Nota
O acesso a esta página requer autorização. Pode tentar iniciar sessão ou alterar os diretórios.
O acesso a esta página requer autorização. Pode tentar alterar os diretórios.
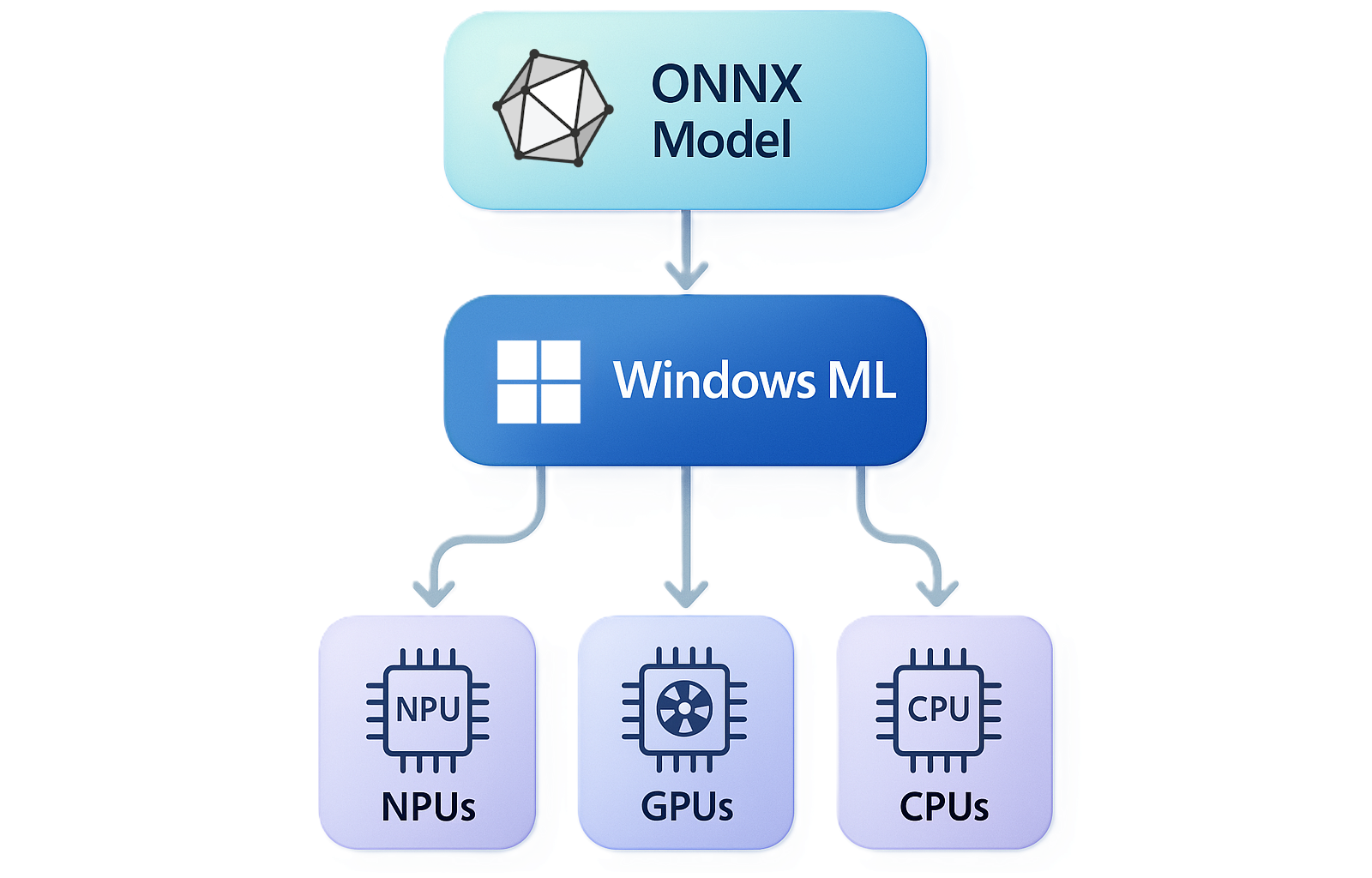
O Windows ML é a framework unificada e de alto desempenho para inferência de IA local para Windows, alimentada pelo ONNX Runtime. Com o Windows ML, pode executar modelos de IA localmente e acelerar a inferência em NPUs, GPUs e CPUs através de fornecedores de execução opcionais que o Windows gere e mantém atualizados. Podes usar modelos do PyTorch, TensorFlow/Keras, TFLite, scikit-learn e outros frameworks com Windows ML.
Principais benefícios
O Windows ML facilita a integração da inferência de IA em qualquer aplicação Windows:
- Execute IA no dispositivo — os modelos correm localmente no hardware do utilizador, mantendo os dados privados, eliminando custos na cloud e funcionando sem ligação à internet.
- Use modelos que já tenha — traga modelos de PyTorch, TensorFlow, scikit-learn, Hugging Face e mais.
- Aceleração de hardware, facilitada pelo Windows — O Windows ML permite-lhe aceder a NPUs, GPUs e CPUs específicas para IHV através de fornecedores de execução que o Windows instala e mantém atualizados via Windows Update — sem necessidade de incluir os fornecedores de execução na sua aplicação.
- Um runtime, muitas apps — opcionalmente, use o Windows ML como um componente do sistema partilhado, para que a sua app permaneça pequena e todas as apps no dispositivo partilhem o mesmo runtime atualizado, em vez de cada app incluir sua própria cópia.
- Desempenho de excelência — O Windows ML oferece um desempenho extremo em NPUs e GPUs, ao nível de SDKs dedicados como o TensorRT para RTX ou o AI Engine Direct da Qualcomm. Os resultados de desempenho variam consoante a configuração de hardware e o modelo — consulte os modelos Accelerate AI para orientações específicas de hardware.
Porque usar o Windows ML em vez do Microsoft ORT?
O Windows ML é a cópia suportada e mantida pelo Windows do ONNX Runtime (ORT), disponível como cópia a nível de sistema ou autónoma:
- Mesmas APIs ONNX — sem alterações ao teu código ONNX Runtime existente
- Suportado por Windows — suportado e mantido pela equipa do Windows
- Suporte abrangente de hardware — funciona em PCs com Windows (x64 e ARM64) e Windows Server com qualquer configuração de hardware
- Opção de tamanho de aplicação mais pequeno — escolha a implementação dependente do framework e partilhe o tempo de execução entre as apps em vez de agrupar a sua própria cópia
- Atualizações opcionais de evergreen — escolha a implementação dependente do framework e os seus utilizadores obtêm sempre o tempo de execução mais recente via Windows Update
Além disso, o Windows ML permite que a sua aplicação adquira dinamicamente os mais recentes fornecedores de execução para acelerar os seus modelos de IA, sem ter de transportar os EPs na sua aplicação e criar builds separadas para hardware diferente.
Veja Comece com o Windows ML para experimentar por si mesmo!
Aceleração de hardware em NPU, GPU e CPU
O Windows ML permite-lhe aceder a fornecedores de execução que podem acelerar a inferência entre as três classes de silício presentes nos PCs Windows modernos:
- NPU — inferência sustentada e eficiente em bateria, com as NPUs mais potentes disponíveis em PCs Copilot+
- GPU — cargas de trabalho de alto rendimento, como imagem, vídeo e IA generativa, que geralmente fornecem o máximo desempenho em GPUs discretas
- CPU — solução universal de contingência, além de acelerações de CPU otimizadas para IHV
Para o mapeamento completo do silício para EP, requisitos de controladores e opções de aquisição de EP, consulte Acelerar modelos de IA.
Requisitos do sistema
- OS: Versão do Windows que SDK de Aplicações Windows suporta
- Arquitetura: x64 ou ARM64
- Hardware: Qualquer configuração de PC (CPUs, GPUs integradas/discretas, NPUs)
Observação
O suporte para CPU e GPU (via DirectML) está disponível em todas as versões suportadas do Windows. Os fornecedores de execução otimizados para hardware para NPUs e hardware específico de GPU requerem Windows 11 versão 24H2 (build 26100) ou superior. Para detalhes, veja Fornecedores de execução de Aprendizagem Automática do Windows.
Otimização do desempenho
A versão mais recente do Windows ML trabalha diretamente com fornecedores dedicados de execução para GPUs e NPUs, oferecendo um desempenho extremo que está ao nível dos SDKs dedicados do passado, como o TensorRT para RTX, AI Engine Direct e a Intel Extension for PyTorch. Desenvolvemos o Windows ML para ter um desempenho de GPU e NPU de excelência, sem exigir que a sua aplicação distribua SDKs específicos para IHV. Os resultados de desempenho variam consoante a configuração de hardware e o modelo — consulte os modelos Accelerate AI para orientações específicas de hardware.
Convertendo modelos para ONNX
Podes converter modelos de outros formatos para ONNX para os usares com Windows ML. Consulte o Foundry Toolkit para a documentação do Visual Studio Code sobre como converter modelos para o formato ONNX para saber mais. Consulte também os tutoriais do ONNX Runtime para obter mais informações sobre como converter modelos PyTorch, TensorFlow e Hugging Face para ONNX.
Distribuição dos modelos
O Windows ML oferece opções flexíveis para distribuir modelos de IA:
- Partilhe modelos entre aplicações - Descarregue e partilhe modelos dinamicamente entre aplicações a partir de qualquer CDN sem agrupar ficheiros grandes
- Modelos locais - Inclua arquivos de modelo diretamente no pacote do aplicativo
Integração com o ecossistema de IA do Windows
O Windows ML serve de base para a plataforma mais ampla de IA do Windows:
- Windows APIs de IA - Modelos incorporados para tarefas comuns
- Foundry Local - Modelos de IA prontos a usar
- Custom models - Acesso direto à API Windows ML para cenários especializados
Fornecer comentários
Encontrou um problema ou tem sugestões? Pesquise ou crie problemas no SDK de Aplicações Windows GitHub.
Próximos passos
- Executa modelos de IA - Instala o Windows ML e executa o teu primeiro modelo ONNX
- Acelerar modelos de IA - Adicionar fornecedores de execução de NPU, GPU ou CPU para inferência mais rápida
- Encontrar ou treinar modelos - Encontrar modelos compatíveis com Windows ML
- API reference - APIs WinRT e ONNX Runtime no pacote Microsoft.WindowsAppSDK.ML