Nota
O acesso a esta página requer autorização. Podes tentar iniciar sessão ou mudar de diretório.
O acesso a esta página requer autorização. Podes tentar mudar de diretório.
Na etapa anterior deste tutorial, instalamos o PyTorch em sua máquina. Agora, vamos usá-lo para configurar nosso código com os dados que usaremos para criar nosso modelo.
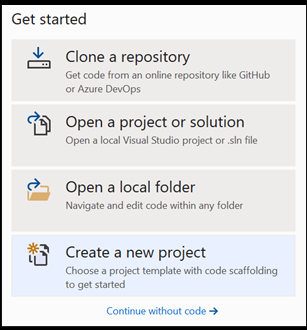
Abra um novo projeto no Visual Studio.
- Abra o Visual Studio e escolha
create a new project.
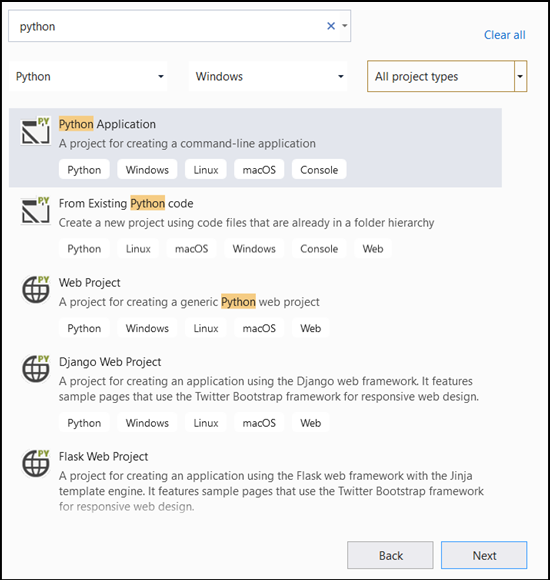
- Na barra de pesquisa, digite
Pythone selecionePython Applicationcomo seu modelo de projeto.
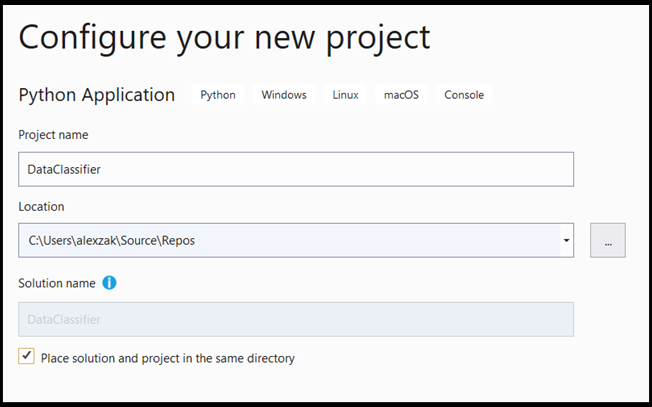
- Na janela de configuração:
- Atribua um nome ao seu projeto. Aqui, nós chamamos DataClassifier.
- Escolha a localização do seu projeto.
- Se você estiver usando o VS2019, verifique se
Create directory for solutionestá marcado. - Se você estiver usando o VS2017, verifique se
Place solution and project in the same directoryestá desmarcado.
Pressione create para criar seu projeto.
Criar um interpretador Python
Agora, você precisa definir um novo interpretador Python. Isso deve incluir o pacote PyTorch que você instalou recentemente.
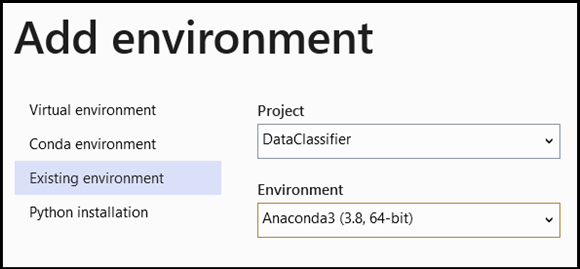
- Navegue até a seleção do intérprete e selecione
Add Environment:

-
Add EnvironmentNa janela, selecioneExisting environmente escolhaAnaconda3 (3.6, 64-bit). Isso inclui o pacote PyTorch.
Para testar o novo interpretador Python e o pacote PyTorch, insira o seguinte código no DataClassifier.py arquivo:
from __future__ import print_function
import torch
x=torch.rand(2, 3)
print(x)
A saída deve ser um tensor 5x3 aleatório semelhante ao abaixo.
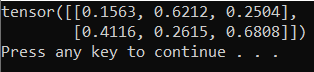
Observação
Interessado em saber mais? Visite o site oficial do PyTorch.
Compreender os dados
Vamos treinar o modelo no conjunto de dados da flor Fisher's Iris. Este famoso conjunto de dados inclui 50 registros para cada uma das três espécies de Iris: Iris setosa, Iris virginica e Iris versicolor.
Foram publicadas várias versões do conjunto de dados. Você pode encontrar o conjunto de dados Iris no UCI Machine Learning Repository, importar o conjunto de dados diretamente da biblioteca Python Scikit-learn ou usar qualquer outra versão publicada anteriormente. Para saber mais sobre o conjunto de dados da flor Iris, visite a página da Wikipédia.
Neste tutorial, para mostrar como treinar o modelo com o tipo tabular de entrada, você usará o conjunto de dados Iris exportado para o arquivo do Excel.
Cada linha da tabela excel mostrará quatro características de Irises: comprimento da sépala em cm, largura da sépala em cm, comprimento da pétala em cm e largura da pétala em cm. Esses recursos servirão como sua entrada. A última coluna inclui o tipo Iris relacionado a esses parâmetros e representará a saída de regressão. No total, o conjunto de dados inclui 150 entradas de quatro características, cada uma delas correspondente ao tipo de Iris relevante.
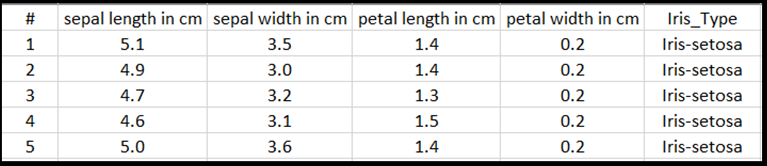
A análise de regressão analisa a relação entre as variáveis de entrada e o resultado. Com base na entrada, o modelo aprenderá a prever o tipo correto de saída - um dos três tipos de Iris: Iris-setosa, Iris-versicolor, Iris-virginica.
Importante
Se você decidir usar qualquer outro conjunto de dados para criar seu próprio modelo, precisará especificar as variáveis de entrada e saída do modelo de acordo com seu cenário.
Carregue o conjunto de dados.
Baixe o conjunto de dados Iris no formato Excel. Pode encontrá-lo aqui.
No arquivo na pasta
DataClassifier.py, adicione a seguinte instrução de importação para obter acesso a todos os pacotes necessários.
import torch
import pandas as pd
import torch.nn as nn
from torch.utils.data import random_split, DataLoader, TensorDataset
import torch.nn.functional as F
import numpy as np
import torch.optim as optim
from torch.optim import Adam
Como você pode ver, você usará o pacote pandas (análise de dados Python) para carregar e manipular dados e o pacote torch.nn que contém módulos e classes extensíveis para a construção de redes neurais.
- Carregue os dados na memória e verifique o número de classes. Esperamos ver 50 itens de cada tipo de Iris. Certifique-se de especificar a localização do conjunto de dados no seu PC.
Adicione o seguinte código ao ficheiro DataClassifier.py.
# Loading the Data
df = pd.read_excel(r'C:…\Iris_dataset.xlsx')
print('Take a look at sample from the dataset:')
print(df.head())
# Let's verify if our data is balanced and what types of species we have
print('\nOur dataset is balanced and has the following values to predict:')
print(df['Iris_Type'].value_counts())
Quando executamos este código, a saída esperada é a seguinte:
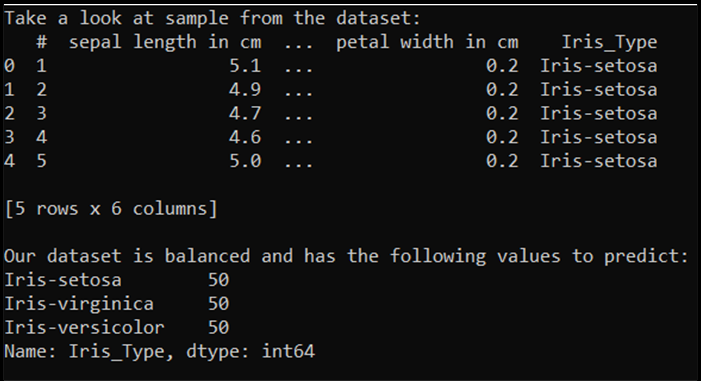
Para poder usar o conjunto de dados e treinar o modelo, precisamos definir entrada e saída. A entrada inclui 150 linhas de características, e a saída é a coluna do tipo Iris. A rede neural que usaremos requer variáveis numéricas, então você converterá a variável de saída para um formato numérico.
- Crie uma nova coluna no conjunto de dados que representará a saída em um formato numérico e definirá uma entrada e saída de regressão.
Adicione o seguinte código ao ficheiro DataClassifier.py.
# Convert Iris species into numeric types: Iris-setosa=0, Iris-versicolor=1, Iris-virginica=2.
labels = {'Iris-setosa':0, 'Iris-versicolor':1, 'Iris-virginica':2}
df['IrisType_num'] = df['Iris_Type'] # Create a new column "IrisType_num"
df.IrisType_num = [labels[item] for item in df.IrisType_num] # Convert the values to numeric ones
# Define input and output datasets
input = df.iloc[:, 1:-2] # We drop the first column and the two last ones.
print('\nInput values are:')
print(input.head())
output = df.loc[:, 'IrisType_num'] # Output Y is the last column
print('\nThe output value is:')
print(output.head())
Quando executamos este código, a saída esperada é a seguinte:
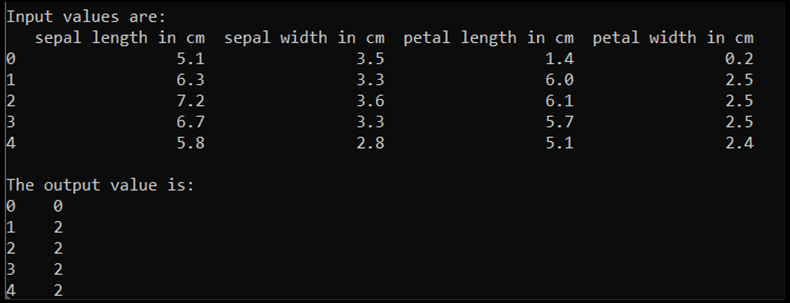
Para treinar o modelo, precisamos converter a entrada e saída do modelo para o formato Tensor:
- Converter para Tensor
Adicione o seguinte código ao ficheiro DataClassifier.py.
# Convert Input and Output data to Tensors and create a TensorDataset
input = torch.Tensor(input.to_numpy()) # Create tensor of type torch.float32
print('\nInput format: ', input.shape, input.dtype) # Input format: torch.Size([150, 4]) torch.float32
output = torch.tensor(output.to_numpy()) # Create tensor type torch.int64
print('Output format: ', output.shape, output.dtype) # Output format: torch.Size([150]) torch.int64
data = TensorDataset(input, output) # Create a torch.utils.data.TensorDataset object for further data manipulation
Se executarmos o código, a saída esperada mostrará o formato de entrada e saída, da seguinte forma:

Existem 150 valores de entrada. Aproximadamente 60% constituirão os dados de treino do modelo. Vai ficar com 20% para validação e 30% para um teste.
Neste tutorial, o tamanho do lote para um conjunto de dados de treinamento é definido como 10. Há 95 itens no conjunto de treino, o que significa que, em média, há 9 lotes completos para percorrer o conjunto de treino uma vez (um ciclo). Você manterá o tamanho do lote dos conjuntos de validação e teste como 1.
- Divida os dados para treinar, validar e testar conjuntos:
Adicione o seguinte código ao ficheiro DataClassifier.py.
# Split to Train, Validate and Test sets using random_split
train_batch_size = 10
number_rows = len(input) # The size of our dataset or the number of rows in excel table.
test_split = int(number_rows*0.3)
validate_split = int(number_rows*0.2)
train_split = number_rows - test_split - validate_split
train_set, validate_set, test_set = random_split(
data, [train_split, validate_split, test_split])
# Create Dataloader to read the data within batch sizes and put into memory.
train_loader = DataLoader(train_set, batch_size = train_batch_size, shuffle = True)
validate_loader = DataLoader(validate_set, batch_size = 1)
test_loader = DataLoader(test_set, batch_size = 1)
Próximas Etapas
Com os dados prontos, é hora de treinar nosso modelo PyTorch