Примечание.
Для доступа к этой странице требуется авторизация. Вы можете попробовать войти или изменить каталоги.
Для доступа к этой странице требуется авторизация. Вы можете попробовать изменить каталоги.
ОБЛАСТЬ ПРИМЕНЕНИЯ: Фабрика данных Azure Azure Synapse Analytics
Фабрика данных Azure Azure Synapse Analytics
Совет
Попробуйте использовать фабрику данных в Microsoft Fabric, решение для аналитики с одним интерфейсом для предприятий. Microsoft Fabric охватывает все, от перемещения данных до обработки и анализа данных в режиме реального времени, бизнес-аналитики и отчетности. Узнайте, как бесплатно запустить новую пробную версию !
Операция блокнота Azure Databricks в конвейере запускает блокнот Databricks в рабочей области Azure Databricks. Данная статья основана на материалах статьи о действиях преобразования данных , в которой приведен общий обзор преобразования данных и список поддерживаемых действий преобразования. Azure Databricks — это управляемая платформа для запуска Apache Spark.
Вы можете создать записную книжку Databricks в шаблоне ARM с помощью JSON или напрямую в пользовательском интерфейсе Фабрики данных Azure. Пошаговое руководство по созданию действия Notebook Databricks с помощью пользовательского интерфейса см. в руководстве по запуску записной книжки Databricks с помощью действия Notebook Databricks в Фабрике данных Azure.
Добавьте действие Notebook для Azure Databricks в конвейер с помощью пользовательского интерфейса
Чтобы использовать активность Notebook для Azure Databricks в конвейере, выполните следующие шаги.
Выполните поиск Notebook в панели "Действия" конвейера и перетащите действие Notebook на холст конвейера.
Выберите новое действие Notebook на холсте, если оно еще не выбрано.
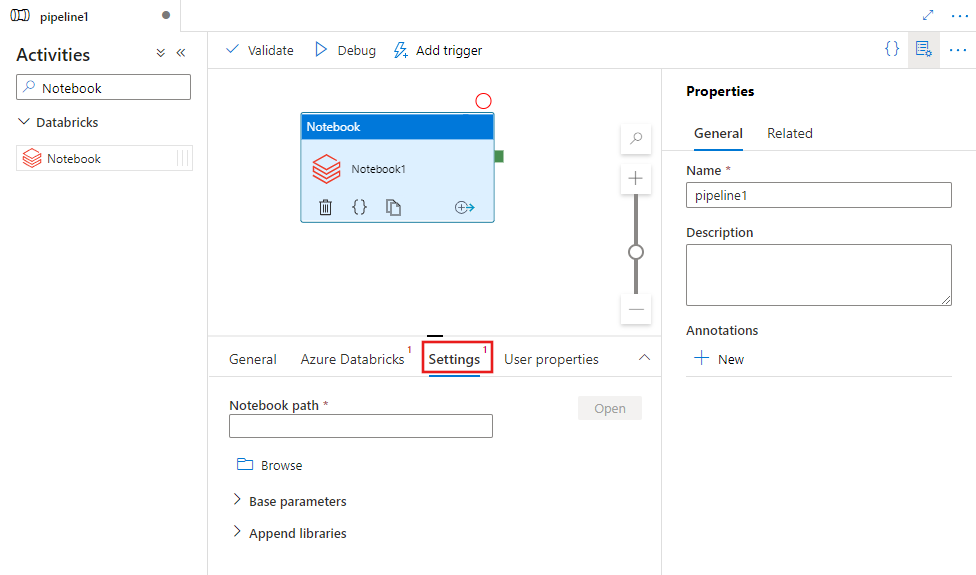
Перейдите на вкладку Azure Databricks, чтобы выбрать или создать новую связанную службу Azure Databricks, которая будет выполнять действие Notebook.
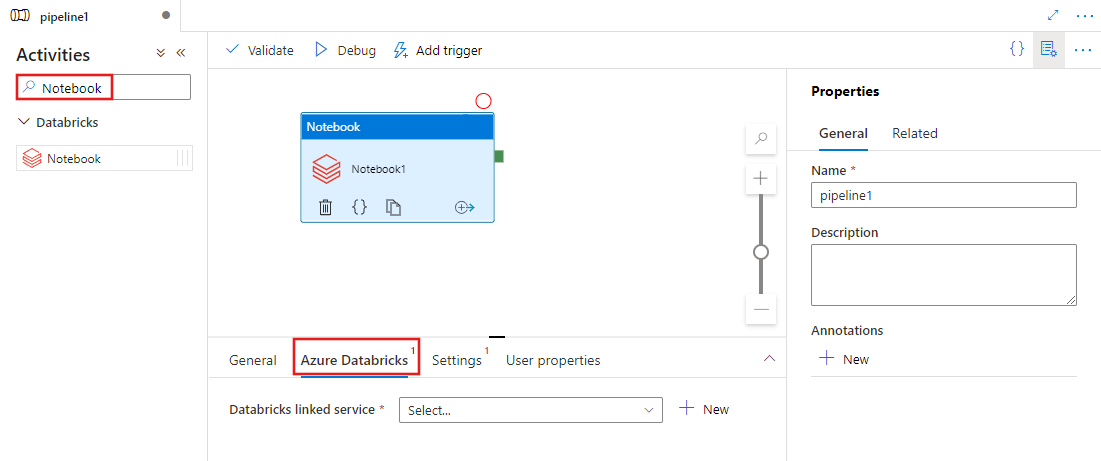
Выберите вкладку "Параметры" и укажите путь к записной книжке, который необходимо выполнить в Azure Databricks, необязательные базовые параметры, передаваемые в записную книжку, и любые другие библиотеки, которые должны быть установлены в кластере для выполнения задания.
Определение активности Databricks Notebook
Вот пример определения JSON для активности записной книжки Databricks:
{
"activity": {
"name": "MyActivity",
"description": "MyActivity description",
"type": "DatabricksNotebook",
"linkedServiceName": {
"referenceName": "MyDatabricksLinkedservice",
"type": "LinkedServiceReference"
},
"typeProperties": {
"notebookPath": "/Users/user@example.com/ScalaExampleNotebook",
"baseParameters": {
"inputpath": "input/folder1/",
"outputpath": "output/"
},
"libraries": [
{
"jar": "dbfs:/docs/library.jar"
}
]
}
}
}
Свойства действия Databricks Notebook
В следующей таблице приведено описание свойств, используемых в определении JSON.
| Свойство | Описание: | Обязательное поле |
|---|---|---|
| имя | Имя действия в конвейере выполнения. | Да |
| описание | Описание того, что делает активность. | Нет |
| тип | Тип активности для Databricks Notebook — это DatabricksNotebook. | Да |
| linkedServiceName | Имя связанного сервиса Databricks, на котором запускается записная книжка Databricks. Чтобы узнать больше об этой связанной службе, см. статью Связанные службы вычислений. | Да |
| путь_к_блокноту | Абсолютный путь блокнота, который будет запущен в рабочей области Databricks. Этот путь должен начинаться с косой черты. | Да |
| основные параметры | Массив пар "ключ-значение". Для каждого выполнения действия можно использовать базовые параметры. Если записная книжка принимает параметр, который не указан, будет использоваться значение по умолчанию из записной книжки. Дополнительные сведения о параметрах Databricks Notebook см. здесь. | Нет |
| библиотеки | Список библиотек, которые должны быть установлены на кластере, на котором будет выполнено задание. Это может быть массив из <строк и объектов>. | Нет |
Поддерживаемые библиотеки для операций Databricks
В приведенном выше определении действия Databricks необходимо указать следующие типы библиотек: jar, egg, whl, maven, pypi, cran.
{
"libraries": [
{
"jar": "dbfs:/mnt/libraries/library.jar"
},
{
"egg": "dbfs:/mnt/libraries/library.egg"
},
{
"whl": "dbfs:/mnt/libraries/mlflow-0.0.1.dev0-py2-none-any.whl"
},
{
"whl": "dbfs:/mnt/libraries/wheel-libraries.wheelhouse.zip"
},
{
"maven": {
"coordinates": "org.jsoup:jsoup:1.7.2",
"exclusions": [ "slf4j:slf4j" ]
}
},
{
"pypi": {
"package": "simplejson",
"repo": "http://my-pypi-mirror.com"
}
},
{
"cran": {
"package": "ada",
"repo": "https://cran.us.r-project.org"
}
}
]
}
Дополнительные сведения см. в документации Databricks по типам библиотек.
Передача параметров между записными книжками и конвейерами
Вы можете передавать параметры в записные книжки с помощью свойства baseParameters в действии Databricks.
Иногда может потребоваться передать определенные значения из ноутбука обратно в службу, которые могут использоваться для управления потоком выполнения (условные проверки) в службе или потребляться последующими действиями (ограничение размера — 2 МБ).
В записной книжке можно вызвать dbutils.notebook.exit("returnValue"), и соответствующий "returnValue" будет возвращен в систему.
Выходные данные в службе можно использовать с помощью выражения, такого как
@{activity('databricks notebook activity name').output.runOutput}.Внимание
Если вы передаете объект JSON, можно получить значения, добавив имена свойств. Пример:
@{activity('databricks notebook activity name').output.runOutput.PropertyName}
Отправка библиотеки в Databricks
Вы можете использовать пользовательский интерфейс рабочей области:
Использование пользовательского интерфейса рабочей области Databricks
Чтобы получить путь к dbfs библиотеки, добавленной с помощью пользовательского интерфейса, можно использовать интерфейс командной строки Databricks.
Обычно библиотеки Jar, добавленные с помощью пользовательского интерфейса, хранятся в каталоге dbfs:/FileStore/jars. Вы можете перечислить все через интерфейс командной строки (CLI): databricks fs ls dbfs:/FileStore/job-jars.
Или можно использовать интерфейс командной строки Databricks:
Затем выполните Копирование библиотеки с помощью интерфейса командной строки Databricks
Используйте интерфейс командной строки Databricks (действия по установке)
Например, чтобы скопировать JAR-файл в dbfs:
dbfs cp SparkPi-assembly-0.1.jar dbfs:/docs/sparkpi.jar