Tutorial da API WebNN
Para obter uma introdução ao WebNN, incluindo informações sobre suporte ao sistema operacional, suporte a modelos e muito mais, visite a Visão geral do WebNN.
Este tutorial vai mostrar como usar a API WebNN para criar um sistema de classificação de imagem na Web com aceleração de hardware usando GPU no dispositivo. Vamos aproveitar o modelo MobileNetv2, que é um modelo de código aberto no Hugging Face usado para classificar imagens.
Se você quiser visualizar e executar o código final deste tutorial, poderá encontrá-lo em nosso GitHub de Preview do desenvolvedor do WebNN.
Observação
A API da WebNN é uma recomendação de candidato do W3C e está nos estágios iniciais de uma preview do desenvolvedor. Algumas funcionalidades são limitadas. Temos uma lista de suporte atual e status de implementação.
Requisitos e configuração:
Configuração do Windows
Verifique se você tem as versões corretas do Edge, do Windows e de drivers de hardware conforme detalhado na seção Requisitos do WebNN.
Configuração do Edge
Baixe e instale o Microsoft Edge Dev.
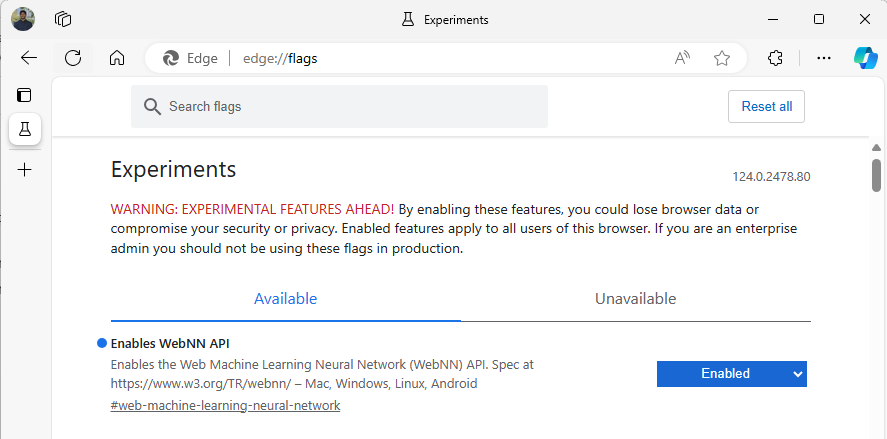
Inicie o Edge Beta e navegue para
about:flagsna barra de endereços.Pesquise "API WebNN", clique na lista suspensa e defina como “Habilitado”.
Reinicie o Edge conforme solicitado.
Configuração do ambiente de desenvolvedor
Faça download e instale o VSCode (Visual Studio Code).
Inicie o VSCode.
Faça o download e instale a extensão do Live Server para VSCode no VSCode.
Selecione
File --> Open Foldere crie uma pasta em branco na localização desejada.
Etapa 1: Inicializar o aplicativo Web
- Para começar, crie uma página
index.html. Adicione o seguinte código padrão à nova página:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>My Website</title>
</head>
<body>
<main>
<h1>Welcome to My Website</h1>
</main>
</body>
</html>
- Verifique se o código padrão e a configuração do desenvolvedor funcionaram selecionando o botão Go Live no canto inferior direito do VSCode. Isso deve iniciar um servidor local no Edge Beta executando o código padrão.
- Agora, crie um arquivo chamado
main.js. Ele conterá todo o código JavaScript para o seu aplicativo. - Em seguida, crie uma subpasta fora do diretório raiz chamada
images. Faça download e salve qualquer imagem dentro da pasta. Para esta demonstração, vamos usar o nome padrão deimage.jpg. - Faça download do modelo mobilenet do ONNX Model Zoo. Neste tutorial, vamos usar o arquivo mobilenet2-10.onnx. Salve esse modelo na pasta raiz do aplicativo Web.
- Por fim, baixe e salve este arquivo de classes de imagem,
imagenetClasses.js. Isso fornece mil classificações comuns de imagens para seu modelo usar.
Etapa 2: Adicionar elementos da interface do usuário e função pai
- No corpo das marcas html
<main>adicionadas na etapa anterior, substitua o código pelos elementos a seguir. Eles vão criar um botão e exibir uma imagem padrão.
<h1>Image Classification Demo!</h1>
<div><img src="./images/image.jpg"></div>
<button onclick="classifyImage('./images/image.jpg')" type="button">Click Me to Classify Image!</button>
<h1 id="outputText"> This image displayed is ... </h1>
- Agora, adicione o ONNX Runtime Web à página, que é uma biblioteca JavaScript que você vai usar para acessar a API WebNN. Dentro do corpo das marcas html
<head>, adicione os links de origem JavaScript a seguir.
<script src="./main.js"></script>
<script src="imagenetClasses.js"></script>
<script src="https://cdn.jsdelivr.net/npm/onnxruntime-web@1.18.0-dev.20240311-5479124834/dist/ort.webgpu.min.js"></script>
- Abra o arquivo
main.jse adicione o snippet de código a seguir.
async function classifyImage(pathToImage){
var imageTensor = await getImageTensorFromPath(pathToImage); // Convert image to a tensor
var predictions = await runModel(imageTensor); // Run inference on the tensor
console.log(predictions); // Print predictions to console
document.getElementById("outputText").innerHTML += predictions[0].name; // Display prediction in HTML
}
Etapa 3: Pré-processar os dados
- A função que você acabou de adicionar chama
getImageTensorFromPath, outra função que você precisa implementar. Você vai adicioná-la abaixo, bem como outra função assíncrona que ela chama para recuperar a imagem em si.
async function getImageTensorFromPath(path, width = 224, height = 224) {
var image = await loadImagefromPath(path, width, height); // 1. load the image
var imageTensor = imageDataToTensor(image); // 2. convert to tensor
return imageTensor; // 3. return the tensor
}
async function loadImagefromPath(path, resizedWidth, resizedHeight) {
var imageData = await Jimp.read(path).then(imageBuffer => { // Use Jimp to load the image and resize it.
return imageBuffer.resize(resizedWidth, resizedHeight);
});
return imageData.bitmap;
}
- Você também precisa adicionar a função
imageDataToTensorreferenciada acima, que vai renderizar a imagem carregada em um formato de tensor que funciona com nosso modelo do ONNX. Essa é uma função mais envolvida, embora possa parecer familiar se você já trabalhou com aplicativos de classificação de imagem semelhantes antes. Para obter uma explicação estendida, você pode assistir a este tutorial do ONNX.
function imageDataToTensor(image) {
var imageBufferData = image.data;
let pixelCount = image.width * image.height;
const float32Data = new Float32Array(3 * pixelCount); // Allocate enough space for red/green/blue channels.
// Loop through the image buffer, extracting the (R, G, B) channels, rearranging from
// packed channels to planar channels, and converting to floating point.
for (let i = 0; i < pixelCount; i++) {
float32Data[pixelCount * 0 + i] = imageBufferData[i * 4 + 0] / 255.0; // Red
float32Data[pixelCount * 1 + i] = imageBufferData[i * 4 + 1] / 255.0; // Green
float32Data[pixelCount * 2 + i] = imageBufferData[i * 4 + 2] / 255.0; // Blue
// Skip the unused alpha channel: imageBufferData[i * 4 + 3].
}
let dimensions = [1, 3, image.height, image.width];
const inputTensor = new ort.Tensor("float32", float32Data, dimensions);
return inputTensor;
}
Etapa 4: Chamar WebNN
- Agora você adicionou todas as funções necessárias para recuperar sua imagem e renderizá-la como um tensor. Agora, usando a biblioteca da Web do ONNX Runtime que você carregou acima, você vai executar seu modelo. Observe que, para usar o WebNN aqui, basta especificar
executionProvider = "webnn". O suporte do ONNX Runtime torna muito simples habilitar o WebNN.
async function runModel(preprocessedData) {
// Set up environment.
ort.env.wasm.numThreads = 1;
ort.env.wasm.simd = true;
ort.env.wasm.proxy = true;
ort.env.logLevel = "verbose";
ort.env.debug = true;
// Configure WebNN.
const executionProvider = "webnn"; // Other options: webgpu
const modelPath = "./mobilenetv2-7.onnx"
const options = {
executionProviders: [{ name: executionProvider, deviceType: "gpu", powerPreference: "default" }],
freeDimensionOverrides: {"batch": 1, "channels": 3, "height": 224, "width": 224}
};
modelSession = await ort.InferenceSession.create(modelPath, options);
// Create feeds with the input name from model export and the preprocessed data.
const feeds = {};
feeds[modelSession.inputNames[0]] = preprocessedData;
// Run the session inference.
const outputData = await modelSession.run(feeds);
// Get output results with the output name from the model export.
const output = outputData[modelSession.outputNames[0]];
// Get the softmax of the output data. The softmax transforms values to be between 0 and 1.
var outputSoftmax = softmax(Array.prototype.slice.call(output.data));
// Get the top 5 results.
var results = imagenetClassesTopK(outputSoftmax, 5);
return results;
}
Etapa 5: Pós-processar dados
- Por fim, você vai adicionar uma função
softmaxe, em seguida, adicionar sua função final para retornar a classificação de imagem mais provável. Osoftmaxtransforma seus valores para que fiquem entre 0 e 1, que é o formato de probabilidade necessário para essa classificação final.
Primeiro, adicione os seguintes arquivos de origem para as bibliotecas auxiliares Jimp e Lodash na tag head do main.js.
<script src="https://cdnjs.cloudflare.com/ajax/libs/jimp/0.22.12/jimp.min.js" integrity="sha512-8xrUum7qKj8xbiUrOzDEJL5uLjpSIMxVevAM5pvBroaxJnxJGFsKaohQPmlzQP8rEoAxrAujWttTnx3AMgGIww==" crossorigin="anonymous" referrerpolicy="no-referrer"></script>
<script src="https://cdn.jsdelivr.net/npm/lodash@4.17.21/lodash.min.js"></script>
Agora, adicione estas funções a seguir ao main.js.
// The softmax transforms values to be between 0 and 1.
function softmax(resultArray) {
// Get the largest value in the array.
const largestNumber = Math.max(...resultArray);
// Apply the exponential function to each result item subtracted by the largest number, using reduction to get the
// previous result number and the current number to sum all the exponentials results.
const sumOfExp = resultArray
.map(resultItem => Math.exp(resultItem - largestNumber))
.reduce((prevNumber, currentNumber) => prevNumber + currentNumber);
// Normalize the resultArray by dividing by the sum of all exponentials.
// This normalization ensures that the sum of the components of the output vector is 1.
return resultArray.map((resultValue, index) => {
return Math.exp(resultValue - largestNumber) / sumOfExp
});
}
function imagenetClassesTopK(classProbabilities, k = 5) {
const probs = _.isTypedArray(classProbabilities)
? Array.prototype.slice.call(classProbabilities)
: classProbabilities;
const sorted = _.reverse(
_.sortBy(
probs.map((prob, index) => [prob, index]),
probIndex => probIndex[0]
)
);
const topK = _.take(sorted, k).map(probIndex => {
const iClass = imagenetClasses[probIndex[1]]
return {
id: iClass[0],
index: parseInt(probIndex[1].toString(), 10),
name: iClass[1].replace(/_/g, " "),
probability: probIndex[0]
}
});
return topK;
}
- Agora você adicionou todos os scripts necessários para executar a classificação de imagem com WebNN no aplicativo Web básico. Usando a extensão Live Server para VS Code, agora você pode iniciar sua página da Web básica no aplicativo e ver os resultados da classificação em primeira mão.
Comentários
Brevemente: Ao longo de 2024, vamos descontinuar progressivamente o GitHub Issues como mecanismo de feedback para conteúdos e substituí-lo por um novo sistema de feedback. Para obter mais informações, veja: https://aka.ms/ContentUserFeedback.
Submeter e ver comentários