Примечание.
Для доступа к этой странице требуется авторизация. Вы можете попробовать войти или изменить каталоги.
Для доступа к этой странице требуется авторизация. Вы можете попробовать изменить каталоги.
ОБЛАСТЬ ПРИМЕНЕНИЯ: Фабрика данных Azure Azure Synapse Analytics
Фабрика данных Azure Azure Synapse Analytics
Совет
Попробуйте использовать фабрику данных в Microsoft Fabric, решение для аналитики с одним интерфейсом для предприятий. Microsoft Fabric охватывает все, от перемещения данных до обработки и анализа данных в режиме реального времени, бизнес-аналитики и отчетности. Узнайте, как бесплатно запустить новую пробную версию !
Действие Spark в фабрике данных и конвейере Synapse выполняет программу Spark в вашем кластере HDInsight или в кластере HDInsight по запросу. Данная статья основана на материалах статьи о действиях преобразования данных , в которой приведен общий обзор преобразования данных и список поддерживаемых действий преобразования. Если вы используете связанную службу Spark по требованию, служба автоматически создает кластер Spark для обработки данных, когда это необходимо, а затем удаляет его после завершения обработки.
Добавление действия Spark в конвейер с помощью пользовательского интерфейса
Чтобы использовать действие Spark в конвейере, выполните следующие действия:
Выполните поиск элемента Spark на панели конвейера «Действия» и перетащите действие Spark на холст конвейера.
Выберите новое действие Spark на холсте, если оно еще не выбрано.
Перейдите на вкладку Кластер HDI, чтобы выбрать или создать связанную службу для кластера HDInsight, которая будет использоваться для выполнения действия Spark.
Перейдите на вкладку Script / Jar для выбора или создания новой службы связанной с работой, которая подключается к учетной записи службы хранилища Azure, чтобы размещать ваш скрипт. Укажите путь к файлу для выполнения. Можно также настроить дополнительные сведения, включая пользователя прокси-сервера, конфигурацию отладки, а также аргументы и параметры конфигурации Spark, которые будут переданы в скрипт.
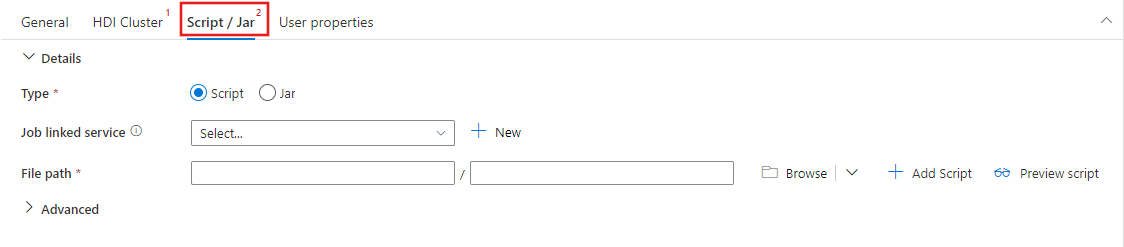
Свойства действия Spark
Ниже приведен пример определения JSON действия Spark.
{
"name": "Spark Activity",
"description": "Description",
"type": "HDInsightSpark",
"linkedServiceName": {
"referenceName": "MyHDInsightLinkedService",
"type": "LinkedServiceReference"
},
"typeProperties": {
"sparkJobLinkedService": {
"referenceName": "MyAzureStorageLinkedService",
"type": "LinkedServiceReference"
},
"rootPath": "adfspark",
"entryFilePath": "test.py",
"sparkConfig": {
"ConfigItem1": "Value"
},
"getDebugInfo": "Failure",
"arguments": [
"SampleHadoopJobArgument1"
]
}
}
В следующей таблице приведено описание свойств, используемых в определении JSON.
| Свойство | Описание: | Обязательное поле |
|---|---|---|
| имя | Имя действия в конвейере. | Да |
| описание | Текст, описывающий, что делает это действие. | Нет |
| тип | Для действия Spark используется тип действия HDInsightSpark. | Да |
| имяСвязанногоСервиса | Имя связанной службы Spark HDInsight, в которой выполняется программа Spark. Дополнительные сведения об этой связанной службе см. в статье Связанные вычислительные службы. | Да |
| SparkJobLinkedService | Связанная служба Azure Storage, в которой хранятся файл задания Spark, зависимости и журналы. Здесь поддерживаются только связанные службы Хранилище BLOB-объектов Azure и ADLS 2-го поколения. Если значение этого свойства не указано, используется хранилище, связанное с кластером HDInsight. Значением этого свойства может быть только связанная служба хранилища Azure. | Нет |
| корневой путь | Контейнер BLOB-объектов Azure и папка, содержащая файл Spark. Имя файла чувствительно к регистру. Подробнее о структуре этой папки см. в разделе о структуре папок (следующий раздел). | Да |
| путь к файлу входа | Относительный путь к корневой папке пакета и кода Spark. Файл записи должен быть файлом Python или JAR-файлом. | Да |
| className | Основной класс Java или Spark приложения. | Нет |
| аргументы | Список аргументов командной строки для программы Spark. | Нет |
| proxyUser | Учетная запись пользователя для олицетворения, используемая для выполнения программы Spark. | Нет |
| sparkConfig | Укажите значения для свойств конфигурации Spark, перечисленных в разделе Конфигурация Spark — свойства приложения. | Нет |
| getDebugInfo | Указывает, когда файлы журнала Spark копируются в хранилище Azure, используемое кластером HDInsight, или в хранилище, указанное в sparkJobLinkedService. Допустимые значения: Нет, Всегда или Ошибка. Значение по умолчанию: None. | Нет |
Структура папок
Задания Spark обеспечивают большую гибкость, чем задания Pig и Hive. Для заданий Spark можно указать несколько зависимостей, например пакеты JAR (размещаются в CLASSPATH Java), файлы Python (размещаются в PYTHONPATH) и другие файлы.
Создайте следующую структуру папок в хранилище BLOB-объектов Azure, на которое ссылается связанная служба HDInsight. Затем передайте зависимые файлы в соответствующие вложенные папки в корневой папке, определенной значением entryFilePath. Например, передайте файлы Python во вложенную папку pyFiles, а JAR-файлы — во вложенную папку jars, расположенную в корневой папке. Во время выполнения служба ожидает в хранилище BLOB-объектов Azure следующую структуру папок:
| Путь | Описание: | Обязательное поле | Тип |
|---|---|---|---|
. (root) |
Путь к корневому каталогу задания Spark в хранилище связанной службы. | Да | Папка |
| <Определяется пользователем> | Путь, указывающий на входной файл задания Spark. | Да | Файлы |
| ./jars | Все файлы в этой папке передаются и помещаются в папку classpath Java для кластера. | Нет | Папка |
| ./pyFiles | Все файлы в этой папке передаются и помещаются в папку PYTHONPATH для кластера. | Нет | Папка |
| ./files | Все файлы в этой папке передаются и помещаются в рабочий каталог исполнителя. | Нет | Папка |
| ./архивы | Все файлы в этой папке не сжаты. | Нет | Папка |
| ./logs | Папка, в которой содержатся журналы из кластера Spark. | Нет | Папка |
Ниже приведен пример хранилища, содержащего два файла заданий Spark в хранилище BLOB-объектов Azure, на которое ссылается связанная служба HDInsight.
SparkJob1
main.jar
files
input1.txt
input2.txt
jars
package1.jar
package2.jar
logs
archives
pyFiles
SparkJob2
main.py
pyFiles
scrip1.py
script2.py
logs
archives
jars
files
Связанный контент
Ознакомьтесь со следующими ссылками, в которых описаны способы преобразования данных другими способами: