Примечание.
Для доступа к этой странице требуется авторизация. Вы можете попробовать войти или изменить каталоги.
Для доступа к этой странице требуется авторизация. Вы можете попробовать изменить каталоги.
ПРИМЕНИМО К: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Совет
Data Factory в Microsoft Fabric — это следующее поколение Azure Data Factory с более простой архитектурой, встроенным ИИ и новыми функциями. Если вы не знакомы с интеграцией данных, начните с Fabric Data Factory. Существующие рабочие нагрузки ADF могут обновляться до Fabric для доступа к новым возможностям в области обработки и анализа данных, аналитики в режиме реального времени и отчетов.
С помощью действия Lookup можно получить набор данных из любого поддерживаемого источника данных фабрикой данных и конвейерами Synapse. Вы можете использовать его, чтобы динамически определять объекты для обработки в последующем действии, вместо жесткого программирования имени объекта. Примерами объектов могут быть файлы и таблицы.
Действие поиска считывает и возвращает содержимое файла конфигурации или таблицы. Оно также возвращает результат выполнения запроса или хранимой процедуры. Выходные данные могут содержать отдельное значение или массив атрибутов, которые можно использовать в последующих действиях копирования, преобразования или управления потоком, например, в действии ForEach.
Создание действия Lookup в пользовательском интерфейсе
Чтобы использовать действие Lookup в конвейере, выполните следующие действия.
Найдите элемент Lookup на панели действий конвейера и перетащите активность Lookup на холст конвейера.
Выберите новое действие Lookup на панели холста, если оно еще не выбрано, и перейдите на вкладку Параметры, чтобы изменить сведения о нем.
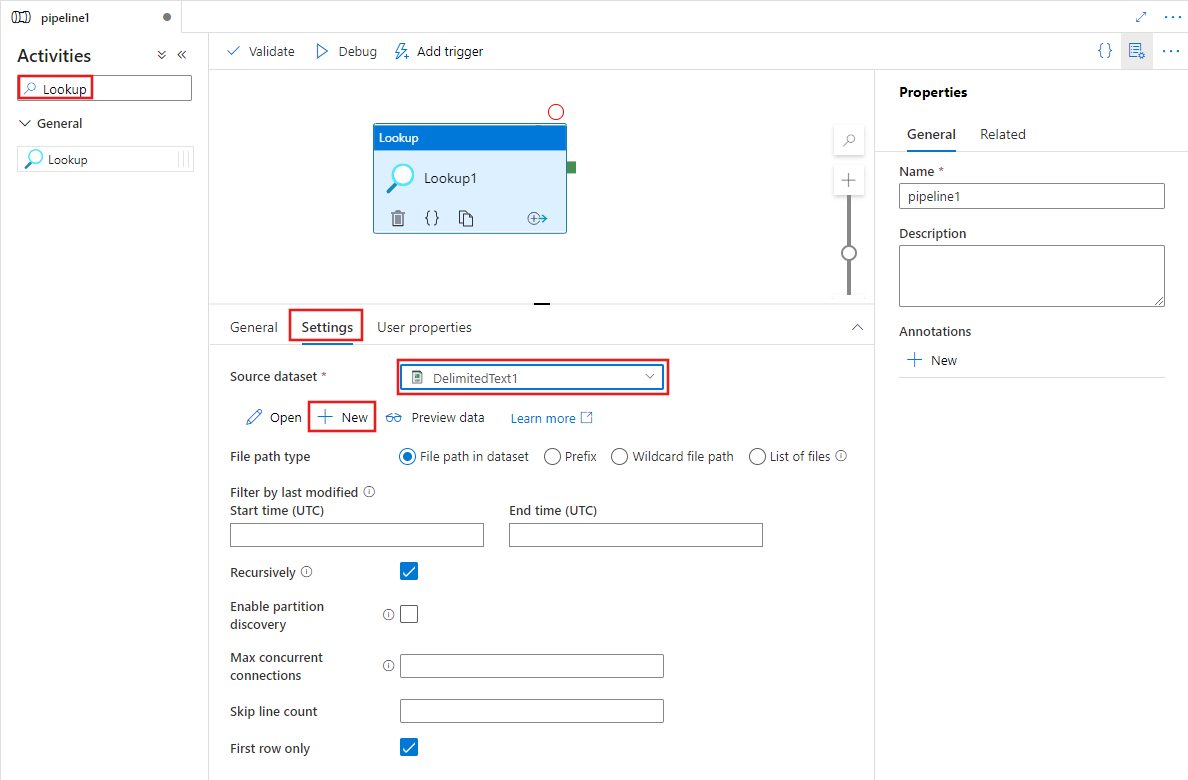
Выберите существующий исходный набор данных или нажмите кнопку Создать, чтобы создать новый.
Параметры идентификации строк, включаемых из исходного набора данных, зависят от типа набора данных. В приведенном выше примере показаны параметры конфигурации для текстового набора данных с разделителями. Ниже приведены примеры параметров конфигурации для набора данных таблицы Azure SQL и набора данных OData.
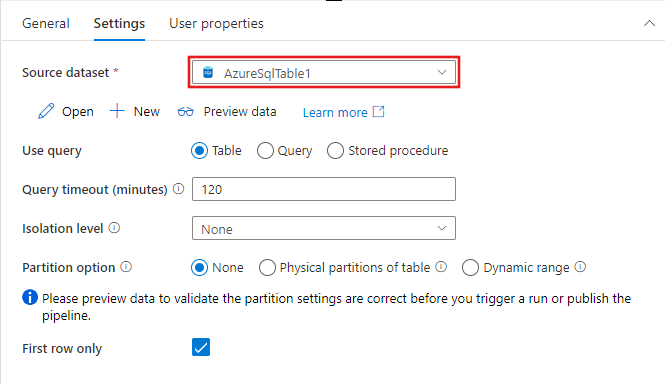
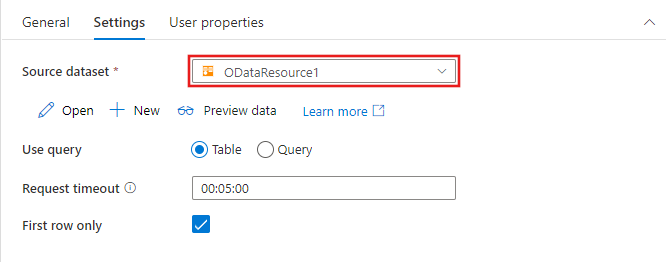
Поддерживаемые возможности
Обратите внимание на следующее:
- Действие Lookup может возвращать до 5000 строк. Если результирующий набор содержит больше записей, будут возвращены только первые 5000 строк.
- Размер выходных данных действия Lookup может составлять до 4 МБ. Если этот размер превысит ограничение, действие завершится ошибкой.
- Максимальная продолжительность операции поиска до тайм-аута составляет 24 часа.
Примечание.
Если вы используете для поиска данных запрос или хранимую процедуру, возвращайте один и только один набор результатов. В противном случае действие Lookup завершится ошибкой.
Для действия поиска поддерживаются следующие источники данных.
Примечание.
Пометка предварительная версия возле соединителя означает, что его можно опробовать и оставить отзыв. Если вы хотите использовать предварительные соединители в своем решении, обратитесь в поддержку Azure.
Синтаксис
{
"name":"LookupActivity",
"type":"Lookup",
"typeProperties":{
"source":{
"type":"<source type>"
},
"dataset":{
"referenceName":"<source dataset name>",
"type":"DatasetReference"
},
"firstRowOnly":<true or false>
}
}
Свойства типа
| Имя | Описание | Тип | Обязательное? |
|---|---|---|---|
| набор данных | Предоставляет ссылку на набор данных для поиска. Дополнительные сведения можно найти в разделе Свойства набора данных в каждой соответствующей статье о соединителе. | Пара "ключ — значение" | Да |
| Источник | Содержит свойства источника конкретного набора данных, аналогичные источнику действия копирования. Подробности можно найти в разделе Свойства действия копирования в статье о каждом соответствующем соединителе. | Пара "ключ — значение" | Да |
| firstRowOnly | Указывает, следует ли возвращать только первую или все строки. | Логический | № Значение по умолчанию — true. |
Примечание.
- Исходные столбцы с типом ByteArray не поддерживаются.
- Структура не поддерживается в определениях набора данных. Для текстовых файлов используйте строку заголовка, чтобы указать имя столбца.
- Если ваш источник поиска — файл JSON, параметр
jsonPathDefinitionдля изменения объекта JSON не поддерживается. Будут извлечены целые объекты.
Используйте результат активности Lookup
Результат поиска возвращается в раздел output результатов выполнения действия.
Когда для
firstRowOnlyзадано значениеtrue(по умолчанию), формат выходного значения выглядит, как показано в следующем коде. Результат поиска находится под фиксированным ключомfirstRow. Чтобы использовать этот результат в последующем действии, примените шаблон@{activity('LookupActivity').output.firstRow.table}.{ "firstRow": { "Id": "1", "schema":"dbo", "table":"Table1" } }Когда для
firstRowOnlyзадано значениеfalse, формат выходного значения выглядит, как показано в следующем коде. В полеcountуказано количество возвращенных записей. Подробные значения отображаются под фиксированным массивомvalue. В этом случае за действием поиска следует действие Foreach. Укажите массивvalueв поле действия ForEachitemsс помощью шаблона@activity('MyLookupActivity').output.value. Для получения доступа к элементам массиваvalueиспользуйте следующий синтаксис:@{activity('lookupActivity').output.value[zero based index].propertyname}. Например,@{activity('lookupActivity').output.value[0].schema}.{ "count": "2", "value": [ { "Id": "1", "schema":"dbo", "table":"Table1" }, { "Id": "2", "schema":"dbo", "table":"Table2" } ] }
Пример
Конвейер в нашем примере содержит два действия: Lookup и Copy. Действие копирования копирует данные из таблицы SQL в экземпляре базы данных Azure SQL в Blob-хранилище Azure. Имя таблицы SQL хранится в файле JSON в хранилище BLOB-объектов. Операция поиска определяет имя таблицы во время выполнения. Такой подход позволяет динамически изменять файл JSON. При этом нет необходимости в повторном развертывании конвейеров или наборов данных.
В этом примере демонстрируется поиск только для первой строки. Примеры выполнения поиска всех строк и связывания результатов с действием ForEach см. в статье Копирование нескольких таблиц в пакетном режиме.
Конвейер
- Действие Lookup настроено для использования LookupDataset, которое ссылается на расположение в хранилище объектов Azure Blob. Действие поиска считывает имя таблицы SQL из файла JSON в этом расположении.
- Действие Copy использует выходные данные действия Lookup, то есть имя таблицы SQL. Свойство tableName в наборе данных SourceDataset настроено для использования выходных данных действия поиска. Операция копирования переносит данные из таблицы SQL в хранилище блоб-объектов Azure. Расположение задается свойством SinkDataset.
{
"name": "LookupPipelineDemo",
"properties": {
"activities": [
{
"name": "LookupActivity",
"type": "Lookup",
"dependsOn": [],
"policy": {
"timeout": "7.00:00:00",
"retry": 0,
"retryIntervalInSeconds": 30,
"secureOutput": false,
"secureInput": false
},
"userProperties": [],
"typeProperties": {
"source": {
"type": "JsonSource",
"storeSettings": {
"type": "AzureBlobStorageReadSettings",
"recursive": true
},
"formatSettings": {
"type": "JsonReadSettings"
}
},
"dataset": {
"referenceName": "LookupDataset",
"type": "DatasetReference"
},
"firstRowOnly": true
}
},
{
"name": "CopyActivity",
"type": "Copy",
"dependsOn": [
{
"activity": "LookupActivity",
"dependencyConditions": [
"Succeeded"
]
}
],
"policy": {
"timeout": "7.00:00:00",
"retry": 0,
"retryIntervalInSeconds": 30,
"secureOutput": false,
"secureInput": false
},
"userProperties": [],
"typeProperties": {
"source": {
"type": "AzureSqlSource",
"sqlReaderQuery": {
"value": "select * from [@{activity('LookupActivity').output.firstRow.schema}].[@{activity('LookupActivity').output.firstRow.table}]",
"type": "Expression"
},
"queryTimeout": "02:00:00",
"partitionOption": "None"
},
"sink": {
"type": "DelimitedTextSink",
"storeSettings": {
"type": "AzureBlobStorageWriteSettings"
},
"formatSettings": {
"type": "DelimitedTextWriteSettings",
"quoteAllText": true,
"fileExtension": ".txt"
}
},
"enableStaging": false,
"translator": {
"type": "TabularTranslator",
"typeConversion": true,
"typeConversionSettings": {
"allowDataTruncation": true,
"treatBooleanAsNumber": false
}
}
},
"inputs": [
{
"referenceName": "SourceDataset",
"type": "DatasetReference",
"parameters": {
"schemaName": {
"value": "@activity('LookupActivity').output.firstRow.schema",
"type": "Expression"
},
"tableName": {
"value": "@activity('LookupActivity').output.firstRow.table",
"type": "Expression"
}
}
}
],
"outputs": [
{
"referenceName": "SinkDataset",
"type": "DatasetReference",
"parameters": {
"schema": {
"value": "@activity('LookupActivity').output.firstRow.schema",
"type": "Expression"
},
"table": {
"value": "@activity('LookupActivity').output.firstRow.table",
"type": "Expression"
}
}
}
]
}
],
"annotations": [],
"lastPublishTime": "2020-08-17T10:48:25Z"
}
}
Набор данных поиска
Набор данных lookup — это файл sourcetable.json в папке лукап на Azure Storage, указанной типом AzureBlobStorageLinkedService.
{
"name": "LookupDataset",
"properties": {
"linkedServiceName": {
"referenceName": "AzureBlobStorageLinkedService",
"type": "LinkedServiceReference"
},
"annotations": [],
"type": "Json",
"typeProperties": {
"location": {
"type": "AzureBlobStorageLocation",
"fileName": "sourcetable.json",
"container": "lookup"
}
}
}
}
Исходный набор данных для действия копирования
Исходный набор данных использует выходные данные операции поиска, которые являются именем таблицы в SQL. Действие копирования копирует данные из этой таблицы SQL в место в хранилище объектов Blob Azure. Расположение задается набором данных синк.
{
"name": "SourceDataset",
"properties": {
"linkedServiceName": {
"referenceName": "AzureSqlDatabase",
"type": "LinkedServiceReference"
},
"parameters": {
"schemaName": {
"type": "string"
},
"tableName": {
"type": "string"
}
},
"annotations": [],
"type": "AzureSqlTable",
"schema": [],
"typeProperties": {
"schema": {
"value": "@dataset().schemaName",
"type": "Expression"
},
"table": {
"value": "@dataset().tableName",
"type": "Expression"
}
}
}
}
Набор данных приемника для действия копирования
Действие копирования копирует данные из таблицы SQL в файл filebylookup.csv, находящийся в папке csv в Azure Storage. Файл задается свойством AzureBlobStorageLinkedService.
{
"name": "SinkDataset",
"properties": {
"linkedServiceName": {
"referenceName": "AzureBlobStorageLinkedService",
"type": "LinkedServiceReference"
},
"parameters": {
"schema": {
"type": "string"
},
"table": {
"type": "string"
}
},
"annotations": [],
"type": "DelimitedText",
"typeProperties": {
"location": {
"type": "AzureBlobStorageLocation",
"fileName": {
"value": "@{dataset().schema}_@{dataset().table}.csv",
"type": "Expression"
},
"container": "csv"
},
"columnDelimiter": ",",
"escapeChar": "\\",
"quoteChar": "\""
},
"schema": []
}
}
sourcetable.JSON
Вы можете использовать в файле sourcetable.json следующие два типа форматов.
Набор объектов
{
"Id":"1",
"schema":"dbo",
"table":"Table1"
}
{
"Id":"2",
"schema":"dbo",
"table":"Table2"
}
Массив объектов
[
{
"Id": "1",
"schema":"dbo",
"table":"Table1"
},
{
"Id": "2",
"schema":"dbo",
"table":"Table2"
}
]
Ограничения и методы обхода
Ниже описаны некоторые ограничения для действия Lookup и рекомендуемые обходные решения.
| Ограничение | Обходное решение |
|---|---|
| Количество строк для действия Lookup не может превышать 5000, а размер — 4 МБ. | Разработайте двухуровневый конвейер, где внешний конвейер выполняет итерацию по внутреннему конвейеру, получаемые данные которого не превышают максимальное количество строк и размер. |
Связанный контент
См. другие действия потока управления, поддерживаемые конвейерами Azure Data Factory и Synapse: