Conheça o Spark
Para obter uma melhor compreensão de como processar e analisar dados com o Apache Spark no Azure Databricks, é importante entender a arquitetura subjacente.
Descrição geral de alto nível
A partir de um nível alto, o serviço Azure Databricks inicia e gerencia clusters Apache Spark em sua assinatura do Azure. Os clusters Apache Spark são grupos de computadores que são tratados como um único computador e lidam com a execução de comandos emitidos a partir de notebooks. Os clusters permitem que o processamento de dados seja paralelizado em muitos computadores para melhorar a escala e o desempenho. Eles consistem em um driver Spark e nós de trabalho. O nó do driver envia trabalho para os nós de trabalho e os instrui a extrair dados de uma fonte de dados especificada.
No Databricks, a interface do notebook é normalmente o programa de driver. Este programa de driver contém o loop principal para o programa e cria conjuntos de dados distribuídos no cluster e, em seguida, aplica operações a esses conjuntos de dados. Os programas de driver acessam o Apache Spark por meio de um objeto SparkSession , independentemente do local de implantação.
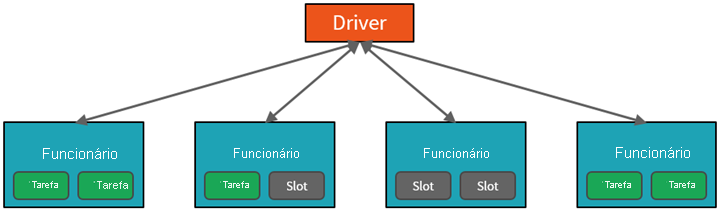
O Microsoft Azure gerencia o cluster e o dimensiona automaticamente conforme necessário com base no seu uso e na configuração usada ao configurar o cluster. O encerramento automático também pode ser habilitado, o que permite que o Azure encerre o cluster após um número especificado de minutos de inatividade.
Trabalhos de faísca em detalhes
O trabalho enviado para o cluster é dividido em quantos trabalhos independentes forem necessários. É assim que o trabalho é distribuído pelos nós do Cluster. Os trabalhos são subdivididos em tarefas. A entrada para um trabalho é particionada em uma ou mais partições. Estas divisórias são a unidade de trabalho para cada slot. Entre as tarefas, as partições podem precisar ser reorganizadas e compartilhadas pela rede.
O segredo para o alto desempenho do Spark é o paralelismo. O dimensionamento vertical (adicionando recursos a um único computador) é limitado a uma quantidade finita de RAM, Threads e velocidades de CPU, mas os clusters são dimensionados horizontalmente, adicionando novos nós ao cluster conforme necessário.
O Spark paraleliza trabalhos em dois níveis:
- O primeiro nível de paralelização é o executor - uma máquina virtual Java (JVM) em execução em um nó de trabalho, normalmente, uma instância por nó.
- O segundo nível de paralelização é o slot - cujo número é determinado pelo número de núcleos e CPUs de cada nó.
- Cada executor tem vários slots aos quais tarefas paralelizadas podem ser atribuídas.
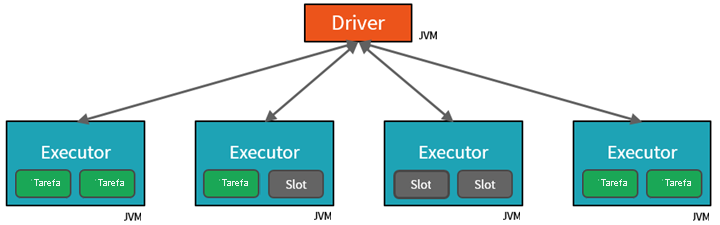
A JVM é naturalmente multi-threaded, mas uma única JVM, como a que coordena o trabalho no driver, tem um limite superior finito. Ao dividir o trabalho em tarefas, o driver pode atribuir unidades de trabalho a *slots nos executores em nós de trabalho para execução paralela. Além disso, o driver determina como particionar os dados para que eles possam ser distribuídos para processamento paralelo. Assim, o driver atribui uma partição de dados a cada tarefa para que cada tarefa saiba qual parte de dados deve processar. Uma vez iniciada, cada tarefa buscará a partição de dados atribuída a ela.
Trabalhos e estágios
Dependendo do trabalho que está sendo executado, vários trabalhos paralelos podem ser necessários. Cada trabalho é dividido em etapas. Uma analogia útil é imaginar que o trabalho é construir uma casa:
- A primeira etapa seria lançar as bases.
- A segunda etapa seria erguer as paredes.
- A terceira etapa seria adicionar o telhado.
Tentar fazer qualquer um desses passos fora de ordem simplesmente não faz sentido, e pode de fato ser impossível. Da mesma forma, o Spark divide cada trabalho em etapas para garantir que tudo seja feito na ordem certa.