Динамическая миграция в управляемый экземпляр Azure для Apache Cassandra с использованием прокси-сервера двойной записи
Рекомендуем по возможности использовать собственную функцию Apache Cassandra для переноса данных из существующего кластера в управляемый экземпляр Azure для Apache Cassandra, настроив гибридный кластер. Эта возможность использует протокол Apache Cassandra для непрерывной репликации данных из исходного центра обработки данных в новый управляемый экземпляр. Однако возможны ситуации, когда версия исходной базы данных несовместима или установка гибридного кластера нецелесообразна.
В этом учебнике описывается, как перенести данные в Управляемый экземпляр Azure для Apache Cassandra в реальном времени с помощью прокси-сервера двойной записи и Apache Spark. Прокси-сервер с двойной записью используется для записи изменений, происходящих в реальном времени, а исторические данные массово копируются помощью Apache Spark. Преимущества этого подхода
- Минимальные изменения приложения. Прокси-сервер может принимать подключения из кода приложения с минимальными изменениями конфигурации или без них. Он направляет все запросы к исходной базе данных и асинхронно перенаправляет операции записи во вторичную цель.
- Зависимость от протокола проводного соединения клиента. Поскольку этот подход не зависит от серверных ресурсов и внутренних протоколов, его можно использовать с любой исходной или целевой системой Cassandra, в которой реализован протокол проводного соединения Apache Cassandra.
На приведенном ниже рисунке представлен этот подход.

Предварительные требования
Подготовьте кластер Управляемого экземпляра Azure для Apache Cassandra с помощью портала Azure или интерфейса командной строки Azure. Убедитесь, что вы можете подключиться к кластеру с помощью CQLSH.
Подготовьте учетную запись Azure Databricks в управляемой виртуальной сети Cassandra. Убедитесь, что у учетной записи есть сетевой доступ к исходному кластеру Cassandra. В этой учетной записи будет создан кластер Spark для загрузки исторических данных.
Убедитесь, что вы уже перенесли схему пространства ключей или таблицы из исходной базы данных Cassandra в целевую базу данных управляемого экземпляра Cassandra.
Подготовка кластера Spark
Мы рекомендуем выбрать среду выполнения Databricks версии 7.5, которая поддерживает Spark 3.0.
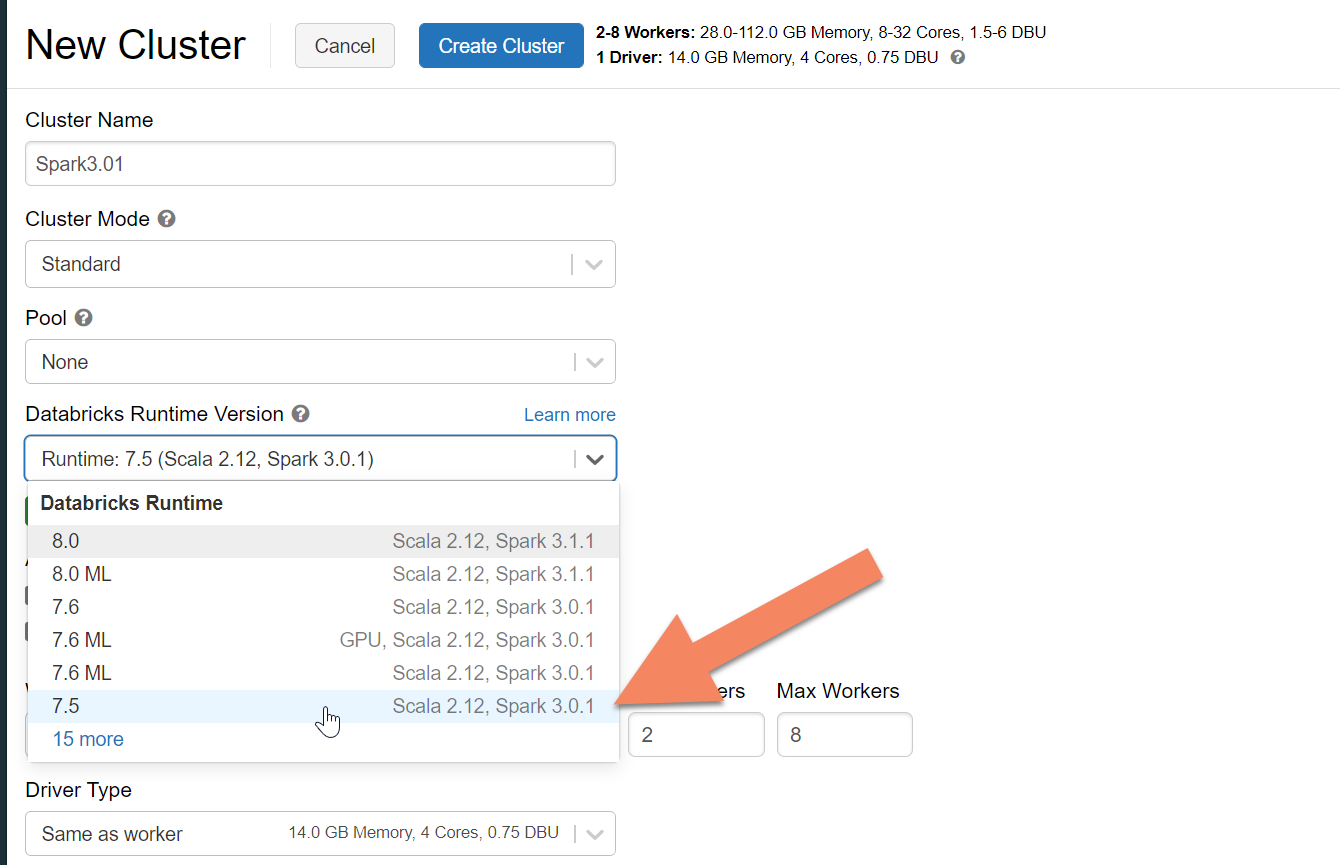
Добавление зависимостей Spark
Необходимо добавить библиотеку соединителя Apache Spark Cassandra в кластер, чтобы подключиться к любым конечным точкам Apache Cassandra, совместимым с проводным протоколом. В кластере выберите Библиотеки>Установить>Maven, а затем добавьте com.datastax.spark:spark-cassandra-connector-assembly_2.12:3.0.0 в координаты Maven.
Важно!
Если во время миграции вам необходимо сохранить writetime Apache Cassandra для каждой строки, рекомендуем использовать этот пример. JAR-файл зависимостей в примере также содержит соединитель Spark, поэтому вам нужно установить его вместо сборки соединителя, указанной выше. Этот пример также пригодится, если вы хотите выполнить проверку со сравнением строк между исходным и целевым объектами после завершения загрузки исторических данных. Дополнительные сведения см. в разделах Запуск нагрузки исторических данных и Проверка исходного и целевого объектов ниже.
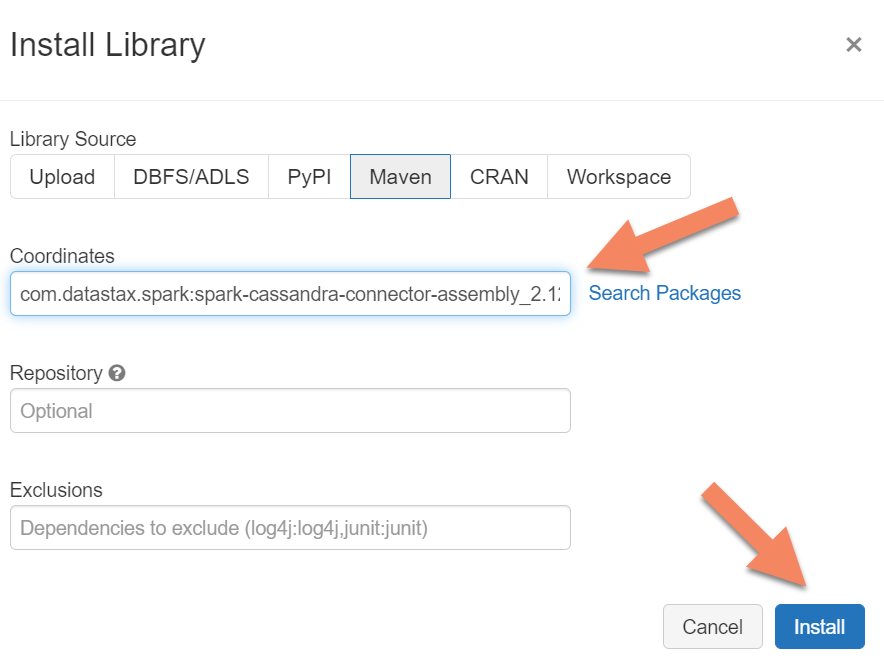
Нажмите кнопку Установить, а затем перезапустите кластер после завершения установки.
Примечание
Не забудьте перезапустить кластер Azure Databricks после установки библиотеки соединителя Cassandra.
Установка прокси-сервера двойной записи
Для достижения оптимальной производительности операций двойной записи рекомендуется установить прокси-сервер на всех узлах в исходном кластере Cassandra.
#assuming you do not have git already installed
sudo apt-get install git
#assuming you do not have maven already installed
sudo apt install maven
#clone repo for dual-write proxy
git clone https://github.com/Azure-Samples/cassandra-proxy.git
#change directory
cd cassandra-proxy
#compile the proxy
mvn package
Запуск прокси-сервера двойной записи
Рекомендуем установить прокси-сервер на всех узлах в исходном кластере Cassandra. Для запуска прокси-сервера на каждом узле необходимо как минимум выполнить приведенную ниже команду. Замените <target-server> на IP-адрес или адрес сервера одного из узлов в целевом кластере. Замените <path to JKS file> на путь к локальному JKS-файлу, а <keystore password> — на соответствующий пароль.
java -jar target/cassandra-proxy-1.0-SNAPSHOT-fat.jar localhost <target-server> --proxy-jks-file <path to JKS file> --proxy-jks-password <keystore password>
Запуск прокси-сервера таким способом предполагает соблюдение следующих условий:
- исходная и целевая конечные точки используют одни и те же имя пользователя и пароль;
- в исходной и целевой конечных точках реализована поддержка протокола SSL.
Если ваши исходная и целевая конечные точки не отвечают этим условиям, ознакомьтесь с описанными ниже параметрами конфигурации.
Настройка SSL
Для протокола SSL можно реализовать существующее хранилище ключей (например, используемое исходным кластером) или создать самозаверяющий сертификат с помощью keytool:
keytool -genkey -keyalg RSA -alias selfsigned -keystore keystore.jks -storepass password -validity 360 -keysize 2048
Вы также можете отключить SSL для исходной или целевой конечной точки, если для них не используется SSL. Используйте флаг --disable-source-tls или --disable-target-tls.
java -jar target/cassandra-proxy-1.0-SNAPSHOT-fat.jar localhost <target-server> --source-port 9042 --target-port 10350 --proxy-jks-file <path to JKS file> --proxy-jks-password <keystore password> --target-username <username> --target-password <password> --disable-source-tls true --disable-target-tls true
Примечание
Убедитесь, что клиентское приложение использует те же хранилище ключей и пароли, что и при установке SSL-соединений с базой данных через прокси-сервер двойной записи.
Настройка учетных данных и порта
По умолчанию исходные учетные данные передаются через ваше клиентское приложение. Прокси-сервер использует учетные данные для подключения к исходному и целевому кластерам. Как упоминалось ранее, в этом процессе предполагается, что исходные и целевые учетные данные совпадают. При необходимости можно отдельно указать другие имя пользователя и пароль целевой конечной точки Cassandra при запуске прокси-сервера.
java -jar target/cassandra-proxy-1.0-SNAPSHOT-fat.jar localhost <target-server> --proxy-jks-file <path to JKS file> --proxy-jks-password <keystore password> --target-username <username> --target-password <password>
Для исходного и целевого портов по умолчанию, если они не указаны, будет задано значение 9042. Если целевая или исходная конечные точки Cassandra запущены на другом порту, можно использовать --source-port или --target-port, чтобы указать другой номер порта.
java -jar target/cassandra-proxy-1.0-SNAPSHOT-fat.jar localhost <target-server> --source-port 9042 --target-port 10350 --proxy-jks-file <path to JKS file> --proxy-jks-password <keystore password> --target-username <username> --target-password <password>
Удаленное развертывание прокси-сервера
Могут возникнуть обстоятельства, когда нежелательно устанавливать прокси непосредственно на узлах кластера, а вместо этого требуется установить его на отдельном компьютере. В этом случае необходимо указать IP-адрес <source-server>:
java -jar target/cassandra-proxy-1.0-SNAPSHOT-fat.jar <source-server> <destination-server>
Предупреждение
Если вы предпочитаете удаленно запускать прокси-сервер на отдельном компьютере (а не на всех узлах в исходном кластере Apache Cassandra), рекомендуется развернуть прокси-сервер на том же количестве компьютеров, что и узлы в кластере, и настроить подстановку их IP-адресов в system.peers с помощью конфигурации в прокси-сервере, упомянутом здесь. Если этого не сделать, это может повлиять на производительность во время динамической миграции, так как драйвер клиента не сможет открывать подключения ко всем узлам в кластере.
Предотвращение изменения кода приложения
По умолчанию прокси-сервер прослушивает порт 29042. Код приложения необходимо изменить, чтобы он указывал на этот порт. Однако вы можете изменить порт, который прослушивает прокси-сервер. Если вы хотите избежать изменения кода на уровне приложения, можно сделать следующее:
- запустить исходный сервер Cassandra на другом порту;
- запустить прокси-сервер на стандартом для Cassandra порту 9042.
java -jar target/cassandra-proxy-1.0-SNAPSHOT-fat.jar source-server destination-server --proxy-port 9042
Примечание
Для установки прокси-сервера на узлах кластера не требуется перезапуск этих узлов. Однако если у вас много клиентов приложений и вы предпочитаете использовать прокси-сервер на стандартном порту Cassandra 9042, чтобы избежать изменения кода на уровне приложения, необходимо изменить порт по умолчанию для Apache Cassandra. Затем необходимо перезапустить узлы в кластере и настроить исходный порт в качестве нового порта, определенного в исходном кластере Cassandra.
В следующем примере мы переведем исходный кластер Cassandra на порт 3074 и запустим кластер на порту 9042:
java -jar target/cassandra-proxy-1.0-SNAPSHOT-fat.jar source-server destination-server --proxy-port 9042 --source-port 3074
Принудительное применение протоколов
Прокси-сервер поддерживает принудительное применение протоколов, которое может потребоваться, если исходная конечная точка сложнее целевой или не поддерживается по другой причине. В таком случае вы можете указать параметры --protocol-version и --cql-version, чтобы принудительно сопоставить протокол с целевым объектом:
java -jar target/cassandra-proxy-1.0-SNAPSHOT-fat.jar source-server destination-server --protocol-version 4 --cql-version 3.11
После запуска прокси-сервера двойной записи необходимо изменить порт в клиенте приложения и перезапустить его. Если выбран этот подход, вы также можете изменить порт Cassandra и перезапустить кластер. После этого прокси-сервер начнет переадресовывать запросы на запись целевой конечной точке. Вы можете узнать о мониторинге и метриках, доступных в средстве прокси-сервера.
Запуск нагрузки исторических данных
Чтобы загрузить данные, создайте записную книжку Scala в учетной записи Azure Databricks. Замените исходные и целевые конфигурации Cassandra соответствующими учетными данными, а также замените исходные и целевые пространства ключей и таблицы. Добавьте дополнительные переменные для каждой таблицы, как указано в приведенном ниже примере, а затем выполните команду. После того как приложение начнет отправлять запросы на прокси-сервер двойной записи, можно приступать к переносу исторических данных.
import com.datastax.spark.connector._
import com.datastax.spark.connector.cql._
import org.apache.spark.SparkContext
// source cassandra configs
val sourceCassandra = Map(
"spark.cassandra.connection.host" -> "<Source Cassandra Host>",
"spark.cassandra.connection.port" -> "9042",
"spark.cassandra.auth.username" -> "<USERNAME>",
"spark.cassandra.auth.password" -> "<PASSWORD>",
"spark.cassandra.connection.ssl.enabled" -> "true",
"keyspace" -> "<KEYSPACE>",
"table" -> "<TABLE>"
)
//target cassandra configs
val targetCassandra = Map(
"spark.cassandra.connection.host" -> "<Source Cassandra Host>",
"spark.cassandra.connection.port" -> "9042",
"spark.cassandra.auth.username" -> "<USERNAME>",
"spark.cassandra.auth.password" -> "<PASSWORD>",
"spark.cassandra.connection.ssl.enabled" -> "true",
"keyspace" -> "<KEYSPACE>",
"table" -> "<TABLE>",
//throughput related settings below - tweak these depending on data volumes.
"spark.cassandra.output.batch.size.rows"-> "1",
"spark.cassandra.output.concurrent.writes" -> "1000",
"spark.cassandra.connection.remoteConnectionsPerExecutor" -> "1",
"spark.cassandra.concurrent.reads" -> "512",
"spark.cassandra.output.batch.grouping.buffer.size" -> "1000",
"spark.cassandra.connection.keep_alive_ms" -> "600000000"
)
//set timestamp to ensure it is before read job starts
val timestamp: Long = System.currentTimeMillis / 1000
//Read from source Cassandra
val DFfromSourceCassandra = sqlContext
.read
.format("org.apache.spark.sql.cassandra")
.options(sourceCassandra)
.load
//Write to target Cassandra
DFfromSourceCassandra
.write
.format("org.apache.spark.sql.cassandra")
.options(targetCassandra)
.option("writetime", timestamp)
.mode(SaveMode.Append)
.save
Примечание
В предыдущем примере со Scala вы могли заметить, что в качестве timestamp устанавливается текущее время, после чего из исходной таблицы считываются все данные. Затем в качестве writetime устанавливается эта метка прошедшего времени. Это необходимо для того, чтобы при считывании исторических данных обновления с более поздней меткой времени, полученные от прокси-сервера двойной записи, не заменялись записями, полученными из исторических данных, которые загружаются в целевую конечную точку.
Важно!
Если по какой-либо причине требуется сохранить точные метки времени, следует применить подход с переносом исторических данных, при котором сохраняются метки времени, например этот пример. JAR-файл зависимостей в примере также содержит соединитель Spark, поэтому вам не нужно устанавливать сборку соединителя Spark, упомянутую в предыдущих предварительных требованиях, так как наличие обеих сборок в кластере Spark приведет к конфликтам.
Проверка исходного и целевого объектов
По завершении загрузки исторических данных ваши базы данных должны быть синхронизированы и готовы к прямому переносу. Однако перед окончательным переносом рекомендуем проверить исходный и целевой объекты, чтобы убедиться, что они совпадают.
Примечание
Если для сохранения writetime использовался упомянутый выше пример cassandra migrator, он включает возможность проверки миграции путем сравнения строк в исходном и целевом объектах с учетом определенных допусков.