Nota
O acesso a esta página requer autorização. Pode tentar iniciar sessão ou alterar os diretórios.
O acesso a esta página requer autorização. Pode tentar alterar os diretórios.
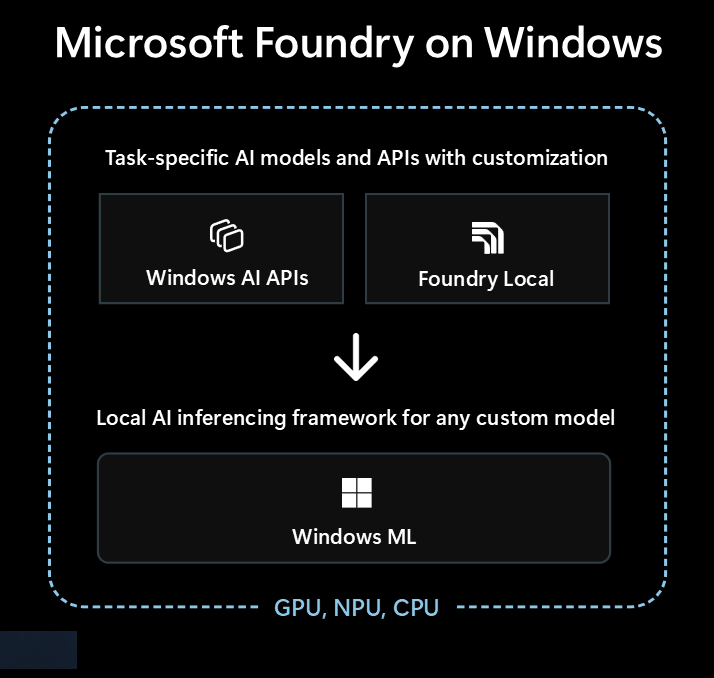
Microsoft Foundry on Windows é a solução principal para programadores que procuram integrar capacidades de IA local nas suas aplicações Windows.
Microsoft Foundry on Windows fornece aos programadores...
- Modelos e APIs de IA prontos a usar via Windows AI APIs e Foundry Local
- Framework de inferência de IA para executar qualquer modelo localmente através de Windows ML
Independentemente de seres novo em IA ou um especialista experiente em Machine Learning (ML), Microsoft Foundry on Windows tem algo para ti.
Modelos e APIs de IA prontos a usar
A sua aplicação pode utilizar facilmente os seguintes modelos e APIs locais de IA em menos de uma hora. A distribuição e o tempo de execução dos ficheiros de modelo são geridos pela Microsoft, e os modelos são partilhados entre as aplicações. Usar estes modelos e APIs requer apenas algumas linhas de código, sem qualquer conhecimento em ML.
| Tipo de modelo ou API | O que é isso? | Opções e dispositivos suportados |
|---|---|---|
| Modelos de linguagem grande (LLMs) | Modelos de texto generativo | Phi Silica via AI APIs (suporta afinação) ou mais de 20 modelos LLM OSS via Foundry Local Consulte os LLMs locais para saber mais. |
| Descrição da Imagem | Obtenha uma descrição em texto em linguagem natural de uma imagem | Descrição da imagem via AI APIs (Copilot+ PCs) |
| Extrator de Primeiro Plano de Imagem | Segmentar o primeiro plano de uma imagem | Extrator de Imagem em Primeiro Plano via AI APIs (Copilot+ PCs) |
| Geração de Imagem | Gerar imagens a partir de texto | Geração de Imagem via AI APIs (Copilot+ PCs) |
| Apagar Objetos de Imagem | Apagar objetos das imagens | Apagar Objetos em Imagens via AI APIs (Copilot+ PCs) |
| Extrator de Objetos de Imagem | Objetos específicos de segmento numa imagem | Extrator de Objetos de Imagem via AI APIs (Copilot+ PCs) |
| Super Resolução de Imagem | Aumentar a resolução das imagens | Super Resolução de Imagens via AI APIs (Copilot+ PCs) |
| Pesquisa semântica | Pesquisa semanticamente texto e imagens | Pesquisa de Conteúdo de Aplicação via AI APIs (Copiloto+ PCs) |
| Reconhecimento de Fala | Converter fala em texto | Sussurrar via Foundry Local ou Reconhecimento de Fala via Windows SDK Consulte Reconhecimento de Fala para saber mais. |
| Reconhecimento de Texto (OCR) | Reconhecer texto a partir de imagens | OCR via AI APIs (Copilot+ PCs) |
| Super Resolução de Vídeo (VSR) | Aumentar a resolução dos vídeos | Super Resolução de Vídeo via AI APIs (Copilot+ PCs) |
Usar outros modelos com Windows ML
Podes usar uma grande variedade de modelos do Hugging Face ou de outras fontes, ou até treinar os teus próprios modelos, e executá-los localmente em PCs Windows 10 e posteriores usando Windows ML(a compatibilidade e desempenho dos modelos variam consoante o hardware do dispositivo).
Consulte encontrar ou treinar modelos para uso com Windows ML para saber mais.
Com que opção começar
Siga esta árvore de decisão para selecionar a melhor abordagem para a sua aplicação e cenário:
Verifique se o Windows AI APIs integrado cobre o seu cenário e se está destinado a PCs com Copilot+. Este é o caminho mais rápido para o mercado com esforço mínimo de desenvolvimento.
Se o Windows AI APIs não tiver o que precisa, ou precisar de suportar Windows 10 e posteriores, considere Foundry Local para cenários de LLM ou conversão de voz em texto.
Se precisares de modelos personalizados, quiseres aproveitar modelos existentes do Hugging Face ou de outras fontes, ou tiveres requisitos específicos de modelos que não estão cobertos pelas opções acima, o Windows ML dá-te a flexibilidade para encontrar ou treinar os teus próprios modelos (e suporta Windows 10 e posteriores).
A sua aplicação também pode usar uma combinação destas três tecnologias.
Tecnologias disponíveis para IA local
As seguintes tecnologias estão disponíveis em Microsoft Foundry on Windows:
| Windows AI APIs | Foundry Local | Windows ML | |
|---|---|---|---|
| O que é | Modelos e APIs de IA prontos a usar em vários tipos de tarefas, otimizados para PCs Copilot+ | LLMs prontos a usar e modelos de voz para texto | ONNX Runtime Framework para executar modelos que encontra ou treina |
| Dispositivos suportados | Copilot+ Computadores | Windows 10 e posteriores PCs e multiplataforma (O desempenho varia consoante o hardware disponível, não todos os modelos disponíveis) |
Windows 10 e PCs posteriores, e multiplataforma através de código aberto ONNX Runtime (O desempenho varia consoante o hardware disponível) |
| Tipos de modelos e APIs disponíveis |
LLM Descrição da Imagem Extrator de Primeiro Plano de Imagem Geração de Imagem Apagar Objetos de Imagem Extrator de Objetos de Imagem Super Resolução de Imagem Pesquisa semântica Reconhecimento de Texto (OCR) Super Resolução de Vídeo |
LLMs (múltiplas) voz para texto Navegue por 20+ modelos disponíveis |
Encontre ou treine os seus próprios modelos |
| Distribuição dos modelos | Alojado pela Microsoft, adquirido em tempo de execução e partilhado entre aplicações | Alojado pela Microsoft, adquirido em tempo de execução e partilhado entre aplicações | Distribuição tratada pela sua aplicação (as bibliotecas de aplicações podem partilhar modelos entre aplicações) |
| Mais informações | Leia a AI APIs documentação | Leia a Foundry Local documentação | Leia a Windows ML documentação |
Microsoft Foundry on Windows inclui também ferramentas para programadores como Foundry Toolkit para Visual Studio Code e AI Dev Gallery que o ajudarão a ter sucesso a desenvolver capacidades de IA.
Foundry Toolkit for Visual Studio Code é uma Extensão VS Code que permite descarregar e executar modelos de IA localmente, incluindo acesso a aceleração por hardware para melhor desempenho e escalabilidade através do DirectML. O Foundry Toolkit também pode ajudar-te com:
- Testando modelos em um playground intuitivo ou em seu aplicativo com uma API REST.
- Ajustando seu modelo de IA, tanto localmente quanto na nuvem (em uma máquina virtual) para criar novas habilidades, melhorar a confiabilidade das respostas, definir o tom e o formato da resposta.
- Ajuste fino de modelos populares de linguagem pequena (SLMs), como Phi-3 e Mistral.
- Implante seu recurso de IA na nuvem ou com um aplicativo executado em um dispositivo.
- Aproveite a aceleração de hardware para obter um melhor desempenho com recursos de IA usando DirectML. O DirectML é uma API de baixo nível que permite ao hardware do seu dispositivo Windows acelerar o desempenho dos modelos de ML usando a GPU ou NPU do dispositivo. Emparelhar o DirectML com o ONNX Runtime é normalmente a maneira mais simples para os desenvolvedores trazerem IA acelerada por hardware para seus usuários em escala. Saiba mais: Visão geral do DirectML.
- Quantize e valide um modelo para uso em NPU usando os recursos de conversão de modelo
Ideias para tirar partido da IA local
Algumas formas pelas quais as aplicações Windows podem aproveitar a IA local para melhorar a sua funcionalidade e experiência do utilizador incluem:
- As aplicações podem usar modelos de LLM de IA Generativa para compreender tópicos complexos e resumir, reescrever, reportar ou expandir.
- As aplicações podem usar modelos LLM para transformar conteúdos livres num formato estruturado que a sua aplicação possa compreender.
- As aplicações podem usar modelos de Pesquisa Semântica que permitem aos utilizadores pesquisar conteúdo pelo significado e encontrar rapidamente conteúdos relacionados.
- Os aplicativos podem usar modelos de processamento de linguagem natural para raciocinar sobre requisitos complexos de linguagem natural e planejar e executar ações para atender à solicitação do usuário.
- Os aplicativos podem usar modelos de manipulação de imagem para modificar imagens de forma inteligente, apagar ou adicionar assuntos, escalonar ou gerar novos conteúdos.
- Os aplicativos podem usar modelos de diagnóstico preditivos para ajudar a identificar e prever problemas e ajudar a orientar o usuário ou fazer isso por ele.
Usando modelos de IA na nuvem
Se usar recursos de IA locais não é o caminho certo para você, usar modelos e recursos de IA na nuvem pode ser uma solução.
Use práticas de IA responsável
Sempre que estiver a incorporar funcionalidades de IA na sua aplicação Windows, recomendamos altamente seguir as orientações Desenvolvimento de Aplicações e Funcionalidades de IA Generativa Responsáveis no Windows.