Nota
O acesso a esta página requer autorização. Pode tentar iniciar sessão ou alterar os diretórios.
O acesso a esta página requer autorização. Pode tentar alterar os diretórios.
A Adaptação de Classificação Baixa (LoRA) pode ser utilizada para ajustar o modelo Phi Silica para melhorar seu desempenho para o seu caso de uso específico. Usando LoRA para otimizar Phi Silica, modelo de idioma local do Microsoft Windows, você pode obter resultados mais precisos. Esse processo envolve treinar um adaptador LoRA e, em seguida, aplicá-lo durante a inferência para melhorar a precisão do modelo.
Pré-requisitos
- Você identificou um caso de uso para melhorar a resposta da Phi Silica.
- Escolheu um critério de avaliação para decidir o que é uma "boa resposta".
- Você tentou as APIs Phi Silica e elas não atendem aos seus critérios de avaliação.
Treine seu adaptador
Para treinar um adaptador LoRA para ajustar o modelo de sílica Phi com o Windows 11, você deve primeiro gerar um conjunto de dados que o processo de treinamento usará.
Gerar um conjunto de dados para uso com um adaptador LoRA
Para gerar um conjunto de dados, você precisará dividir os dados em dois arquivos:
train.json– Usado para treinar o adaptador.test.json– Utilizado para avaliar o desempenho do adaptador durante e após o treino.
Ambos os arquivos devem usar o formato JSON, onde cada linha é um objeto JSON separado que representa um único exemplo. Cada exemplo deve conter uma lista de mensagens trocadas entre um usuário e um assistente.
Cada objeto de mensagem requer dois campos:
content: o texto da mensagem.role: ou"user""assistant", indicando o remetente.
Veja os seguintes exemplos:
{"messages": [{"content": "Hello, how do I reset my password?", "role": "user"}, {"content": "To reset your password, go to the settings page and click 'Reset Password'.", "role": "assistant"}]}
{"messages": [{"content": "Can you help me find nearby restaurants?", "role": "user"}, {"content": "Sure! Here are some restaurants near your location: ...", "role": "assistant"}]}
{"messages": [{"content": "What is the weather like today?", "role": "user"}, {"content": "Today's forecast is sunny with a high of 25°C.", "role": "assistant"}]}
Dicas de formação:
Não é necessária vírgula no final de cada linha de amostragem.
Inclua o maior número possível de exemplos diversificados e de alta qualidade. Para obter melhores resultados, colete pelo menos alguns milhares de amostras de treinamento em seu
train.jsonarquivo.O
test.jsonarquivo pode ser menor, mas deve abranger os tipos de interações que você espera que seu modelo manipule.Crie
train.jsonetest.jsonarquivos com um objeto JSON por linha, cada um contendo uma breve conversa de ida e volta entre um usuário e um assistente. A qualidade e a quantidade dos seus dados afetarão grandemente a eficácia do seu adaptador LoRA.
Treinamento de um adaptador LoRA no AI Toolkit
Para treinar um adaptador LoRA usando o AI Toolkit for Visual Studio Code, primeiro você precisará dos seguintes pré-requisitos necessários:
Subscrição do Azure com quota disponível no serviço Azure Container Apps.
- Recomendamos o uso de GPUs A100 ou superiores para executar com eficiência um trabalho de ajuste fino.
- Verifique se você tem uma cota disponível no Portal do Azure. Se pretender ajuda para encontrar a sua quota, consulte Ver quotas.
Você precisará instalar o Visual Studio Code se ainda não o tiver.
Para instalar o AI Toolkit for Visual Studio Code:
Depois que a extensão do AI Toolkit for baixada, você poderá acessá-la a partir do painel esquerdo da barra de ferramentas dentro do Visual Studio Code.
Navegue até Ferramentas>Ajuste Fino.
Insira um nome e um local do projeto.
Selecione "microsoft/phi-silica" do Catálogo de Modelos.
Selecione "Configurar projeto".
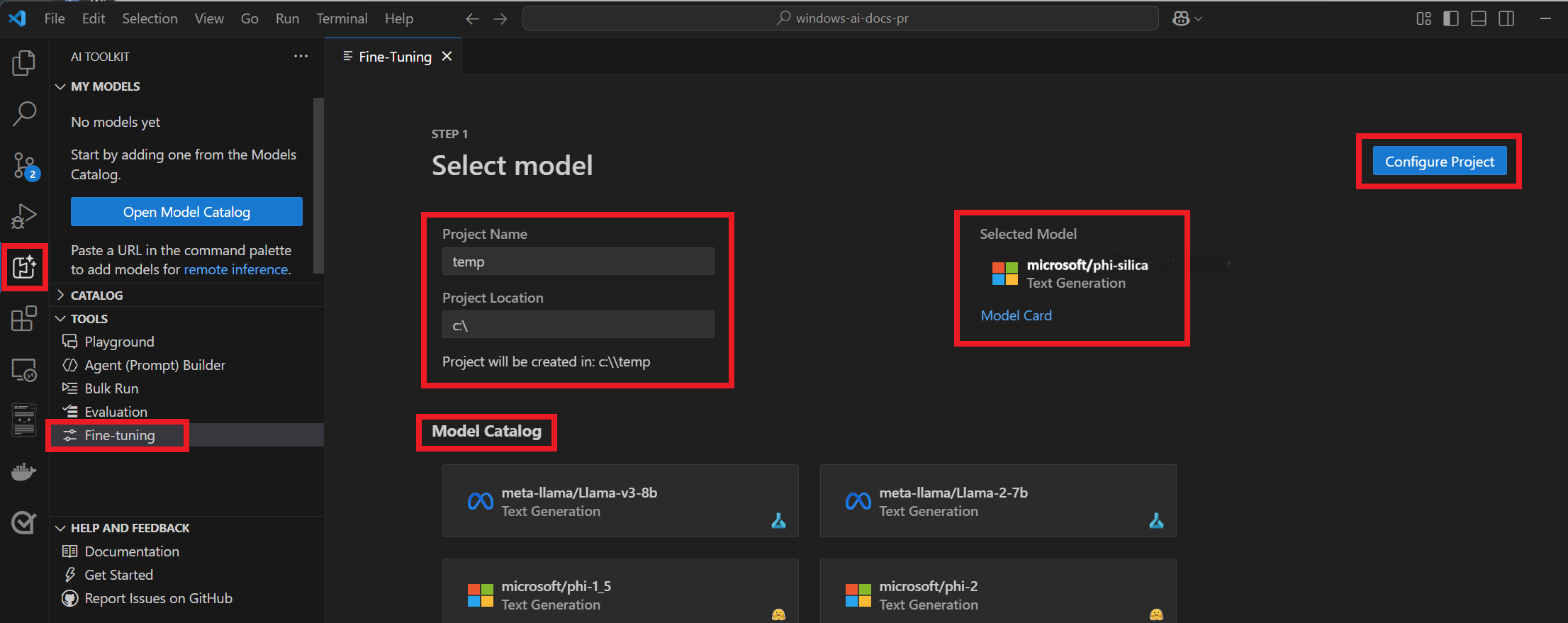
Selecione a versão mais recente do Phi Silica.
Sob Dados, > e Nome do conjunto de dados de teste, selecione os seus e
train.jsonarquivos.Selecione "Gerar projeto" - uma nova janela do VS Code será aberta.
Verifique se o perfil de carga de trabalho correto está selecionado no seu ficheiro Bicep para que a tarefa no Azure seja implantada e executada corretamente. Aditar o seguinte em
workloadProfiles:{ workloadProfileType: 'Consumption-GPU-NC24-A100' name: 'GPU' }Selecione "Novo processo de ajuste fino" e insira um nome para o processo.
Será exibida uma caixa de diálogo solicitando que você selecione a conta da Microsoft com a qual acessar sua assinatura do Azure.
Depois de a sua conta ser selecionada, irá precisar de selecionar um Grupo de Recursos a partir do menu pendente de subscrição.
Agora você verá que seu trabalho de ajuste fino foi iniciado com êxito, juntamente com um Status do trabalho. Uma vez que o trabalho tenha sido concluído, você terá a opção de baixar o adaptador LoRA recém-treinado selecionando o botão "Download". Normalmente, leva em média de 45 a 60 minutos para que um trabalho de ajuste fino seja concluído.
Inferência
O treinamento é a fase inicial em que o modelo de IA aprende com um grande conjunto de dados, reconhecendo padrões e correlações. A inferência, por outro lado, é a fase de aplicação em que um modelo treinado (Phi Silica no nosso caso) usa novos dados (nosso adaptador LoRA) para fazer previsões ou decisões com as quais gerar resultados mais personalizados.
Para aplicar o adaptador LoRA treinado:
Use o aplicativo AI Dev Gallery. AI Dev Gallery é um aplicativo que permite experimentar modelos de IA locais e API, além de visualizar e exportar código de exemplo. Saiba mais sobre a AI Dev Gallery.
Depois de instalar o AI Dev Gallery, abra o aplicativo e selecione a guia "AI APIs" e, em seguida, selecione "Phi Silica LoRA".
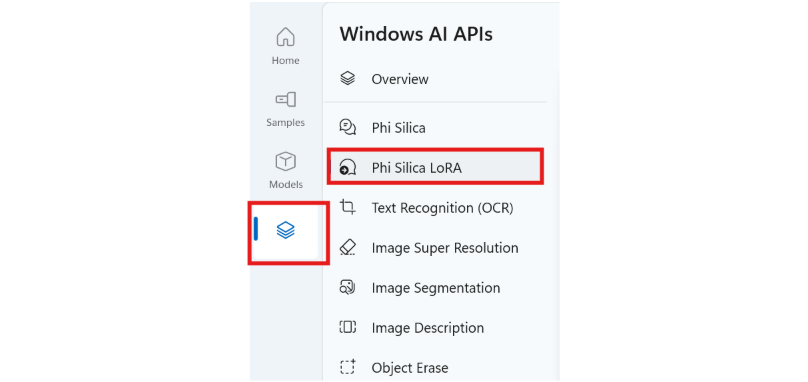
Selecione o arquivo do adaptador. O local padrão para que eles sejam armazenados é:
Desktop/lora_lab/trainedLora.Preencha os campos "Prompt do sistema" e "Prompt". Em seguida, selecione "Gerar" para ver a diferença entre Phi Silica com e sem o adaptador LoRA.
Experimente o Comando e o Comando do Sistema para ver como isso faz diferença no seu resultado.
Selecione "Exportar exemplo" para baixar uma solução autônoma do Visual Studio que contém apenas esse código de exemplo.
Gerar respostas
Depois de testar seu novo adaptador LoRA usando a AI Dev Gallery, você pode adicionar o adaptador ao seu aplicativo do Windows usando o exemplo de código abaixo.
using Microsoft.Windows.AI.Text;
using Microsoft.Windows.AI.Text.Experimental;
// Path to the LoRA adapter file
string adapterFilePath = "C:/path/to/adapter/file.safetensors";
// Prompt to be sent to the LanguageModel
string prompt = "How do I add a new project to my Visual Studio solution?";
// Wait for LanguageModel to be ready
if (LanguageModel.GetReadyState() == AIFeatureReadyState.NotReady)
{
var languageModelDeploymentOperation = LanguageModel.EnsureReadyAsync();
await languageModelDeploymentOperation;
}
// Create the LanguageModel session
var session = LanguageModel.CreateAsync();
// Create the LanguageModelExperimental
var languageModelExperimental = new LanguageModelExperimental(session);
// Load the LoRA adapter
LowRankAdaptation loraAdapter = languageModelExperimental.LoadAdapter(adapterFilePath);
// Set the adapter in LanguageModelOptionsExperimental
LanguageModelOptionsExperimental options = new LanguageModelOptionsExperimental
{
LoraAdapter = loraAdapter
};
// Generate a response with the LoRA adapter provided in the options
var response = await languageModelExperimental.GenerateResponseAsync(prompt, options);
IA responsável - Riscos e limitações do ajuste fino
Quando os clientes ajustam o Phi Silica, ele pode melhorar o desempenho e a precisão do modelo em tarefas e domínios específicos, mas também pode introduzir novos riscos e limitações que os clientes devem estar cientes. Alguns desses riscos e limitações são:
Qualidade e representação dos dados: A qualidade e a representatividade dos dados usados para ajuste fino podem afetar o comportamento e as saídas do modelo. Se os dados forem barulhentos, incompletos, desatualizados ou se contiverem conteúdo nocivo, como estereótipos, o modelo pode herdar esses problemas e produzir resultados imprecisos ou prejudiciais. Por exemplo, se os dados contiverem estereótipos de género, o modelo pode amplificá-los e gerar linguagem sexista. Os clientes devem selecionar cuidadosamente e pré-processar seus dados para garantir que eles sejam relevantes, diversificados e equilibrados para a tarefa e o domínio pretendidos.
Robustez e generalização do modelo: A capacidade do modelo de lidar com entradas e cenários diversos e complexos pode diminuir após o ajuste fino, especialmente se os dados forem muito estreitos ou específicos. O modelo pode sobreajustar aos dados e perder alguns de seus conhecimentos e capacidades gerais. Por exemplo, se os dados forem apenas sobre esportes, o modelo pode ter dificuldades para responder perguntas ou gerar texto sobre outros tópicos. Os clientes devem avaliar o desempenho e a robustez do modelo em uma variedade de entradas e cenários e evitar o uso do modelo para tarefas ou domínios que estão fora de seu escopo.
Regurgitação: Embora seus dados de treinamento não estejam disponíveis para a Microsoft ou quaisquer clientes de terceiros, modelos mal ajustados podem regurgitar ou repetir diretamente os dados de treinamento. Os clientes são responsáveis por remover quaisquer PII ou informações protegidas de outra forma de seus dados de treinamento e devem avaliar seus modelos ajustados para sobreajuste ou respostas de baixa qualidade. Para evitar regurgitação, os clientes são incentivados a fornecer conjuntos de dados grandes e diversificados.
Transparência e explicabilidade do modelo: A lógica e o raciocínio do modelo podem se tornar mais opacos e difíceis de entender após o ajuste fino, especialmente se os dados forem complexos ou abstratos. Um modelo ajustado pode produzir saídas inesperadas, inconsistentes ou contraditórias, e os clientes podem não ser capazes de explicar como ou por que o modelo chegou a essas saídas. Por exemplo, se os dados forem sobre termos legais ou médicos, o modelo pode gerar saídas imprecisas ou enganosas, e os clientes podem não ser capazes de verificá-las ou justificá-las. Os clientes devem monitorar e auditar as saídas e o comportamento do modelo e fornecer informações e orientações claras e precisas aos usuários finais do modelo.