Заметка
Доступ к этой странице требует авторизации. Вы можете попробовать войти в систему или изменить каталог.
Доступ к этой странице требует авторизации. Вы можете попробовать сменить директорию.
Параметр разбиения по умолчанию элемента управления представления данных не подходит при работе с большими объемами данных, так как его базовый элемент управления источником данных извлекает все записи, даже если отображается только подмножество данных. В таких обстоятельствах необходимо обратиться к пользовательскому разбиению по страницам.
Введение
Как мы обсуждали в предыдущем руководстве, разбиение по страницам можно реализовать одним из двух способов:
- По умолчанию можно реализовать путем простой проверки параметра Enable Paging в смарт-теге веб-элемента управления данными. Однако при просмотре страницы данных ОбъектDataSource извлекает все записи, даже если на странице отображаются только подмножество из них.
- Настраиваемое разбиение по умолчанию повышает производительность разбиения по умолчанию, извлекая только те записи из базы данных, которые должны отображаться для конкретной страницы данных, запрашиваемых пользователем; однако настраиваемое разбиение по страницам включает в себя немного больше усилий по реализации, чем по умолчанию.
Из-за простоты реализации просто установите флажок, и вы сделали это! Разбиение по умолчанию является привлекательным вариантом. Его наивный подход к получению всех записей, однако, делает его неправдоподобным выбором при разбиении на страницы с достаточно большим объемом данных или для сайтов с множеством одновременных пользователей. В таких обстоятельствах необходимо обратиться к пользовательскому разбиению по страницам, чтобы обеспечить адаптивную систему.
Задача пользовательского разбиения на страницы позволяет создавать запрос, возвращающий точный набор записей, необходимых для определенной страницы данных. К счастью, Microsoft SQL Server 2005 предоставляет новое ключевое слово для ранжирования результатов, что позволяет нам создавать запрос, который может эффективно извлекать соответствующие подмножества записей. В этом руководстве мы посмотрим, как использовать это новое ключевое слово SQL Server 2005 для реализации пользовательского разбиения по страницам в элементе управления GridView. Хотя пользовательский интерфейс пользовательского разбиения на страницы идентичен тому, что для разбиения страниц по умолчанию, шаг от одной страницы к следующей, используя настраиваемую страницу, может быть несколько порядков величины быстрее, чем разбиение по умолчанию.
Примечание.
Точное повышение производительности, предоставляемое пользовательским разбиением на страницы, зависит от общего количества записей, которые страницируются, и нагрузки, размещенной на сервере базы данных. В конце этого руководства мы рассмотрим некоторые грубые метрики, демонстрирующие преимущества производительности, полученные с помощью пользовательского разбиения на страницах.
Шаг 1. Общие сведения о пользовательском процессе разбиения по страницам
При разбиении по страницам точные записи, отображаемые на странице, зависят от страницы запрашиваемых данных и количества записей, отображаемых на каждой странице. Например, представьте, что мы хотели бы просмотреть 81 продукты, отображая 10 продуктов на страницу. При просмотре первой страницы мы хотим, чтобы продукты от 1 до 10; при просмотре второй страницы мы будем заинтересованы в продуктах от 11 до 20 и т. д.
Существует три переменные, которые определяют, какие записи необходимо извлечь и как должен отображаться интерфейс разбиения на страницы:
- Запустите индекс строки индекс первой строки на странице данных для отображения; этот индекс можно вычислить, умножив индекс страницы на записи, отображаемые на каждой странице и добавив один. Например, при разбиении по записям 10 за раз на первой странице (индекс страницы 0), начальный индекс строки равен 0 * 10 + 1 или 1; для второй страницы (индекс страницы которого равен 1), начальный индекс строки равен 1 * 10 + 1 или 11.
- Максимальное число строк , отображаемых на каждой странице, максимальное число записей. Эта переменная называется максимальной строкой, так как для последней страницы может быть меньше записей, возвращаемых, чем размер страницы. Например, при разбиении по страницам по 81 продуктам 10 записей на страницу девятая и окончательная страница будет иметь только одну запись. Однако страница не будет отображать больше записей, чем значение "Максимальные строки".
- Общее количество записей , с помощью которых выполняется страница. Хотя эта переменная не требуется для определения записей, извлекаемой для данной страницы, она диктует интерфейс разбиения на страницы. Например, если в пользовательском интерфейсе страницы есть 81 продуктов, то интерфейс разбиения на страницы знает, чтобы отобразить девять номеров страниц в пользовательском интерфейсе.
При разбиении по умолчанию индекс начальной строки вычисляется как продукт индекса страницы и размер страницы плюс один, в то время как максимальные строки — это просто размер страницы. Так как по умолчанию разбиение по умолчанию извлекает все записи из базы данных при отрисовке любой страницы данных, индекс каждой строки известен, тем самым при переходе к строке начального индекса строк тривиальной задачей. Кроме того, общее число записей легко доступно, так как это просто количество записей в DataTable (или любой объект, используемый для хранения результатов базы данных).
Учитывая переменные начального индекса строк и максимальных строк, пользовательская реализация разбиения по страницам должна возвращать только точное подмножество записей, начиная с начального индекса строки и до максимального числа строк записей после этого. Настраиваемое разбиение на страницах обеспечивает две проблемы:
- Мы должны быть в состоянии эффективно связать индекс строки с каждой строкой во всех данных, с помощью которых можно начать возвращать записи по указанному индексу начальной строки.
- Нам нужно предоставить общее количество записей, на которые будут выстраивать страницы.
В следующих двух шагах мы рассмотрим скрипт SQL, необходимый для реагирования на эти две проблемы. Помимо скрипта SQL, нам также потребуется реализовать методы в DAL и BLL.
Шаг 2. Возврат общего количества записей, которые страницируются через
Прежде чем изучить, как получить точное подмножество записей для отображаемой страницы, давайте сначала рассмотрим, как вернуть общее количество записей, с помощью которых выводятся страницы. Эти сведения необходимы для правильной настройки пользовательского интерфейса разбиения по страницам. Общее количество записей, возвращаемых конкретным SQL-запросом, можно получить с помощью агрегатной COUNT функции. Например, чтобы определить общее количество записей в Products таблице, можно использовать следующий запрос:
SELECT COUNT(*)
FROM Products
Давайте добавим метод в наш DAL, который возвращает эти сведения. В частности, мы создадим метод DAL, который TotalNumberOfProducts() выполняет инструкцию, показанную SELECT выше.
Начните с открытия Northwind.xsd файла Typed DataSet в папке App_Code/DAL . Затем щелкните правой кнопкой мыши конструктор ProductsTableAdapter и выберите команду "Добавить запрос". Как мы видели в предыдущих руководствах, это позволит нам добавить новый метод в DAL, который при вызове будет выполнять определенную инструкцию SQL или хранимую процедуру. Как и в наших методах TableAdapter в предыдущих руководствах, для этого можно использовать нерегламентированный оператор SQL.
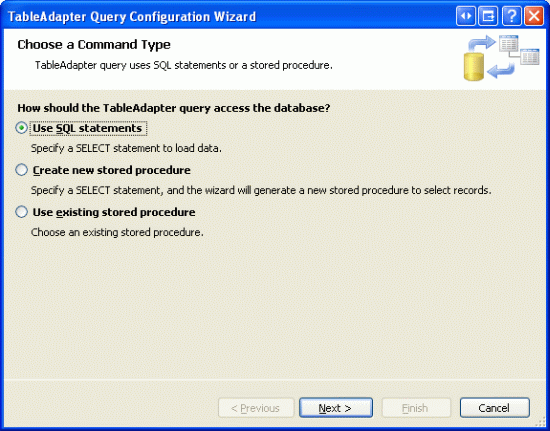
Рис. 1. Использование инструкции AD-Hoc SQL
На следующем экране можно указать тип создаваемого запроса. Так как этот запрос вернет одно скалярное значение общего количества записей в Products таблице, выберите SELECT параметр значения singe.
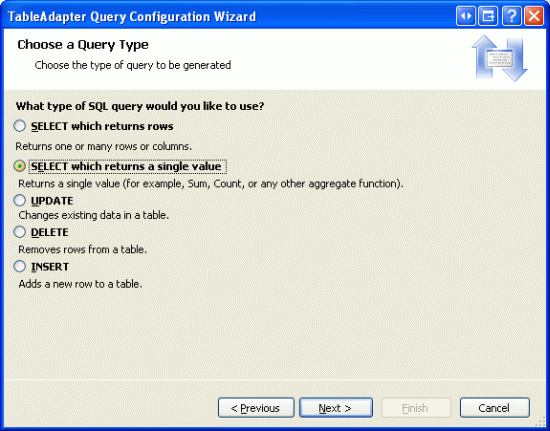
Рис. 2. Настройка запроса для использования инструкции SELECT, возвращающей одно значение
После указания типа используемого запроса необходимо далее указать запрос.
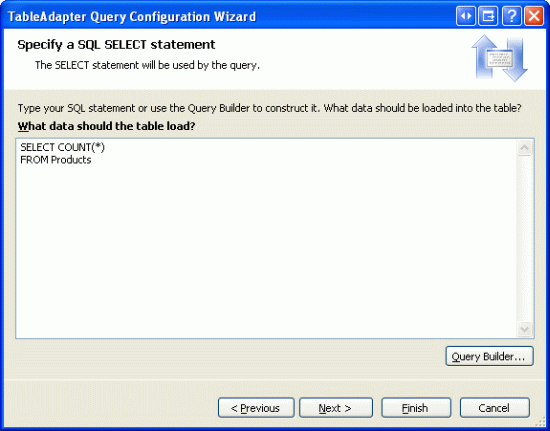
Рис. 3. Использование запроса SELECT COUNT(*) FROM Products
Наконец, укажите имя метода. Как уже упоминалось, давайте будем использовать TotalNumberOfProducts.
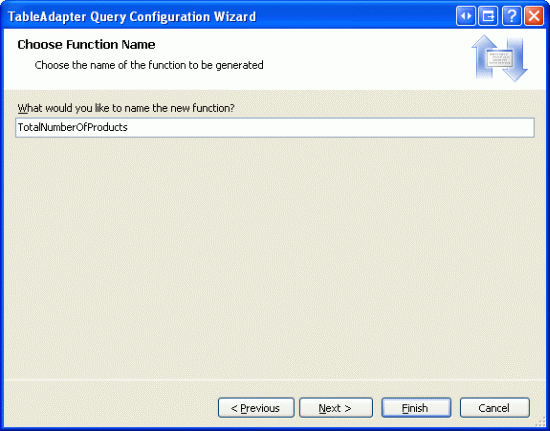
Рис. 4. Имя метода DAL TotalNumberOfProducts
После нажатия кнопки "Готово" мастер добавит метод в TotalNumberOfProducts DAL. Скалярные возвращающие методы в типах возвращаемых значений NULL DAL в случае, если результатом запроса SQL является NULL. Однако наш COUNT запрос всегда возвращает значение, отличноеNULL от значения. Независимо от того, что метод DAL возвращает целое число, допускающее значение NULL.
Помимо метода DAL, нам также нужен метод в BLL.
ProductsBLL Откройте файл класса и добавьте TotalNumberOfProducts метод, который просто вызывает метод DALTotalNumberOfProducts:
public int TotalNumberOfProducts()
{
return Adapter.TotalNumberOfProducts().GetValueOrDefault();
}
Метод DAL TotalNumberOfProducts возвращает целое число, допускающее значение NULL. Однако мы создали ProductsBLL метод класса TotalNumberOfProducts , чтобы он возвращал стандартное целое число. Поэтому необходимо, ProductsBLL чтобы метод класса TotalNumberOfProducts возвращал часть значения целого числа, допускающего значение NULL, возвращаемого методом DAL TotalNumberOfProducts . Вызов, возвращающий GetValueOrDefault() значение целого числа, допускающего значение NULL, если оно существует; если целое число null, допускающее значение NULL, равно 0, возвращает значение целого числа по умолчанию.
Шаг 3. Возврат точного подмножества записей
Наша следующая задача — создать методы в DAL и BLL, которые принимают переменные начальной строки и максимальные строки, рассмотренные ранее, и возвращают соответствующие записи. Прежде чем это сделать, давайте сначала рассмотрим необходимый скрипт SQL. Задача, связанная с нами, заключается в том, что мы должны быть в состоянии эффективно назначить индекс каждой строке во всех результатах, чтобы мы могли возвращать только те записи, начиная с начального индекса строк (и до максимального числа записей записей).
Это не проблема, если в таблице базы данных уже есть столбец, который служит индексом строк. На первый взгляд мы можем подумать, что Products поле таблицы ProductID было бы достаточно, как первый продукт имеет ProductID 1, второй 2 и т. д. Однако удаление продукта оставляет пробел в последовательности, допуская значение NULL.
Существует два общих метода, используемых для эффективного связывания индекса строк с данными на страницу, что позволяет получить точное подмножество записей:
ROW_NUMBER()SQL Server 2005, новое для SQL Server 2005,ROW_NUMBER()ключевое слово связывает рейтинг с каждой возвращаемой записью на основе определенного порядка. Этот рейтинг можно использовать в качестве индекса строк для каждой строки.SET ROWCOUNTможно указать, сколько записей должно обрабатываться перед завершением запроса;SET ROWCOUNTT-SQL, которые могут содержать табличные данные, а также временные таблицы. Этот подход работает одинаково хорошо с Microsoft SQL Server 2005 и SQL Server 2000 (в то время какROW_NUMBER()подход работает только с SQL Server 2005).Здесь необходимо создать переменную таблицы, которая содержит
IDENTITYстолбец и столбцы для первичных ключей таблицы, данные которых выстраиваются. Затем содержимое таблицы, данные которой передаются на страницу, сбрасываются в переменную таблицы, тем самым объединяя последовательный индекс строк (черезIDENTITYстолбец) для каждой записи в таблице. После заполненияSELECTпеременной таблицы можно выполнить инструкцию в переменной таблицы, присоединенной к базовой таблице, чтобы извлечь определенные записи. ИнструкцияSET ROWCOUNTиспользуется для интеллектуального ограничения количества записей, которые необходимо дампать в переменную таблицы.Этот подход основан на запрашиваемом номере страницы, так как
SET ROWCOUNTзначение присваивается значению начального индекса строк плюс максимальные строки. При разбиении на страницы с низким числом страниц, таких как первые несколько страниц данных, этот подход очень эффективен. Однако она демонстрирует производительность по умолчанию по умолчанию при получении страницы в конце.
В этом руководстве реализовано пользовательское разбиение по страницам с помощью ключевого ROW_NUMBER() слова. Дополнительные сведения об использовании табличной переменной и SET ROWCOUNT техники см. в статье "Эффективное разбиение по страницам с помощью больших объемов данных".
Ключевое ROW_NUMBER() слово, связанное с рейтингом каждой записи, возвращаемой по определенному упорядочению, с помощью следующего синтаксиса:
SELECT columnList,
ROW_NUMBER() OVER(orderByClause)
FROM TableName
ROW_NUMBER() возвращает числовое значение, указывающее ранг для каждой записи в отношении указанного порядка. Например, чтобы просмотреть ранг для каждого продукта, упорядоченного от наиболее дорогого до наименьшего, можно использовать следующий запрос:
SELECT ProductName, UnitPrice,
ROW_NUMBER() OVER(ORDER BY UnitPrice DESC) AS PriceRank
FROM Products
На рисунке 5 показаны результаты этого запроса при выполнении окна запроса в Visual Studio. Обратите внимание, что продукты упорядочены по цене, а также ценовую категорию для каждой строки.
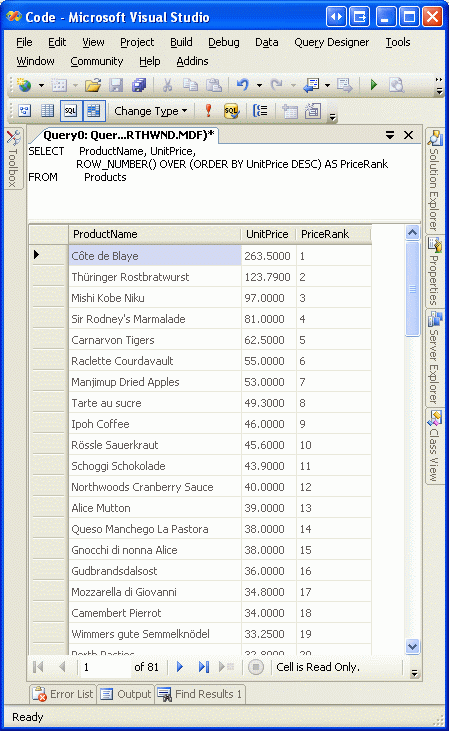
Рис. 5. Ценовая ранг включена для каждой возвращаемой записи.
Примечание.
ROW_NUMBER() — это только один из многих новых функций ранжирования, доступных в SQL Server 2005. Для более подробного обсуждения наряду с другими функциями ранжирования ROW_NUMBER()ознакомьтесь с возвращающими ранжированные результаты с помощью Microsoft SQL Server 2005.
При ранжировании результатов по указанному ORDER BY столбцу в OVER предложении (UnitPriceв приведенном выше примере) SQL Server должен сортировать результаты. Это быстрая операция при наличии кластеризованного индекса по столбцам, по которым результаты упорядочены или если имеется индекс покрытия, но может оказаться более дорогостоящим в противном случае. Чтобы повысить производительность достаточно больших запросов, рекомендуется добавить некластикционный индекс для столбца, по которому результаты упорядочивается. Дополнительные сведения о рекомендациях по производительности см. в статье "Ранжирование функций и производительности" в SQL Server 2005 .
Данные ранжирования, возвращаемые напрямую ROW_NUMBER() , нельзя использовать в предложении WHERE . Однако производная таблица может использоваться для возврата ROW_NUMBER() результата, который затем может появиться в предложении WHERE . Например, следующий запрос использует производную таблицу для возврата столбцов ProductName и UnitPrice, а ROW_NUMBER() затем использует WHERE предложение для возврата только тех продуктов, ценовая категория которых составляет от 11 до 20:
SELECT PriceRank, ProductName, UnitPrice
FROM
(SELECT ProductName, UnitPrice,
ROW_NUMBER() OVER(ORDER BY UnitPrice DESC) AS PriceRank
FROM Products
) AS ProductsWithRowNumber
WHERE PriceRank BETWEEN 11 AND 20
Расширяя эту концепцию немного дальше, мы можем использовать этот подход для получения определенной страницы данных с учетом требуемых значений начального индекса строк и максимальных строк:
SELECT PriceRank, ProductName, UnitPrice
FROM
(SELECT ProductName, UnitPrice,
ROW_NUMBER() OVER(ORDER BY UnitPrice DESC) AS PriceRank
FROM Products
) AS ProductsWithRowNumber
WHERE PriceRank > <i>StartRowIndex</i> AND
PriceRank <= (<i>StartRowIndex</i> + <i>MaximumRows</i>)
Примечание.
Как мы увидим далее в этом руководстве, StartRowIndex предоставленный ObjectDataSource, индексируется начиная с нуля, в то время ROW_NUMBER() как значение, возвращаемое SQL Server 2005, индексируется начиная с 1. Поэтому предложение WHERE возвращает эти записи, где PriceRankStartRowIndex строго больше и меньше или равноStartRowIndex + MaximumRows.
Теперь, когда мы обсудили, как ROW_NUMBER() можно использовать для получения определенной страницы данных с учетом значений начального индекса строк и максимальных строк, теперь необходимо реализовать эту логику в качестве методов в DAL и BLL.
При создании этого запроса необходимо решить порядок, по которому будут ранжированы результаты; позвольте отсортировать продукты по их имени в алфавитном порядке. Это означает, что с помощью пользовательской реализации разбиения на страницы в этом руководстве мы не сможем создать пользовательский отчет, чем можно отсортировать. Однако в следующем руководстве мы увидим, как можно предоставить такие функциональные возможности.
В предыдущем разделе мы создали метод DAL в качестве нерегламентированной инструкции SQL. К сожалению, средство синтаксического анализа T-SQL в Visual Studio, используемое мастером TableAdapter, не любит OVER синтаксис, используемый ROW_NUMBER() функцией. Поэтому необходимо создать этот метод DAL как хранимую процедуру. Выберите обозреватель серверов в меню "Вид" (или нажмите клавиши CTRL+ALT+S) и разверните NORTHWND.MDF узел. Чтобы добавить новую хранимую процедуру, щелкните правой кнопкой мыши узел хранимых процедур и выберите команду "Добавить новую хранимую процедуру" (см. рис. 6).
Рис. 6. Добавление новой хранимой процедуры для разбиения по страницам с помощью продуктов
Эта хранимая процедура должна принимать два целочисленных входных параметра и @startRowIndex@maximumRows использовать ROW_NUMBER() функцию, упорядоченную ProductName полем, возвращая только те строки, которые больше указанного @startRowIndex и меньше или равно @startRowIndex + @maximumRow s. Введите следующий сценарий в новую хранимую процедуру и щелкните значок "Сохранить", чтобы добавить хранимую процедуру в базу данных.
CREATE PROCEDURE dbo.GetProductsPaged
(
@startRowIndex int,
@maximumRows int
)
AS
SELECT ProductID, ProductName, SupplierID, CategoryID, QuantityPerUnit,
UnitPrice, UnitsInStock, UnitsOnOrder, ReorderLevel, Discontinued,
CategoryName, SupplierName
FROM
(
SELECT ProductID, ProductName, SupplierID, CategoryID, QuantityPerUnit,
UnitPrice, UnitsInStock, UnitsOnOrder, ReorderLevel, Discontinued,
(SELECT CategoryName
FROM Categories
WHERE Categories.CategoryID = Products.CategoryID) AS CategoryName,
(SELECT CompanyName
FROM Suppliers
WHERE Suppliers.SupplierID = Products.SupplierID) AS SupplierName,
ROW_NUMBER() OVER (ORDER BY ProductName) AS RowRank
FROM Products
) AS ProductsWithRowNumbers
WHERE RowRank > @startRowIndex AND RowRank <= (@startRowIndex + @maximumRows)
После создания хранимой процедуры выполните некоторое время, чтобы проверить его. Щелкните правой кнопкой мыши GetProductsPaged имя хранимой процедуры в обозревателе серверов и выберите параметр "Выполнить". Затем Visual Studio предложит вам входные параметры @startRowIndex и @maximumRow s (см. рис. 7). Попробуйте различные значения и изучите результаты.
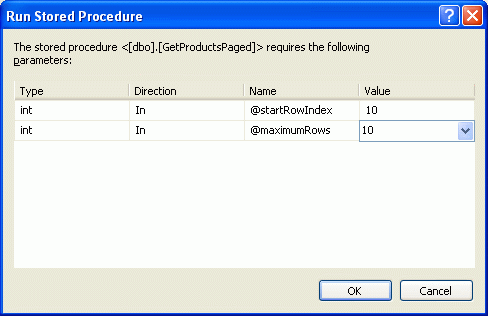 @startRowIndex и @maximumRows параметры" />
@startRowIndex и @maximumRows параметры" />
Рис. 7. Введите значение для @startRowIndex и @maximumRows параметров
После выбора этих значений входных параметров окно вывода отобразит результаты. На рисунке 8 показаны результаты при передаче 10 для обоих @startRowIndex параметров и @maximumRows параметров.
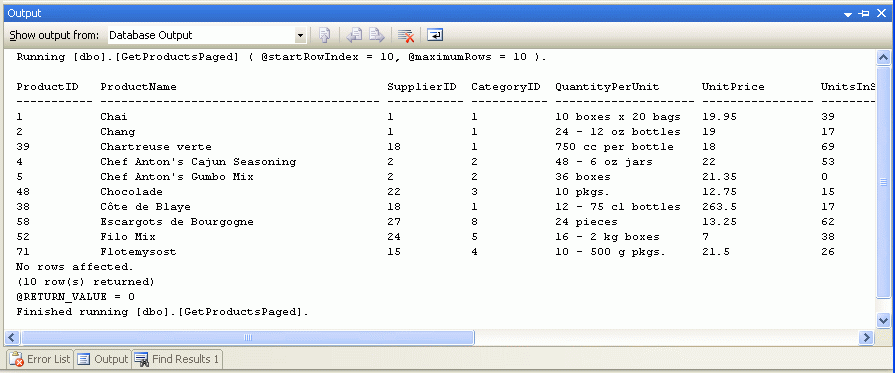
Рис. 8. Возвращаются записи, которые будут отображаться на второй странице данных (щелкните, чтобы просмотреть изображение полного размера)
{kind=link}
После создания этой хранимой процедуры мы готовы к созданию ProductsTableAdapter метода. Откройте типизированный Northwind.xsd набор данных, щелкните правой кнопкой мыши ProductsTableAdapterи выберите параметр "Добавить запрос". Вместо создания запроса с помощью нерегламентированной инструкции SQL создайте его с помощью существующей хранимой процедуры.
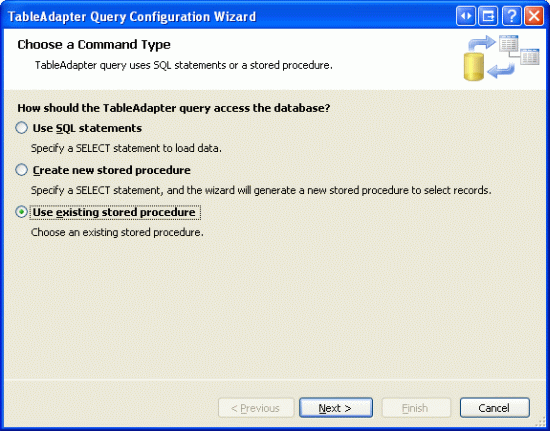
Рис. 9. Создание метода DAL с помощью существующей хранимой процедуры
Затем нам будет предложено выбрать хранимую процедуру для вызова. Выберите хранимую GetProductsPaged процедуру из раскрывающегося списка.
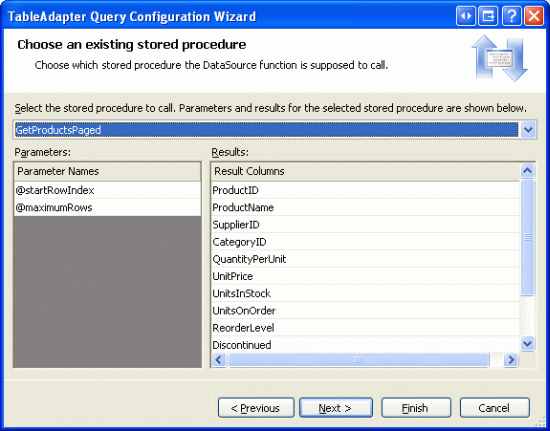
Рис. 10. Выберите хранимую процедуру GetProductsPaged из раскрывающегося списка
На следующем экране показано, какие данные возвращаются хранимой процедурой: табличные данные, одно значение или нет. Так как хранимая GetProductsPaged процедура может возвращать несколько записей, укажите, что она возвращает табличные данные.
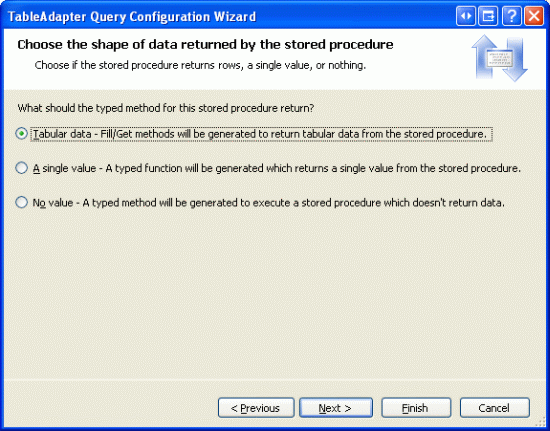
Рис. 11. Указывает, что хранимая процедура возвращает табличные данные
Наконец, укажите имена созданных методов. Как и в предыдущих руководствах, используйте методы заполнения dataTable и Return a DataTable. Назовите первый метод FillPaged и второй GetProductsPaged.
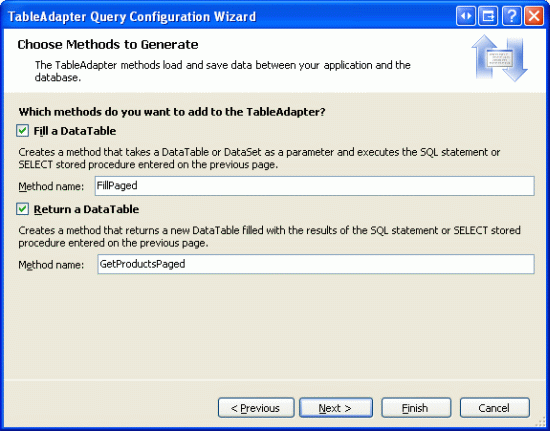
Рис. 12. Имя методов FillPaged и GetProductsPaged
Помимо создания метода DAL для возврата определенной страницы продуктов, необходимо также предоставить такие функции в BLL. Как и в методе DAL, метод GetProductsPaged BLL должен принимать два целочисленных входных данных для указания начального индекса строк и максимальных строк, и должен возвращать только те записи, которые попадают в указанный диапазон. Создайте такой метод BLL в классе ProductsBLL, который просто вызывает метод GetProductsPaged DAL, как показано ниже.
[System.ComponentModel.DataObjectMethodAttribute(
System.ComponentModel.DataObjectMethodType.Select, false)]
public Northwind.ProductsDataTable GetProductsPaged(int startRowIndex, int maximumRows)
{
return Adapter.GetProductsPaged(startRowIndex, maximumRows);
}
Вы можете использовать любое имя входных параметров метода BLL, но, как мы увидим в ближайшее время, выбор использования startRowIndex и maximumRows экономит нас от дополнительных битов при настройке ObjectDataSource для использования этого метода.
Шаг 4. Настройка ObjectDataSource для использования пользовательского разбиения по страницам
С помощью методов BLL и DAL для доступа к определенному подмножеству записей мы готовы создать элемент управления GridView, который страницы через свои базовые записи с помощью настраиваемого разбиения на страницы. Начните с открытия EfficientPaging.aspx страницы в PagingAndSorting папке, добавьте GridView на страницу и настройте ее для использования нового элемента управления ObjectDataSource. В наших прошлых руководствах мы часто имели объект ObjectDataSource, настроенный ProductsBLL для использования метода класса GetProducts . Однако на этот раз мы хотим использовать GetProductsPaged этот метод, так как GetProducts метод возвращает все продукты в базе данных, а GetProductsPaged возвращает только определенное подмножество записей.
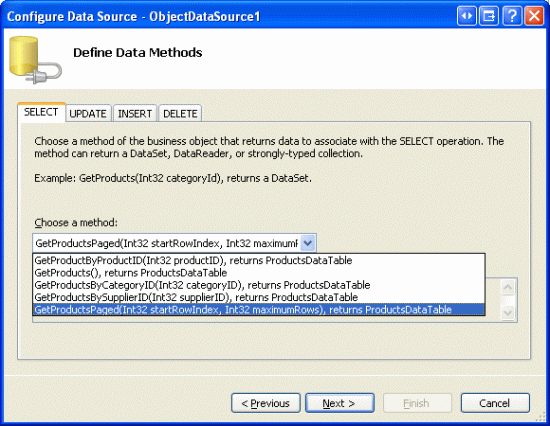
Рис. 13. Настройка ObjectDataSource для использования метода GetProductsPaged класса ProductsBLL
Так как мы повторно создадим GridView только для чтения, задайте раскрывающийся список методов в вкладках INSERT, UPDATE и DELETE (Нет).
Затем мастер ObjectDataSource запрашивает у нас источники значений GetProductsPaged параметров метода startRowIndex и maximumRows входных параметров. Эти входные параметры на самом деле задаются в GridView автоматически, поэтому просто оставьте исходный параметр "Нет" и нажмите кнопку "Готово".
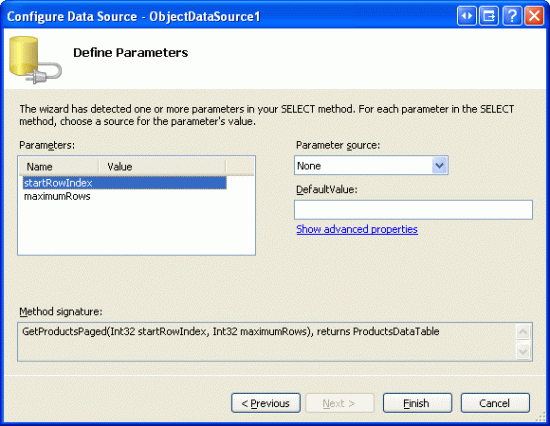
Рис. 14. Оставьте входные источники параметров как нет
Завершив работу мастера ObjectDataSource, GridView будет содержать BoundField или CheckBoxField для каждого поля данных продукта. Вы можете настроить внешний вид GridView, как вы видите. Я решил отобразить только ProductNameполя , CategoryName, SupplierNameQuantityPerUnitи UnitPrice BoundFields. Кроме того, настройте GridView для поддержки разбиения по страницам, установив флажок "Включить разбиение по страницам" в смарт-теге. После этих изменений декларативная разметка GridView и ObjectDataSource должна выглядеть следующим образом:
<asp:GridView ID="GridView1" runat="server" AutoGenerateColumns="False"
DataKeyNames="ProductID" DataSourceID="ObjectDataSource1" AllowPaging="True">
<Columns>
<asp:BoundField DataField="ProductName" HeaderText="Product"
SortExpression="ProductName" />
<asp:BoundField DataField="CategoryName" HeaderText="Category"
ReadOnly="True" SortExpression="CategoryName" />
<asp:BoundField DataField="SupplierName" HeaderText="Supplier"
SortExpression="SupplierName" />
<asp:BoundField DataField="QuantityPerUnit" HeaderText="Qty/Unit"
SortExpression="QuantityPerUnit" />
<asp:BoundField DataField="UnitPrice" DataFormatString="{0:c}"
HeaderText="Price" HtmlEncode="False" SortExpression="UnitPrice" />
</Columns>
</asp:GridView>
<asp:ObjectDataSource ID="ObjectDataSource1" runat="server"
OldValuesParameterFormatString="original_{0}" SelectMethod="GetProductsPaged"
TypeName="ProductsBLL">
<SelectParameters>
<asp:Parameter Name="startRowIndex" Type="Int32" />
<asp:Parameter Name="maximumRows" Type="Int32" />
</SelectParameters>
</asp:ObjectDataSource>
Если вы посещаете страницу через браузер, однако GridView не является местом для обнаружения.
Рис. 15. GridView не отображается
GridView отсутствует, так как ОбъектDataSource в настоящее время использует значение 0 в качестве значений для обоих GetProductsPagedstartRowIndex параметров и maximumRows входных параметров. Поэтому результирующий SQL-запрос не возвращает записей, поэтому GridView не отображается.
Чтобы устранить эту проблему, необходимо настроить ObjectDataSource для использования настраиваемого разбиения по страницам. Это можно сделать в следующих шагах:
-
EnablePagingObjectDataSource значение этого параметра, указывающее объекту ObjectDataSourcetrue, что он должен передать два дополнительных параметра: один, чтобы указать начальный индекс строк (SelectMethod) и один, чтобы указать максимальные строки (StartRowIndexParameterName). -
Задайте объект ObjectDataSource
StartRowIndexParameterNameиMaximumRowsParameterNameсвойства соответственноStartRowIndexParameterNameиMaximumRowsParameterNameсвойства указывают имена входных параметров, переданных вSelectMethodпользовательские цели разбиения. По умолчанию эти имена параметров иstartIndexRowmaximumRows, поэтому при созданииGetProductsPagedметода в BLL, я использовал эти значения для входных параметров. Если вы решили использовать разные имена параметров для метода BLLGetProductsPaged,startIndexнапример,maxRowsнеобходимо задать свойства ObjectDataSourceStartRowIndexParameterNameMaximumRowsParameterNameсоответствующим образом (например, startIndex дляStartRowIndexParameterNameи maxRows).MaximumRowsParameterName -
SelectCountMethodЭти сведения необходимы объекту ObjectDataSource для правильной отрисовки интерфейса разбиения по страницам. -
startRowIndexУдалите элементыmaximumRows<asp:Parameter>из декларативной разметки ObjectDataSource при настройке ObjectDataSource с помощью мастера, Visual Studio автоматически добавил два<asp:Parameter>элемента дляGetProductsPagedвходных параметров метода. Если этиEnablePagingtrueпараметры передаются автоматически. Если они также отображаются в декларативном синтаксисе, ОбъектDataSource попытается передать четыре параметраGetProductsPagedметоду и два параметра методуTotalNumberOfProducts. Если вы забыли удалить эти<asp:Parameter>элементы, при посещении страницы через браузер вы получите сообщение об ошибке, например: ObjectDataSource "ObjectDataSource1" не удалось найти не универсальный метод TotalNumberOfProducts, имеющий параметры: startRowIndex, maximumRows.
После внесения этих изменений декларативный синтаксис ObjectDataSource должен выглядеть следующим образом:
<asp:ObjectDataSource ID="ObjectDataSource1" runat="server"
OldValuesParameterFormatString="original_{0}" TypeName="ProductsBLL"
SelectMethod="GetProductsPaged" EnablePaging="True"
SelectCountMethod="TotalNumberOfProducts">
</asp:ObjectDataSource>
Обратите внимание, что EnablePaging заданы свойства и SelectCountMethod<asp:Parameter> элементы были удалены. На рисунке 16 показан снимок экрана окно свойств после внесения этих изменений.

Рис. 16. Чтобы использовать настраиваемое разбиение на страницах, настройте элемент управления ObjectDataSource
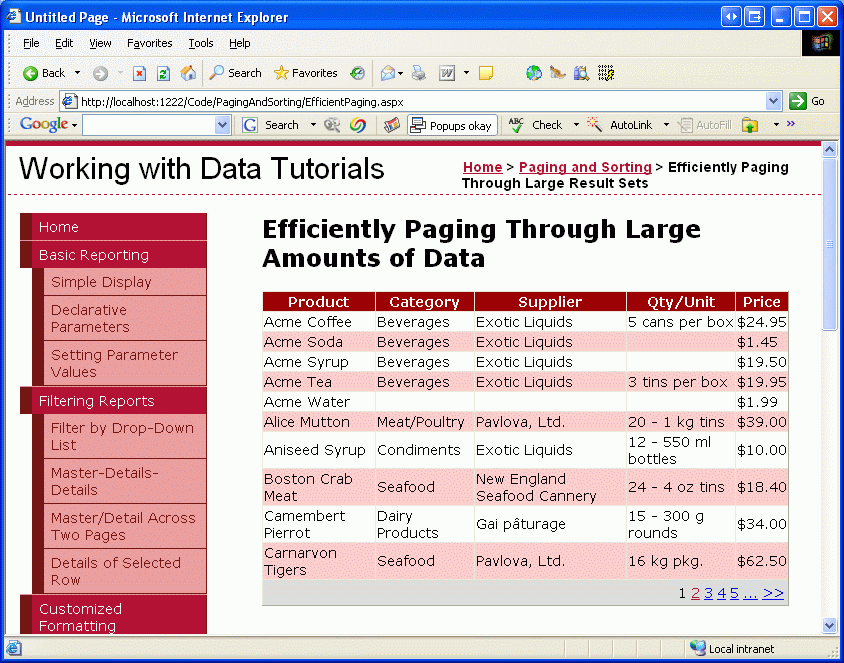
После внесения этих изменений посетите эту страницу через браузер. Вы должны увидеть 10 продуктов, упорядоченных в алфавитном порядке. Найдите момент, чтобы выполнить переход к данным на одну страницу за раз. Хотя визуальное отличие от точки зрения конечного пользователя между разбиением по страницам по умолчанию и пользовательским разбиением на страницы не отличается, а настраиваемое разбиение на страницы эффективнее всего через большие объемы данных, так как оно извлекает только те записи, которые должны отображаться для данной страницы.
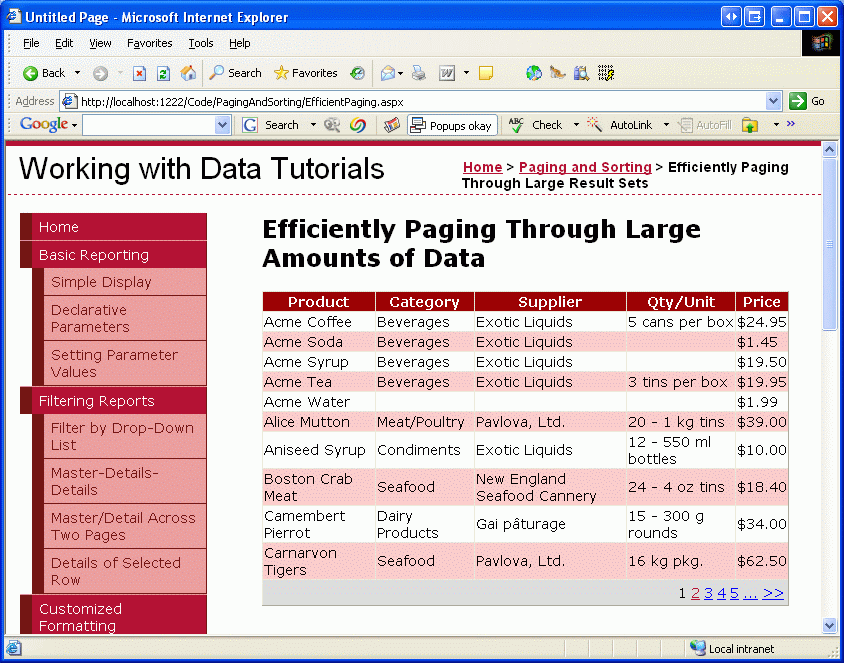
Рис. 17. Данные, упорядоченные по имени продукта, отображаются с помощью настраиваемого разбиения на страницы (щелкните, чтобы просмотреть изображение полного размера)
{kind=link}
Примечание.
При настройке разбиения страниц значение счетчика страниц, возвращаемое объектом ObjectDataSource SelectCountMethod , хранится в состоянии представления GridView. Другие переменные PageIndexEditIndexSelectedIndexDataKeysGridView, коллекции и т. д. хранятся в состоянии управления, который сохраняется независимо от значения свойства GridView.EnableViewState
PageCount Так как значение сохраняется в обратном режиме с помощью состояния представления, при использовании интерфейса разбиения на страницы, включающего ссылку на последнюю страницу, необходимо включить состояние представления GridView. (Если интерфейс разбиения страниц не содержит прямую ссылку на последнюю страницу, вы можете отключить состояние просмотра.)
Щелкнув последнюю ссылку страницы, обратная связь и указывает GridView обновить его PageIndex свойство. Если щелкнуть последнюю ссылку на страницу, GridView назначает его PageIndex свойству значение, меньшее его PageCount свойству. При отключенном PageCount состоянии представления значение теряется во время обратной передачи и PageIndex назначается максимальное целочисленное значение. Затем GridView пытается определить начальный индекс строки путем умножения PageSize и PageCount свойств. Это приводит к тому OverflowException , что продукт превышает максимальный допустимый размер целого числа.
Реализация пользовательского разбиения по страницам и сортировки
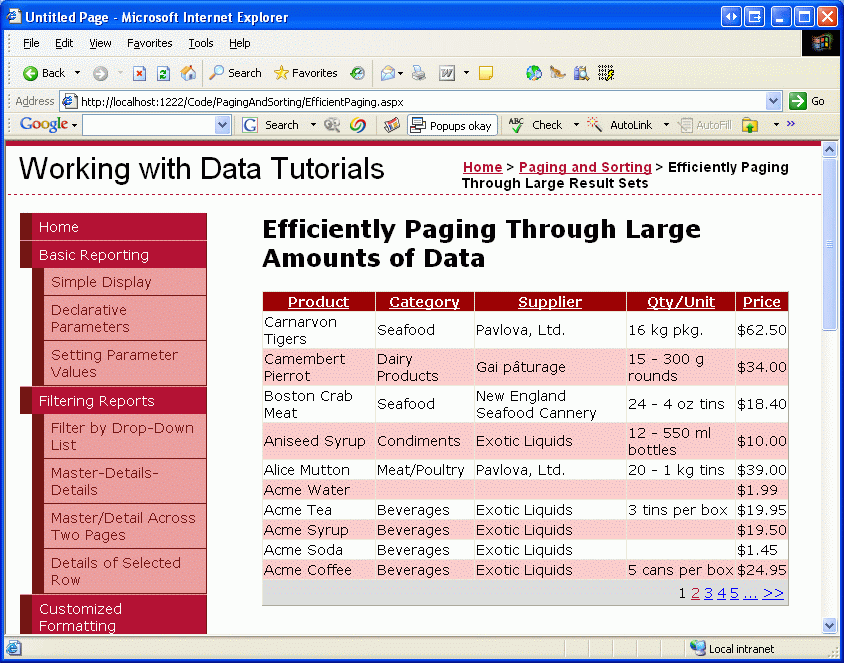
Текущая пользовательская реализация разбиения на страницы требует, чтобы при создании GetProductsPaged хранимой процедуры указать порядок, с помощью которого данные будут выстраиванием. Однако, возможно, вы отметили, что смарт-тег GridView содержит флажок "Включить сортировку" в дополнение к параметру "Включить разбиение по страницам". К сожалению, добавление поддержки сортировки в GridView с текущей пользовательской реализацией разбиения страниц будет отсортировать только записи на текущей странице данных. Например, если вы настроите GridView для поддержки разбиения по страницам, а затем при просмотре первой страницы данных сортировка по имени продукта в порядке убывания он изменит порядок продуктов на странице 1. Как показано на рисунке 18, такие показаны Carnarvon Tigers в качестве первого продукта при сортировке в обратном алфавитном порядке, который игнорирует 71 других продуктов, которые приходят после Carnarvon Tigers, в алфавитном порядке; В сортировке рассматриваются только те записи на первой странице.
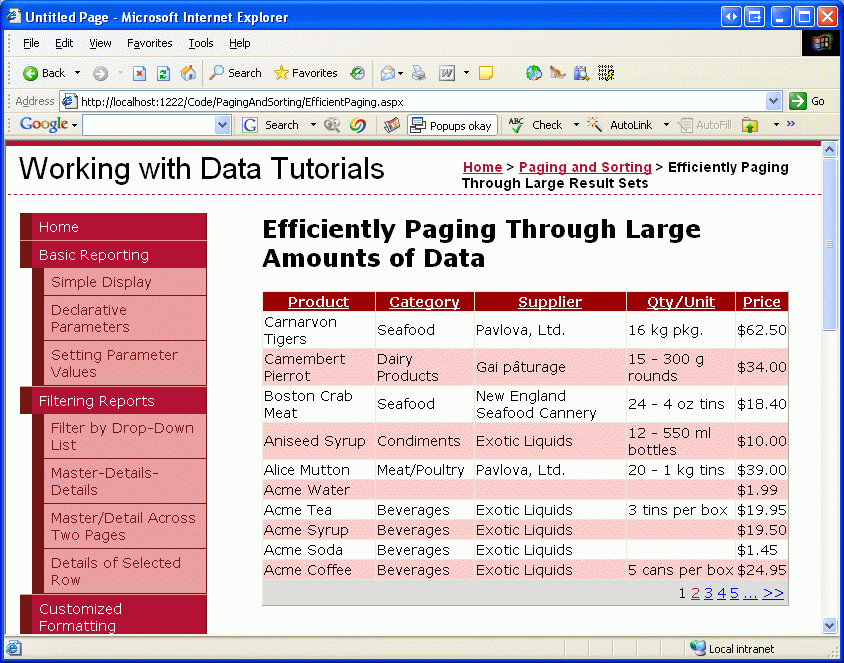
Рис. 18. Отсортированы только данные, отображаемые на текущей странице (щелкните, чтобы просмотреть изображение полного размера)
{kind=link}
Сортировка применяется только к текущей странице данных, так как сортировка происходит после получения данных из метода BLL GetProductsPaged , и этот метод возвращает только эти записи для конкретной страницы. Чтобы правильно реализовать сортировку, необходимо передать выражение сортировки методу GetProductsPaged , чтобы данные могли быть ранжированы соответствующим образом, прежде чем возвращать определенную страницу данных. Мы посмотрим, как это сделать в следующем руководстве.
Реализация пользовательского разбиения по страницам и удаление
Если вы включаете функцию удаления в GridView, данные которой выстраиваются с помощью пользовательских методов разбиения на страницы, вы увидите, что при удалении последней записи с последней страницы GridView PageIndexисчезает, а не соответствующим образом уменьшается. Чтобы воспроизвести эту ошибку, включите удаление только что созданного учебника. Перейдите на последнюю страницу (страницу 9), где вы должны увидеть один продукт, так как мы разбием по страницам до 81 продуктов, 10 продуктов за раз. Удалите этот продукт.
При удалении последнего продукта GridView должен автоматически перейти на восьмую страницу, и такая функция будет выставлена с разбиением по умолчанию. Однако при использовании настраиваемого разбиения на страницы после удаления последнего продукта на последней странице элемент GridView просто исчезает с экрана. Точная причина , по которой это происходит, немного выходит за рамки этого учебника; см. статью "Удаление последней записи на последней странице" из GridView с настраиваемым разбиением на страницы с низким уровнем сведений о источнике этой проблемы. В сводке это связано со следующей последовательностью шагов, выполняемых GridView при нажатии кнопки "Удалить".
- Удаление записи
- Получение соответствующих записей для отображения указанных
PageIndexиPageSize - Убедитесь, что
PageIndexколичество страниц данных в источнике данных не превышается; если оно выполняется, автоматически уменьшается свойство GridViewPageIndex - Привязка соответствующей страницы данных к GridView с помощью записей, полученных на шаге 2.
Проблема связана с тем, что на шаге 2 PageIndex используемый при захвате записей для отображения по-прежнему PageIndex является последней страницей, единственная запись которой была только что удалена. Таким образом, на шаге 2 записи не возвращаются, так как последняя страница данных больше не содержит записей. Затем на шаге 3 GridView понимает, что его PageIndex свойство больше общего количества страниц в источнике данных (так как мы удалили последнюю запись на последней странице) и, следовательно, уменьшает его PageIndex свойство. На шаге 4 GridView пытается привязать себя к данным, извлеченным на шаге 2; Однако в шаге 2 записи не были возвращены, поэтому в результате пустой GridView. При разбиении по умолчанию эта проблема не возникает, так как на шаге 2 все записи извлекаются из источника данных.
Чтобы устранить эту проблему, у нас есть два варианта. Сначала необходимо создать обработчик событий для обработчика событий GridView RowDeleted , который определяет количество записей, отображаемых на странице, которая была только что удалена. Если была только одна запись, то только что удаленная запись должна быть последней, и нам нужно отделить gridView s PageIndex. Конечно, мы хотим обновить PageIndex только тот факт, что операция удаления была успешной, что может быть определено путем обеспечения наличия e.Exception свойства null.
Этот подход работает, так как он обновляется PageIndex после шага 1, но до шага 2. Поэтому в шаге 2 возвращается соответствующий набор записей. Для этого используйте следующий код:
protected void GridView1_RowDeleted(object sender, GridViewDeletedEventArgs e)
{
// If we just deleted the last row in the GridView, decrement the PageIndex
if (e.Exception == null && GridView1.Rows.Count == 1)
// we just deleted the last row
GridView1.PageIndex = Math.Max(0, GridView1.PageIndex - 1);
}
Альтернативным решением является создание обработчика событий для события ObjectDataSource RowDeleted и установка AffectedRows свойства значением 1. После удаления записи на шаге 1 (но перед извлечением данных на шаге 2) GridView обновляет его PageIndex свойство, если одна или несколько строк пострадали от операции.
AffectedRows Однако свойство не задано ObjectDataSource, поэтому этот шаг не указан. Один из способов выполнения этого шага заключается в том, чтобы вручную задать AffectedRows свойство, если операция удаления успешно завершится. Это можно сделать с помощью следующего кода:
protected void ObjectDataSource1_Deleted(
object sender, ObjectDataSourceStatusEventArgs e)
{
// If we get back a Boolean value from the DeleteProduct method and it's true,
// then we successfully deleted the product. Set AffectedRows to 1
if (e.ReturnValue is bool && ((bool)e.ReturnValue) == true)
e.AffectedRows = 1;
}
Код для обоих этих обработчиков событий можно найти в классе программной EfficientPaging.aspx части примера.
Сравнение производительности по умолчанию и настраиваемого разбиения на страницы
Так как настраиваемое разбиение на страницы получает только необходимые записи, в то время как по умолчанию по умолчанию возвращает все записи для каждой страницы, ясно, что настраиваемое разбиение на страницы более эффективно, чем по умолчанию. Но насколько эффективнее настраивается разбиение по страницам? Какой вид повышения производительности можно увидеть путем перехода с разбиения по умолчанию на пользовательские разбиения на разбиение на страницах?
К сожалению, ни один размер не подходит для всех ответов здесь. Повышение производительности зависит от ряда факторов, наиболее заметных двух из которых является количество записей, которые выстраиваются на страницы, и нагрузка, размещенная на сервере базы данных и каналах связи между веб-сервером и сервером базы данных. Для небольших таблиц с несколькими десятками записей производительность может быть незначительной. Для больших таблиц, с тысячами до сотен тысяч строк, однако, разница в производительности остро.
Статья из моей статьи "Настраиваемое разбиение по страницам в ASP.NET 2.0 с SQL Server 2005", содержит некоторые тесты производительности, которые я побежал, чтобы продемонстрировать различия в производительности между этими двумя способами разбиения по страницам в таблице базы данных с 50 000 записей. В этих тестах я рассмотрел время выполнения запроса на уровне SQL Server (с помощью SQL Profiler) и на странице ASP.NET с помощью функций трассировки ASP.NET. Помните, что эти тесты были запущены в поле разработки с одним активным пользователем, и поэтому не являются ненаучными и не имитируют типичные шаблоны загрузки веб-сайта. Независимо от этого, результаты показывают относительные различия во времени выполнения по умолчанию и настраиваемом разбиении по страницам при работе с достаточно большими объемами данных.
| Среднее значение. Длительность (с) | Читает | |
|---|---|---|
| Профилировщик SQL по умолчанию | 1.411 | 383 |
| Настраиваемый профилировщик SQL на страницы | 0,002 | 29 |
| Трассировка ASP.NET по умолчанию | 2.379 | Н/Д |
| Настраиваемая трассировка на страницах ASP.NET | 0,029 | Н/Д |
Как видно, получение определенной страницы данных требуется 354 меньше операций чтения в среднем и завершено в доли времени. На странице ASP.NET пользовательская страница была в состоянии отрисовки близко к 1/100м времени, за который оно потребовалось при использовании разбиения по умолчанию.
Итоги
Разбиение по умолчанию — это cinch для реализации простой проверки флажка "Включить разбиение по страницам" в смарт-теге веб-элемента управления данными, но такая простота обеспечивает затраты на производительность. При разбиении по умолчанию, когда пользователь запрашивает любую страницу данных , возвращаются все записи, даже если может отображаться только небольшая часть из них. Для борьбы с этой нагрузкой на производительность объект ObjectDataSource предлагает альтернативный вариант разбиения по страницам.
Хотя настраиваемое разбиение на страницах улучшается при проблемах производительности разбиения по умолчанию, извлекая только те записи, которые должны отображаться, для реализации настраиваемой разбиения по страницам. Во-первых, запрос должен быть записан, что правильно (и эффективно) обращается к определенному подмножество запрошенных записей. Это можно сделать несколькими способами; То, что мы рассмотрели в этом руководстве, — использовать новую ROW_NUMBER() функцию SQL Server 2005 для ранжирования результатов, а затем возвращать только те результаты, ранжирование которых попадает в указанный диапазон. Кроме того, необходимо добавить средства, чтобы определить общее количество записей, на которые выстраиваются страницы. После создания этих методов DAL и BLL также необходимо настроить ObjectDataSource, чтобы определить, сколько общих записей перестраиваются и могут правильно передавать значения начального индекса строк и максимальных строк в BLL.
При реализации пользовательского разбиения на страницах требуется несколько шагов и не так просто, как разбиение по умолчанию, настраиваемое разбиение по страницам является необходимостью при разбиении по страницам с достаточно большим объемом данных. Как показали результаты, настраиваемое разбиение на страницы может отложить секунды от времени отрисовки ASP.NET страницы и может облегчить нагрузку на сервере базы данных по одному или нескольким порядкам величины.
Счастливое программирование!
Об авторе
Скотт Митчелл, автор семи книг ASP/ASP.NET и основатель 4GuysFromRolla.com, работает с технологиями Microsoft Web с 1998 года. Скотт работает независимым консультантом, тренером и писателем. Его последняя книга Сэмс Учит себя ASP.NET 2.0 в 24 часах. С ним можно связаться по адресу mitchell@4GuysFromRolla.com.