Примечание.
Для доступа к этой странице требуется авторизация. Вы можете попробовать войти или изменить каталоги.
Для доступа к этой странице требуется авторизация. Вы можете попробовать изменить каталоги.
ПРИМЕНИМО К: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Совет
Data Factory в Microsoft Fabric — это следующее поколение Azure Data Factory с более простой архитектурой, встроенным ИИ и новыми функциями. Если вы не знакомы с интеграцией данных, начните с Fabric Data Factory. Существующие рабочие нагрузки ADF могут обновляться до Fabric для доступа к новым возможностям в области обработки и анализа данных, аналитики в режиме реального времени и отчетов.
Сопоставление потоков данных в конвейерах Azure Data Factory и Synapse предоставляет свободный от кода интерфейс для разработки и выполнения преобразований данных в масштабе. Если вы не знакомы с сопоставлением потоков данных, см. раздел Обзор потоков данных сопоставления. В этой статье описываются различные способы настройки и оптимизации потоков данных, чтобы они соответствовали вашим эталонам производительности.
Просмотрите следующее видео, чтобы просмотреть примеры времени преобразования данных с помощью потоков данных.
Отслеживание производительности потоков данных
После проверки логики преобразования в режиме отладки выполните поток данных от начала до конца в качестве действия в конвейере. Потоки данных обрабатываются в конвейере с помощью действия выполнения потока данных. Деятельность потока данных предлагает уникальные возможности для мониторинга по сравнению с другими действиями благодаря отображению подробного плана выполнения и профиля производительности логики преобразования. Чтобы просмотреть подробные сведения о мониторинге потока данных, выберите значок очков в результатах выполнения активности конвейера. Дополнительные сведения см. в статье Мониторинг потоков данных для сопоставления.

При мониторинге производительности потока данных существует четыре возможных узких места, на которые следует обратить внимание.
- время запуска кластера;
- чтение из источника;
- время преобразования;
- запись в приемник.
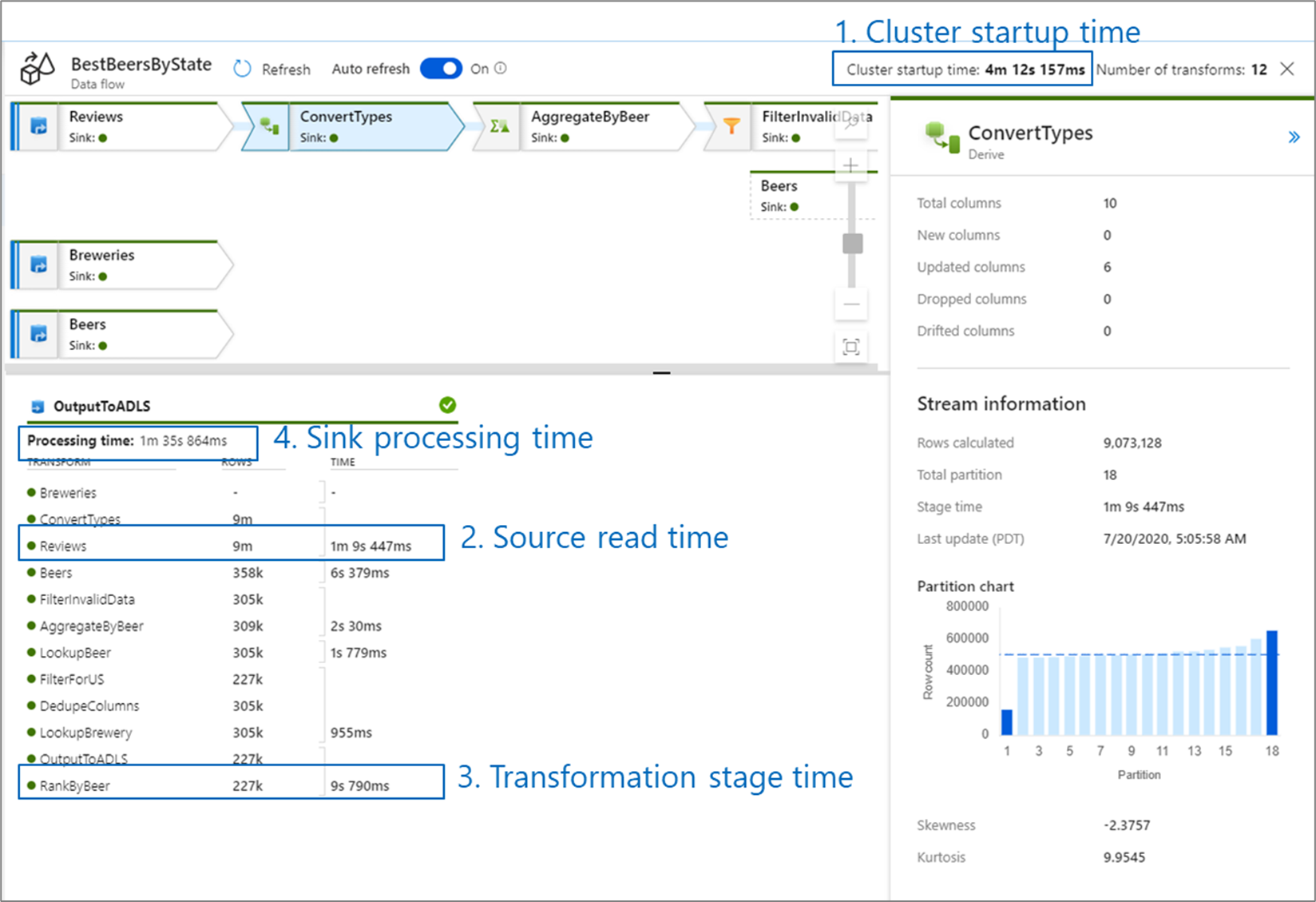
Время запуска кластера — это время, затрачиваемое на запуск кластера Apache Spark. Это значение указано в правом верхнем углу экрана мониторинга. Потоки данных работают по модели "точно в срок" (JIT), в которой каждое задание использует изолированный кластер. Это время запуска обычно занимает 3–5 минут. Для последовательных заданий время запуска может быть сокращено за счет установки значения времени жизни. Дополнительные сведения можно найти в разделе Время жизни в разделе производительности среды выполнения интеграции.
Потоки данных используют оптимизатор Spark, который переупорядочивает и выполняет бизнес-логику поэтапно, чтобы обеспечить максимально быстрое выполнение. Для каждого приемника, в который поток данных выполняет запись, в выходных данных мониторинга указывается длительность каждого этапа преобразования, а также время, затрачиваемое на запись данных в приемник. Самое большое время, вероятно, указывает на узкое место потока данных. Если этап преобразования, требующий больше всего времени, содержит источник, возможно, стоит дополнительно оптимизировать время чтения. Если преобразование занимает много времени, возможно, потребуется перераспределить или увеличить размер среды выполнения интеграции. Если время обработки приемника большое, может потребоваться увеличить масштаб базы данных или убедиться, что вы не выводите данные в один файл.
Выявив узкие места в потоке данных, используйте приведенные ниже стратегии оптимизации, чтобы повысить производительность.
Тестирование логики потока данных
При разработке и тестировании потоков данных из пользовательского интерфейса режим отладки позволяет интерактивно тестировать кластер Spark, что позволяет просматривать данные и выполнять потоки данных, не ожидая разогрева кластера. Дополнительные сведения см. в статье Режим отладки.
Вкладка оптимизации
Вкладка Оптимизация содержит параметры для настройки схемы секционирования кластера Spark. Эта вкладка доступна в каждом преобразовании потока данных. На ней указывается, нужно ли повторно секционировать данные после завершения преобразования. Настройка секционирования обеспечивает контроль над распределением данных между вычислительными узлами и оптимизацией размещения данных. Все это может иметь как положительное, так и отрицательное влияние на общую производительность потока данных.
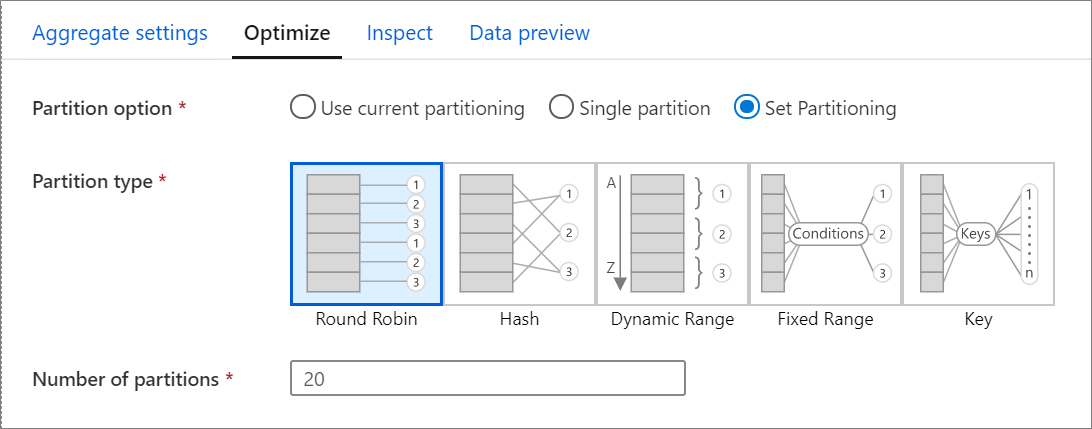
По умолчанию выбран параметр Использовать текущее секционирование, который указывает службе, что следует сохранить текущее секционирование выходных данных преобразования. Так как пересекционирование данных занимает некоторое время, в большинстве случаев рекомендуется использовать текущее секционирование. Сценарии, в которых может потребоваться повторно разделить данные, включают случаи после выполнения агрегаций и соединений, которые значительно искажают данные, или при использовании разбиения источника в базе данных SQL.
Чтобы изменить секционирование для любого преобразования, перейдите на вкладку Оптимизация и установите переключатель Задать секционирование. Вам предоставляется ряд вариантов секционирования. Оптимальный метод секционирования зависит от объемов данных, потенциальных ключей, значений NULL и кратности.
Внимание
В одной секции все распределенные данные объединяются в отдельную секцию. Это очень медленная операция, которая также значительно влияет на все нисходящие операции преобразования и записи. Этот вариант настоятельно не рекомендуется использовать без явной бизнес-причины.
Приведенные ниже параметры секционирования доступны в каждом преобразовании.
Циклический алгоритм
Алгоритм циклического распределения равномерно распределяет данные по разделам. Циклический перебор можно использовать, если у вас нет подходящих потенциальных ключей для реализации надежной и интеллектуальной стратегии секционирования. Вы можете задать количество физических разделов.
хэш
Служба создает хэш столбцов, чтобы обеспечить равномерное распределение по секциям, и при этом строки со сходными значениями попадают в одну секцию. Если вы выбрали параметр "Хэш", проверьте возможное неравномерное распределение данных в секциях. Вы можете задать количество физических разделов.
Динамический диапазон
Динамический диапазон использует динамические диапазоны Spark, основанные на предоставленных вами столбцах или выражениях. Вы можете задать количество физических разделов.
Фиксированный диапазон
Создайте выражение, которое обеспечивает фиксированный диапазон значений в пределах столбцов секционированных данных. Чтобы избежать перекоса разделов, важно хорошо понимать ваши данные перед использованием этого параметра. Значения, введенные в выражении, используются в функции секционирования. Вы можете задать количество физических разделов.
Ключ
Если вы хорошо понимаете кратность своих данных, хорошей стратегией может оказаться секционирование по ключу. При секционировании по ключу создаются секции для каждого уникального значения в столбце. Вы не можете задать число секций, так как оно зависит от количества уникальных значений в данных.
Совет
Ручная настройка схемы секционирования приведет к перемешиванию данных в случайном порядке, что может уменьшить преимущества оптимизатора Spark. Рекомендуется без необходимости не задавать секционирование вручную.
Уровень ведения журнала
Если вам не нужно, чтобы каждое выполнение конвейера данных записывало все подробные журналы телеметрии, при необходимости можно установить уровень ведения журнала до "Базовый" или "Нет". При выполнении потоков данных в режиме "Подробный" (по умолчанию) вы запрашиваете у службы ведение полного журнала активности на уровне каждого отдельного раздела во время преобразования данных. Это может быть ресурсоемкой операцией, поэтому включать режим подробного ведения журнала следует только при устранении неполадок. Такой подход может повысить общую производительность потоков данных и конвейеров. Режим "Базовый" регистрирует только длительность преобразования, в то время как "Нет" предоставляет только сводку по длительности.

Связанный контент
- Оптимизация источников
- Оптимизация узлов
- Оптимизация преобразований
- Использование потоков данных в конвейерах
См. другие статьи Data Flow, связанные с производительностью: