Высокий уровень доступности (надежность) в База данных Azure для PostgreSQL — гибкий сервер
ОБЛАСТЬ ПРИМЕНЕНИЯ:  База данных Azure для PostgreSQL — гибкий сервер
База данных Azure для PostgreSQL — гибкий сервер
В этой статье описывается высокий уровень доступности в База данных Azure для PostgreSQL — гибкий сервер, включающий зоны доступности и восстановление между регионами и непрерывность бизнес-процессов. Более подробный обзор надежности в Azure см. в статье "Надежность Azure".
База данных Azure для PostgreSQL. Гибкий сервер обеспечивает поддержку высокой доступности путем подготовки физически разделенных первичных и резервных реплик в пределах одной зоны доступности (зональной) или между зонами доступности (избыточной между зонами). Эта модель высокой доступности предназначена для обеспечения того, чтобы зафиксированные данные никогда не терялись в случае сбоев. Модель также разработана таким образом, чтобы база данных не стала единственной точкой сбоя в архитектуре программного обеспечения. Дополнительные сведения о поддержке высокого уровня доступности и зоны доступности см. в разделе "Поддержка зоны доступности".
Поддержка зоны доступности
Зоны доступности Azure — это по крайней мере три физически отдельные группы центров обработки данных в каждом регионе Azure. Центры обработки данных в каждой зоне оснащены независимой питанием, охлаждения и сетевой инфраструктурой. В случае сбоя локальной зоны зоны зоны создаются таким образом, чтобы при возникновении влияния одной зоны, региональных служб, емкости и высокой доступности поддерживались остальными двумя зонами.
Сбои могут варьироваться от сбоев программного обеспечения и оборудования до таких событий, как землетрясения, наводнения и пожары. Устойчивость к сбоям достигается с избыточностью и логической изоляцией служб Azure. Дополнительные сведения о зонах доступности в Azure см. в разделе "Регионы и зоны доступности".
Службы с поддержкой зон доступности Azure предназначены для обеспечения правильного уровня надежности и гибкости. Их можно настроить двумя способами. Они могут быть избыточными по зонам с автоматической репликацией между зонами или зональными экземплярами, закрепленными в определенной зоне. Эти подходы также можно объединить. Дополнительные сведения об зональной архитектуре, избыточной между зонами, см . в рекомендациях по использованию зональных зон и регионов.
База данных Azure для PostgreSQL . Гибкий сервер поддерживает как избыточные по зонам, так и зональные модели для конфигураций высокой доступности. Обе конфигурации высокой доступности обеспечивают автоматическую отработку отказа с нулевой потерей данных во время запланированных и незапланированных событий.
Избыточность между зонами. Высокий уровень доступности избыточности зоны развертывает резервную реплику в другой зоне с возможностью автоматической отработки отказа. Избыточность зоны обеспечивает высокий уровень доступности, но требуется настроить избыточность приложений в зонах. По этой причине выберите избыточность зоны, если требуется защита от сбоев уровня зоны доступности и когда задержка между зонами доступности допустима.
Вы можете выбрать регион и зоны доступности для основных и резервных серверов. Резервный сервер реплики подготавливается в выбранной зоне доступности в том же регионе с аналогичной конфигурацией вычислений, хранилища и сети в качестве основного сервера. Файлы данных и файлы журналов транзакций (журналы перед записью, a.a WAL) хранятся в локально избыточном хранилище (LRS) в каждой зоне доступности, автоматически сохраняя три копии данных. Конфигурация с избыточностью между зонами обеспечивает физическую изоляцию всего стека между основными и резервными серверами.
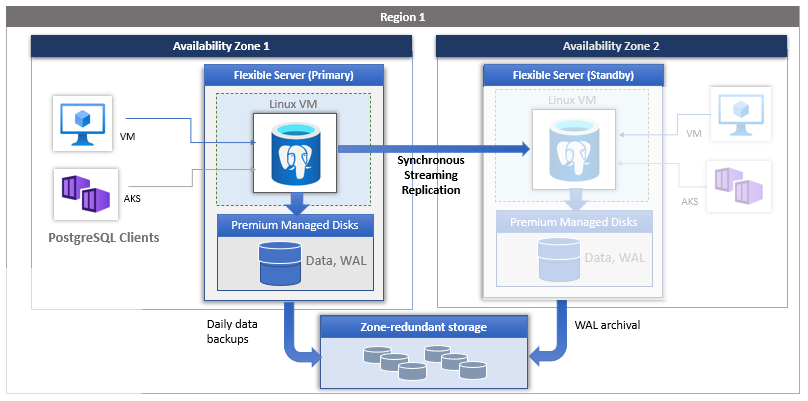
Зональный. Выберите зональное развертывание, если вы хотите достичь самого высокого уровня доступности в пределах одной зоны доступности, но с наименьшей задержкой сети. Вы можете выбрать регион и зону доступности, чтобы развернуть оба сервера базы данных-источника. Резервный сервер реплики автоматически подготавливается и управляется в той же зоне доступности с аналогичной вычислительной, хранилищем и конфигурацией сети в качестве основного сервера. Зональная конфигурация защищает базы данных от сбоев на уровне узла, а также помогает сократить время простоя приложения во время запланированных и незапланированных событий простоя. Данные с первичного сервера реплицируются на резервную реплику в синхронном режиме. В случае нарушения работы основного сервера происходит автоматическое переключение сервера на резервную реплику.



Примечание.
Модели зонального и избыточного между зонами развертывания ведут себя одинаково. Различные обсуждения в следующих разделах применяются к обоим, если не было вызвано в противном случае.
Необходимые компоненты
Избыточность в пределах зоны.
Параметр избыточности зоны доступен только в регионах, поддерживающих зоны доступности.
Избыточность между зонами не поддерживается для:
- База данных Azure для PostgreSQL — номер SKU одного сервера.
- Ресурсоемкие вычислительные уровни.
- Регионы с доступностью в одной зоне.
Зональный:
- Параметр зонального развертывания доступен во всех регионах Azure, где можно развернуть гибкий сервер.
Возможности обеспечения высокой доступности
Резервная реплика развертывается в той же конфигурации виртуальной машины, включая виртуальные ядра, хранилище, параметры сети как основной сервер.
Вы можете добавить поддержку зоны доступности для существующего сервера базы данных.
Вы можете удалить резервную реплику, отключив высокий уровень доступности.
Вы можете выбрать зоны доступности для серверов основной и резервной базы данных для доступности, избыточной между зонами.
Некоторые операции, например остановку, запуск и перезапуск, выполняют одновременно и на главном, и на резервном серверах базы данных.
В избыточных зонах и зональных моделях автоматические резервные копии выполняются периодически с сервера базы данных-источника. В то же время журналы транзакций постоянно архивируются в хранилище резервных копий из резервной реплики. Если регион поддерживает зоны доступности, данные резервного копирования хранятся в хранилище, избыточном между зонами (ZRS). В регионах, не поддерживающих зоны доступности, данные резервного копирования хранятся в локальном избыточном хранилище (LRS).
Клиенты всегда подключаются к конечному имени узла сервера базы данных-источника.
Все изменения параметров сервера также применяются к резервной реплике.
Возможность перезапуска сервера для сбора всех изменений статических параметров сервера.
Периодические действия обслуживания, такие как незначительные обновления версий, выполняются в резервном режиме и, чтобы сократить время простоя, резервный режим повышается до первичного уровня, чтобы рабочие нагрузки могли продолжаться, а задачи обслуживания применяются на оставшемся узле.
Мониторинг работоспособности высокой доступности
Мониторинг состояния работоспособности высокого уровня доступности в База данных Azure для PostgreSQL . Гибкий сервер предоставляет непрерывный обзор работоспособности и готовности экземпляров с поддержкой высокой доступности. Эта функция мониторинга использует платформу проверки Работоспособность ресурсов Azure (RHC) для обнаружения и оповещения о любых проблемах, которые могут повлиять на готовность к отработке отказа базы данных или общую доступность. Оценивая ключевые метрики, такие как состояние подключения, состояние отработки отказа и работоспособность репликации данных, мониторинг состояния работоспособности высокой доступности обеспечивает упреждающее устранение неполадок и помогает поддерживать время и производительность базы данных.
Клиенты могут использовать мониторинг состояния работоспособности высокой доступности для:
- Получите аналитические сведения о работоспособности основных и резервных реплик в режиме реального времени с индикаторами состояния, которые показывают потенциальные проблемы, такие как снижение производительности или блокировка сети.
- Настройте оповещения для своевременного уведомления о любых изменениях состояния высокого уровня доступности, обеспечивая немедленное действие по устранению потенциальных нарушений.
- Оптимизируйте готовность отработки отказа, определяя и устраняя проблемы, прежде чем они влияют на операции базы данных.
Подробное руководство по настройке и интерпретации состояний работоспособности высокой доступности см. в основной статье о мониторинге состояния работоспособности высокого уровня доступности для База данных Azure для PostgreSQL — гибкий сервер.
Ограничения высокого уровня доступности
Из-за синхронной репликации с резервным сервером, особенно с конфигурацией, избыточной по зонам, приложения могут испытывать повышенные задержки записи и фиксации.
Резервную реплику нельзя использовать для запросов чтения.
В зависимости от рабочей нагрузки и действий на основном сервере процесс отработки отказа может занять более 120 секунд из-за восстановления, связанного с резервной репликой, прежде чем его можно будет повысить.
Резервный сервер обычно восстанавливает ФАЙЛЫ WAL в 40 МБ/с. Если ваша рабочая нагрузка превышает это ограничение, можно столкнуться с длительным временем завершения восстановления во время отработки отказа или после установки нового резервного копирования.
Настройка зон доступности вызывает некоторую задержку для операций записи и фиксаций, в то время как она не оказывает никакого влияния на чтение запросов. Влияние на производительность зависит от рабочей нагрузки. Как правило, влияние на операции записи и фиксации может составлять около 20–30 %.
Перезапуск сервера базы данных-источника также перезапускает резервную реплику.
Настройка дополнительного резервного копирования не поддерживается.
Настройка задач управления, инициированных клиентом, не может быть запланирована во время управляемого периода обслуживания.
Запланированные события, такие как масштабирование вычислений и хранилище масштабирования, происходят сначала в резервном режиме, а затем на основном сервере. В настоящее время сервер не выполняет отработку отказа для этих запланированных операций.
Если логическая декодирование или логическая репликация настроена с помощью гибкого сервера, настроенного на доступность, в случае отработки отказа на резервный сервер логические слоты репликации не копируются на резервный сервер. Чтобы поддерживать слоты логической репликации и обеспечить согласованность данных после отработки отказа, рекомендуется использовать расширение слотов отработки отказа PG. Дополнительные сведения о включении этого расширения см . в документации.
Настройка зон доступности между частной (виртуальной сетью) и общедоступным доступом с частными конечными точками не поддерживается. Необходимо настроить зоны доступности в виртуальной сети (охватываемые между зонами доступности в пределах региона) или общедоступный доступ с частными конечными точками.
Зоны доступности настраиваются только в одном регионе. Зоны доступности не могут быть настроены в разных регионах.
SLA
Зональная модель предлагает соглашение об уровне обслуживания от 99,95%.
Модель избыточности между зонами обеспечивает соглашение об уровне обслуживания от 99,99%.
Создание База данных Azure для PostgreSQL — гибкий сервер с включенной зоной доступности
Сведения о создании гибкого сервера База данных Azure для PostgreSQL для обеспечения высокой доступности с зонами доступности см. в кратком руководстве по созданию гибкого сервера База данных Azure для PostgreSQL в портал Azure.
Развертывание и миграция зон доступности
Сведения о включении или отключении конфигурации высокой доступности на гибком сервере в моделях избыточного между зонами и зонального развертывания см. в статье "Управление высокой доступностью на гибком сервере".
Компоненты и рабочие процессы высокого уровня доступности
Выполнение транзакций
Операции записи и фиксации, активированные приложением, сначала регистрируются в WAL на первичном сервере. Затем они передаются на резервный сервер с помощью протокола потоковой передачи Postgres. После сохранения журналов в резервном хранилище сервера основной сервер будет подтвержден для завершения записи. Только после этого приложение подтверждает фиксацию своей транзакции. Этот дополнительный круговой путь повышает задержку в приложении. Процент влияния зависит от приложения. Этот процесс подтверждения не ожидает применения журналов к резервному серверу. Резервный сервер постоянно находится в режиме восстановления, пока он не будет повышен.
Проверка работоспособности
Гибкий мониторинг работоспособности сервера периодически проверяет как основное, так и резервное состояние работоспособности. Если мониторинг работоспособности обнаруживает, что первичный сервер недоступен, служба инициирует автоматическую отработку отказа на резервный сервер. Алгоритм мониторинга работоспособности основан на нескольких точках данных, чтобы избежать ложных положительных ситуаций.
Режимы отработки отказа
Гибкий сервер поддерживает два режима отработки отказа, плановую отработку отказа и отмену плановая отработка отказа. В обоих режимах после того, как репликация будет удалена, резервный сервер запускает восстановление, прежде чем продвигаться в качестве основного и открывается для чтения и записи. При обновлении автоматических записей DNS с помощью новой конечной точки сервера-источника приложения могут подключаться к серверу с помощью той же конечной точки. Новый резервный сервер устанавливается в фоновом режиме, чтобы приложение может поддерживать подключение.
Статус высокой доступности
Работоспособность первичных и резервных серверов постоянно отслеживается, и для устранения проблем выполняются соответствующие действия, включая активацию отработки отказа на резервный сервер. В таблице ниже перечислены возможные состояния высокого уровня доступности:
| Состояние | Description |
|---|---|
| Инициализации | В процессе создания нового резервного сервера |
| Репликация данных | После создания резервного копирования он догоняет основной. |
| Работоспособен | Репликация находится в стабильном и работоспособном состоянии. |
| Отработка отказа | Сервер базы данных находится в процессе отработки отказа с переходом на резервный сервер. |
| Удаление резервного режима | В процессе удаления резервного сервера. |
| Не включено | Высокий уровень доступности не включен. |
Примечание.
Включить высокий уровень доступности можно в процессе создания сервера или позже. Если вы включаете или отключите высокий уровень доступности на этапе после создания, то рекомендуется работать при низком уровне активности сервера-источника.
Операции в устойчивом состоянии
Клиентские приложения PostgreSQL подключены к главному серверу, при использовании имени сервера базы данных. Операции чтения приложений выполняются непосредственно с первичного сервера. В то же время фиксации и записи подтверждаются в приложение только после сохранения данных журнала на основном сервере и резервной реплике. Из-за этого дополнительного кругового пути приложения могут ожидать повышенную задержку для операций записи и фиксации. Состояние высокого уровня доступности можно отслеживать на портале.

- Клиенты подключаются к гибкому серверу и выполняют операции записи.
- Изменения реплицируются на резервный сайт.
- Первичный получает подтверждение.
- Подтверждаются операции записи и фиксации.
Восстановление серверов высокой доступности на определенный момент времени
Для гибких серверов, настроенных с высокой доступностью, данные журнала реплицируются в режиме реального времени на резервный сервер. Все ошибки пользователя на основном сервере, например случайное падение таблицы или неправильные обновления данных, реплицируются в резервную реплику. Таким образом, вы не можете использовать резервный режим для восстановления после таких логических ошибок. Чтобы восстановиться после таких ошибок, необходимо выполнить восстановление на определенный момент времени из резервной копии. С помощью возможности восстановления на определенный момент времени гибкого сервера можно восстановить время до возникновения ошибки. Новый сервер базы данных восстанавливается как гибкий сервер с одной зоной с новым именем сервера, предоставленным пользователем, для баз данных, настроенных с высоким уровнем доступности. Для нескольких вариантов использования можно использовать восстановленный сервер:
Восстановленный сервер можно использовать для рабочей среды и при необходимости включить высокий уровень доступности с резервной репликой в той же зоне или другой зоне в том же регионе.
Если вы хотите восстановить объект, экспортируйте его с восстановленного сервера базы данных и импортируйте его на рабочий сервер базы данных.
Если вы хотите клонировать сервер базы данных для тестирования и разработки или восстановления для любых других целей, можно выполнить восстановление на определенный момент времени.
Сведения о восстановлении гибкого сервера на определенный момент времени см. в статье "Восстановление гибкого сервера на определенный момент времени".
Поддержка отработки отказа
Плановая отработка отказа
Запланированные события простоев включают запланированные периодические обновления программного обеспечения Azure и небольшие обновления версии. Вы также можете использовать плановая отработка отказа для возврата первичного сервера в предпочтительную зону доступности. При настройке в режиме высокой доступности эти операции сначала применяются к резервной реплике, а приложения продолжают получать доступ к главному серверу. После обновления резервной реплики подключения сервера-источника удаляются и активируется отработка отказа, которая активирует резервную реплику в качестве источника с тем же именем сервера базы данных. Клиентские приложения должны повторно подключиться с тем же именем сервера базы данных к новому основному серверу и возобновить свои операции. Новый резервный сервер устанавливается в той же зоне, что и старый основной сервер.
Для других операций, инициируемых пользователем, таких как масштабирование вычислений или масштабирование хранилища, изменения применяются сначала в резервном режиме, а затем основной. В настоящее время служба не выполняет отработку отказа на резервный сервер, в то время как операция масштабирования переносится на главный сервер, и приложение будет простаивать в течение небольшого периода времени.
Эту функцию можно также использовать для отработки отказа на резервный сервер с меньшим временем простоя. Например, основной объект может находиться в другой зоне доступности, отличной от приложения, после отмены плановая отработка отказа. Вы хотите вернуть основной сервер в предыдущую зону, чтобы выполнить колотек с приложением.
При выполнении этой функции резервный сервер сначала готов, чтобы убедиться, что он догоняет последние транзакции, позволяя приложению продолжать выполнять операции чтения и записи. Затем резервный режим повышается, а подключения к основному — отрезаны. Пока в фоновом режиме будет создаваться новый резервный сервер, ваше приложение сможет продолжить записывать данные на главный сервер. Ниже приведены действия, связанные с плановая отработка отказа.
| Step | Description | Ожидается ли простой приложений? |
|---|---|---|
| 1 | Подождите, пока резервный сервер поймал основной сервер. | No |
| 2 | Внутренняя система мониторинга инициирует рабочий процесс отработки отказа. | No |
| 3 | Записи приложений блокируются, когда резервный сервер близок к основному номеру последовательности журналов (LSN). | Да |
| 4 | Уровень резервного сервера повышен до независимого сервера. | Да |
| 5 | Запись DNS обновлена, и в ней указан IP-адрес нового резервного сервера. | Да |
| 6 | Приложение для повторного подключения и возобновления чтения и записи с новым основным. | No |
| 7 | Создан новый резервный сервер в другой зоне. | No |
| 8 | Резервный сервер начинает восстанавливать журналы (из БОЛЬШОго двоичного объекта Azure), пропущенные во время его создания. | No |
| 9 | Устанавливается устойчивое состояние между основным и резервным сервером. | No |
| 10 | Процесс плановой отработки отказа завершен. | No |
Простой приложения начинается на действии 3. Приложение может возобновить работу после действия 5. Остальные действия выполняются в фоновом режиме, не затрагивая записи и фиксации приложения.
Совет
С гибким сервером вы можете при необходимости запланировать действия обслуживания, инициированные Azure, выбрав 60-минутное окно в день вашего предпочтения, где действия в базах данных, как ожидается, будут низкими. Во время этого окна будут выполнены задачи по обслуживанию Azure, например обновление путем частичной замены или незначительное обновление версий. Если вы не выбираете настраиваемое окно, для сервера выбрано 1-часовое окно, выделенное 11 часов — 7 утра локального времени. Эти действия обслуживания, инициированные Azure, также выполняются на резервной реплике для гибких серверов, настроенных с зонами доступности.
Список возможных запланированных событий простоя см. в разделе "Запланированные события простоя".
Внеплановая отработка отказа
Незапланированные простои могут возникать в результате непредвиденных сбоев, таких как отказ основного оборудования, проблемы с сетью и ошибки программного обеспечения. Если сервер базы данных, настроенный для обеспечения высокой доступности, неожиданно выходит из строя, то активируется резервная реплика, и клиенты могут возобновить свои операции. Если не настроена высокая доступность (HA), то при неудачной попытке перезапуска автоматически создается новый сервер базы данных. Хотя незапланированное время простоя нельзя избежать, гибкий сервер помогает снизить время простоя, автоматически выполняя операции восстановления без вмешательства человека.
Сведения об отмене плановая отработка отказа и простое, включая возможные сценарии, см. в разделе "Внеплановая защита от простоя".
Тесты отработки отказа (принудительное отработка отказа)
При принудительной отработке отказа можно имитировать незапланированный сценарий сбоя при выполнении рабочей нагрузки и наблюдать за временем простоя приложения. Вы также можете использовать принудительную отработку отказа, когда основной сервер не отвечает.
Принудительная отработка отказа приводит к понижению первичного сервера и инициирует рабочий процесс отработки отказа, в котором выполняется операция резервного повышения уровня. После завершения резервного процесса восстановления до последнего зафиксированного данных он будет повышен до основного сервера. Записи DNS обновляются, и приложение может подключаться к продвинутому основному серверу. Приложение может продолжать записывать данные в основной сервер, пока новый резервный сервер установлен в фоновом режиме, что не влияет на время простоя.
Ниже приведены шаги во время принудительной отработки отказа.
| Step | Description | Ожидается ли простой приложений? |
|---|---|---|
| 1 | Сервер-источник останавливается вскоре после получения запроса отработки отказа. | Да |
| 2 | Так как главный сервер не работает, приложение простаивает. | Да |
| 3 | Внутренняя система мониторинга обнаруживает сбой и инициирует отработку отказа на резервный сервер. | Да |
| 4 | Резервный сервер переходит в режим восстановления до того момента, пока его уровень не будет повышен до независимого сервера. | Да |
| 5 | Процесс отработки отказа ожидает завершения операции восстановления резервного сервера. | Да |
| 6 | После завершения работы сервера запись DNS обновляется с тем же именем узла, но с помощью IP-адреса резервного сервера. | Да |
| 7 | Приложение может повторно подключиться к новому главному серверу и возобновить свою работу. | No |
| 8 | Создан резервный сервер в предпочтительной зоне. | No |
| 9 | Резервный сервер начинает восстанавливать журналы (из БОЛЬШОго двоичного объекта Azure), пропущенные во время его создания. | No |
| 10 | Устанавливается устойчивое состояние между основным и резервным сервером. | No |
| 11 | Процесс принудительного перехода на другой ресурс завершен. | No |
Простой приложений должен начаться после выполнения действия 1 и продолжаться до завершения действия 6. Остальные действия выполняются в фоновом режиме, не влияя на запись и фиксацию приложения.
Внимание
Сквозной процесс отработки отказа включает (a) отработку отказа на резервный сервер после первичного сбоя и (b) установления нового резервного сервера в устойчивом состоянии. По мере завершения отработки отказа в резервный режим приложение измеряет время простоя с точки зрения приложения или клиента, а не общий сквозной процесс отработки отказа.
Рекомендации при выполнении принудительной отработки отказа
Общее время сквозной операции можно рассматривать как более длинное, чем фактическое время простоя, которое испытывает приложение.
Внимание
Всегда следите за временем простоя с точки зрения приложения!
Не выполняйте немедленные обратные отработки отказа. Подождите по крайней мере 15–20 минут между отработками отказа, что позволяет полностью установить новый резервный сервер.
Рекомендуется выполнить принудительное отработка отказа во время низкой активности, чтобы сократить время простоя.
Рекомендации по статистике PostgreSQL после отработки отказа
После отработки отказа PostgreSQL основной механизм обеспечения оптимальной производительности базы данных включает понимание различных ролей pg_statistic и таблиц pg_stat_* . Таблица pg_statistic содержит статистику оптимизатора, которая имеет решающее значение для планировщика запросов. Эти статистические данные включают распределение данных в таблицах и остаются неизменными после отработки отказа, гарантируя, что планировщик запросов сможет эффективно оптимизировать выполнение запросов на основе точных, исторических сведений о распределении данных.
В отличие от этого, pg_stat_* таблицы, которые записывают статистику действий, такие как количество проверок, кортежей чтения и обновлений, сбрасываются при отработке отказа. Примером такой таблицы является pg_stat_user_tablesотслеживание действий для определяемых пользователем таблиц. Этот сброс предназначен для точного отражения рабочего состояния нового первичного источника, но также означает потерю метрик исторической активности, которые могут информировать процесс автовакуума и другие операционные эффективность.
Учитывая это различие, рекомендуется выполнить ANALYZEотработку отказа PostgreSQL. Это действие обновляет таблицы, такие как pg_stat_user_tablesсвежие pg_stat_* статистические данные о действиях, помогая процессу автовакуума и обеспечивая оптимальную производительность базы данных в новой роли. Этот упреждающий шаг связывает разрыв между сохранением важной статистики оптимизатора и обновлением метрик действий для выравнивания текущего состояния базы данных.
Взаимодействие с зонами вниз
Зональный: чтобы восстановиться после сбоя уровня зоны, можно выполнить восстановление на определенный момент времени с помощью резервной копии. Можно выбрать пользовательскую точку восстановления с последним временем для восстановления последних данных. Новый гибкий сервер развертывается в другой небезопасной зоне. Время, необходимое для восстановления, зависит от предыдущей резервной копии и объема восстанавливаемых журналов транзакций.
Дополнительные сведения о восстановлении на определенный момент времени см. в статье "Резервное копирование и восстановление" на База данных Azure для PostgreSQL гибком сервере.
Избыточность зоны. Гибкий сервер автоматически выполняет отработку отказа на резервный сервер в течение 60–120 секунд с нулевой потерей данных.
Конфигурации без зон доступности
Хотя это не рекомендуется, можно настроить гибкий сервер без включения высокой доступности. Для гибких серверов, настроенных без высокой доступности, служба предоставляет локальное избыточное хранилище с тремя копиями данных, резервной копией, избыточной между зонами (в регионах, где она поддерживается), и встроенной устойчивостью сервера для автоматического перезапуска аварийного сервера и перемещения сервера на другой физический узел. Соглашение об уровне обслуживания от 99,9% предоставляется в этой конфигурации. Во время запланированных или незапланированных событий плановая отработка отказа, если сервер выходит из строя, служба сохраняет доступность серверов с помощью следующей автоматизированной процедуры:
- Будет подготовлена новая виртуальная машина Linux для вычислений.
- Хранилище с файлами данных сопоставляется с новой виртуальной машиной.
- Ядро СУБД PostgreSQL подключено к сети на новой виртуальной машине.
На рисунке ниже показан переход между виртуальной машиной и сбоем хранилища.

Аварийное восстановление между регионами и непрерывность бизнес-процессов
В случае аварии на уровне региона Azure может обеспечить защиту от региональных или крупных географических аварий с аварийного восстановления, используя другой регион. Дополнительные сведения об архитектуре аварийного восстановления Azure см . в azure для архитектуры аварийного восстановления Azure.
Гибкий сервер предоставляет функции, которые защищают данные и устраняют простой для критически важных баз данных во время запланированных и незапланированных событий простоя. На основе инфраструктуры Azure, которая обеспечивает надежную устойчивость и доступность, гибкий сервер предлагает функции непрерывности бизнес-процессов, обеспечивающие защиту от сбоев, требования к времени восстановления и снижение риска потери данных. При разработке приложений следует учитывать допустимость простоя — цель времени восстановления (RTO) и потери данных — цель точки восстановления (RPO). Например, для базы данных, критически важной для бизнеса, требуется более строгое время простоя, чем тестовая база данных.
Аварийное восстановление в географическом регионе с несколькими регионами
Геоизбыточное резервное копирование и восстановление
Геоизбыточное резервное копирование и восстановление обеспечивают возможность восстановления сервера в другом регионе в случае аварии. Это также обеспечивает устойчивость объектов резервного копирования как минимум на 99,99999999999999 % (16 девяток) в течение заданного года.
Геоизбыточное резервное копирование можно настроить только во время создания сервера. Если на сервере настроено геоизбыточное резервное копирование, данные резервного копирования и журналы транзакций копируются в парный регион в асинхронном режиме через репликацию хранилища.
Дополнительные сведения о геоизбыточного резервного копирования и восстановлении см. в разделе геоизбыточное резервное копирование и восстановление.
Реплики чтения
Межрегионные реплики чтения можно развернуть для защиты баз данных от сбоев на уровне региона. Реплики чтения обновляются асинхронно с помощью технологии физической репликации PostgreSQL и могут отстать от основного. Реплики чтения поддерживаются в уровнях вычислений, оптимизированных для общего назначения и памяти.
Дополнительные сведения о функциях и рекомендациях по реплике чтения см. в разделе "Реплики чтения".
Обнаружение сбоев, уведомление и управление
Если на сервере настроено геоизбыточное резервное копирование, можно выполнить геовосстановление в парном регионе. Новый сервер подготавливается и восстанавливается до последних доступных данных, скопированных в этот регион.
Можно также использовать реплики чтения между регионами. В случае сбоя региона можно выполнить операцию аварийного восстановления, продвигая реплика чтения в качестве автономного сервера для чтения. Ожидается, что RPO составляет до 5 минут (возможна потеря данных), за исключением случаев серьезного регионального сбоя, когда RPO может быть близок к задержке репликации во время сбоя.
Дополнительные сведения о незапланированном устранении простоя и восстановлении после региональной аварии см. в разделе "Внеплановая защита от простоя".