Примечание.
Для доступа к этой странице требуется авторизация. Вы можете попробовать войти или изменить каталоги.
Для доступа к этой странице требуется авторизация. Вы можете попробовать изменить каталоги.
ОБЛАСТЬ ПРИМЕНЕНИЯ: Фабрика данных Azure Azure Synapse Analytics
Фабрика данных Azure Azure Synapse Analytics
Совет
Попробуйте использовать фабрику данных в Microsoft Fabric, решение для аналитики с одним интерфейсом для предприятий. Microsoft Fabric охватывает все, от перемещения данных до обработки и анализа данных в режиме реального времени, бизнес-аналитики и отчетности. Узнайте, как бесплатно запустить новую пробную версию !
В этой статье описывается, как с помощью действия копирования в конвейере Фабрики данных Azure и Synapse Analytics копировать данные из Spark. Это продолжение статьи об обзоре действия копирования, в которой представлены общие сведения о действии копирования.
Это важно
Соединитель Spark версии 1.0 находится на этапе удаления. Рекомендуется обновить соединитель Spark с версии 1.0 до версии 2.0.
Поддерживаемые возможности
Соединитель Spark поддерживается для перечисленных ниже возможностей.
| Поддерживаемые возможности | ИК |
|---|---|
| Копировать действие (источник/-) | (1) (2) |
| Действие поиска | (1) (2) |
① Среда выполнения интеграции Azure ② Локальная среда выполнения интеграции
Список хранилищ данных, которые поддерживаются в качестве источников и приемников для копирования, приведен в таблице Поддерживаемые хранилища данных.
Служба предоставляет встроенный драйвер для обеспечения подключения, поэтому вам не нужно вручную устанавливать какой-либо драйвер с помощью этого соединителя.
Предварительные условия
Если хранилище данных размещено в локальной сети, виртуальной сети Azure или виртуальном частном облаке Amazon, для подключения к нему нужно настроить локальную среду выполнения интеграции.
Если же хранилище данных представляет собой управляемую облачную службу данных, можно использовать Azure Integration Runtime. Если доступ предоставляется только по IP-адресам, утвержденным в правилах брандмауэра, вы можете добавить IP-адреса Azure Integration Runtime в список разрешений.
Вы также можете использовать функцию среды выполнения интеграции в управляемой виртуальной сети в Фабрике данных Azure для доступа к локальной сети без установки и настройки локальной среды выполнения интеграции.
Дополнительные сведения о вариантах и механизмах обеспечения сетевой безопасности, поддерживаемых Фабрикой данных, см. в статье Стратегии получения доступа к данным.
Начало работы
Для выполнения действия копирования с конвейером можно использовать один из следующих средств или пакетов SDK:
- Средство копирования данных
- Портал Azure
- Пакет SDK для .NET
- Пакет SDK для Python
- Azure PowerShell
- REST API
- Шаблон Azure Resource Manager
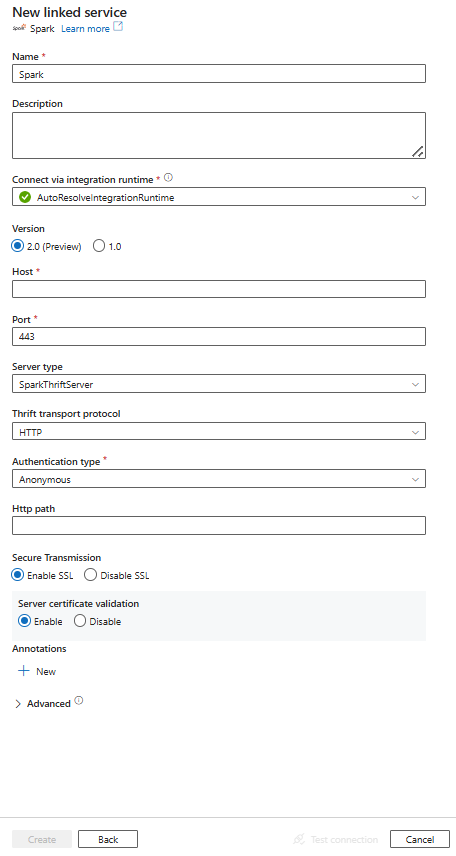
Создание связанной службы для Spark с помощью пользовательского интерфейса
Выполните следующие действия, чтобы создать связанную службу для Spark с использованием пользовательского интерфейса портала Azure.
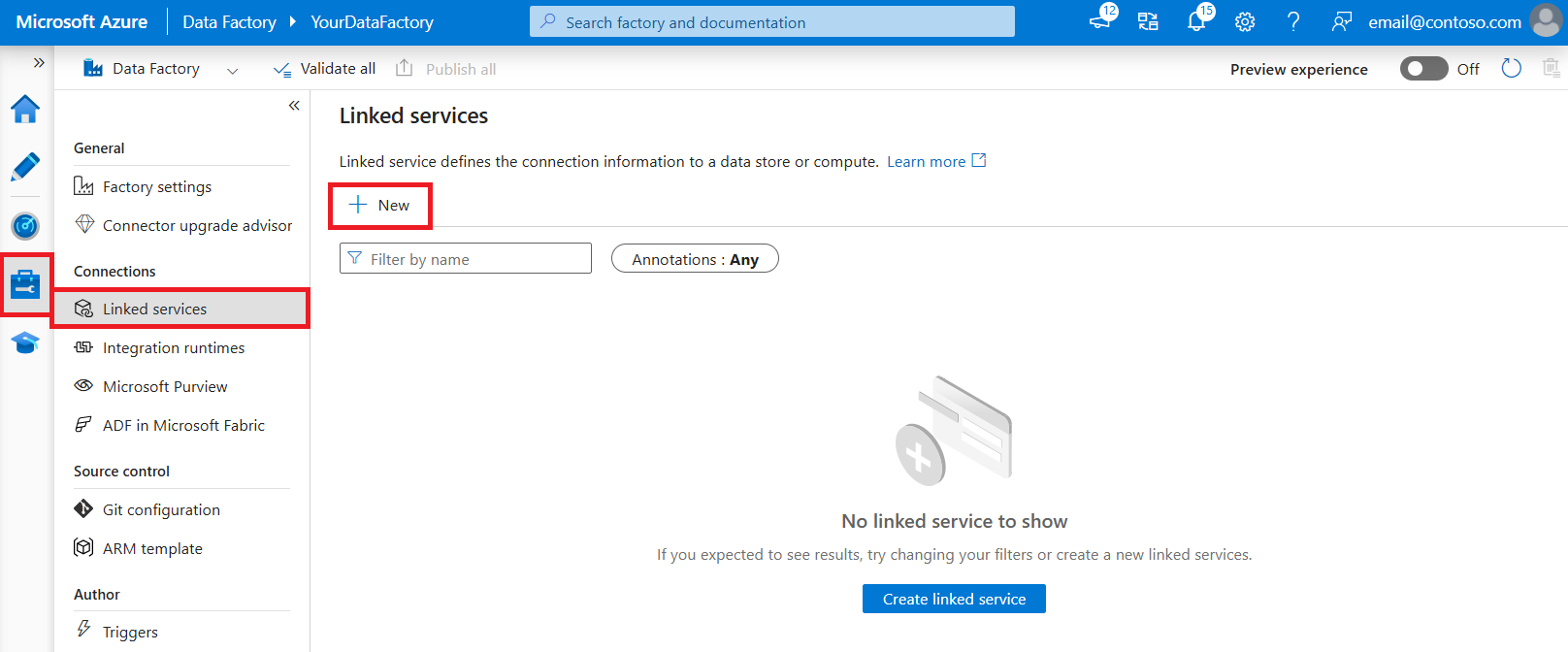
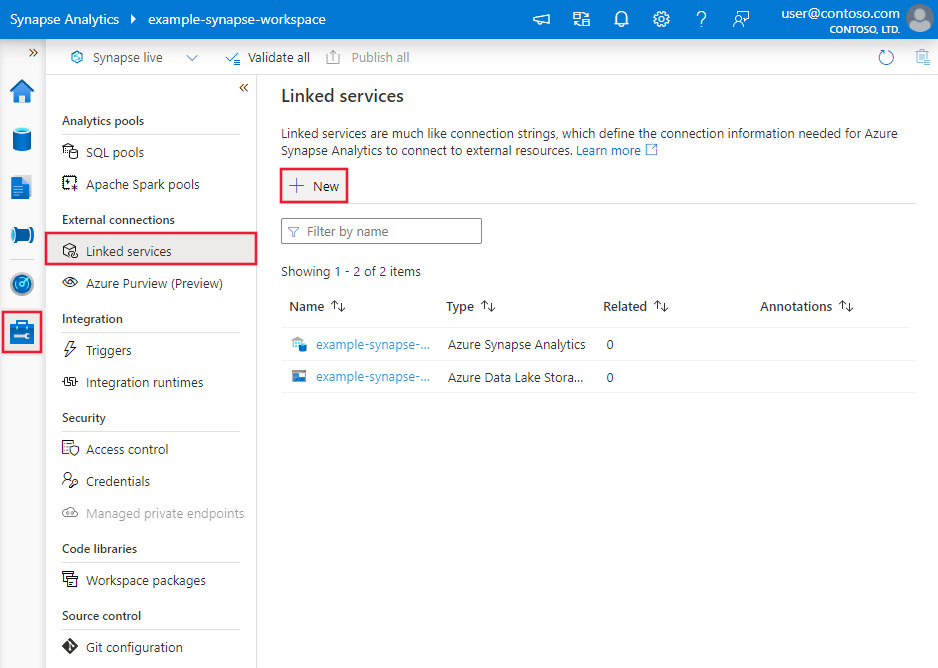
Перейдите на вкладку "Управление" в рабочей области Фабрики данных Azure или Synapse и выберите "Связанные службы", после чего нажмите "Создать":
Выполните поиск Spark и выберите соединитель Spark.

Настройте сведения о службе, проверьте подключение и создайте связанную службу.
Сведения о конфигурации соединителя
Следующие разделы содержат сведения о свойствах, которые используются для задания сущностей Data Factory, специфичных для соединителя Spark.
Свойства связанной службы
Соединитель Spark теперь поддерживает версию 2.0. Ознакомьтесь с этим разделом , чтобы обновить версию соединителя Spark с версии 1.0. Чтобы узнать подробности о свойстве, см. соответствующие разделы.
Версия 2.0
Для связанной службы Spark версии 2.0 поддерживаются следующие свойства:
| Свойство | Описание: | Обязательное поле |
|---|---|---|
| тип | Для свойства type необходимо задать значение Spark | Да |
| версия | Версия, которую вы указали. Значение равно 2.0. |
Да |
| ведущий | IP-адрес или имя узла сервера Spark | Да |
| порт | TCP-порт, используемый сервером Spark для прослушивания клиентских подключений. При подключении к Azure HDInsights укажите порт 443. | Да |
| тип сервера | Тип сервера Spark. Допустимое значение: SparkThriftServer |
Нет |
| thriftTransportProtocol | Транспортный протокол для использования в слое Thrift. Допустимое значение: HTTP |
Нет |
| тип аутентификации | Метод аутентификации, используемый для доступа к серверу Spark. Допустимые значения: Anonymous, UsernameAndPassword, WindowsAzureHDInsightService. |
Да |
| имя пользователя | Имя пользователя, которое позволяет получить доступ к серверу Spark. | Нет |
| пароль | Пароль, соответствующий пользователю. Пометьте это поле как SecureString, чтобы безопасно хранить его, или добавьте ссылку на секрет, хранящийся в Azure Key Vault. | Нет |
| httpPath (HTTP путь) | Частичный URL-адрес, соответствующий серверу Spark. Для типа проверки подлинности WindowsAzureHDInsightService используется /sparkhive2значение по умолчанию. |
Нет |
| включитьSSL | Указывает, шифруются ли подключения к серверу с помощью протокола TLS. Значение по умолчанию — true. | Нет |
| включитьПроверкуСертификатаСервера | Укажите, следует ли включить проверку SSL-сертификата сервера при подключении. Всегда используйте системное хранилище доверия. Значение по умолчанию — true. |
Нет |
| connectVia | Среда выполнения интеграции, используемая для подключения к хранилищу данных. Дополнительные сведения см. в разделе Предварительные условия. Если не указано другое, по умолчанию используется интегрированная среда выполнения Azure. | Нет |
Пример:
{
"name": "SparkLinkedService",
"properties": {
"type": "Spark",
"version": "2.0",
"typeProperties": {
"host": "<cluster>.azurehdinsight.net",
"port": "<port>",
"authenticationType": "WindowsAzureHDInsightService",
"username": "<username>",
"password": {
"type": "SecureString",
"value": "<password>"
}
}
}
}
Версия 1.0
Для связанной службы Spark версии 1.0 поддерживаются следующие свойства:
| Свойство | Описание: | Обязательное поле |
|---|---|---|
| тип | Для свойства type необходимо задать значение Spark | Да |
| ведущий | IP-адрес или имя узла сервера Spark | Да |
| порт | TCP-порт, используемый сервером Spark для прослушивания клиентских подключений. При подключении к Azure HDInsights укажите порт 443. | Да |
| тип сервера | Тип сервера Spark. Допустимые значения: SharkServer, SharkServer2, SparkThriftServer. |
Нет |
| thriftTransportProtocol | Транспортный протокол для использования в слое Thrift. Допустимые значения: Binary, SASL, HTTP |
Нет |
| тип аутентификации | Метод аутентификации, используемый для доступа к серверу Spark. Допустимые значения: Anonymous, Username, UsernameAndPassword, WindowsAzureHDInsightService. |
Да |
| имя пользователя | Имя пользователя, которое позволяет получить доступ к серверу Spark. | Нет |
| пароль | Пароль, соответствующий пользователю. Пометьте это поле как SecureString, чтобы безопасно хранить его, или добавьте ссылку на секрет, хранящийся в Azure Key Vault. | Нет |
| httpPath (HTTP путь) | Частичный URL-адрес, соответствующий серверу Spark. | Нет |
| включитьSSL | Указывает, шифруются ли подключения к серверу с помощью протокола TLS. По умолчанию используется значение false. | Нет |
| доверенный_путь_сертификата | Полный путь к PEM-файлу, содержащему сертификаты удостоверяющего центра (ЦС) для проверки сервера при подключении по протоколу TLS. Это свойство можно установить только при использовании TLS на самоустановленных серверах интеграции. Значением по умолчанию является файл cacerts.pem, который устанавливается вместе с IR. | Нет |
| useSystemTrustStore (использовать хранилище доверия системы) | Указывает, следует ли использовать сертификат ЦС из доверенного хранилища системы или из указанного PEM-файла. По умолчанию используется значение false. | Нет |
| разрешитьНесоответствиеИмениХостаCN | Указывает, следует ли требовать, чтобы имя TLS/SSL-сертификата, выданного ЦС, совпадало с именем узла сервера при подключении по протоколу TLS. По умолчанию используется значение false. | Нет |
| разрешить самоподписанный серверный сертификат | Указывает, следует ли разрешить использование самозаверяющих сертификатов с сервера. По умолчанию используется значение false. | Нет |
| connectVia | Среда выполнения интеграции, используемая для подключения к хранилищу данных. Дополнительные сведения см. в разделе Предварительные условия. Если не указано другое, по умолчанию используется интегрированная среда выполнения Azure. | Нет |
Пример:
{
"name": "SparkLinkedService",
"properties": {
"type": "Spark",
"typeProperties": {
"host": "<cluster>.azurehdinsight.net",
"port": "<port>",
"authenticationType": "WindowsAzureHDInsightService",
"username": "<username>",
"password": {
"type": "SecureString",
"value": "<password>"
}
}
}
}
Свойства набора данных
Полный список разделов и свойств, доступных для определения наборов данных, см. в статье о наборах данных. В этом разделе содержится список свойств, поддерживаемых набором данных Spark.
Чтобы скопировать данные с Spark, установите свойство type набора данных SparkObject. Поддерживаются следующие свойства:
| Свойство | Описание: | Обязательное поле |
|---|---|---|
| тип | Свойство type для набора данных должно иметь значение SparkObject | Да |
| схема | Имя схемы. | Нет (если свойство query указано в источнике активности) |
| стол | Имя таблицы. | Нет (если свойство query указано в источнике активности) |
| имя_таблицы | Имя таблицы со схемой. Это свойство поддерживается только для обеспечения обратной совместимости. Для новых рабочих нагрузок используйте schema и table. |
Нет (если свойство query указано в источнике активности) |
Пример
{
"name": "SparkDataset",
"properties": {
"type": "SparkObject",
"typeProperties": {},
"schema": [],
"linkedServiceName": {
"referenceName": "<Spark linked service name>",
"type": "LinkedServiceReference"
}
}
}
Свойства действия копирования
Для получения полного списка разделов и свойств, доступных для определения действий, см. статью Конвейеры. В этом разделе содержится список свойств, поддерживаемых источником Spark.
Spark в качестве источника
Чтобы скопировать данные из Spark, установите тип источника SparkSource в действии копирования. В разделе source действия копирования поддерживаются следующие свойства:
| Свойство | Описание: | Обязательное поле |
|---|---|---|
| тип | Свойство type источника действия копирования должно иметь значение SparkSource. | Да |
| запрос | Используйте пользовательский SQL-запрос для чтения данных. Например: "SELECT * FROM MyTable". |
Нет (если для набора данных задано свойство tableName) |
Пример:
"activities":[
{
"name": "CopyFromSpark",
"type": "Copy",
"inputs": [
{
"referenceName": "<Spark input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "SparkSource",
"query": "SELECT * FROM MyTable"
},
"sink": {
"type": "<sink type>"
}
}
}
]
Сопоставление типов данных для Spark
При копировании данных из и в Spark в рамках службы используются следующие промежуточные сопоставления типов данных. Чтобы узнать, как действие копирования сопоставляет исходную схему и типы данных с приемником, см. раздел Сопоставление схем и типов данных.
| Тип данных Spark | Тип данных промежуточной службы (для версии 2.0) | Тип данных промежуточной службы (для версии 1.0) |
|---|---|---|
| Тип Boolean | Логическое | Логическое |
| Тип байта | Sbyte | Int16 |
| ShortType | Int16 | Int16 |
| ЦелочисленныйТип | Int32 | Int32 |
| LongType | Int64 | Int64 |
| FloatType | Единственный | Единственный |
| DoubleType | Двойной | Двойной |
| Тип даты | ДатаВремя | ДатаВремя |
| Тип временной метки | DateTimeOffset (Смещение даты и времени) | ДатаВремя |
| Тип строки (StringType) | String | String |
| Тип бинарных данных | Байт[] | Байт[] |
| Десятичный тип | Десятичный | Десятичный Строка (точность > 28) |
| Тип массива | String | String |
| Тип структуры | String | String |
| Тип карты | String | String |
| ТипВременнойМеткиNTZ | ДатаВремя | ДатаВремя |
| ТипИнтервалаГодМесяц | String | Не поддерживается. |
| ТипИнтервалаВремениДня | String | Не поддерживается. |
Свойства операции поиска
Подробные сведения об этих свойствах см. в разделе Действие поиска.
Жизненный цикл и обновление соединителя Spark
В следующей таблице показаны этап выпуска и журналы изменений для разных версий соединителя Spark:
| Версия | Этап выпуска | Журнал изменений |
|---|---|---|
| Версия 1.0 | Removed | Неприменимо. |
| Версия 2.0 | GA версия доступна | • enableServerCertificateValidation поддерживается. • Значение enableSSL по умолчанию имеет значение true. • Для типа проверки подлинности WindowsAzureHDInsightService используется httpPathзначение /sparkhive2 по умолчанию.• DecimalType считывается как тип данных Decimal. • TimestampType считывается как тип данных DateTimeOffset. • YearMonthIntervalType, DayTimeIntervalType считываются как тип данных String. • trustedCertPath, useSystemTrustStoreallowHostNameCNMismatch и allowSelfSignedServerCert не поддерживаются. • SharkServer и SharkServer2 не поддерживаются serverType. • Двоичные и SASL не поддерживаются thriftTransportProtocl. • Тип проверки подлинности имени пользователя не поддерживается. |
Обновление соединителя Spark с версии 1.0 до версии 2.0
На странице "Изменить связанную службу " выберите версию 2.0 и настройте связанную службу, указав свойства связанной службы версии 2.0.
Сопоставление типов данных для связанной службы Spark версии 2.0 отличается от сопоставления типов данных для версии 1.0. Сведения о последнем сопоставлении типов данных см. в разделе "Сопоставление типов данных" для Spark.
Связанный контент
Для получения списка хранилищ данных, поддерживаемых в качестве источников и приемников операции копирования, см. Поддерживаемые хранилища данных.