Примечание.
Для доступа к этой странице требуется авторизация. Вы можете попробовать войти или изменить каталоги.
Для доступа к этой странице требуется авторизация. Вы можете попробовать изменить каталоги.
ПРИМЕНИМО К: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Совет
Data Factory в Microsoft Fabric — это следующее поколение Azure Data Factory с более простой архитектурой, встроенным ИИ и новыми функциями. Если вы не знакомы с интеграцией данных, начните с Fabric Data Factory. Существующие рабочие нагрузки ADF могут обновляться до Fabric для доступа к новым возможностям в области обработки и анализа данных, аналитики в режиме реального времени и отчетов.
Смещение схемы происходит при частом изменении метаданных ваших источников. Поля, столбцы и типы могут быть добавлены, удалены или изменены "на лету". Без обработки смещения схемы поток данных становится уязвимым к изменениям в вышестоящих источниках данных. Типичные ETL шаблоны терпят неудачу при изменении входящих столбцов и полей, потому что они обычно привязаны к этим именам источников.
Чтобы защититься от смещения схемы, важно иметь возможности в инструменте для потоков данных, чтобы вы, как инженер данных, могли:
- определять источники с изменяемыми именами полей, типами данных, значениями и размерами;
- определять параметры преобразования, которые могут работать с шаблонами данных вместо жестко закодированных полей и значений;
- определять выражения, которые распознают шаблоны для сопоставления входящих полей вместо использования именованных полей.
Azure Data Factory изначально поддерживает гибкие схемы, которые изменяются от выполнения до выполнения, чтобы можно было создать универсальную логику преобразования данных без необходимости перекомпилировать потоки данных.
Необходимо принять архитектурное решение в потоке данных, чтобы учитывать изменение схемы на протяжении всего потока. При этом можно защититься от изменений схемы, поступающих из источников. Однако вы утратите раннюю привязку столбцов и типов во всем потоке данных. Azure Data Factory обрабатывает потоки смещения схемы как потоки с поздней привязкой, поэтому при построении преобразований имена смещенных столбцов не будут доступны в представлениях схемы на протяжении всего потока.
Это видео содержит общие сведения о некоторых сложных решениях, которые можно легко создавать в конвейерах Azure Data Factory или Synapse Analytics с помощью функции schema drift. В этом примере мы компилируем многоразовые шаблоны на основе гибких схем баз данных.
Смещение схемы в источнике
Столбцы, поступающие в поток данных из определения источника данных, называются "смещенными", если они отсутствуют в проекции источника данных. Проекцию источника можно просмотреть на вкладке "Проекция" в преобразовании источника. После выбора вами набора данных для источника служба автоматически возьмет схему из набора данных и создаст проекцию из этого определения схемы набора данных.
В преобразовании источника смещение схемы определяется как считывание столбцов, не определенных в схеме набора данных. Чтобы включить смещение схемы, установите флажок Разрешить смещение схемы в преобразовании источника.
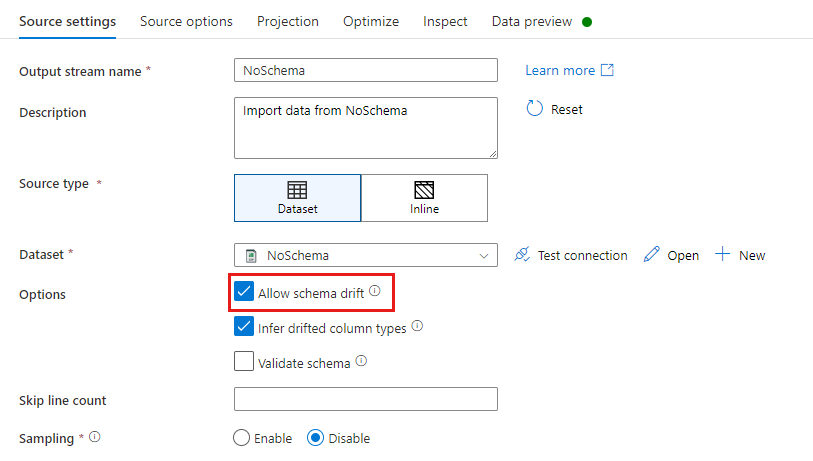
Если смещение схемы включено, все входящие поля считываются из источника в процессе выполнения и проходят по всему процессу к Sink. По умолчанию все вновь обнаруженные столбцы, называющиеся смещенными столбцами, поступают в виде строкового типа данных. Если нужно, чтобы поток данных автоматически определял типы данных для смещенных столбцов, установите флажок Выводить типы смещенных столбцов в параметрах источника.
Смещение схемы в приемнике
В преобразовании приемника дрейф схемы происходит, когда записываются дополнительные столбцы помимо тех, которые определены в схеме данных приемника. Чтобы включить смещение схемы, установите флажок Разрешить смещение схемы в преобразовании приемного узла.
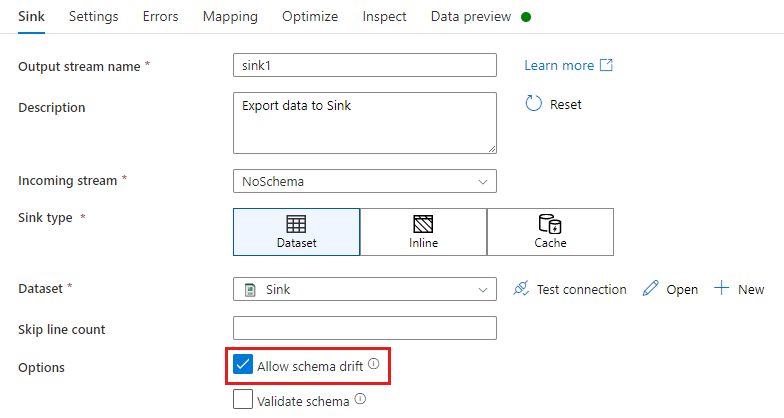
Если смещение схемы включено, убедитесь, что включен ползунок Автоматическое сопоставление на вкладке "Сопоставление". Когда этот ползунок включен, все входящие столбцы записываются в место назначения. Иначе для записи смещенных столбцов необходимо использовать сопоставление на основе правил.
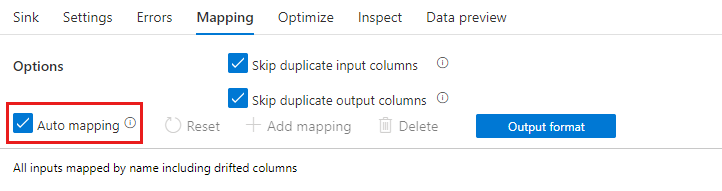
Преобразование смещенных столбцов
Когда в потоке данных есть смещенные столбцы, к ним можно получить доступ в преобразованиях с помощью следующих методов:
- С помощью выражений
byPositionиbyNameявно ссылайтесь на столбец по имени или номеру позиции. - Добавьте шаблон столбца в преобразование "Производный столбец" или "агрегатное преобразование" для соответствия любому сочетанию имени, потока, позиции, происхождения или типа.
- Добавьте сопоставление на основе правил в преобразовании "Выбор" или "Приемник" для сопоставления по шаблону смещенных столбцов и псевдонимов столбцов
Дополнительные сведения о реализации шаблонов столбцов см. в статье Шаблоны столбцов в потоке данных для сопоставления.
Быстрое действие "Сопоставить смещенные столбцы"
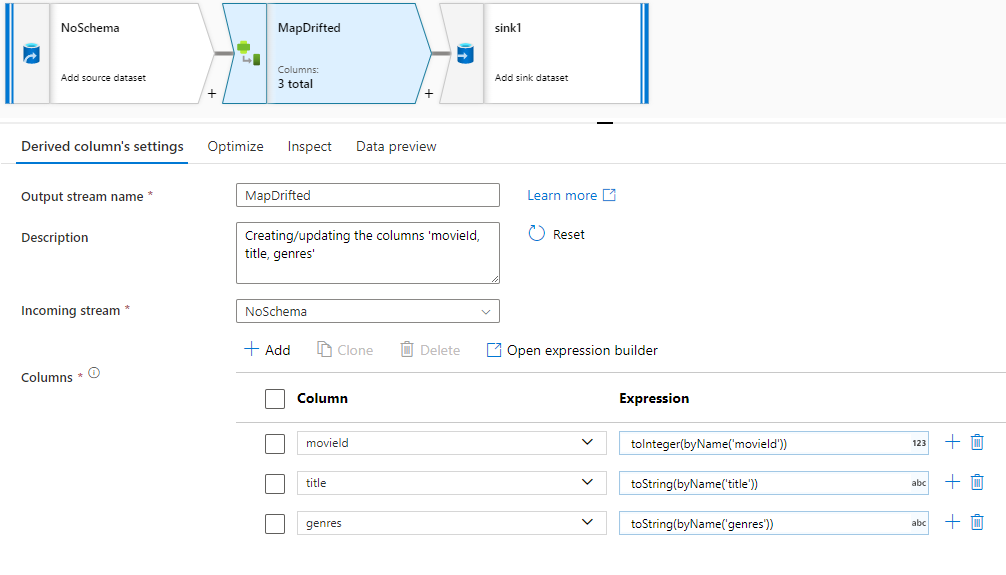
Чтобы явно ссылаться на смещенные столбцы, можно быстро создавать для них сопоставления с помощью быстрого действия "Предварительный просмотр данных". Включив режим отладки, перейдите на вкладку "Предварительный просмотр данных" и нажмите кнопку Обновить, чтобы получить предварительную версию данных. Если фабрика данных обнаруживает наличие смещенных столбцов, можно щелкнуть Сопоставить смещенные и создать производный столбец, который позволяет ссылаться на все смещенные столбцы в нижестоящих представлениях схемы.
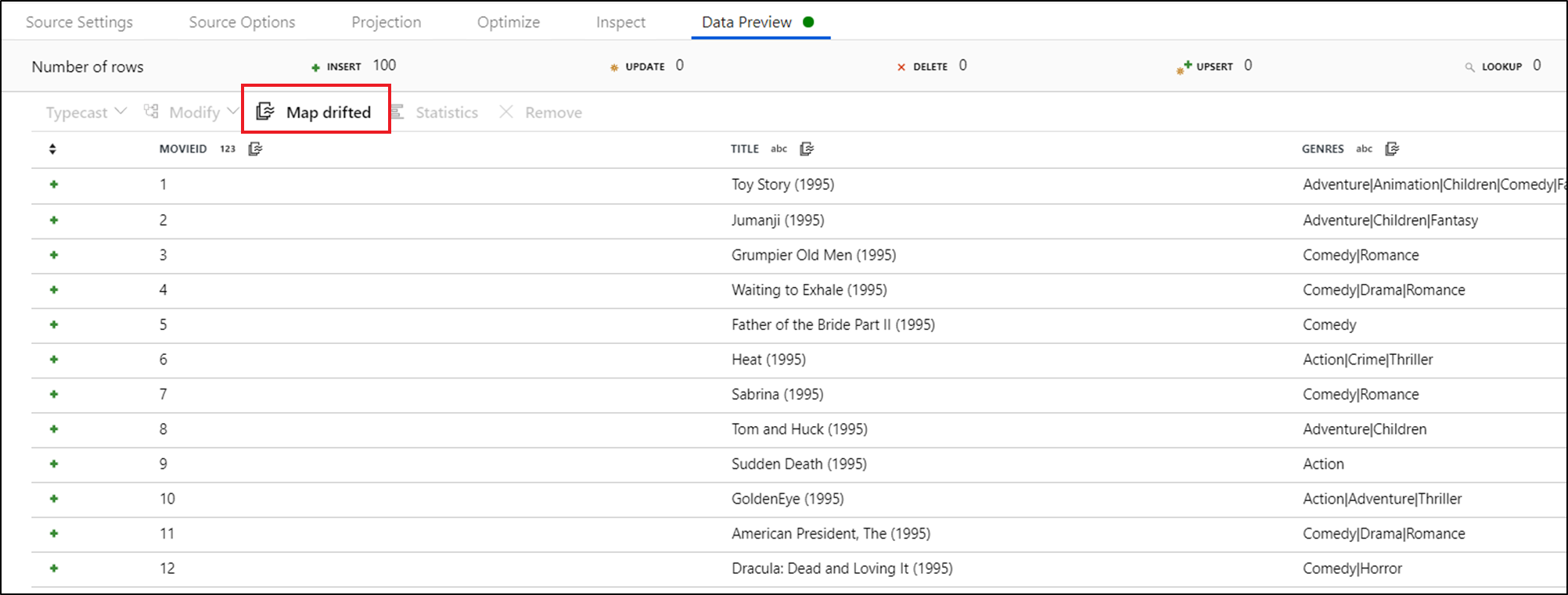
В сгенерированном преобразовании "Производный столбец" каждый смещенный столбец сопоставляется с его обнаруженным именем и типом данных. При приведенном выше предварительном просмотре данных столбец "movieId" определяется как целое число. После нажатия кнопки Map Drifted, "movieId" определяется в Derived Column как toInteger(byName('movieId')) и включается в представления схемы в последующих преобразованиях.
Связанный контент
В языке выражений Data Flow вы найдете дополнительные средства для шаблонов столбцов и смещения схемы, включая "byName" и "byPosition".