Функции и терминология в Центрах событий Azure
Центры событий Azure — это масштабируемая служба обработки событий, которая принимает и обрабатывает большие объемы событий и данных с низкой задержкой и высокой надежностью. Общие сведения о службе см. в разделе "Что такое Центры событий?".
Эта статья продолжает тему Центров событий и содержит техническую информацию и сведения о реализации компонентов и функций этой службы.
Пространство имен
Пространство имен концентраторов событий — это контейнер управления для концентраторов событий (или разделов, как они называются Kafka). Оно предоставляет интегрированные с DNS конечные точки сети, а также различные функции управления доступом и сетевой интеграции, такие как фильтрация IP-адресов, конечная точка службы виртуальной сети и Приватный канал

Секции
Центры событий упорядочивают последовательности событий, отправленных в концентратор событий, в одну или несколько секций. По мере поступления новых событий они добавляются в конец этой последовательности.

Секцию можно рассматривать как журнал фиксации. Секции содержат данные о событиях, содержащие следующие сведения:
- Текст события
- Определяемый пользователем контейнер свойств, описывающий событие
- Метаданные, такие как смещение в секции, его число в последовательности потоков
- Метка времени на стороне службы, в которой она была принята
Преимущества использования секций
Служба "Центры событий" предназначена для обработки больших объемов событий, а секционирование помогает при этом двумя способами.
- Несмотря на то, что Центры событий — это служба PaaS, под ней есть физическая реальность. Сохранение журнала, сохраняющего порядок событий, требует, чтобы эти события хранились вместе в базовом хранилище и ее репликах, что приводит к потолку пропускной способности для такого журнала. Секционирование позволяет использовать несколько параллельных журналов для одного концентратора событий и, следовательно, умножение доступной емкости пропускной способности ввода-вывода (ввода-вывода).
- Ваши приложения должны справляться с обработкой объема событий, отправляемых в концентратор событий. Она может быть сложной и требует существенной, масштабируемой, параллельной обработки емкости. Емкость одного процесса обработки событий ограничена, поэтому вам требуется несколько процессов. Секции — это то, как ваше решение передает эти процессы и тем самым гарантирует, что у каждого события есть четкий владелец обработки.
Количество разделов
Количество секций можно указать во время создания концентратора событий. Оно должно быть между одним и максимальным числом секций, разрешенным для каждой ценовой категории. Сведения об ограничении количества секций для каждой категории см. в этой статье.
Рекомендуем выбрать как минимум столько секций, сколько может потребоваться во время пиковой нагрузки вашего приложения для этого концентратора событий. Для уровней, отличных от уровня "Премиум" и выделенных уровней, нельзя изменить число секций для концентратора событий после его создания. Для концентратора событий уровня "Премиум" или "Выделенный" можно увеличить число секций после его создания, но их нельзя уменьшить. Распределение потоков между секциями изменится при сопоставлении ключей секций с изменениями, поэтому следует стараться избежать таких изменений, если относительный порядок событий имеет значение в приложении.
Установить для количества секций максимально допустимое значение может быть заманчиво, но всегда помните, что ваши потоки событий должны быть структурированы так, чтобы вы действительно могли воспользоваться преимуществами нескольких секций. Если требуется абсолютное сохранение порядка во всех событиях или только несколько подпотоков, вы можете не воспользоваться преимуществами множества секций. Кроме того, наличие большого количества секций усложняет обработку.
Когда речь идет о ценах, не имеет значения, сколько секций находится в концентраторе событий. Это зависит от количества единиц ценообразования (единиц пропускной способности для стандартного уровня, единиц обработки для уровня "Премиум" и единиц мощности для уровня "Выделенный") для пространства имен или выделенного кластера. Например, концентратор событий уровня "Стандартный" с 32 секциями или с одной секцией влечет за собой ту же стоимость, если пространство имен имеет одну емкость TU. Кроме того, можно масштабировать единицы пропускной способности или единицы обработки в пространстве имен или единицы емкости в выделенном кластере независимо от числа секций.
Как секционирование — это механизм организации данных, позволяющий публиковать и использовать данные параллельно. Рекомендуется сбалансировать единицы масштабирования (единицы пропускной способности для стандартного уровня, единицы обработки для уровня "Премиум" или единицы емкости для выделенного уровня) и секции для достижения оптимального масштабирования. Как правило, рекомендуется использовать максимальную пропускную способность в 1 МБ/с на секцию. Таким образом, правило большого пальца для вычисления количества секций будет делить максимальную ожидаемую пропускную способность на 1 МБ/с. Например, если для вашего варианта использования требуется 20 МБ/с, рекомендуется выбрать по крайней мере 20 секций для достижения оптимальной пропускной способности.
Однако если у вас есть модель, в которой приложение имеет сходство с определенной секцией, увеличение числа секций не является полезным. Дополнительные сведения см. в статье Доступность и согласованность в Центрах событий.
Сопоставление событий с секциями
Вы можете использовать ключ секции, чтобы сопоставлять входные данные событий с определенными секциями для организации данных. Ключ секции — это указываемое отправителем значение, передаваемое в концентратор событий. Он обрабатывается через статическую хэш-функцию, которая создает назначение секции. Если при публикации события не указать ключ секции, назначение создается с помощью циклического перебора.
Издателю событий известен только ключ секции, но не сама секция, в которой публикуются события. Благодаря разделению ключа и секции отправителю не нужно располагать избыточными сведениями о последующей обработке и хранении событий. Уникальное удостоверение устройства или пользователя является хорошим ключом секции, но другие атрибуты, например географическое положение, можно также использовать для группировки связанных событий в одну секцию.
Указание ключа секции позволяет хранить связанные события в одной и той же секции и в точно таком же порядке, в котором они прибыли. Ключ секции — это строка, которая является производной от контекста приложения и определяет взаимосвязь событий. Последовательность событий, определяемых ключом секции, называется потоком. Секция — это мультиплексное хранилище журналов для множества таких потоков.
Примечание.
Хотя вы можете отправить события непосредственно в секции, мы не рекомендуем это делать, особенно если вам важна высокая доступность. Это понижает доступность концентратора событий до уровня секции. Дополнительные сведения см. в статье Доступность и согласованность в Центрах событий.
Издатели событий
Любая сущность, которая отправляет данные в Центр событий, является издателем событий (синоним создателя событий). Издатели событий могут публиковать события с помощью протокола HTTPS, AMQP 1.0 или Kafka. Издатели событий используют авторизацию на основе идентификатора Microsoft Entra с маркерами JWT, выданными OAuth2, или маркером подписанного URL-адреса концентратора событий (SAS) для получения доступа к публикации.
Вы можете опубликовать событие через протокол AMQP 1.0, Kafka или HTTPS. Служба Центров событий предоставляет клиентские библиотеки для публикации событий в Центре событий REST API и .NET, Java, Python, JavaScriptи Go. Для других сред выполнения и платформ можно использовать любой клиент AMQP 1.0, например Apache Qpid.
Решение об использовании AMQP или HTTPS обусловлено сценарием использования. AMQP требует установки постоянного двунаправленного сокета в дополнение к безопасности на уровне транспорта (TLS) или протоколу SSL/TLS. AMQP имеет более высокие затраты на сеть при инициализации сеанса, однако HTTPS требует дополнительных затрат TLS для каждого запроса. AMQP имеет более высокую производительность для частых издателей и может достичь значительно меньшей задержки при использовании с асинхронным кодом публикации.
Можно публиковать события по отдельности или в пакетном режиме. Для одной публикации установлено ограничение в 1 МБ, независимо от того, одиночное это событие или пакет. События публикации, превышающие это пороговое значение, отклоняется.
Пропускная способность Центров событий масштабируется с помощью секций и распределения единиц пропускной способности. Издателям рекомендуется не знать, какая конкретно модель секционирования выбрана для Центра событий. Следует указать только ключ секции, который используется для согласованного назначения связанных событий одной и той же секции.
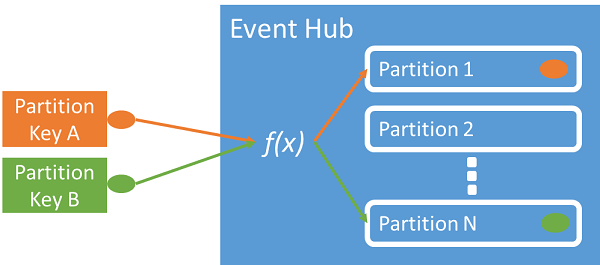
Центры событий хранят вместе все события, использующие одинаковое значение ключа секции, и доставляют их в порядке поступления. Если ключи секций используются с применением политик издателя, удостоверение издателя и значение ключа секции должны совпадать. В противном случае возникает ошибка.
Хранение событий
Опубликованные события удаляются из Центра событий в соответствии с настраиваемой политикой хранения на основе времени. Ниже приведены некоторые важные замечания.
- Значение по умолчанию и самый короткий срок хранения составляет 1 час.
- Для Центров событий (цен. категория Стандартный) максимальный период хранения составляет 7 дней.
- Для Центров событий (ценовых категорий Премиум и Выделенный) максимальный период хранения составляет 90 дней.
- Если вы измените период хранения, он будет применяться ко всем событиям, включая события, которые уже находятся в концентраторе событий.
Центры событий сохраняют события в течение указанного времени хранения, которое применяется для всех секций. События автоматически удаляются по окончании периода хранения. Если вы указали период хранения в течение одного дня (24 часа), событие становится недоступным ровно через 24 часа после его принятия. События нельзя явно удалять.
Если необходимо архивировать события за пределами допустимого срока хранения, их можно автоматически сохранить в службе хранилища Azure или Azure Data Lake, включив функцию записи концентраторов событий. Если необходимо выполнить поиск или анализ таких глубоких архивов, их можно легко импортировать в Azure Synapse или другие аналогичные хранилища и платформы аналитики.
Причина, по которой в Центрах событий устанавливается ограничение на хранение данных по времени, заключается в том, чтобы предотвратить попадание больших объемов исторических данных клиентов в глубокое хранилище, которое индексируется только по метке времени и допускает только последовательный доступ. Философия такой архитектуры заключается в том, что исторические данные нуждаются в более подробном индексировании и более прямом доступе, чем обеспечивает интерфейс событий в реальном времени, который предоставляют Центры событий или Kafka. Подсистемы потоковой передачи событий не подходят для того, чтобы играть роль озер данных или долгосрочных архивов для источника событий.
Примечание.
Центр событий — это обработчик потока событий в реальном времени, не предназначенный для использования вместо базы данных и (или) в качестве постоянного хранилища для бесконечно удерживаемых потоков событий.
Чем глубже журнал потока событий, тем больше вам понадобятся дополнительные индексы для поиска определенного сегмента журнала заданного потока. Проверка полезных данных и индексирования событий не входит в область применения функций Центров событий (или Apache Kafka). Таким образом, базы данных и специализированные хранилища и модули аналитики, такие как Azure Data Lake Store, Azure Data Lake Analytics и Azure Synapse, гораздо больше подходят для хранения исторических событий.
Функция "Сбор" в Центрах событий интегрируется непосредственно с Хранилищем BLOB-объектов Azure и Azure Data Lake Storage, благодаря чему также позволяет перемещать потоки событий напрямую в Azure Synapse.
Политика издателя
Центры событий обеспечивают точный контроль над издателями событий через политики издателя. Политики издателя — это функции среды выполнения, которые упрощают обработку большого количества независимых издателей событий. Благодаря политикам издателя каждый издатель использует свой собственный уникальный идентификатор при публикации событий в концентраторе событий с помощью следующего механизма:
//<my namespace>.servicebus.windows.net/<event hub name>/publishers/<my publisher name>
Не требуется создавать имена издателей заранее, но они должны соответствовать маркеру SAS, который используется при публикации события, для обеспечения идентификации независимого издателя. При использовании политик издателя значение PartitionKey должно быть задано на имя издателя. Для правильной работы эти значения должны совпадать.
Capture
Функция "Сбор" в Центрах событий позволяет автоматически собирать данные потоковой передачи в Центры событий и сохранять их в выбранной учетной записи хранения BLOB-объектов или учетной записи службы хранения Azure Data Lake. Эту функцию можно включить на портале Azure и указать минимальный размер записываемых данных и интервал времени для записи. С помощью функции "Сбор" в Центрах событий можно указать собственную учетную запись хранилища BLOB-объектов Azure и контейнер или учетную запись службы хранения Azure Data Lake, используемую для хранения собранных данных. Зафиксированные данные записываются в формате Apache Avro.

Файлы, созданные записью с помощью функции "Сбор" в Центрах событий, имеют следующую схему Avro.

Примечание.
При использовании бескодового редактора на портале Azure можно записывать данные потоковой передачи в Центрах событий в учетной записи Azure Data Lake Storage 2-го поколения в формате Parquet. Дополнительные сведения см. в статьях Практическое руководство: запись данных из Центров событий в формате Parquet и Учебник: запись данных Центров событий в формате Parquet и анализ этих данных с помощью Azure Synapse Analytics.
Маркеры SAS
Центры событий используют подписанные URL-адреса, доступные на уровне пространства имен и концентратора событий. Маркер SAS создается на основе ключа SAS и хэша SHA URL-адреса, закодированного в определенном формате. С помощью имени ключа (политики) и токена Центры событий могут повторно создать хэш, чтобы аутентифицировать отправителя. Как правило, маркеры SAS для издателей событий создаются только с правом отправки конкретному концентратору событий. Этот механизм URL-адреса маркера SAS является основой для идентификации издателя, представленной в политике издателя. Дополнительные сведения о работе с SAS см. в статье Проверка подлинности подписи при общем доступе с помощью служебной шины.
Получатели событий
Любая сущность, считывающая данные из концентратора событий, является потребителем событий. Потребители или получатели используют AMQP или Apache Kafka для получения событий из концентратора событий. Центры событий поддерживают только модель извлечения для потребителей, получая от нее события. Даже если обработчики событий используются для обработки событий из концентратора событий, обработчик событий внутренне использует модель извлечения для получения событий из концентратора событий.
Группы получателей
Механизм публикации и подписки Центров событий реализован в виде групп потребителей. Группа потребителей — это логическая группа потребителей, которые считывают данные из концентратора событий или раздела Kafka. Это позволяет нескольким потребляющим приложениям считывать одни и те же потоковые данные в концентраторе событий независимо от их смещения. Он позволяет параллельно использовать сообщения и распределять рабочую нагрузку между несколькими потребителями, сохраняя порядок сообщений в каждой секции.
Рекомендуется использовать только один активный приемник в секции в группе потребителей. Однако в некоторых сценариях можно использовать до пяти потребителей или получателей на секцию, где все получатели получают все события секции. Если в одной секции находится несколько читателей, процесс обработки событий будет дублироваться. Необходимо обработать его в коде, который не является тривиальным. Тем не менее для некоторых сценариев такой поход допустим.
В архитектуре обработки потока каждое потребляющее приложение соответствует группе потребителей. Если вы хотите записать данные событий в долговременное хранилище, то приложение, записывающее данные в хранилище, является группой потребителей. Сложную обработку событий затем может выполнить еще одна (отдельная) группа потребителей. К секции можно обращаться только через группу потребителей. В концентраторе событий всегда есть группа потребителей по умолчанию, и можно создать любое количество, не превышающее максимальное количество групп потребителей, для соответствующей ценовой категории.
Некоторые клиенты, предлагаемые пакетами SDK для Azure, представляют собой интеллектуальные агенты объекта-получателя, которые автоматически следят за тем, чтобы у каждой секции был один читатель и чтение осуществлялось из всех секций для Центра событий. Он позволяет коду сосредоточиться на обработке событий, считываемых из концентратора событий, чтобы игнорировать многие сведения о секциях. Дополнительные сведения см. в разделе Подключение к секции.
Ниже приведены примеры соглашения URI группы потребителей.
//<my namespace>.servicebus.windows.net/<event hub name>/<Consumer Group #1>
//<my namespace>.servicebus.windows.net/<event hub name>/<Consumer Group #2>
На следующем рисунке показана архитектура обработки потока Центров событий.

Смещение потока
Смещение — это положение события внутри секции. Смещение можно представить как клиентский курсор. Смещение представляет собой байт-нумерацию события. Благодаря этому потребитель события (модуль чтения) может указать точку в потоке событий, с которой требуется начать чтение событий. Можно указать смещение как отметку времени или как значение смещения. Потребители ответственны за хранение своих собственных значений смещения вне службы "Центры событий". В секции каждое событие включает смещение.

Назначение контрольных точек
Создание контрольных точек — это процесс, с помощью которого модули чтения помечают или фиксируют свое положение в последовательности событий секции. Создание контрольных точек является ответственностью потребителя и выполняется для каждой секции в пределах группы потребителей. Это означает, что для каждой группы потребителей модуль чтения каждой секции должен хранить свое текущее положение в потоке событий и может сообщать службе, когда он считает поток данных завершенным.
Если модуль чтения отключается от секции, при повторном подключении он приступает к чтению данных с контрольной точки, которая ранее была отправлена последним модулем чтения этой секции в этой группе потребителей. При подключении модуль чтения передает это смещение в концентратор событий, чтобы указать место, с которого следует начинать чтение. Таким образом, можно использовать контрольные точки как для маркировки событий как "завершенных" подчиненными приложениями, так и для обеспечения устойчивости в случае отработки отказа между модулями чтения, работающими на разных компьютерах. Можно вернуться к предыдущим данным, указав в этом процессе назначения контрольных точек меньшую величину смещения. В рамках такого подхода при создании контрольных точек вы обеспечиваете отказоустойчивость и воспроизведение потока событий.
Внимание
Смещения предоставляются службой Центров событий. Ответственность за назначение контрольных точек в процессе обработки событий несет объект-получатель.
Следуйте этим рекомендациям при использовании Хранилище BLOB-объектов Azure в качестве хранилища контрольных точек:
- Используйте отдельный контейнер для каждой группы потребителей. Вы можете использовать одну и ту же учетную запись хранения, но использовать один контейнер для каждой группы.
- Не используйте контейнер для других компонентов и не используйте учетную запись хранения для других действий.
- Учетная запись хранения должна находиться в том же регионе, в который находится развернутое приложение. Если приложение находится в локальной среде, попробуйте выбрать ближайший регион.
На странице учетной записи хранения в портал Azure в разделе службы BLOB-объектов убедитесь, что следующие параметры отключены.
- Иерархическое пространство имен
- Обратимое удаление BLOB-объекта
- Управление версиями
сжатие журнала;
Центры событий Azure поддерживает сжатие журнала событий, чтобы сохранить последние события заданного ключа события. С помощью компактных центров событий или раздела Kafka можно использовать хранение на основе ключей, а не использование грубого хранения на основе времени.
Дополнительные сведения о сжатиях журналов см. в разделе "Сжатие журналов".
Стандартные задачи потребителя
Все потребители Центров событий подключаются через двунаправленный канал связи с поддержкой состояния и сеанса AMQP 1.0. Каждая секция связана с сеансом связи AMQP 1.0, что упрощает транспортировку событий, разделенных по секциям.
Подключение к секции
При подключении к секциям часто используется механизм аренды для координации подключения к конкретным секциям для чтения. Таким образом, в каждой секции в группе потребителей может быть только один активный модуль чтения. Назначение контрольных точек, аренда и управление модулями чтения упрощаются благодаря использованию клиентов в пакетах SDK для Центров событий, которые действуют как интеллектуальные агенты объекта-получателя. В их число входят:
- EventProcessorClient для .NET
- EventProcessorClient для Java
- EventHubConsumerClient для Python
- EventHubConsumerClient для JavaScript/TypeScript
Чтение событий
После открытия сеанса и связи AMQP 1.0 для определенной секции служба Центров событий доставляет события в клиент AMQP 1.0. Этот механизм доставки обеспечивает более высокую пропускную способность и меньшую задержку, чем механизмы извлечения по запросу, такие как HTTP GET. Когда события отправляются клиенту, каждый экземпляр данных событий содержит важные метаданные, такие как смещение и порядковый номер, которые используются для упрощения создания контрольных точек в последовательности событий.
Данные событий
- Смещение
- Порядковый номер
- Текст
- Свойства пользователя
- Свойства системы
Пользователь управляет смещением самостоятельно.
Группы приложений
Группа приложений — это коллекция клиентских приложений, которые подключаются к пространству имен Центров событий, которые совместно используют уникальное условие идентификации, например контекст безопасности — политику общего доступа или идентификатор приложения Microsoft Entra.
Центры событий Azure позволяют задавать такие политики доступа к ресурсам, как политики регулирования для определенной группы приложений, а также управлять потоковой передачей событий (публикацией или получением) между клиентскими приложениями и Центрами событий.
Дополнительные сведения см. в разделе Управление ресурсами для клиентских приложений с помощью групп приложений.
Поддержка Apache Kafka
Поддержка протокола для клиентов Apache Kafka (версии >=1.0) предоставляет конечные точки, позволяющие существующим приложениям Kafka использовать центры событий. Большинство существующих приложений Kafka можно перенастроить, чтобы указать пространство имен вместо сервера начальной загрузки кластера Kafka.
С точки зрения затрат, эксплуатационных усилий и надежности Центры событий Azure — отличная альтернатива развертыванию и эксплуатации собственных кластеров Kafka и Zookeeper, а также предложений Kafka как услуга, не встроенных в Azure.
Помимо получения той же основной функциональности, что и брокер Apache Kafka, вы также получаете доступ к Центры событий Azure функциям, таким как автоматическая пакетная обработка и архивация через сбор событий, автоматическое масштабирование и балансировку, аварийное восстановление, поддержку зоны доступности, поддержку гибкой и безопасной сетевой интеграции, а также поддержку нескольких протоколов, включая протокол AMQP-over-WebSockets.
Протоколы
Производители или отправители могут использовать протоколы advanced Messaging Queuing (AMQP), Kafka или HTTPS для отправки событий в концентратор событий.
Потребители или получатели используют AMQP или Kafka для получения событий из концентратора событий. Центры событий поддерживают только модель извлечения для потребителей, получая от нее события. Даже если обработчики событий используются для обработки событий из концентратора событий, обработчик событий внутренне использует модель извлечения для получения событий из концентратора событий.
AMQP
Протокол AMQP 1.0 можно использовать для отправки событий в Центры событий Azure и получения событий. AMQP обеспечивает надежную, исполнительную и безопасную связь как для отправки, так и для получения событий. Его можно использовать для высокопроизводительной и потоковой передачи в режиме реального времени и поддерживается большинством Центры событий Azure пакетов SDK.
HTTPS/REST API
События можно отправлять только в Центры событий с помощью HTTP-запросов POST. Центры событий не поддерживают получение событий по протоколу HTTPS. Он подходит для упрощенных клиентов, где прямое TCP-подключение невозможно.
Apache Kafka
Центры событий Azure имеет встроенную конечную точку Kafka, которая поддерживает производителей и потребителей Kafka. Приложения, созданные с помощью Kafka, могут использовать протокол Kafka (версия 1.0 или более поздней версии) для отправки и получения событий из Центров событий без каких-либо изменений кода.
Пакеты SDK Azure абстрагируют базовые протоколы связи и предоставляют упрощенный способ отправки и получения событий из Центров событий с помощью таких языков, как C#, Java, Python, JavaScript и т. д.
Следующие шаги
Дополнительные сведения о Центрах событий см. по следующим ссылкам:
- Начало работы с Центрами событий