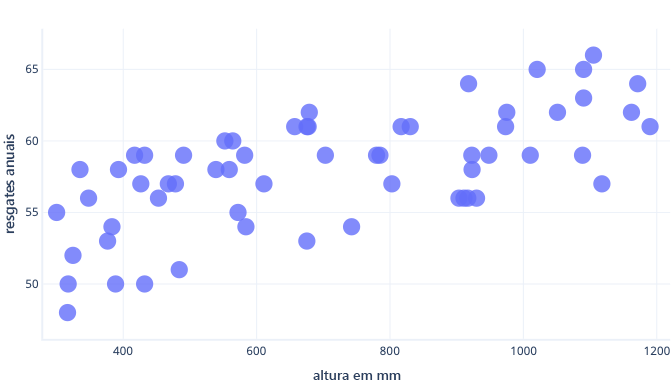
Digamos que coletamos informações sobre apenas cinco cães e usamos isso como nosso conjunto de dados de treinamento para se adequar a uma linha complexa. Se conseguirmos fazê-lo, podemos encaixá-lo muito bem:
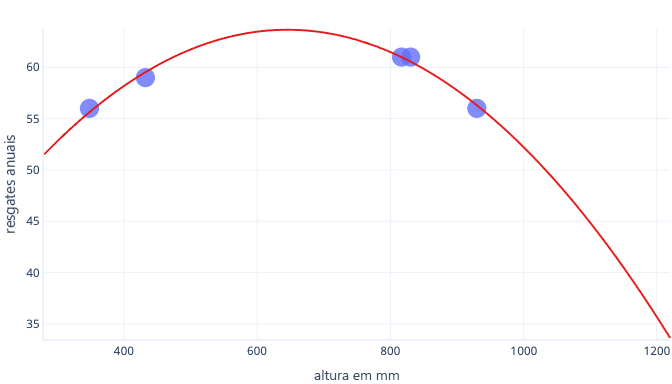
Quando isso é usado no mundo real, porém, descobriremos que ele faz previsões que acabam sendo erradas:
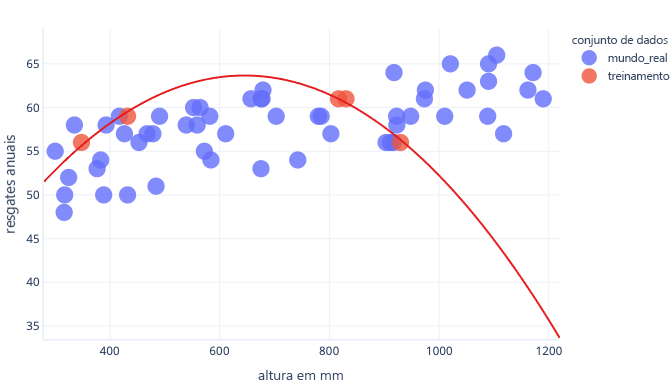
Se tivermos um conjunto de dados mais representativo e um modelo mais simples, a linha que encaixamos acaba por fazer previsões melhores (embora não perfeitas):
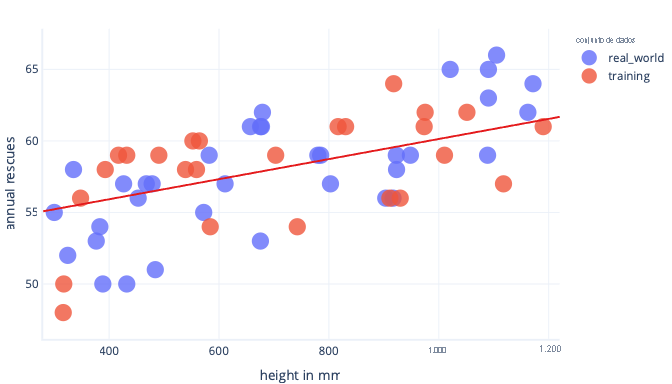
Uma maneira complementar de evitar o overfitting é parar de treinar depois que o modelo aprendeu as regras gerais, mas antes que o modelo seja overfit. No entanto, isso requer detetar quando estamos começando a sobreajustar nosso modelo. Podemos fazer isso usando um conjunto de dados de teste.
O que é um conjunto de dados de teste?
Um conjunto de dados de teste, também chamado de conjunto de dados de validação, é um conjunto de dados semelhante ao conjunto de dados de treinamento. Na verdade, os conjuntos de dados de teste geralmente são criados pegando um grande conjunto de dados e dividindo-o. Uma parte é chamada de conjunto de dados de treinamento e a outra é chamada de conjunto de dados de teste.
O trabalho do conjunto de dados de treinamento é treinar o modelo; Já vimos treinos. O trabalho do conjunto de dados de teste é verificar como o modelo funciona; não contribui diretamente para a formação.
OK, mas qual é o objetivo?
O ponto de um conjunto de dados de teste é duplo.
Primeiro, se o desempenho do teste parar de melhorar durante o treinamento, podemos parar; não vale a pena continuar. Se continuarmos, podemos acabar incentivando o modelo a aprender detalhes sobre o conjunto de dados de treinamento que não estão no conjunto de dados de teste, o que é overfitting.
Em segundo lugar, podemos usar um conjunto de dados de teste após o treinamento. Isso nos dá uma indicação de quão bem o modelo final funcionará quando ele vê dados do "mundo real" que não viu antes.
O que isso significa para as funções de custo?
Quando usamos conjuntos de dados de treinamento e teste, acabamos calculando duas funções de custo.
A primeira função de custo é usar o conjunto de dados de treinamento, assim como vimos antes. Esta função de custo é alimentada para o otimizador e usada para treinar o modelo.
A segunda função de custo é calculada usando o conjunto de dados de teste. Usamos isso para verificar o quão bem o modelo pode funcionar no mundo real. O resultado da função de custo não é usado para treinar o modelo. Para calcular isso, pausamos o treinamento, examinamos o desempenho do modelo em um conjunto de dados de teste e, em seguida, retomamos o treinamento.