Visualizar dados em um bloco de anotações do Spark
Uma das maneiras mais intuitivas de analisar os resultados de consultas de dados é visualizá-los como gráficos. Os blocos de anotações no Microsoft Fabric fornecem alguns recursos básicos de gráficos na interface do usuário e, quando essa funcionalidade não fornece o que você precisa, você pode usar uma das muitas bibliotecas de gráficos Python para criar e exibir visualizações de dados no bloco de anotações.
Usando gráficos de bloco de anotações integrados
Quando você exibe um dataframe ou executa uma consulta SQL em um bloco de anotações do Spark, os resultados são exibidos na célula de código. Por padrão, os resultados são renderizados como uma tabela, mas você também pode alterar a exibição de resultados para um gráfico e usar as propriedades do gráfico para personalizar como o gráfico visualiza os dados, conforme mostrado aqui:
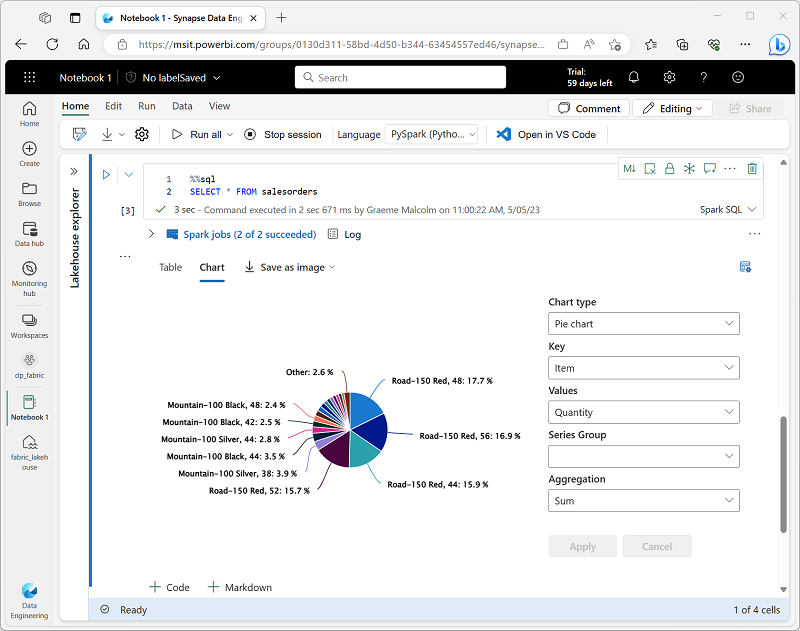
A funcionalidade de gráficos integrada em blocos de anotações é útil quando você deseja resumir rapidamente os dados visualmente. Quando quiser ter mais controle sobre como os dados são formatados, considere o uso de um pacote gráfico para criar suas próprias visualizações.
Usando pacotes gráficos no código
Há muitos pacotes gráficos que você pode usar para criar visualizações de dados no código. Em particular, Python suporta uma grande seleção de pacotes; a maioria deles construída na base da biblioteca Matplotlib . A saída de uma biblioteca de gráficos pode ser renderizada em um bloco de anotações, facilitando a combinação de código para ingerir e manipular dados com visualizações de dados embutidas e células de marcação para fornecer comentários.
Por exemplo, você pode usar o seguinte código PySpark para agregar dados dos dados de produtos hipotéticos explorados anteriormente neste módulo e usar Matplotlib para criar um gráfico a partir dos dados agregados.
from matplotlib import pyplot as plt
# Get the data as a Pandas dataframe
data = spark.sql("SELECT Category, COUNT(ProductID) AS ProductCount \
FROM products \
GROUP BY Category \
ORDER BY Category").toPandas()
# Clear the plot area
plt.clf()
# Create a Figure
fig = plt.figure(figsize=(12,8))
# Create a bar plot of product counts by category
plt.bar(x=data['Category'], height=data['ProductCount'], color='orange')
# Customize the chart
plt.title('Product Counts by Category')
plt.xlabel('Category')
plt.ylabel('Products')
plt.grid(color='#95a5a6', linestyle='--', linewidth=2, axis='y', alpha=0.7)
plt.xticks(rotation=70)
# Show the plot area
plt.show()
A biblioteca Matplotlib requer que os dados estejam em um dataframe Pandas em vez de um dataframe Spark, portanto, o método toPandas é usado para convertê-lo. Em seguida, o código cria uma figura com um tamanho especificado e plota um gráfico de barras com alguma configuração de propriedade personalizada antes de mostrar o gráfico resultante.
O gráfico produzido pelo código seria semelhante à seguinte imagem:
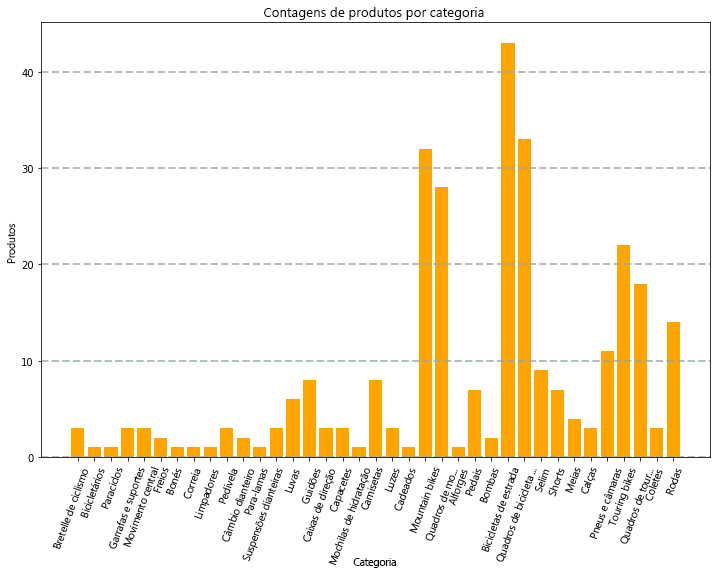
Você pode usar a biblioteca Matplotlib para criar muitos tipos de gráfico; ou, se preferir, você pode usar outras bibliotecas, como Seaborn , para criar gráficos altamente personalizados.