Nota
O acesso a esta página requer autorização. Pode tentar iniciar sessão ou alterar os diretórios.
O acesso a esta página requer autorização. Pode tentar alterar os diretórios.
Integre o reconhecimento de voz e a síntese de voz (também conhecido como TTS, ou síntese de voz) diretamente na experiência do utilizador da sua aplicação.
Reconhecimento de fala O reconhecimento de voz converte palavras ditas pelo utilizador em texto para introdução de formulários, para ditado de texto, para especificar uma ação ou comando, e para realizar tarefas. Suporta tanto gramáticas pré-definidas para ditado em texto livre e pesquisa na web, como gramáticas personalizadas criadas usando a Especificação de Gramática de Reconhecimento de Fala (SRGS) Versão 1.0.
Síntese de voz/Text to Speech (TTS) TTS utiliza um motor de síntese de voz (voz) para converter uma cadeia de texto em palavras faladas. A cadeia de entrada pode ser texto básico e despojado ou uma Linguagem de Marcação de Síntese de Fala (SSML) mais complexa. O SSML fornece uma forma padrão de controlar características da saída da fala, como pronúncia, volume, tom, frequência ou velocidade, e ênfase.
Design de interação de fala
Quando se desenha e implementa a fala de forma ponderada, pode ser uma forma eficaz, acessível e natural de as pessoas interagirem com as suas aplicações Windows, complementando ou até substituindo experiências tradicionais de interação baseadas num rato, teclado, comando ou toque.
Estas orientações e recomendações descrevem como integrar da melhor forma tanto o reconhecimento de fala como o TTS na experiência de interação da sua aplicação.
Se está a considerar apoiar interações de fala na sua aplicação, faça a si próprio as seguintes perguntas:
- Que ações podem os utilizadores tomar através da fala? Conseguem navegar entre páginas, invocar comandos ou introduzir dados como campos de texto, notas breves ou mensagens longas?
- A entrada de voz é uma boa opção para completar uma tarefa?
- Como é que um utilizador sabe quando há entrada de voz disponível?
- A aplicação está sempre a ouvir, ou o utilizador precisa de tomar alguma ação para que a aplicação entre em modo de escuta?
- Que frases iniciam uma ação ou comportamento? As frases e ações precisam de ser enumeradas no ecrã?
- São necessários ecrãs de prompt, confirmação e desambiguação ou TTS?
- Qual é o diálogo de interação entre a aplicação e o utilizador?
- É necessário um vocabulário personalizado ou limitado (como medicina, ciência ou local) para o contexto da sua aplicação?
- É necessária conectividade de rede?
Entrada de texto
A introdução de texto pode variar desde entradas curtas, como uma única palavra ou frase, até entradas longas, como múltiplas frases, parágrafos ou ditados contínuos. As entradas curtas têm normalmente menos de 10 segundos de duração, enquanto as sessões longas podem durar até dois minutos. A entrada de formato longo pode reiniciar sem intervenção do utilizador para dar a impressão de ditado contínuo.
Forneça um sinal visual para indicar que o reconhecimento de voz é suportado e está disponível para o utilizador e se este precisa de o ativar. Por exemplo, use um botão de barra de comandos com um glifo de microfone (ver barras de comandos) para mostrar tanto a disponibilidade como o estado.
Forneça feedback contínuo de reconhecimento para minimizar qualquer aparente falta de resposta enquanto o reconhecimento está a ser realizado.
Permita aos utilizadores rever texto de reconhecimento usando introdução por teclado, prompts de desambiguação, sugestões ou reconhecimento de voz adicional.
Parar o reconhecimento se for detetada entrada de um dispositivo que não seja o reconhecimento de voz, como tátil ou teclado. Esta entrada provavelmente indica que o utilizador passou para outra tarefa, como corrigir o texto de reconhecimento ou interagir com outros campos do formulário.
Especifique o tempo durante o qual nenhuma entrada de fala indica que o reconhecimento terminou. Não reinicie automaticamente o reconhecimento após este período, pois normalmente indica que o utilizador deixou de interagir com a sua aplicação.
Em alguns casos, pode ser necessária uma ligação de rede para suportar o reconhecimento de voz. Se não estiver disponível, desative toda a interface de reconhecimento contínuo e termine a sessão de reconhecimento.
Comando
A entrada de voz pode iniciar ações, invocar comandos e realizar tarefas.
Se o espaço permitir, considere mostrar as respostas suportadas para o contexto atual da aplicação, com exemplos de entrada válida. Esta abordagem reduz as potenciais respostas que a sua aplicação precisa de processar e também elimina a confusão para o utilizador.
Tente formular as suas perguntas de forma a obter uma resposta o mais específica possível. Por exemplo, "O que queres fazer hoje?" é muito aberto e requer uma definição gramatical muito extensa devido à variação das respostas. Alternativamente, "Gostaria de jogar um jogo ou ouvir música?" limita a resposta a uma de duas respostas válidas com uma definição gramatical correspondente pequena. Uma pequena gramática é mais fácil de criar e resulta em resultados de reconhecimento muito mais precisos.
Peça confirmação ao utilizador quando a confiança no reconhecimento de fala estiver baixa. Se a intenção do utilizador não estiver clara, é melhor obter esclarecimentos do que iniciar uma ação não intencional.
Forneça um sinal visual para indicar que o reconhecimento de voz é suportado e está disponível para o utilizador e se este precisa de o ativar. Por exemplo, use um botão de barra de comandos com um glifo de microfone (ver Diretrizes para barras de comando) para mostrar tanto a disponibilidade como o estado.
Se o interruptor de reconhecimento de voz estiver normalmente fora de vista, considere exibir um indicador de estado na área de conteúdo da aplicação.
Se o utilizador iniciar o reconhecimento, considere usar a experiência de reconhecimento incorporada para maior consistência. A experiência integrada inclui ecrãs personalizáveis com prompts, exemplos, desambiguações, confirmações e erros.
Os ecrãs variam consoante as restrições especificadas:
Gramática pré-definida (ditado ou pesquisa na web)
- O ecrã de escuta.
- O ecrã Pensamento.
- O ecrã "Ouvir o que disse" ou o ecrã de erro.
Lista de palavras ou expressões, ou um ficheiro gramatical SRGS
- O ecrã de escuta.
- O ecrã do "Disseste", se o que o utilizador disse puder ser interpretado como mais de um resultado potencial.
- O ecrã "Ouvir o que disse" ou o ecrã de erro.
No ecrã de Audição, pode:
- Personaliza o texto do título.
- Forneça texto de exemplo do que o utilizador pode dizer.
- Especifique se o ecrã ouviu dizer é mostrado.
- Lê a cadeia reconhecida de volta ao utilizador no ecrã Ouvi você disse.
As imagens seguintes mostram um exemplo do fluxo de reconhecimento incorporado para um reconhecor de fala que utiliza uma restrição definida pelo SRGS. Neste exemplo, o reconhecimento de fala é bem-sucedido.
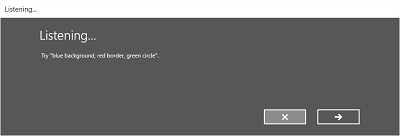
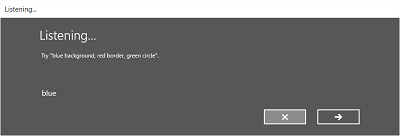
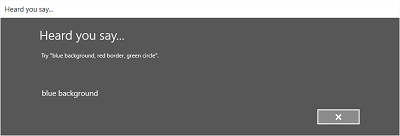
Sempre a ouvir
A sua aplicação pode ouvir e reconhecer a entrada de voz assim que a aplicação é iniciada, sem intervenção do utilizador.
Personaliza as restrições gramaticais com base no contexto da aplicação. Esta abordagem mantém a experiência de reconhecimento de fala muito direcionada e relevante para a tarefa atual, minimizando os erros.
"O que posso dizer?"
Ao ativar a entrada de voz, ajude os utilizadores a descobrir o que a aplicação pode compreender e que ações pode realizar.
Se os utilizadores ativarem o reconhecimento de voz, considere usar a barra de comandos ou um comando de menu para mostrar todas as palavras e frases suportadas no contexto atual.
Se o reconhecimento de fala estiver sempre ativo, considere adicionar a frase "O que posso dizer?" em cada página. Quando o utilizador disser esta frase, mostre todas as palavras e expressões suportadas no contexto atual. A utilização desta frase proporciona uma forma consistente para os utilizadores descobrirem capacidades de fala em todo o sistema.
Falhas de reconhecimento
O reconhecimento de fala pode falhar. As falhas acontecem quando a qualidade do áudio é má, quando o reconhecedor deteta apenas parte de uma frase, ou quando não deteta qualquer input.
Lide com a falha com elegância, ajude o utilizador a perceber porque é que o reconhecimento falhou e recupere.
A tua aplicação deve informar o utilizador que o reconhecedor não o entendeu e que precisa de tentar novamente.
Considere fornecer exemplos de uma ou mais frases apoiadas. O utilizador tende a repetir uma frase sugerida, o que aumenta o sucesso do reconhecimento.
Mostre uma lista de potenciais correspondências para o utilizador escolher. Esta abordagem pode ser muito mais eficiente do que passar novamente pelo processo de reconhecimento.
Apoie sempre tipos de entrada alternativos, o que é especialmente útil para lidar com falhas de reconhecimento repetidas. Por exemplo, pode sugerir que o utilizador tente usar um teclado, ou o toque ou o rato para selecionar de uma lista de potenciais combinações.
Use a experiência de reconhecimento de voz incorporada, pois inclui ecrãs que informam o utilizador de que o reconhecimento não foi bem-sucedido e permitem que o utilizador faça uma nova tentativa de reconhecimento.
Ouve e tenta corrigir problemas na entrada de áudio. O reconhecedor de voz pode detetar problemas na qualidade do áudio que possam afetar negativamente a precisão do reconhecimento de voz. Pode usar a informação fornecida pelo reconhecimento de fala para informar o utilizador do problema e permitir que tome medidas corretivas, se possível. Por exemplo, se o volume do microfone estiver demasiado baixo, pode pedir ao utilizador para falar mais alto ou aumentar o volume.
Restrições
As restrições, ou gramáticas, definem as palavras e frases faladas que o reconhecedor de fala pode reconhecer. Pode especificar uma das gramáticas pré-definidas dos serviços web ou criar uma gramática personalizada que instale com a sua aplicação.
Gramáticas pré-definidas
A ditadura pré-definida e as gramáticas de pesquisa na web fornecem reconhecimento de voz para a sua aplicação sem que precise de criar uma gramática. Quando utiliza estas gramáticas, um serviço web remoto realiza o reconhecimento de voz e devolve os resultados ao dispositivo.
- A gramática padrão de ditado em texto livre reconhece a maioria das palavras e expressões que um utilizador pode dizer numa determinada língua. Está otimizado para reconhecer frases curtas. Use ditado em texto livre quando não quiser limitar o tipo de coisas que um utilizador pode dizer. Utilizações típicas incluem criar notas ou ditar o conteúdo de uma mensagem.
- A gramática de pesquisa na web, tal como a gramática de ditado, contém um grande número de palavras e frases que um utilizador pode dizer. No entanto, está otimizado para reconhecer termos que as pessoas normalmente usam ao pesquisar na internet.
Observação
Como as gramáticas pré-definidas de ditado e pesquisa na web podem ser grandes, e porque estão online (não no dispositivo), o desempenho pode não ser tão rápido como com uma gramática personalizada instalada no dispositivo.
Estas gramáticas pré-definidas podem reconhecer até 10 segundos de entrada de fala e não requerem esforço de autoria. No entanto, exigem ligação a uma rede.
Gramáticas personalizadas
Desenhe e crie uma gramática personalizada, e instale-a com a sua aplicação. O dispositivo realiza reconhecimento de voz utilizando uma restrição personalizada.
As restrições de listas programáticas fornecem uma abordagem leve para criar gramáticas simples, utilizando uma lista de palavras ou frases. Uma restrição de lista funciona bem para reconhecer frases curtas e distintas. Especificar explicitamente todas as palavras numa gramática também melhora a precisão do reconhecimento, pois o motor de reconhecimento de fala só deve processar a fala para confirmar uma correspondência. Também pode atualizar a lista programaticamente.
Uma gramática SRGS é um documento estático que, ao contrário de uma restrição programática de lista, utiliza o formato XML definido pela Versão 1.0 do SRGS. Uma gramática SRGS oferece o maior controlo sobre a experiência de reconhecimento de voz, permitindo captar múltiplos significados semânticos num único reconhecimento.
Aqui ficam algumas dicas para criar gramáticas SRGS:
- Mantenha cada gramática pequena. Gramáticas que contêm menos frases tendem a proporcionar um reconhecimento mais preciso do que gramáticas maiores que contêm muitas frases. É melhor ter várias gramáticas mais pequenas para cenários específicos do que ter uma única gramática para toda a aplicação.
- Informe os utilizadores sobre o que dizer para cada contexto da aplicação e ative e desative as gramáticas conforme necessário.
- Desenhe cada gramática para que os utilizadores possam pronunciar um comando de várias formas. Por exemplo, use a GARBAGE rule para tratar a entrada de voz que a gramática não reconhece. Esta regra permite que os utilizadores pronunciem palavras adicionais que não têm significado para a sua aplicação. Por exemplo, "dá-me", "e", "ãh", "talvez", e assim por diante.
- Use o elemento sapi:subset para ajudar a compatibilizar com a entrada de voz. Este elemento é uma extensão da Microsoft à especificação SRGS para ajudar a corresponder frases parciais.
- Tente evitar definir frases na sua gramática que contenham apenas uma sílaba. O reconhecimento tende a ser mais preciso para frases que contêm duas ou mais sílabas.
- Evite usar frases que soem semelhantes. Por exemplo, frases como "olá", "bellow" e "fellow" podem confundir o motor de reconhecimento e resultar em fraca precisão de reconhecimento.
Observação
O tipo de restrição que usa depende da complexidade da experiência de reconhecimento que pretende criar. Qualquer tipo pode ser a melhor escolha para uma tarefa de reconhecimento específica, e podes encontrar utilidades para todos os tipos de restrições na tua aplicação.
Pronúncias personalizadas
Se a sua aplicação contiver vocabulário especializado com palavras invulgares ou fictícias, ou palavras com pronúncias pouco comuns, poderá melhorar o desempenho de reconhecimento dessas palavras ao definir pronúncias personalizadas.
Para uma pequena lista de palavras e expressões, ou uma lista de palavras e expressões usadas com pouca frequência, crie pronúncias personalizadas numa gramática SRGS. Consulte Token Element para mais informações.
Para listas maiores de palavras e expressões, ou palavras e expressões frequentemente usadas, crie documentos de léxico de pronúncia separados. Consulte Sobre Léxicos e Alfabetos Fonéticos para mais informações.
Testes
Teste a precisão do reconhecimento de fala e qualquer interface de suporte com o público-alvo da sua aplicação. Esta abordagem ajuda-o a determinar quão eficaz é a experiência da interação de fala na sua aplicação. Por exemplo, os utilizadores estão a obter resultados de reconhecimento fracos porque a sua aplicação não ouve uma frase comum?
Ou modifica a gramática para suportar esta frase ou fornece aos utilizadores uma lista de frases suportadas. Se já forneces a lista de frases suportadas, certifica-te de que os utilizadores a encontram facilmente.
Texto para fala (TTS)
O TTS gera saída de voz a partir de texto sem formatação ou SSML.
Tente criar prompts educados e encorajadores.
Considere se deve ler longas sequências de texto. Uma coisa é ouvir uma mensagem de texto, outra bem diferente é ouvir uma longa lista de resultados de pesquisa difíceis de recordar.
Forneça controlos de media para permitir que os utilizadores pausem ou parem o TTS.
Ouve todas as cordas TTS para garantir que são inteligíveis e soam naturais.
- Juntar uma sequência incomum de palavras, números ou pontuação pode tornar uma frase ininteligível.
- A fala pode soar artificial quando a prosódia ou a cadência são diferentes da forma como um falante nativo diria uma frase.
Pode resolver ambos os problemas usando SSML em vez de texto simples como entrada para o sintetizador de voz. Para mais informações sobre SSML, consulte Use SSML para Controlar a Fala Sintetizada e Referência de Linguagem de Marcação de Síntese de Fala.