Nota
O acesso a esta página requer autorização. Pode tentar iniciar sessão ou alterar os diretórios.
O acesso a esta página requer autorização. Pode tentar alterar os diretórios.
Aplica-se a: SQL Server
Este artigo fornece etapas de solução de problemas para um problema de desempenho em que uma consulta é executada mais lentamente em um servidor do que em outro.
Sintomas
Suponha que haja dois servidores com o SQL Server instalado. Uma das instâncias do SQL Server contém uma cópia de um banco de dados na outra instância do SQL Server. Quando você executa uma consulta nos bancos de dados em ambos os servidores, a consulta é executada mais lentamente em um servidor do que no outro.
As etapas a seguir podem ajudar a solucionar esse problema.
Etapa 1: Determinar se é um problema comum com várias consultas
Use um dos dois métodos a seguir para comparar o desempenho de duas ou mais consultas nos dois servidores:
Teste manualmente as consultas em ambos os servidores:
- Escolha várias consultas para teste com prioridade colocada em consultas que são:
- Significativamente mais rápido em um servidor do que no outro.
- Importante para o usuário/aplicativo.
- Frequentemente executado ou projetado para reproduzir o problema sob demanda.
- Suficientemente longo para capturar dados nele (por exemplo, em vez de uma consulta de 5 milissegundos, escolha uma consulta de 10 segundos).
- Execute as consultas nos dois servidores.
- Compare o tempo decorrido (duração) em dois servidores para cada consulta.
- Escolha várias consultas para teste com prioridade colocada em consultas que são:
Analise dados de desempenho com o SQL Nexus.
- Colete dados PSSDiag/SQLdiag ou SQL LogScout para as consultas nos dois servidores.
- Importe os arquivos de dados coletados com o SQL Nexus e compare as consultas dos dois servidores. Para obter mais informações, consulte Comparação de desempenho entre duas coleções de logs (lenta e rápida, por exemplo).
Cenário 1: Apenas uma única consulta é executada de forma diferente nos dois servidores
Se apenas uma consulta tiver um desempenho diferente, é mais provável que o problema seja específico da consulta individual do que do ambiente. Nesse caso, vá para Etapa 2: Coletar dados e determinar o tipo de problema de desempenho.
Cenário 2: Várias consultas são executadas de forma diferente nos dois servidores
Se várias consultas forem executadas mais lentamente em um servidor do que no outro, a causa mais provável serão as diferenças no servidor ou no ambiente de dados. Vá para Diagnosticar diferenças de ambiente e veja se a comparação entre os dois servidores é válida.
Etapa 2: coletar dados e determinar o tipo de problema de desempenho
Colete o tempo decorrido, o tempo de CPU e as leituras lógicas
Para coletar o tempo decorrido e o tempo de CPU da consulta em ambos os servidores, use um dos seguintes métodos que melhor se adapte à sua situação:
Para instruções em execução no momento, verifique total_elapsed_time e cpu_time colunas em sys.dm_exec_requests. Execute a seguinte consulta para obter os dados:
SELECT req.session_id , req.total_elapsed_time AS duration_ms , req.cpu_time AS cpu_time_ms , req.total_elapsed_time - req.cpu_time AS wait_time , req.logical_reads , SUBSTRING (REPLACE (REPLACE (SUBSTRING (ST.text, (req.statement_start_offset/2) + 1, ((CASE statement_end_offset WHEN -1 THEN DATALENGTH(ST.text) ELSE req.statement_end_offset END - req.statement_start_offset)/2) + 1) , CHAR(10), ' '), CHAR(13), ' '), 1, 512) AS statement_text FROM sys.dm_exec_requests AS req CROSS APPLY sys.dm_exec_sql_text(req.sql_handle) AS ST ORDER BY total_elapsed_time DESC;Para execuções anteriores da consulta, verifique last_elapsed_time e last_worker_time colunas em sys.dm_exec_query_stats. Execute a seguinte consulta para obter os dados:
SELECT t.text, (qs.total_elapsed_time/1000) / qs.execution_count AS avg_elapsed_time, (qs.total_worker_time/1000) / qs.execution_count AS avg_cpu_time, ((qs.total_elapsed_time/1000) / qs.execution_count ) - ((qs.total_worker_time/1000) / qs.execution_count) AS avg_wait_time, qs.total_logical_reads / qs.execution_count AS avg_logical_reads, qs.total_logical_writes / qs.execution_count AS avg_writes, (qs.total_elapsed_time/1000) AS cumulative_elapsed_time_all_executions FROM sys.dm_exec_query_stats qs CROSS apply sys.Dm_exec_sql_text (sql_handle) t WHERE t.text like '<Your Query>%' -- Replace <Your Query> with your query or the beginning part of your query. The special chars like '[','_','%','^' in the query should be escaped. ORDER BY (qs.total_elapsed_time / qs.execution_count) DESCObservação
Se
avg_wait_timemostrar um valor negativo, será uma consulta paralela.Se você puder executar a consulta sob demanda no SQL Server Management Studio (SSMS) ou no Azure Data Studio, execute-a com SET STATISTICS TIME
ONe SET STATISTICS IOON.SET STATISTICS TIME ON SET STATISTICS IO ON <YourQuery> SET STATISTICS IO OFF SET STATISTICS TIME OFFEm seguida, em Mensagens, você verá o tempo de CPU, o tempo decorrido e as leituras lógicas como esta:
Table 'tblTest'. Scan count 1, logical reads 3, physical reads 0, page server reads 0, read-ahead reads 0, page server read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob page server reads 0, lob read-ahead reads 0, lob page server read-ahead reads 0. SQL Server Execution Times: CPU time = 460 ms, elapsed time = 470 ms.Se você puder coletar um plano de consulta, verifique os dados nas propriedades do plano de execução.
Execute a consulta com Incluir Plano de Execução Real ativado.
Selecione o operador mais à esquerda em Plano de execução.
Em Propriedades, expanda a propriedade QueryTimeStats .
Verifique ElapsedTime e CpuTime.
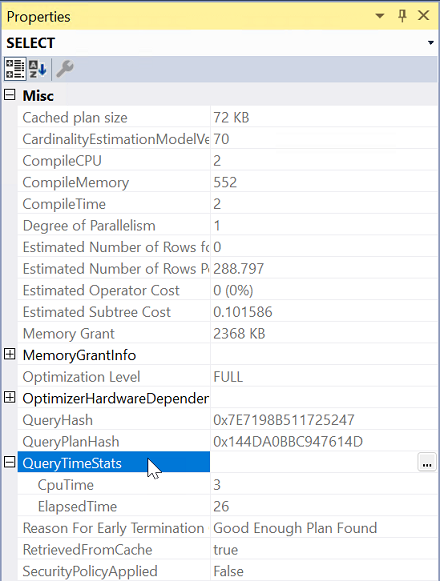
Compare o tempo decorrido e o tempo de CPU da consulta para determinar o tipo de problema para ambos os servidores.
Tipo 1: vinculado à CPU (runner)
Se o tempo de CPU for próximo, igual ou maior que o tempo decorrido, você poderá tratá-lo como uma consulta associada à CPU. Por exemplo, se o tempo decorrido for de 3000 milissegundos (ms) e o tempo de CPU for de 2900 ms, isso significa que a maior parte do tempo decorrido será gasto na CPU. Então podemos dizer que é uma consulta vinculada à CPU.
Exemplos de consultas em execução (associadas à CPU):
| Tempo decorrido (ms) | Tempo de CPU (ms) | Leituras (lógicas) |
|---|---|---|
| 3200 | 3000 | 300000 |
| 1080 | 1000 | 20 |
As leituras lógicas - leitura de páginas de dados/índice no cache - são mais freqüentemente os impulsionadores da utilização da CPU no SQL Server. Pode haver cenários em que o uso da CPU vem de outras fontes: um loop while (em T-SQL ou outro código como objetos XProcs ou SQL CRL). O segundo exemplo na tabela ilustra esse cenário, em que a maioria da CPU não é de leituras.
Observação
Se o tempo da CPU for maior que a duração, isso indica que uma consulta paralela foi executada; vários threads estão usando a CPU ao mesmo tempo. Para obter mais informações, consulte Consultas paralelas - executor ou garçom.
Tipo 2: Esperando por um gargalo (garçom)
Uma consulta está aguardando um afunilamento se o tempo decorrido for significativamente maior que o tempo de CPU. O tempo decorrido inclui o tempo de execução da consulta na CPU (tempo de CPU) e o tempo de espera para que um recurso seja liberado (tempo de espera). Por exemplo, se o tempo decorrido for de 2000 ms e o tempo de CPU for de 300 ms, o tempo de espera será de 1700 ms (2000 - 300 = 1700). Para obter mais informações, consulte Tipos de esperas.
Exemplos de consultas em espera:
| Tempo decorrido (ms) | Tempo de CPU (ms) | Leituras (lógicas) |
|---|---|---|
| 2000 | 300 | 28000 |
| 10080 | 700 | 80000 |
Consultas paralelas - executor ou garçom
As consultas paralelas podem usar mais tempo de CPU do que a duração geral. O objetivo do paralelismo é permitir que vários threads executem partes de uma consulta simultaneamente. Em um segundo de tempo de clock, uma consulta pode usar oito segundos de tempo de CPU executando oito threads paralelos. Portanto, torna-se um desafio determinar uma consulta associada à CPU ou em espera com base no tempo decorrido e na diferença de tempo da CPU. No entanto, como regra geral, siga os princípios listados nas duas seções acima. O resumo é:
- Se o tempo decorrido for muito maior que o tempo da CPU, considere-o um garçom.
- Se o tempo da CPU for muito maior do que o tempo decorrido, considere-o um executor.
Exemplos de consultas paralelas:
| Tempo decorrido (ms) | Tempo de CPU (ms) | Leituras (lógicas) |
|---|---|---|
| 1200 | 8100 | 850000 |
| 3080 | 12300 | 1.500.000 |
Etapa 3: Compare os dados de ambos os servidores, descubra o cenário e solucione o problema
Vamos supor que haja duas máquinas chamadas Server1 e Server2. E a consulta é executada mais lentamente no Server1 do que no Server2. Compare os tempos de ambos os servidores e siga as ações do cenário que melhor corresponde ao seu nas seções a seguir.
Cenário 1: A consulta no Servidor1 usa mais tempo de CPU e as leituras lógicas são maiores no Servidor1 do que no Servidor2
Se o tempo de CPU no Servidor1 for muito maior do que no Servidor2 e o tempo decorrido corresponder ao tempo de CPU em ambos os servidores, não haverá grandes esperas ou gargalos. O aumento no tempo de CPU no Server1 é provavelmente causado por um aumento nas leituras lógicas. Uma alteração significativa nas leituras lógicas normalmente indica uma diferença nos planos de consulta. Por exemplo:
| Servidor | Tempo decorrido (ms) | Tempo de CPU (ms) | Leituras (lógicas) |
|---|---|---|---|
| Servidor1 | 3100 | 3000 | 300000 |
| Servidor2 | 1100 | 1000 | 90200 |
Ação: Verificar planos de execução e ambientes
- Compare os planos de execução da consulta em ambos os servidores. Para fazer isso, use um dos dois métodos:
- Compare os planos de execução visualmente. Para obter mais informações, confira Exibir um plano de execução real.
- Salve os planos de execução e compare-os usando o recurso Comparação de Planos do SQL Server Management Studio.
- Compare ambientes. Ambientes diferentes podem levar a diferenças no plano de consulta ou diferenças diretas no uso da CPU. Os ambientes incluem versões de servidor, definições de configuração de banco de dados ou servidor, sinalizadores de rastreamento, contagem de CPU ou velocidade de clock e máquina virtual versus máquina física. Consulte Diagnosticar diferenças de plano de consulta para obter detalhes.
Cenário 2: A consulta é um garçom no Servidor1, mas não no Servidor2
Se os tempos de CPU para a consulta em ambos os servidores forem semelhantes, mas o tempo decorrido no Servidor1 for muito maior do que no Servidor2, a consulta no Servidor1 gastará muito mais tempo aguardando um afunilamento. Por exemplo:
| Servidor | Tempo decorrido (ms) | Tempo de CPU (ms) | Leituras (lógicas) |
|---|---|---|---|
| Servidor1 | 4500 | 1000 | 90200 |
| Servidor2 | 1100 | 1000 | 90200 |
- Tempo de espera no Server1: 4500 - 1000 = 3500 ms
- Tempo de espera no Server2: 1100 - 1000 = 100 ms
Ação: Verificar tipos de espera no Server1
Identifique e elimine o gargalo no Server1. Exemplos de esperas são bloqueios (esperas de bloqueio), esperas de trava, esperas de E/S de disco, esperas de rede e esperas de memória. Para solucionar problemas comuns de gargalo, prossiga para Diagnosticar esperas ou gargalos.
Cenário 3: As consultas em ambos os servidores são waiters, mas os tipos ou tempos de espera são diferentes
Por exemplo:
| Servidor | Tempo decorrido (ms) | Tempo de CPU (ms) | Leituras (lógicas) |
|---|---|---|---|
| Servidor1 | 8000 | 1000 | 90200 |
| Servidor2 | 3000 | 1000 | 90200 |
- Tempo de espera no Server1: 8000 - 1000 = 7000 ms
- Tempo de espera no Server2: 3000 - 1000 = 2000 ms
Nesse caso, os tempos de CPU são semelhantes em ambos os servidores, o que indica que os planos de consulta provavelmente são os mesmos. As consultas teriam um desempenho igual em ambos os servidores se não esperassem pelos gargalos. Portanto, as diferenças de duração vêm das diferentes quantidades de tempo de espera. Por exemplo, a consulta aguarda bloqueios no Servidor1 por 7000 ms enquanto aguarda a E/S no Servidor2 por 2000 ms.
Ação: Verificar os tipos de espera em ambos os servidores
Resolva cada gargalo, espere individualmente em cada servidor e acelere as execuções em ambos os servidores. A solução desse problema é trabalhosa porque você precisa eliminar gargalos em ambos os servidores e tornar o desempenho comparável. Para solucionar problemas comuns de gargalo, prossiga para Diagnosticar esperas ou gargalos.
Cenário 4: a consulta no Servidor1 usa mais tempo de CPU do que no Servidor2, mas as leituras lógicas estão próximas
Por exemplo:
| Servidor | Tempo decorrido (ms) | Tempo de CPU (ms) | Leituras (lógicas) |
|---|---|---|---|
| Servidor1 | 3000 | 3000 | 90200 |
| Servidor2 | 1000 | 1000 | 90200 |
Se os dados corresponderem às seguintes condições:
- O tempo de CPU no Servidor1 é muito maior do que no Servidor2.
- O tempo decorrido corresponde ao tempo da CPU em cada servidor, o que indica que não há esperas.
- As leituras lógicas, normalmente o maior driver de tempo de CPU, são semelhantes em ambos os servidores.
Em seguida, o tempo adicional de CPU vem de algumas outras atividades vinculadas à CPU. Este cenário é o mais raro de todos os cenários.
Causas: Rastreamento, UDFs e integração CLR
Esse problema pode ser causado por:
- Rastreamento XEvents/SQL Server, especialmente com filtragem em colunas de texto (nome do banco de dados, nome de logon, texto da consulta e assim por diante). Se o rastreamento estiver habilitado em um servidor, mas não no outro, esse pode ser o motivo da diferença.
- UDFs (funções definidas pelo usuário) ou outro código T-SQL que executa operações associadas à CPU. Normalmente, essa seria a causa quando outras condições são diferentes no Server1 e no Server2, como tamanho dos dados, velocidade do clock da CPU ou plano de energia.
- Integração CLR do SQL Server ou XPs (procedimentos armazenados estendidos) que podem conduzir a CPU, mas não executam leituras lógicas. Diferenças nas DLLs podem levar a tempos de CPU diferentes.
- Diferença na funcionalidade do SQL Server associada à CPU (por exemplo, código de manipulação de cadeia de caracteres).
Ação: verificar rastreamentos e consultas
Verifique os rastreamentos em ambos os servidores para o seguinte:
- Se houver algum rastreamento habilitado no Server1, mas não no Server2.
- Se algum rastreamento estiver habilitado, desabilite o rastreamento e execute a consulta novamente no Server1.
- Se a consulta for executada mais rápido desta vez, habilite o rastreamento de volta, mas remova os filtros de texto dele, se houver.
Verifique se a consulta usa UDFs que fazem manipulações de cadeia de caracteres ou fazem processamento extensivo em colunas de dados na
SELECTlista.Verifique se a consulta contém loops, recursões de função ou aninhamentos.
Diagnosticar diferenças de ambiente
Verifique as perguntas a seguir e determine se a comparação entre os dois servidores é válida.
As duas instâncias do SQL Server são a mesma versão ou compilação?
Caso contrário, pode haver algumas correções que causaram as diferenças. Execute a seguinte consulta para obter informações de versão em ambos os servidores:
SELECT @@VERSIONA quantidade de memória física é semelhante em ambos os servidores?
Se um servidor tiver 64 GB de memória enquanto o outro tiver 256 GB de memória, isso seria uma diferença significativa. Com mais memória disponível para armazenar em cache páginas de dados/índice e planos de consulta, a consulta pode ser otimizada de forma diferente com base na disponibilidade de recursos de hardware.
As configurações de hardware relacionadas à CPU são semelhantes em ambos os servidores? Por exemplo:
O número de CPUs varia entre as máquinas (24 CPUs em uma máquina versus 96 CPUs na outra).
Planos de energia - equilibrados versus alto desempenho.
Máquina Virtual (VM) versus máquina física (bare metal).
Hyper-V versus VMware — diferença na configuração.
Diferença de velocidade de clock (velocidade de clock mais baixa versus velocidade de clock mais alta). Por exemplo, 2 GHz versus 3,5 GHz podem fazer a diferença. Para obter a velocidade do clock em um servidor, execute o seguinte comando do PowerShell:
Get-CimInstance Win32_Processor | Select-Object -Expand MaxClockSpeed
Use uma das duas maneiras a seguir para testar a velocidade da CPU dos servidores. Se eles não produzirem resultados comparáveis, o problema está fora do SQL Server. Pode ser uma diferença no plano de energia, menos CPUs, problema de software de VM ou diferença de velocidade de clock.
Execute o script do PowerShell a seguir em ambos os servidores e compare as saídas.
$bf = [System.DateTime]::Now for ($i = 0; $i -le 20000000; $i++) {} $af = [System.DateTime]::Now Write-Host ($af - $bf).Milliseconds " milliseconds" Write-Host ($af - $bf).Seconds " Seconds"Execute o código Transact-SQL a seguir em ambos os servidores e compare as saídas.
SET NOCOUNT ON DECLARE @spins INT = 0 DECLARE @start_time DATETIME = GETDATE(), @time_millisecond INT WHILE (@spins < 20000000) BEGIN SET @spins = @spins +1 END SELECT @time_millisecond = DATEDIFF(millisecond, @start_time, getdate()) SELECT @spins Spins, @time_millisecond Time_ms, @spins / @time_millisecond Spins_Per_ms
Diagnosticar esperas ou gargalos
Para otimizar uma consulta que está aguardando gargalos, identifique quanto tempo é a espera e onde está o gargalo (o tipo de espera). Assim que o tipo de espera for confirmado, reduza o tempo de espera ou elimine completamente a espera.
Para calcular o tempo de espera aproximado, subtraia o tempo de CPU (tempo de trabalho) do tempo decorrido de uma consulta. Normalmente, o tempo de CPU é o tempo de execução real e a parte restante do tempo de vida da consulta está aguardando.
Exemplos de como calcular a duração aproximada da espera:
| Tempo decorrido (ms) | Tempo de CPU (ms) | Tempo de espera (ms) |
|---|---|---|
| 3200 | 3000 | 200 |
| 7080 | 1000 | 6080 |
Identifique o gargalo ou aguarde
Para identificar consultas históricas de longa espera (por exemplo, >20% do tempo total decorrido é tempo de espera), execute a consulta a seguir. Essa consulta usa estatísticas de desempenho para planos de consulta armazenados em cache desde o início do SQL Server.
SELECT t.text, qs.total_elapsed_time / qs.execution_count AS avg_elapsed_time, qs.total_worker_time / qs.execution_count AS avg_cpu_time, (qs.total_elapsed_time - qs.total_worker_time) / qs.execution_count AS avg_wait_time, qs.total_logical_reads / qs.execution_count AS avg_logical_reads, qs.total_logical_writes / qs.execution_count AS avg_writes, qs.total_elapsed_time AS cumulative_elapsed_time FROM sys.dm_exec_query_stats qs CROSS apply sys.Dm_exec_sql_text (sql_handle) t WHERE (qs.total_elapsed_time - qs.total_worker_time) / qs.total_elapsed_time > 0.2 ORDER BY qs.total_elapsed_time / qs.execution_count DESCPara identificar consultas em execução no momento com esperas superiores a 500 ms, execute a seguinte consulta:
SELECT r.session_id, r.wait_type, r.wait_time AS wait_time_ms FROM sys.dm_exec_requests r JOIN sys.dm_exec_sessions s ON r.session_id = s.session_id WHERE wait_time > 500 AND is_user_process = 1Se você puder coletar um plano de consulta, verifique os WaitStats nas propriedades do plano de execução no SSMS:
- Execute a consulta com Incluir Plano de Execução Real ativado.
- Clique com o botão direito do mouse no operador mais à esquerda na guia Plano de execução
- Selecione Propriedades e, em seguida, a propriedade WaitStats .
- Verifique os WaitTimeMs e WaitType.
Se você estiver familiarizado com os cenários PSSDiag/SQLdiag ou SQL LogScout LightPerf/GeneralPerf, considere usar qualquer um deles para coletar estatísticas de desempenho e identificar consultas em espera em sua instância do SQL Server. Você pode importar os arquivos de dados coletados e analisar os dados de desempenho com o SQL Nexus.
Referências para ajudar a eliminar ou reduzir esperas
As causas e resoluções para cada tipo de espera variam. Não há um método geral para resolver todos os tipos de espera. Aqui estão os artigos para solucionar problemas comuns de tipo de espera:
- Entender e resolver problemas de bloqueio (LCK_M_*)
- Entender e resolver problemas de bloqueio do Banco de Dados SQL do Azure
- Solucionar problemas de desempenho lento do SQL Server causados por problemas de E/S (PAGEIOLATCH_*, WRITELOG, IO_COMPLETION, BACKUPIO)
- Resolva a contenção de PAGELATCH_EX de inserção da última página no SQL Server
- A memória concede explicações e soluções (RESOURCE_SEMAPHORE)
- Solucionar problemas de consultas lentas resultantes de ASYNC_NETWORK_IO tipo de espera
- Solução de problemas do tipo de espera de alta HADR_SYNC_COMMIT com Grupos de Disponibilidade Always On
- Como funciona: CMEMTHREAD e depurando-os
- Tornando as esperas de paralelismo acionáveis (CXPACKET e CXCONSUMER)
- Espera do THREADPOOL
Para obter descrições de muitos tipos de espera e o que eles indicam, consulte a tabela em Tipos de esperas.
Diagnosticar diferenças de plano de consulta
Aqui estão algumas causas comuns para diferenças nos planos de consulta:
Tamanho dos dados ou diferenças de valores de dados
O mesmo banco de dados está sendo usado em ambos os servidores, usando o mesmo backup de banco de dados? Os dados foram modificados em um servidor em comparação com o outro? As diferenças de dados podem levar a diferentes planos de consulta. Por exemplo, unir a tabela T1 (1000 linhas) com a tabela T2 (2.000.000 linhas) é diferente de unir a tabela T1 (100 linhas) com a tabela T2 (2.000.000 linhas). O tipo e a
JOINvelocidade da operação podem ser significativamente diferentes.Diferenças estatísticas
As estatísticas foram atualizadas em um banco de dados e não no outro? As estatísticas foram atualizadas com uma taxa de amostragem diferente (por exemplo, 30% versus 100% de verificação completa)? Certifique-se de atualizar as estatísticas em ambos os lados com a mesma taxa de amostragem.
Diferenças de nível de compatibilidade do banco de dados
Verifique se os níveis de compatibilidade dos bancos de dados são diferentes entre os dois servidores. Para obter o nível de compatibilidade do banco de dados, execute a seguinte consulta:
SELECT name, compatibility_level FROM sys.databases WHERE name = '<YourDatabase>'Diferenças de versão/compilação do servidor
As versões ou builds do SQL Server são diferentes entre os dois servidores? Por exemplo, um servidor é SQL Server versão 2014 e o outro SQL Server versão 2016? Pode haver alterações de produto que podem levar a alterações na forma como um plano de consulta é selecionado. Certifique-se de comparar a mesma versão e build do SQL Server.
SELECT ServerProperty('ProductVersion')Diferenças de versão do Avaliador de Cardinalidade (CE)
Verifique se o avaliador de cardinalidade herdado está ativado no nível do banco de dados. Para obter mais informações sobre CE, consulte Estimativa de cardinalidade (SQL Server).
SELECT name, value, is_value_default FROM sys.database_scoped_configurations WHERE name = 'LEGACY_CARDINALITY_ESTIMATION'Hotfixes do otimizador ativados/desativados
Se os hotfixes do otimizador de consulta estiverem habilitados em um servidor, mas desabilitados no outro, diferentes planos de consulta poderão ser gerados. Para obter mais informações, consulte Modelo de manutenção 4199 do sinalizador de rastreamento de hotfix do otimizador de consulta do SQL Server.
Para obter o estado dos hotfixes do otimizador de consulta, execute a seguinte consulta:
-- Check at server level for TF 4199 DBCC TRACESTATUS (-1) -- Check at database level USE <YourDatabase> SELECT name, value, is_value_default FROM sys.database_scoped_configurations WHERE name = 'QUERY_OPTIMIZER_HOTFIXES'Diferenças de sinalizadores de rastreamento
Alguns sinalizadores de rastreamento afetam a seleção do plano de consulta. Verifique se há sinalizadores de rastreamento habilitados em um servidor que não estão habilitados no outro. Execute a seguinte consulta em ambos os servidores e compare os resultados:
-- Check at server level for trace flags DBCC TRACESTATUS (-1)Diferenças de hardware (contagem de CPU, tamanho da memória)
Para obter as informações de hardware, execute a seguinte consulta:
SELECT cpu_count, physical_memory_kb/1024/1024 PhysicalMemory_GB FROM sys.dm_os_sys_infoDiferenças de hardware de acordo com o otimizador de consulta
Verifique o de um plano de consulta e veja se as
OptimizerHardwareDependentPropertiesdiferenças de hardware são consideradas significativas para planos diferentes.WITH xmlnamespaces(DEFAULT 'http://schemas.microsoft.com/sqlserver/2004/07/showplan') SELECT txt.text, t.OptHardw.value('@EstimatedAvailableMemoryGrant', 'INT') AS EstimatedAvailableMemoryGrant , t.OptHardw.value('@EstimatedPagesCached', 'INT') AS EstimatedPagesCached, t.OptHardw.value('@EstimatedAvailableDegreeOfParallelism', 'INT') AS EstimatedAvailDegreeOfParallelism, t.OptHardw.value('@MaxCompileMemory', 'INT') AS MaxCompileMemory FROM sys.dm_exec_cached_plans AS cp CROSS APPLY sys.dm_exec_query_plan(cp.plan_handle) AS qp CROSS APPLY qp.query_plan.nodes('//OptimizerHardwareDependentProperties') AS t(OptHardw) CROSS APPLY sys.dm_exec_sql_text (CP.plan_handle) txt WHERE text Like '%<Part of Your Query>%'Tempo limite do otimizador
Existe um problema de tempo limite do otimizador? O otimizador de consulta pode parar de avaliar as opções de plano se a consulta que está sendo executada for muito complexa. Quando para, escolhe o plano com o menor custo disponível no momento. Isso pode levar ao que parece ser uma escolha de plano arbitrária em um servidor em relação a outro.
Opções Set
Algumas opções SET afetam o plano, como SET ARITHABORT. Para obter mais informações, consulte Opções SET.
Diferenças de dica de consulta
Uma consulta usa dicas de consulta e a outra não? Verifique o texto da consulta manualmente para estabelecer a presença de dicas de consulta.
Planos sensíveis a parâmetros (problema de detecção de parâmetros)
Você está testando a consulta com exatamente os mesmos valores de parâmetro? Se não, então você pode começar por aí. O plano foi compilado anteriormente em um servidor com base em um valor de parâmetro diferente? Teste as duas consultas usando a dica de consulta RECOMPILE para garantir que não haja reutilização de plano ocorrendo. Para obter mais informações, consulte Investigar e resolver problemas sensíveis a parâmetros.
Diferentes opções de banco de dados/definições de configuração com escopo
As mesmas opções de banco de dados ou definições de configuração com escopo são usadas em ambos os servidores? Algumas opções de banco de dados podem influenciar as escolhas do plano. Por exemplo, compatibilidade de banco de dados, CE herdado versus CE padrão e detecção de parâmetros. Execute a seguinte consulta de um servidor para comparar as opções de banco de dados usadas nos dois servidores:
-- On Server1 add a linked server to Server2 EXEC master.dbo.sp_addlinkedserver @server = N'Server2', @srvproduct=N'SQL Server' -- Run a join between the two servers to compare settings side by side SELECT s1.name AS srv1_config_name, s2.name AS srv2_config_name, s1.value_in_use AS srv1_value_in_use, s2.value_in_use AS srv2_value_in_use, Variance = CASE WHEN ISNULL(s1.value_in_use, '##') != ISNULL(s2.value_in_use,'##') THEN 'Different' ELSE '' END FROM sys.configurations s1 FULL OUTER JOIN [server2].master.sys.configurations s2 ON s1.name = s2.name SELECT s1.name AS srv1_config_name, s2.name AS srv2_config_name, s1.value srv1_value_in_use, s2.value srv2_value_in_use, s1.is_value_default, s2.is_value_default, Variance = CASE WHEN ISNULL(s1.value, '##') != ISNULL(s2.value, '##') THEN 'Different' ELSE '' END FROM sys.database_scoped_configurations s1 FULL OUTER JOIN [server2].master.sys.database_scoped_configurations s2 ON s1.name = s2.nameGuias de plano
Algum guia de plano é usado para suas consultas em um servidor, mas não no outro? Execute a seguinte consulta para estabelecer diferenças:
SELECT * FROM sys.plan_guides