Примечание.
Для доступа к этой странице требуется авторизация. Вы можете попробовать войти или изменить каталоги.
Для доступа к этой странице требуется авторизация. Вы можете попробовать изменить каталоги.
ОБЛАСТЬ ПРИМЕНЕНИЯ: Фабрика данных Azure Azure Synapse Analytics
Фабрика данных Azure Azure Synapse Analytics
Совет
Попробуйте использовать фабрику данных в Microsoft Fabric, решение для аналитики с одним интерфейсом для предприятий. Microsoft Fabric охватывает все, от перемещения данных до обработки и анализа данных в режиме реального времени, бизнес-аналитики и отчетности. Узнайте, как бесплатно запустить новую пробную версию !
Если вы еще не работали с фабрикой данных Azure, ознакомьтесь со статьей Введение в фабрику данных Azure.
В этом руководстве вы узнаете о лучших практиках, которые можно применять при записи файлов в ADLS Gen2 или Azure Blob Storage с помощью потоков данных. Вам потребуется доступ к аккаунту хранилища Blob-объектов Azure или аккаунту Azure Data Lake Storage второго поколения для чтения parquet-файла и последующего сохранения результатов в папках.
Предварительные условия
- Подписка Azure. Если у вас еще нет подписки Azure, создайте бесплатную учетную запись Azure, прежде чем начинать работу.
- Учетная запись хранения Azure. Хранилище ADLS используется в качестве хранилища данных источника и приемника. Если у вас нет учетной записи хранения, создайте ее, следуя действиям в этом разделе.
Для действий, описанных в этом учебнике, предполагается:
Создание фабрики данных
На этом этапе вы создадите фабрику данных и откроете пользовательский интерфейс службы "Фабрика данных" для создания конвейера в фабрике данных.
Откройте Microsoft Edge или Google Chrome. Сейчас пользовательский интерфейс Фабрики данных поддерживают только браузеры Microsoft Edge и Google Chrome.
В меню слева последовательно выберите элементы Создать ресурс>Интеграция>Фабрика данных.
На странице Новая фабрика данных в поле Имя введите ADFTutorialDataFactory.
Выберите подписку Azure, в рамках которой вы хотите создать фабрику данных.
Для группы ресурсов выполните одно из следующих действий:
a. Выберите Использовать существующуюи укажите существующую группу ресурсов в раскрывающемся списке.
б. Выберите "Создать" и введите имя группы ресурсов. Дополнительные сведения о группах ресурсов см. в статье "Использование групп ресурсов для управления ресурсами Azure".
В качестве версии выберите V2.
В поле Расположение выберите расположение фабрики данных. В раскрывающемся списке отображаются только поддерживаемые местоположения. Хранилища данных (например, служба хранилища Azure и База данных SQL) и вычислительные ресурсы (например, Azure HDInsight), используемые фабрикой данных, могут располагаться в других регионах.
Нажмите кнопку создания.
После завершения создания вы увидите уведомление в центре уведомлений. Нажмите кнопку Перейти к ресурсу, чтобы открыть страницу фабрики данных.
Выберите Автор и мониторинг, чтобы открыть в отдельной вкладке интерфейс Data Factory.
Создание производственного конвейера с активностью потока данных
На этом этапе вы создадите конвейер, содержащий действие потока данных.
На главной странице Azure Data Factory выберите элемент Оркестрация.
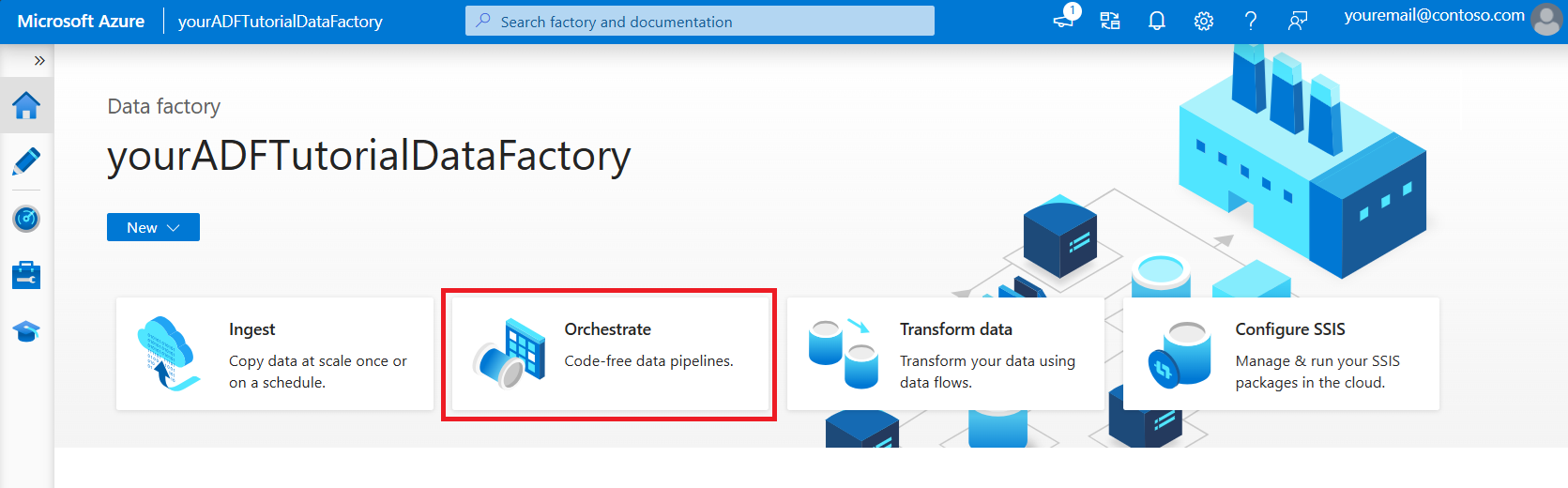
На вкладке Общие для конвейера введите DeltaLake в качестве имени конвейера.
На верхней панели фабрики переместите ползунок Data Flow debug (Отладка Потока данных) во включенное положение. Режим отладки позволяет в интерактивном режиме тестировать логику преобразования в динамическом кластере Spark. Подготовка кластеров Потоков данных занимает 5–7 минут, поэтому пользователям рекомендуем сначала включить отладку, если планируется разработка Потока данных. Дополнительные сведения см. в статье Режим отладки.
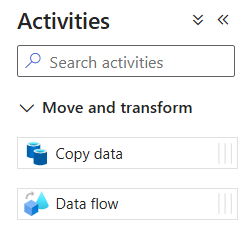
В области Действия разверните панель Перемещение и преобразование. Перетащите активность Поток данных с панели на холст конвейера.
Создание логики преобразования на холсте потока данных
Вы будете получать любые исходные данные (в этом учебнике мы будем использовать источник файлы Parquet) и использовать синхронное преобразование для размещения данных в формате Parquet, используя наиболее эффективные механизмы для ETL в озере данных.

Цели руководства
- Выбор любого из исходных наборов данных в новом потоке данных. 1. Использование потоков данных для эффективного секционирования набора данных приемника.
- Разместите секционированные данные в папках озера данных ADLS Gen2.
Начните с пустого холста потока данных
Сначала давайте настроим среду потока данных для каждого из механизмов, описанных ниже, для размещения данных в ADLS 2-го поколения.
- Щелкните трансформацию источника.
- Нажмите новую кнопку рядом с набором данных в нижней области.
- Выберите набор данных или создайте новый. В этой демонстрации мы будем использовать набор данных Parquet с именем User Data.
- Добавьте преобразование "Деривативный столбец". Мы будем использовать его в качестве способа динамического задания имен для нужных папок.
- Добавьте преобразование разветвителя.
Вывод иерархической папки
Очень часто используются уникальные значения в ваших данных для построения иерархий папок, чтобы секционировать данные в хранилище данных. Это оптимальный способ организации и обработки данных в озере данных и в Spark (вычислительном движке для потоков данных). Тем не менее, чтобы упорядочить выходные данные таким образом, наблюдаются небольшие потери производительности. При использовании этого механизма в приемнике ожидается небольшое снижение эффективности конвейера.
- Вернитесь к конструктору потока данных и измените поток данных, созданный выше. Щелкните преобразование узла приёмки.
- Щелкните «Оптимизировать» > «Установить секционирование» > «Ключ».
- Выберите столбцы, которые вы хотите использовать, чтобы задать структуру иерархии папок.
- Обратите внимание, что в примере ниже год и месяц используются в качестве столбцов для именования папок. Результатом будут папки вида
releaseyear=1990/month=8. - При доступе к секциям данных в источнике потока данных вы будете указывать только на папку верхнего уровня выше
releaseyearи использовать шаблон с подстановочными знаками для каждой последующей папки, например**/**/*.parquet. - Для управления значениями данных или даже при необходимости создания искусственных значений для имен папок используйте преобразование "Производный столбец", чтобы создать значения, которые нужно использовать в именах папок.

Назвать папку по значению данных
Немного более эффективным методом приемника для данных озера с использованием ADLS 2-го поколения без такого преимущества, как секционирование по ключу или значению, является Name folder as column data. В то время как иерархическая структура по ключу позволяет вам легче обрабатывать срезы данных, данный метод является плоской структурой папок, что позволяет быстрее записывать данные.
- Вернитесь к конструктору потока данных и измените поток данных, созданный выше. Щелкните преобразование узла приёмки.
- Щелкните "Оптимизировать > Задать секционирование > Использовать текущее секционирование".
- Щелкните «Настройки» > Назовите папку по данным столбца.
- Выберите столбец, который вы хотите использовать для создания имен папок.
- Для управления значениями данных или даже при необходимости создания искусственных значений для имен папок используйте преобразование "Производный столбец", чтобы создать значения, которые нужно использовать в именах папок.
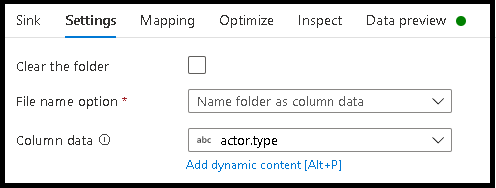
Назовите файл в соответствии со значениями данных
Методы, перечисленные выше, являются хорошим вариантом использования при создании категорий папок в озере данных. Схема именования файлов по умолчанию, применяемая этими методами, заключается в использовании идентификатора задания для исполнителя Spark. Иногда может потребоваться задать имя выходного файла в приемнике текста потока данных. Этот метод рекомендуется использовать только с маленькими файлами. Процесс объединения файлов секций в один выходной файл является длительным.
- Вернитесь к конструктору потока данных и измените поток данных, созданный выше. Щелкните преобразование узла приёмки.
- Щелкните "Оптимизировать > Задать секционирование > Одна секция". Именно это требование единственного раздела становится узким местом в процессе выполнения при объединении файлов. Рекомендуем использовать этот параметр только для маленьких файлов.
- Щелкните «Параметры» > Назовите файл как столбец данных.
- Выберите столбец, который вы хотите использовать для создания имен файлов.
- Для управления значениями данных или даже при необходимости создания искусственных значений для имен файлов используйте преобразование "Производный столбец", чтобы создать значения, которые нужно использовать в именах файлов.
Связанный контент
Дополнительные сведения о приемниках потока данных.