Примечание.
Для доступа к этой странице требуется авторизация. Вы можете попробовать войти или изменить каталоги.
Для доступа к этой странице требуется авторизация. Вы можете попробовать изменить каталоги.
В этом руководстве вы узнаете, как выполнять анализ аналитических данных с помощью существующих открытых наборов данных без необходимости настройки хранилища. Вы научитесь объединять различные Открытые наборы данных Azure с помощью бессерверного пула SQL. Затем вы сможете визуализировать результаты в Synapse Studio для Azure Synapse Analytics.
Изучив это руководство, вы:
- Доступ к встроенному бессерверному пулу SQL
- Доступ к открытым наборам данных Azure для использования данных руководства
- Выполнение базового анализа данных с помощью SQL
Доступ к бессерверному пулу SQL
Каждая рабочая область поставляется с предварительно настроенным бессерверным пулом SQL для использования, который называется Built-in. Чтобы получить доступ к нему, выполните приведенные далее действия.
- Откройте рабочую область и выберите центр разработки.
- Нажмите кнопку +"Добавить новый ресурс ".
- Выберите Сценарий SQL.
Этот скрипт можно использовать для изучения данных без необходимости резервировать емкость SQL.
Если у вас нет подписки Azure, создайте бесплатную учетную запись, прежде чем приступить к работе.
Доступ к данным руководства
Все данные, которые мы используем в этом руководстве, хранятся в учетной записи хранения данных azureopendatastorage, которая содержит наборы данных Azure Open Datasets для открытого использования в таких руководствах, как это. Все скрипты можно запускать непосредственно из рабочей области, пока ваша рабочая область может получить доступ к общедоступной сети.
В этом руководстве используется набор данных о такси Нью-Йорка:
- Даты и время посадки и высадки пассажиров
- Пункты посадки и высадки
- Расстояния поездок
- Детализированные пассажирские тарифы
- Виды тарифов
- Типы платежей
- Отчеты водителей о количестве пассажиров
Функция OPENROWSET(BULK...) позволяет получить доступ к файлам в службе хранилища Azure.
[OPENROWSET](develop-openrowset.md) считывает содержимое удаленного источника данных (например, файла) и возвращает содержимое в виде набора строк.
Чтобы ознакомиться с данными о такси Нью-Йорка, выполните следующий запрос:
SELECT TOP 100 * FROM
OPENROWSET(
BULK 'https://azureopendatastorage.blob.core.windows.net/nyctlc/yellow/puYear=*/puMonth=*/*.parquet',
FORMAT='PARQUET'
) AS [nyc]
Другие доступные наборы данных
Аналогичным образом можно запросить набор данных о государственных праздниках:
SELECT TOP 100 * FROM
OPENROWSET(
BULK 'https://azureopendatastorage.blob.core.windows.net/holidaydatacontainer/Processed/*.parquet',
FORMAT='PARQUET'
) AS [holidays]
Также можно запросить набор данных о погоде, выполнив следующий запрос:
SELECT
TOP 100 *
FROM
OPENROWSET(
BULK 'https://azureopendatastorage.blob.core.windows.net/isdweatherdatacontainer/ISDWeather/year=*/month=*/*.parquet',
FORMAT='PARQUET'
) AS [weather]
Вы можете получить дополнительные сведения о значении отдельных столбцов в описаниях наборов данных:
Автоматический вывод схемы
Так как данные хранятся в формате файла Parquet, доступно автоматическое вывод схемы. Таким образом, вы можете запрашивать информацию без перечисления типов данных для всех столбцов в файлах. Кроме того, вы можете отфильтровать определенное подмножество файлов, используя механизм виртуальных столбцов и функцию filepath.
Примечание.
Параметры сортировки по умолчанию — SQL_Latin1_General_CP1_CI_ASIf. Для сортировки, отличной от по умолчанию, учитывайте чувствительность к регистру.
При создании базы данных с учетом регистра при указании столбцов обязательно используйте правильное имя столбца.
Например, имя столбца tpepPickupDateTime будет правильным, а имя столбца tpeppickupdatetime не будет работать с параметрами сортировки, отличными от параметров по умолчанию.
Анализ временных рядов, сезонности и анализ выбросов
Ежегодное количество поездок на такси можно подсчитать с помощью следующего запроса:
SELECT
YEAR(tpepPickupDateTime) AS current_year,
COUNT(*) AS rides_per_year
FROM
OPENROWSET(
BULK 'https://azureopendatastorage.blob.core.windows.net/nyctlc/yellow/puYear=*/puMonth=*/*.parquet',
FORMAT='PARQUET'
) AS [nyc]
WHERE nyc.filepath(1) >= '2009' AND nyc.filepath(1) <= '2019'
GROUP BY YEAR(tpepPickupDateTime)
ORDER BY 1 ASC
Следующий фрагмент показывает результат относительно ежегодного количества поездок на такси:
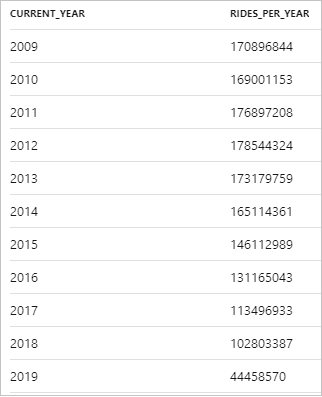
Данные можно визуализировать в Synapse Studio. Для этого переключитесь из представления Таблица в представление Диаграмма. Вы можете выбрать один из различных типов диаграмм, таких как площадная, гистограмма, столбиковая диаграмма, линия, круговая диаграмма и диаграмма рассеяния. В этом случае построим гистограмму, у которой в столбце Категория задано значение current_year (текущий_год):
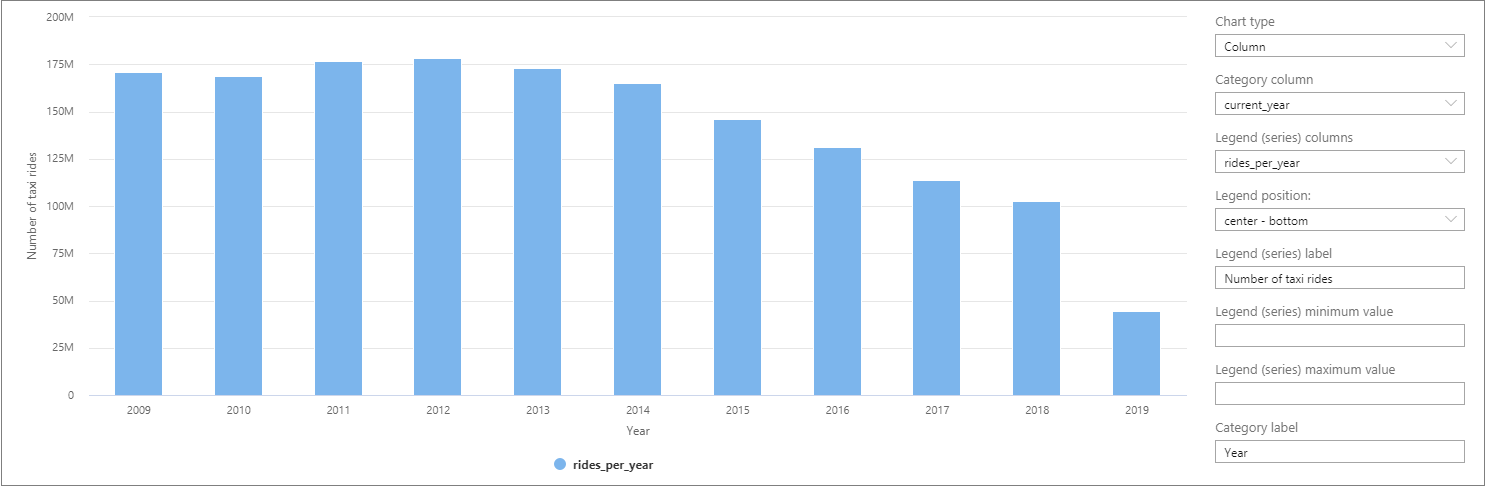
В этой визуализации можно увидеть тенденцию уменьшения числа поездок в течении нескольких лет. Предположительно, причина заключается в недавно возросшей популярности сервисов совместных поездок.
Примечание.
На момент написания этого руководства данные за 2019 год были неполными. В результате, количество поездок в том году существенно сократилось.
Вы можете выполнить анализ для определенного года, например, 2016-го. Следующий запрос возвращает ежедневное количество поездок за тот год.
SELECT
CAST([tpepPickupDateTime] AS DATE) AS [current_day],
COUNT(*) as rides_per_day
FROM
OPENROWSET(
BULK 'https://azureopendatastorage.blob.core.windows.net/nyctlc/yellow/puYear=*/puMonth=*/*.parquet',
FORMAT='PARQUET'
) AS [nyc]
WHERE nyc.filepath(1) = '2016'
GROUP BY CAST([tpepPickupDateTime] AS DATE)
ORDER BY 1 ASC
Следующий фрагмент показывает результат для этого запроса:
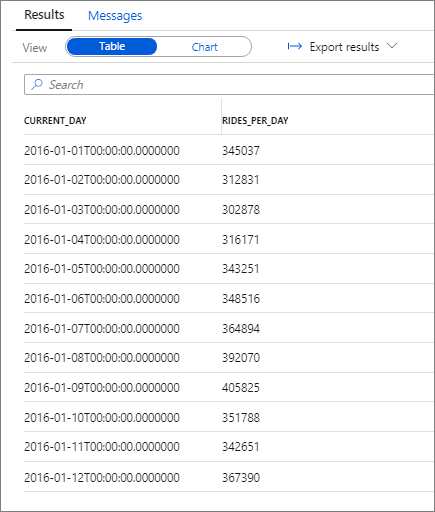
Снова можно визуализировать данные, построив гистограмму с установкой столбца Категория на current_day и столбца Легенда (ряды) на rides_per_day.
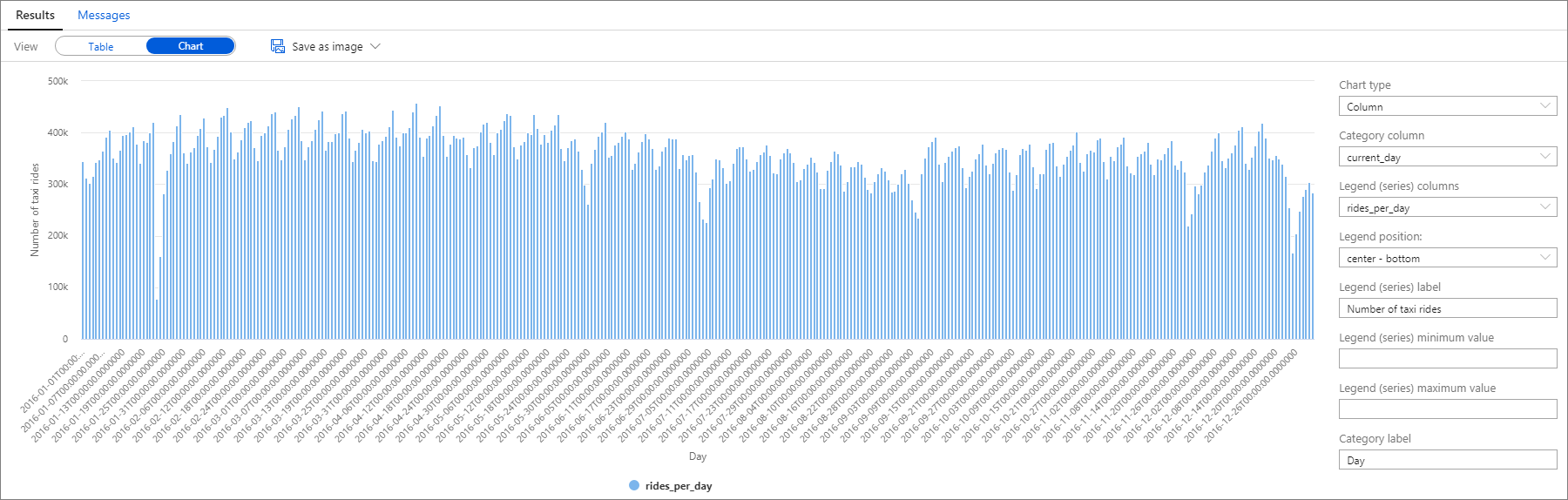
На графике видно, что существует еженедельная закономерность, с пиком в субботу. В летние месяцы количество поездок на такси уменьшается из-за отпусков. Кроме того, обратите внимание на значительные снижения в числе поездок на такси, без четкой связи с тем, когда и почему они происходят.
Теперь посмотрим, коррелирует ли падение количества поездок с государственными праздниками. Чтобы определить наличие корреляции, объединим набор данных о поездках такси Нью-Йорка с набором данных о государственных праздниках:
WITH taxi_rides AS (
SELECT
CAST([tpepPickupDateTime] AS DATE) AS [current_day],
COUNT(*) as rides_per_day
FROM
OPENROWSET(
BULK 'https://azureopendatastorage.blob.core.windows.net/nyctlc/yellow/puYear=*/puMonth=*/*.parquet',
FORMAT='PARQUET'
) AS [nyc]
WHERE nyc.filepath(1) = '2016'
GROUP BY CAST([tpepPickupDateTime] AS DATE)
),
public_holidays AS (
SELECT
holidayname as holiday,
date
FROM
OPENROWSET(
BULK 'https://azureopendatastorage.blob.core.windows.net/holidaydatacontainer/Processed/*.parquet',
FORMAT='PARQUET'
) AS [holidays]
WHERE countryorregion = 'United States' AND YEAR(date) = 2016
),
joined_data AS (
SELECT
*
FROM taxi_rides t
LEFT OUTER JOIN public_holidays p on t.current_day = p.date
)
SELECT
*,
holiday_rides =
CASE
WHEN holiday is null THEN 0
WHEN holiday is not null THEN rides_per_day
END
FROM joined_data
ORDER BY current_day ASC
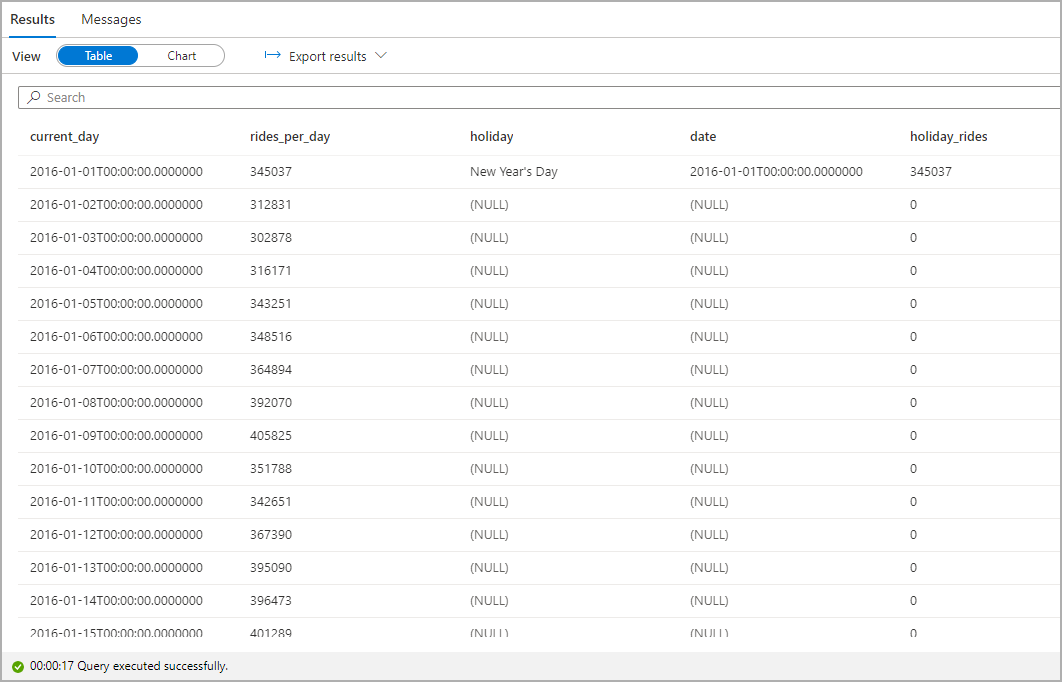
Выделим число поездок на такси в дни государственных праздников. Для этого выберите значение current_day для столбца Категория и rides_per_day и holiday_rides в качестве столбцов Условные обозначения (ряды).
На снимке экрана показано количество поездок на такси во время государственных праздников в виде графика.
По графику видно, что в дни государственных праздников количество поездок на такси уменьшается. Но по-прежнему остается необъясненным огромный спад 23 января. Давайте проверим погоду в Нью-Йорке в этот день, запросив набор данных о погоде:
SELECT
AVG(windspeed) AS avg_windspeed,
MIN(windspeed) AS min_windspeed,
MAX(windspeed) AS max_windspeed,
AVG(temperature) AS avg_temperature,
MIN(temperature) AS min_temperature,
MAX(temperature) AS max_temperature,
AVG(sealvlpressure) AS avg_sealvlpressure,
MIN(sealvlpressure) AS min_sealvlpressure,
MAX(sealvlpressure) AS max_sealvlpressure,
AVG(precipdepth) AS avg_precipdepth,
MIN(precipdepth) AS min_precipdepth,
MAX(precipdepth) AS max_precipdepth,
AVG(snowdepth) AS avg_snowdepth,
MIN(snowdepth) AS min_snowdepth,
MAX(snowdepth) AS max_snowdepth
FROM
OPENROWSET(
BULK 'https://azureopendatastorage.blob.core.windows.net/isdweatherdatacontainer/ISDWeather/year=*/month=*/*.parquet',
FORMAT='PARQUET'
) AS [weather]
WHERE countryorregion = 'US' AND CAST([datetime] AS DATE) = '2016-01-23' AND stationname = 'JOHN F KENNEDY INTERNATIONAL AIRPORT'

Результаты запроса указывают, что уменьшение количества поездок на такси произошло из-за:
- В этот день в Нью-Йорке была метель и выпало много снега (около 30 см).
- Было холодно (ниже нуля по Цельсию).
- Было ветрено (скорость ветра около 10 м/с).
В этом руководстве показано, как специалист по анализу данных может быстро выполнить исследовательский анализ данных. Вы можете объединить различные наборы данных с помощью бессерверного пула SQL и визуализировать результаты с помощью Azure Synapse Studio.
Связанный контент
Узнайте, как подключить бессерверный пул SQL к Power BI Desktop и создавать отчеты.
Сведения об использовании внешних таблиц в бессерверном пуле SQL см. в статье Использование внешних таблиц с Synapse SQL