Conceitos de redes neurais profundas
Antes de explorar como treinar um modelo de aprendizado de máquina de rede neural profunda (DNN), vamos considerar o que estamos tentando alcançar. O aprendizado de máquina está preocupado em prever um rótulo com base em algumas características de uma observação específica. Em termos simples, um modelo de aprendizado de máquina é uma função que calcula y (o rótulo) a partir de x (os recursos): f(x)=y.
Um exemplo de classificação simples
Por exemplo, suponha que sua observação consiste em algumas medidas de um pinguim.

Especificamente, as medidas são:
- O comprimento do bico do pinguim.
- A profundidade do bico do pinguim.
- O comprimento da barbatana do pinguim.
- O peso do pinguim.
Neste caso, as características (x) são um vetor de quatro valores, ou matematicamente, x=[x1,x2,x3,x4].
Vamos supor que o rótulo que estamos tentando prever (y) é a espécie do pinguim, e que existem três espécies possíveis que poderiam ser:
- Adélia
- Gentoo
- Chinstrap
Este é um exemplo de um problema de classificação , no qual o modelo de aprendizado de máquina deve prever a classe mais provável à qual a observação pertence. Um modelo de classificação consegue isso prevendo um rótulo que consiste na probabilidade para cada classe. Em outras palavras, y é um vetor de três valores de probabilidade; uma para cada uma das classes possíveis: y=[P(0),P(1),P(2)].
Você treina o modelo de aprendizado de máquina usando observações para as quais já conhece o rótulo verdadeiro. Por exemplo, pode ter as seguintes medidas de características para um espécime Adelie :
x=[37,3; 16,8; 19,2, 30,0]
Você já sabe que este é um exemplo de Adélia (classe 0), então uma função de classificação perfeita deve resultar em um rótulo que indique uma probabilidade de 100% para a classe 0 e uma probabilidade de 0% para as classes 1 e 2:
y=[1, 0, 0]
Um modelo de rede neural profunda
Então, como usaríamos o deep learning para construir um modelo de classificação para o modelo de classificação de pinguins? Vejamos um exemplo:
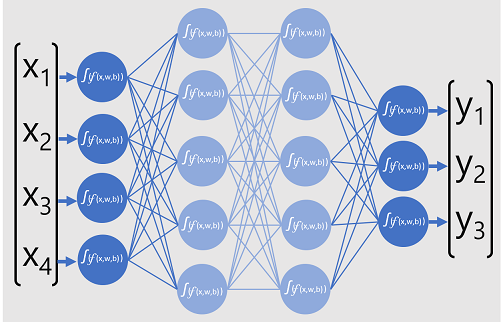
O modelo de rede neural profunda para o classificador consiste em várias camadas de neurônios artificiais. Neste caso, existem quatro camadas:
- Uma camada de entrada com um neurônio para cada valor de entrada esperado (x).
- Duas chamadas camadas ocultas , cada uma contendo cinco neurônios.
- Uma camada de saída contendo três neurônios - um para cada valor de probabilidade de classe (y) a ser previsto pelo modelo.
Devido à arquitetura em camadas da rede, este tipo de modelo é por vezes referido como um perceptron multicamadas. Além disso, observe que todos os neurônios nas camadas de entrada e ocultas estão conectados a todos os neurônios nas camadas subsequentes - este é um exemplo de uma rede totalmente conectada.
Ao criar um modelo como este, você deve definir uma camada de entrada que suporte o número de recursos que seu modelo processará e uma camada de saída que reflita o número de saídas que você espera que ele produza. Você pode decidir quantas camadas ocultas deseja incluir e quantos neurônios estão em cada uma delas; Mas você não tem controle sobre os valores de entrada e saída para essas camadas - eles são determinados pelo processo de treinamento do modelo.
Treinando uma rede neural profunda
O processo de formação para uma rede neural profunda consiste em múltiplas iterações, chamadas épocas. Para a primeira era, começas atribuindo valores de inicialização aleatórios para os pesos (w) e viés b. Em seguida, o processo é o seguinte:
- Os recursos para observações de dados com valores de rótulo conhecidos são enviados para a camada de entrada. Geralmente, essas observações são agrupadas em lotes (muitas vezes referidos como minilotes).
- Os neurônios então aplicam sua função e, se ativados, passam o resultado para a próxima camada até que a camada de saída produza uma previsão.
- A previsão é comparada com o valor real conhecido, e a quantidade de variância entre os valores previstos e verdadeiros (que chamamos de perda) é calculada.
- Com base nos resultados, valores revisados para os pesos e valores de viés são calculados para reduzir a perda, e esses ajustes são retropropagados para os neurônios nas camadas de rede.
- A próxima época repete o passe de treinamento em lote com os valores de peso e viés revisados, esperançosamente melhorando a precisão do modelo (reduzindo a perda).
Nota
O processamento dos recursos de treinamento como um lote melhora a eficiência do processo de treinamento processando múltiplas observações simultaneamente como uma matriz de características com vetores de pesos e vieses. Funções algébricas lineares que operam com matrizes e vetores também estão presentes no processamento gráfico 3D, e é por isso que computadores com unidades de processamento gráfico (GPUs) fornecem um desempenho significativamente melhor para treinamento de modelos de aprendizagem profunda do que apenas computadores com unidades centrais de processamento (CPU).
Um olhar mais atento sobre as funções de perda e retropropagação
A descrição anterior do processo de treinamento de deep learning mencionou que a perda do modelo é calculada e usada para ajustar os valores de peso e viés. Como funciona exatamente?
Cálculo das perdas
Suponhamos que uma das amostras passadas pelo processo de treinamento contenha características de um espécime de Adélia (classe 0). A saída correta da rede seria [1, 0, 0]. Agora suponha que a saída produzida pela rede é [0,4, 0,3, 0,3]. Comparando-os, podemos calcular uma variância absoluta para cada elemento (em outras palavras, quão longe cada valor previsto está longe do que deveria ser) como [0,6, 0,3, 0,3].
Na realidade, como estamos lidando com várias observações, normalmente agregamos a variância - por exemplo, quadrando os valores de variância individuais e calculando a média, então acabamos com um único valor de perda média, como 0,18.
Otimizadores
Agora, aqui está a parte inteligente. A perda é calculada usando uma função, que opera sobre os resultados da camada final da rede, que também é uma função. A camada final da rede opera nas saídas das camadas anteriores, que também são funções. Então, na verdade, todo o modelo, desde a camada de entrada até o cálculo de perdas, é apenas uma grande função aninhada. As funções têm algumas características realmente úteis, incluindo:
- Você pode conceituar uma função como uma linha plotada comparando sua saída com cada uma de suas variáveis.
- Você pode usar o cálculo diferencial para calcular a derivada da função em qualquer ponto em relação às suas variáveis.
Vamos pegar o primeiro desses recursos. Podemos plotar a linha da função para mostrar como um valor de peso individual se compara à perda e marcar nessa linha o ponto em que o valor de peso atual corresponde ao valor de perda atual.
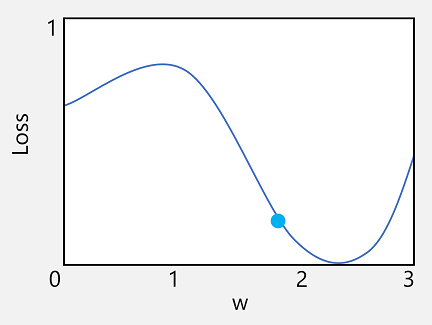
Agora vamos aplicar a segunda característica de uma função. A derivada de uma função para um determinado ponto indica se a inclinação (ou gradiente) da saída da função (neste caso, perda) está aumentando ou diminuindo em relação a uma variável de função (neste caso, o valor de peso). Uma derivada positiva indica que a função está aumentando, e uma derivada negativa indica que ela está diminuindo. Neste caso, no ponto plotado para o valor de peso atual, a função tem um gradiente descendente. Ou seja, aumentar o peso terá o efeito de diminuir a perda.
Usamos um otimizador para aplicar esse mesmo truque para todas as variáveis de peso e viés no modelo e determinar em que direção precisamos ajustá-las (para cima ou para baixo) para reduzir a quantidade total de perda no modelo. Existem vários algoritmos de otimização comumente usados, incluindo descida de gradiente estocástico (SGD),Taxa de Aprendizagem Adaptativa (ADADELTA),Estimativa de Momento Adaptativo (Adam) e outros; todos os quais são projetados para descobrir como ajustar os pesos e vieses para minimizar a perda.
Taxa de aprendizagem
Agora, a próxima pergunta óbvia é: por quanto o otimizador deve ajustar os pesos e valores de polarização? Se você olhar para o gráfico para o nosso valor de peso, você pode ver que aumentar o peso em uma pequena quantidade seguirá a linha de função para baixo (reduzindo a perda), mas se aumentarmos muito, a linha de função começa a subir novamente, então podemos realmente aumentar a perda; E depois da próxima época, podemos achar que precisamos reduzir o peso.
O tamanho do ajuste é controlado por um parâmetro que você define para o treinamento chamado taxa de aprendizagem. Uma baixa taxa de aprendizagem resulta em pequenos ajustes (para que possa levar mais épocas para minimizar a perda), enquanto uma alta taxa de aprendizagem resulta em grandes ajustes (então você pode perder o mínimo completamente).