Примечание.
Для доступа к этой странице требуется авторизация. Вы можете попробовать войти или изменить каталоги.
Для доступа к этой странице требуется авторизация. Вы можете попробовать изменить каталоги.
ОБЛАСТЬ ПРИМЕНЕНИЯ: Фабрика данных Azure Azure Synapse Analytics
Фабрика данных Azure Azure Synapse Analytics
Совет
Попробуйте использовать фабрику данных в Microsoft Fabric, решение для аналитики с одним интерфейсом для предприятий. Microsoft Fabric охватывает все, от перемещения данных до обработки и анализа данных в режиме реального времени, бизнес-аналитики и отчетности. Узнайте, как бесплатно запустить новую пробную версию !
Конвейер в рабочей области Azure Data Factory или Synapse Analytics обрабатывает данные в связанных службах хранилища с помощью связанных вычислительных служб. В нем содержится последовательность действий, каждое из которых выполняет определенную операцию обработки. В этой статье описывается действие U-SQL в Data Lake Analytics, которое запускает сценарий U-SQL в связанной службе вычислений Azure Data Lake Analytics.
Перед созданием конвейера с активностью U-SQL в Azure Data Lake Analytics следует создать учетную запись Azure Data Lake Analytics. Дополнительные сведения об Azure Data Lake Analytics см. в разделе Начало работы с Azure Data Lake Analytics.
Добавление действия U-SQL для Azure Data Lake Analytics в конвейер с помощью пользовательского интерфейса
Чтобы использовать действие U-SQL для Azure Data Lake Analytics в конвейере, выполните следующие шаги:
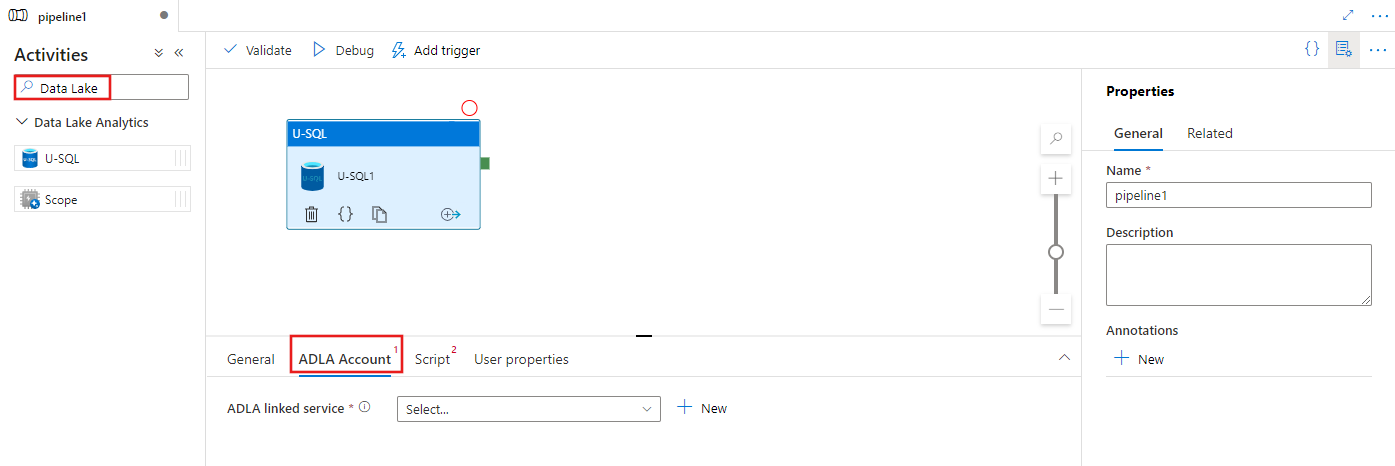
Выполните поиск Data Lake в области "Действия" конвейера и перетащите действие U-SQL на холст конвейера.
Выберите новое действие U-SQL на холсте, если оно еще не выбрано.
Перейдите на вкладку Учетная запись ADLA, чтобы выбрать существующую или создать новую связанную службу Azure Data Lake Analytics, которая будет использоваться для выполнения действия U-SQL.
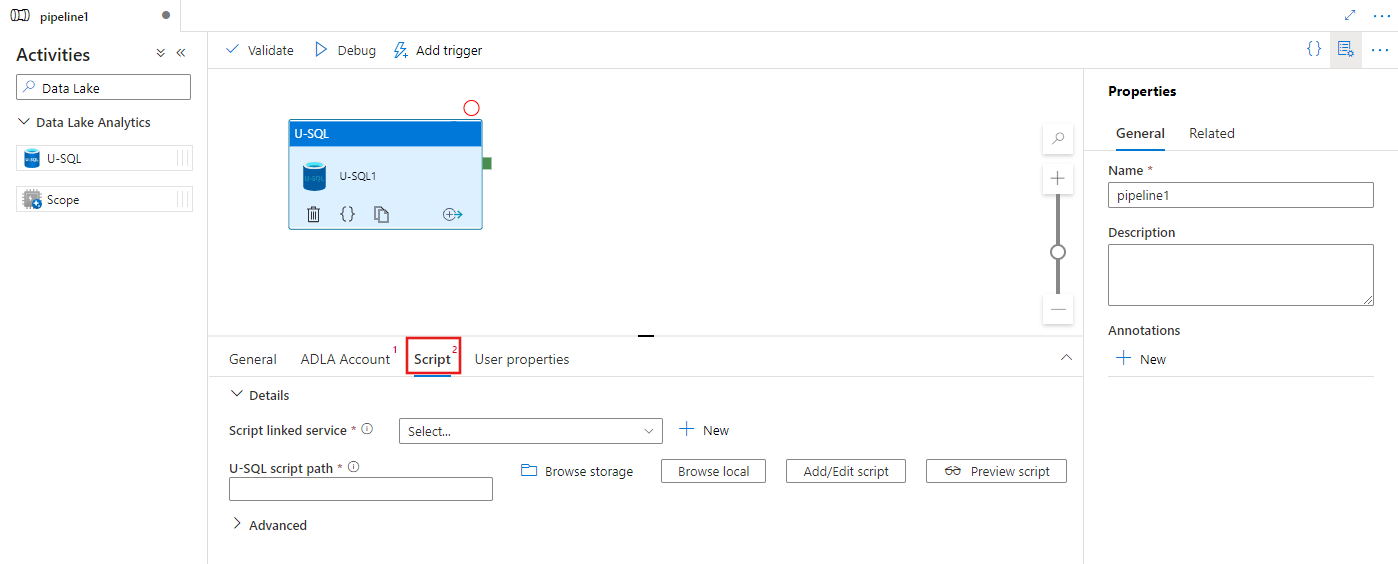
Перейдите на вкладку Скрипт, чтобы выбрать или создать связанную службу хранилища, и путь в месте хранения, в котором будет размещен скрипт.
Связанная служба Azure Data Lake Analytics
Вы создаете связанную службу Azure Data Lake Analytics для подключения службы вычислений Azure Data Lake Analytics к рабочей области Azure Data Factory или Synapse Analytics. Действие U-SQL для Data Lake Analytics в рамках конвейера ссылается на эту связанную службу.
В следующей таблице приведены описания универсальных свойств из определения JSON.
| Свойство | Описание: | Обязательное поле |
|---|---|---|
| тип | Свойству type необходимо присвоить значение AzureDataLakeAnalytics. | Да |
| accountName | Имя учетной записи аналитики озера данных Azure. | Да |
| dataLakeAnalyticsUri | URI Azure Data Lake Analytics. | Нет |
| subscriptionId | Идентификатор подписки Azure | Нет |
| resourceGroupName | Имя группы ресурсов Azure | Нет |
Аутентификация субъекта-службы
Для связанной службы Azure Data Lake Analytics необходимо выполнить проверку подлинности субъекта-службы, чтобы подключиться к службе Azure Data Lake Analytics. Чтобы использовать аутентификацию основного сервисного компонента, зарегистрируйте сущность приложения в Microsoft Entra ID и предоставьте ей доступ как к Data Lake Analytics, так и к используемому Data Lake Store. Подробные инструкции см. в разделе Аутентификация между службами. Запишите следующие значения, которые используются для определения связанной службы:
- Идентификатор приложения
- ключ приложения.
- Идентификатор клиента
Предоставьте разрешение учетной записи службы для Azure Data Lake Analytics с помощью Мастера добавления пользователей.
Используйте аутентификацию с использованием главного объекта службы, указав следующие свойства:
| Свойство | Описание: | Обязательное поле |
|---|---|---|
| servicePrincipalId | Укажите идентификатора клиента приложения. | Да |
| servicePrincipalKey | Укажите ключ приложения. | Да |
| арендатор | Укажите сведения о клиенте (доменное имя или идентификатор клиента), в котором находится приложение. Эти сведения можно получить, наведя указатель мыши на правый верхний угол страницы портала Azure. | Да |
Пример: Аутентификация с помощью служебного принципала
{
"name": "AzureDataLakeAnalyticsLinkedService",
"properties": {
"type": "AzureDataLakeAnalytics",
"typeProperties": {
"accountName": "<account name>",
"dataLakeAnalyticsUri": "<azure data lake analytics URI>",
"servicePrincipalId": "<service principal id>",
"servicePrincipalKey": {
"value": "<service principal key>",
"type": "SecureString"
},
"tenant": "<tenant info, e.g. microsoft.onmicrosoft.com>",
"subscriptionId": "<optional, subscription id of ADLA>",
"resourceGroupName": "<optional, resource group name of ADLA>"
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Дополнительные сведения о связанной службе см. в статье Службы, связанные с вычислениями.
Действие U-SQL в Data Lake Analytics
В следующем фрагменте кода JSON определяется конвейер с действием U-SQL в Data Lake Analytics. Определение действия содержит ссылку на ранее созданную связанную службу Azure Data Lake Analytics. Чтобы выполнить скрипт U-SQL Data Lake Analytics, служба отправляет указанный скрипт в Data Lake Analytics. Необходимые входные и выходные данные определяются в скрипте Data Lake Analytics для извлечения и вывода.
{
"name": "ADLA U-SQL Activity",
"description": "description",
"type": "DataLakeAnalyticsU-SQL",
"linkedServiceName": {
"referenceName": "<linked service name of Azure Data Lake Analytics>",
"type": "LinkedServiceReference"
},
"typeProperties": {
"scriptLinkedService": {
"referenceName": "<linked service name of Azure Data Lake Store or Azure Storage which contains the U-SQL script>",
"type": "LinkedServiceReference"
},
"scriptPath": "scripts\\kona\\SearchLogProcessing.txt",
"degreeOfParallelism": 3,
"priority": 100,
"parameters": {
"in": "/datalake/input/SearchLog.tsv",
"out": "/datalake/output/Result.tsv"
}
}
}
В следующей таблице описаны имена и описания свойств, относящихся к этому действию.
| Свойство | Описание: | Обязательное поле |
|---|---|---|
| имя | Имя действия в конвейере. | Да |
| описание | Описание того, что делает активность. | Нет |
| тип | Для действия U-SQL в Data Lake Analytics тип действия — DataLakeAnalyticsU-SQL. | Да |
| linkedServiceName | Связанная служба Azure Data Lake Analytics. Чтобы узнать больше об этой связанной службе, см. статью Связанные службы вычислений. | Да |
| scriptPath | Путь к папке, содержащей скрипт U-SQL В имени файла учитывается регистр. | Да |
| scriptLinkedService | Связанная служба, которая связывает Azure Data Lake Store или службу хранилища Azure, содержащую скрипт. | Да |
| степень параллелизма | Максимальное количество узлов, используемых одновременно для выполнения задания. | Нет |
| приоритет | Определяет, какие из всех заданий в очереди должны запускаться первыми. Чем меньше число, тем выше приоритет. | Нет |
| параметры | Параметры для передачи в скрипт U-SQL. | Нет |
| версия среды выполнения | Версия среды выполнения обработчика U-SQL, которую нужно использовать. | Нет |
| режим компиляции | Режим компиляции U-SQL. Может иметь одно из следующих значений: Semantic: выполнение только семантических проверок и необходимых проверок работоспособности. Full: выполнение полной компиляции, включая проверку синтаксиса, оптимизацию, создание кода и т. д. SingleBox: выполнение полной компиляции с параметром TargetType для SingleBox. Если не указать значение для этого свойства, сервер определит оптимальный режим компиляции. |
Нет |
См. SearchLogProcessing.txt для определения сценария.
Пример скрипта U-SQL
@searchlog =
EXTRACT UserId int,
Start DateTime,
Region string,
Query string,
Duration int,
Urls string,
ClickedUrls string
FROM @in
USING Extractors.Tsv(nullEscape:"#NULL#");
@rs1 =
SELECT Start, Region, Duration
FROM @searchlog
WHERE Region == "en-gb";
@rs1 =
SELECT Start, Region, Duration
FROM @rs1
WHERE Start <= DateTime.Parse("2012/02/19");
OUTPUT @rs1
TO @out
USING Outputters.Tsv(quoting:false, dateTimeFormat:null);
В приведенном выше примере входные и выходные данные скрипта определяются в параметрах @in и @out. Значения параметров @in и @out в сценарии U-SQL передаются службой динамически, с использованием раздела parameters.
В определении конвейера для заданий, которые выполняются в службе Azure Data Lake Analytics, можно определить другие свойства, например degreeOfParallelism и priority.
Динамические параметры
В примере определения конвейера параметрам in и out присвоено жестко заданные значения.
"parameters": {
"in": "/datalake/input/SearchLog.tsv",
"out": "/datalake/output/Result.tsv"
}
Вместо этого можно использовать динамические параметры. Например:
"parameters": {
"in": "/datalake/input/@{formatDateTime(pipeline().parameters.WindowStart,'yyyy/MM/dd')}/data.tsv",
"out": "/datalake/output/@{formatDateTime(pipeline().parameters.WindowStart,'yyyy/MM/dd')}/result.tsv"
}
В этом случае входные файлы по-прежнему берутся из папки /datalake/input, а выходные файлы создаются в папке /datalake/output. Имена файлов являются динамическими и зависят от времени начала окна, которое передается, когда активируется конвейер.
Связанный контент
Ознакомьтесь со следующими ссылками, в которых описаны способы преобразования данных другими способами: