Примечание
Для доступа к этой странице требуется авторизация. Вы можете попробовать войти или изменить каталоги.
Для доступа к этой странице требуется авторизация. Вы можете попробовать изменить каталоги.
Внимание
Начиная с 20 сентября 2023 г. вы не сможете создавать новые ресурсы помощника по метрикам. Служба помощника по метрикам отменяется 1 октября 2026 года.
Что такое инцидент?
При обнаружении аномалий в нескольких временных рядах в пределах одной метрики в определенной метке времени Помощник по метрикам автоматически сгруппирует аномалии с одинаковой первопричиной в один инцидент. Инцидент обычно указывает на реальную неполадку, а Помощник по метрикам выполняет анализ поверх него и обеспечивает автоматический анализ первопричин.
Это значительно упрощает работу для клиента и исключает необходимость просматривать каждую отдельную аномалию, что позволяет быстро найти наиболее важный фактор, приведший к проблеме.
Оповещение, созданное Помощником по метрикам, может содержать несколько инцидентов, и каждый инцидент может содержать несколько аномалий, записанных в разных временных рядах в той же метке времени.
Пути диагностики инцидента
Диагностика из уведомления об оповещении
Если вы настроили перехватчик электронной почты или Teams и применили по крайней мере одну конфигурацию оповещений. Затем вы получите непрерывные уведомления об оповещениях эскалации инцидентов, которые будут анализироваться с помощью Помощника по метрикам. В уведомлении указаны список инцидентов и краткое описание. Для каждого инцидента есть кнопкаДиагностика, при нажатии которой открывается страница сведений об инциденте, где можно ознакомиться с аналитикой диагностики.
Диагностика из инцидента в разделе "Центр инцидентов"
В Помощнике по метрикам есть раздел, где собраны все зарегистрированные инциденты, что упрощает отслеживание всех текущих проблем. При выборе вкладки "Концентратор инцидентов " в левой области будут перечислены все инциденты в выбранных метриках. Выберите в списке один из инцидентов для просмотра аналитики диагностики.
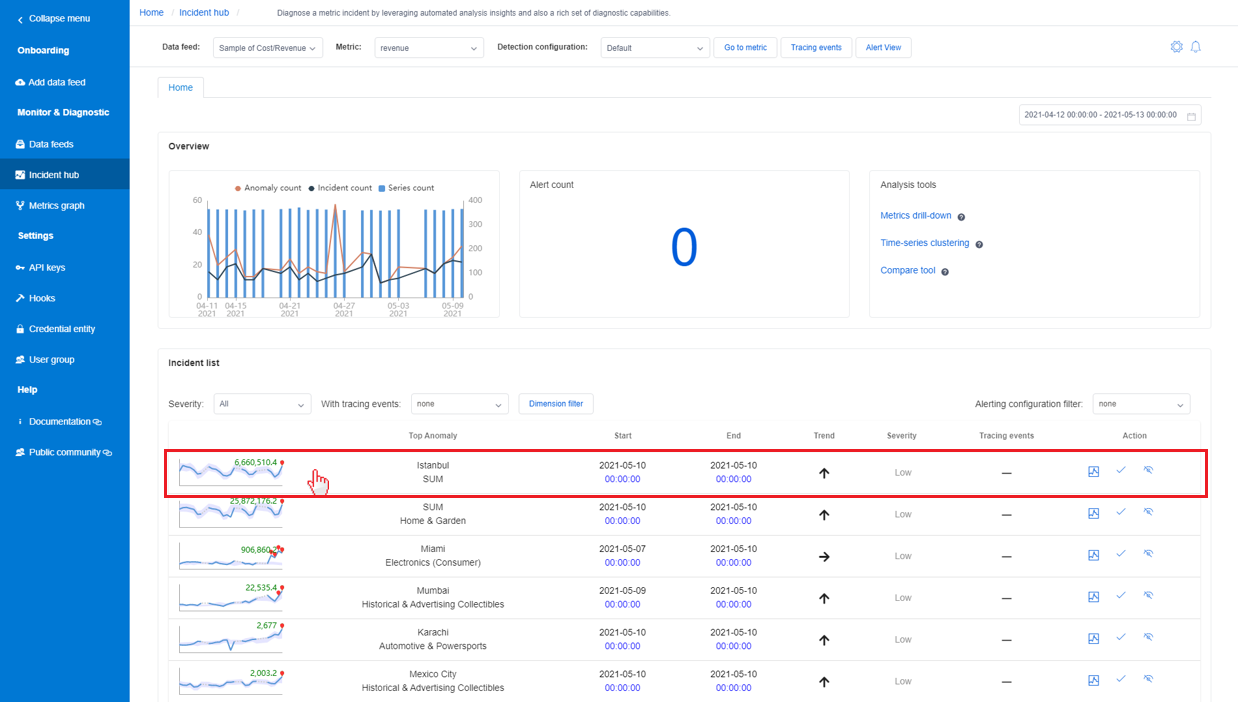
Диагностика из инцидента, указанного на странице метрик
На странице сведений о метрике имеется вкладка Инциденты со списком последних инцидентов, зарегистрированных для этой метрики. Список можно отфильтровать по уровню серьезности или значению измерения метрик.
Если выбрать один инцидент в списке, откроется страница сведений об этом инциденте для просмотра анализа диагностики.
Стандартный поток диагностики
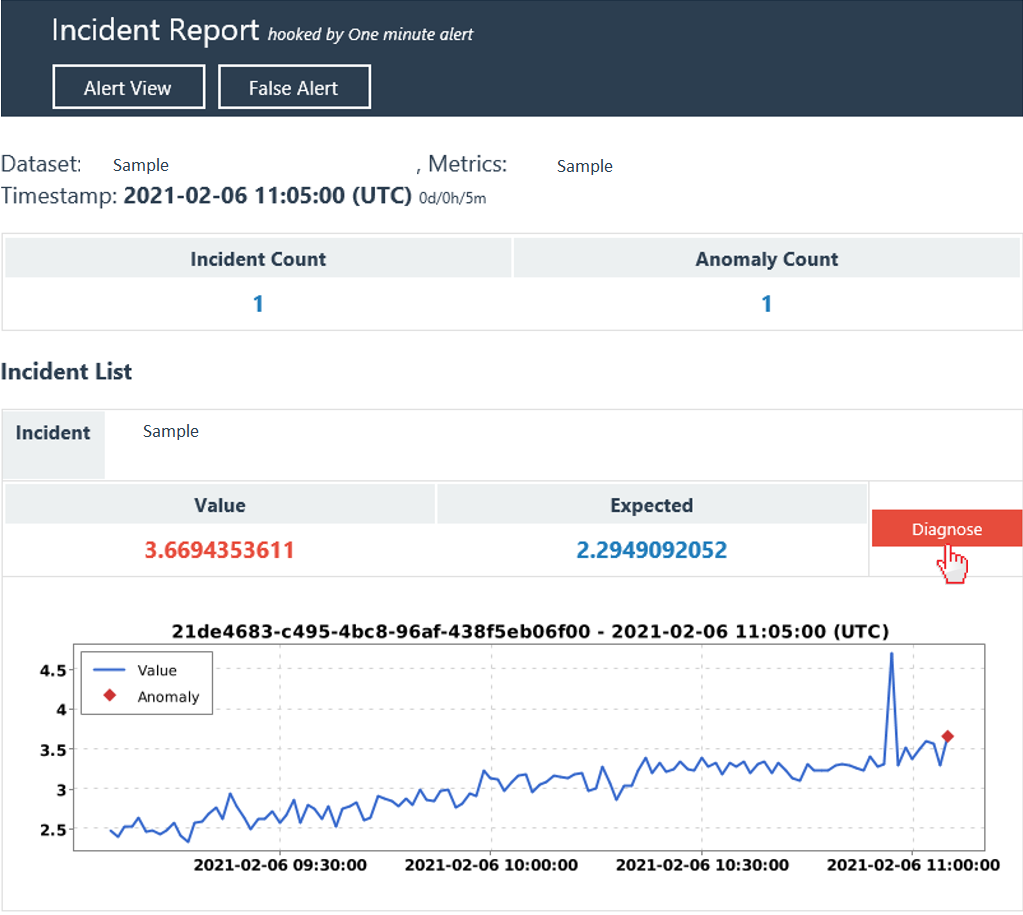
После перехода на страницу сведений об инциденте можно воспользоваться аналитическими данными, которые автоматически анализируются Помощником по метрикам, чтобы быстро определить первопричину проблемы или использовать средство анализа для дальнейшего анализа влияния проблемы. На странице сведений об инциденте есть три раздела, которые соответствуют трем основным действиям по диагностике инцидентов.
Шаг 1. Проверка сводки по текущему инциденту
В первом разделе приведена сводка текущего инцидента, включая основные сведения, действия и трассировки и анализируемую первопричину.
Основные сведения включают в себя наиболее затронутые ряды со схемой, время начала и окончания воздействия, серьезность инцидента и общее число аномалий. Ознакомившись с ними, вы сможете получить общее представление о текущей проблеме и ее влиянии.
Действия и трассировки используются для упрощения совместной работы группы над текущим инцидентом. Иногда по одному инциденту может потребоваться выполнить анализ с привлечением участников различных групп. Каждый, у кого есть разрешение на просмотр инцидента, может добавить действие или событие трассировки.
Например, после определения инцидента и первопричины инженер может добавить элемент трассировки с типом "Настроено" и ввести основную причину в разделе комментариев. Оставьте состояние "Активно". Затем другие участники команды могут использовать эти же сведения и будут в курсе, что кто-то работает над исправлением. Можно также добавить элемент Azure DevOps для отслеживания инцидента с определенной задачей или ошибкой.
Проанализированная первопричина — это результат автоматического анализа. Помощник по метрикам анализирует все записанные аномалии временных рядов в одной метрике с разными значениями измерения для одной и той же метки времени. Затем он выполняет корреляцию, группирует связанные аномалии и формирует совет по первопричине.
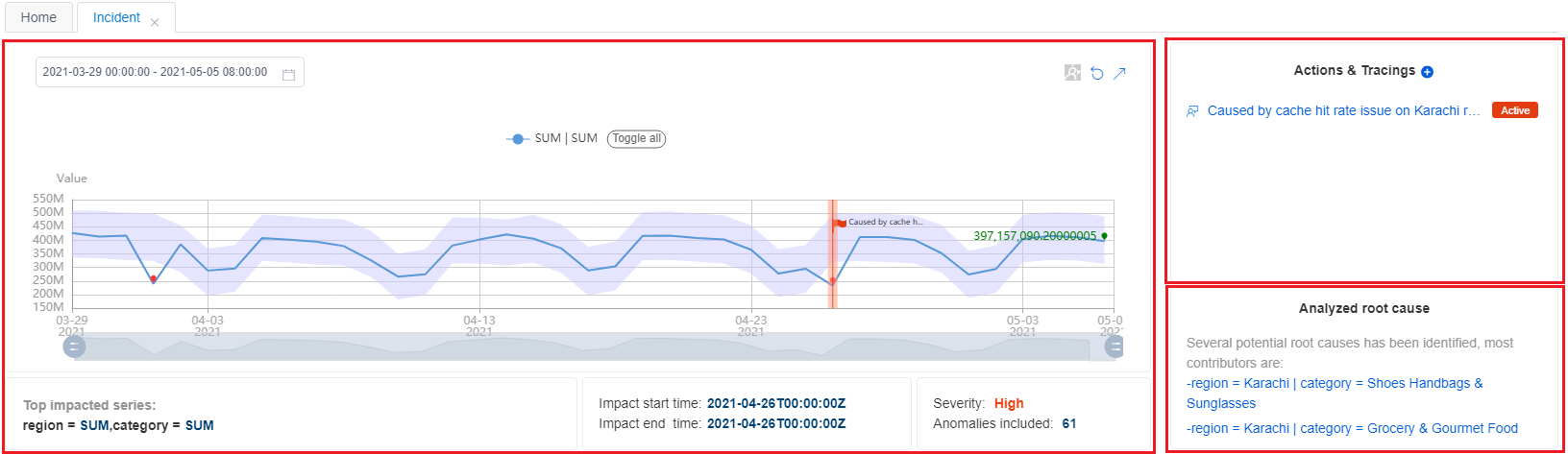
Для метрик с несколькими измерениями распространенным случаем является одновременное обнаружение сразу нескольких аномалий. Однако эти аномалии могут иметь одну и ту же первопричину. Вместо анализа всех аномалий по одной использование проанализированной первопричины является наиболее эффективным способом диагностики текущего инцидента.
Шаг 2. Просмотр аналитических сведений о межмерной диагностике
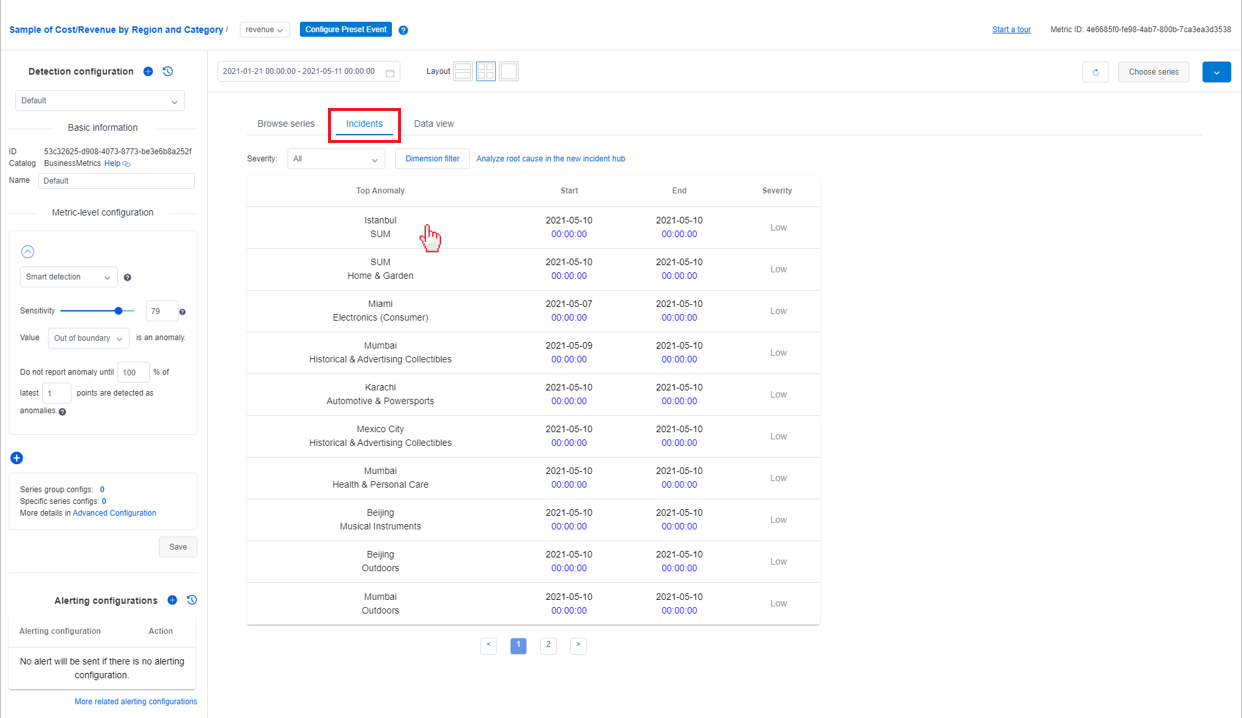
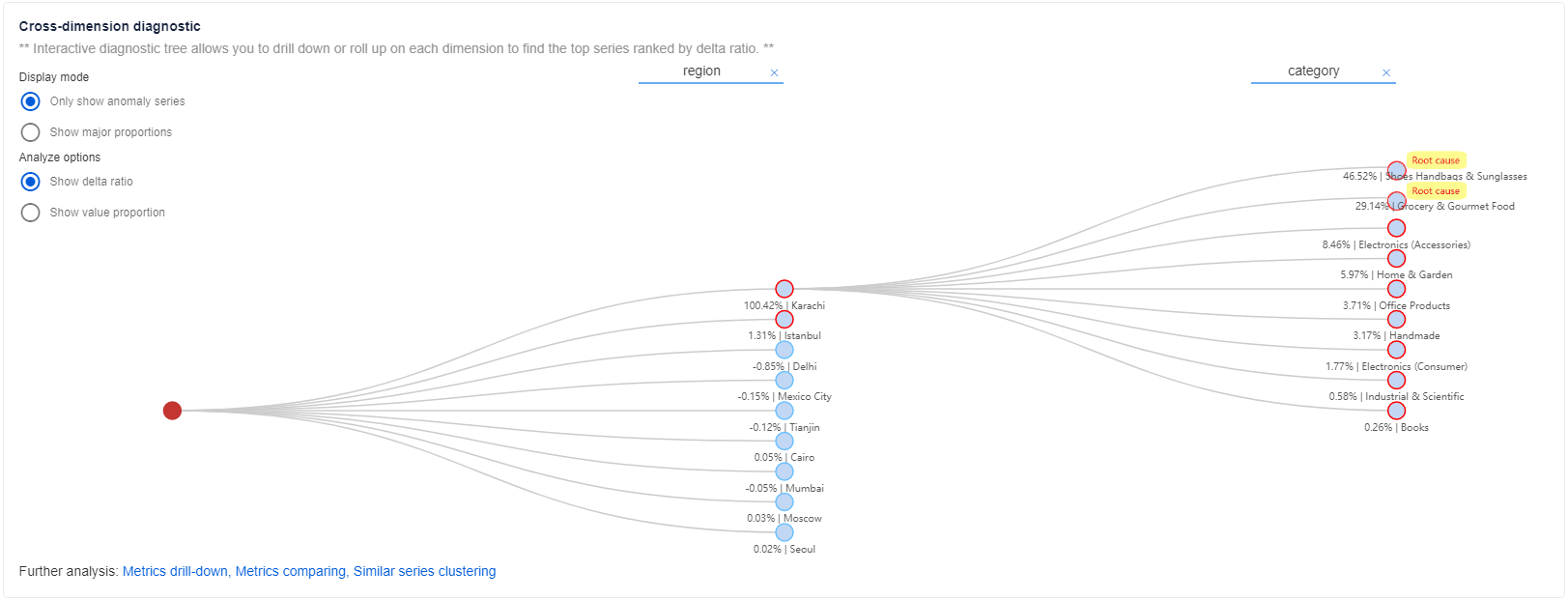
После получения основных сведений и данных автоматического анализа можно получить более подробные сведения об аномальном состоянии других измерений в той же метрике, используя дерево диагностики.
Для метрик с несколькими измерениями Помощник по метрикам классифицирует временные ряды и формирует иерархию, которая называется деревом диагностики. Например, метрика revenue отслеживается по двум измерениям: region и category. Несмотря на конкретные значения измерений, необходимо агрегированное значение измерения, например SUM. Тогда временные ряды region = SUM и category = SUM будут отнесены к категории корневого узла в дереве. Если в измерении SUM обнаружена аномалия, его можно детализировать и проанализировать, чтобы узнать, какое конкретное значение измерения больше всего повлияло на возникновение аномалии родительского узла. Выберите каждый узел, чтобы развернуть и просмотреть подробные сведения.
Включение "агрегированного" значения измерения в метриках
Помощник по метрикам поддерживает "сведение" измерений, чтобы вычислить "агрегированное" значение измерения. Дерево диагностики поддерживает диагностику по агрегатамSUM, AVG, MAX, MIN, COUNT. Чтобы включить "агрегированное" значение измерения, можно включить функцию "Сведение" во время подключения данных. Убедитесь, что метрики математически вычисляемые, а также в том, что агрегированное измерение имеет реальное значение для бизнеса.

Если в метриках нет "агрегированных" значений измерения
Если в метриках нет "агрегированного" значения измерения, а функция "Свернуть" не включена во время адаптации данных. Для "агрегированного" измерения не будет вычислено значение метрики, оно будет отображаться как серый узел в дереве и его можно будет развернуть для просмотра его дочерних узлов.
Условные обозначения дерева диагностики
В дереве диагностики есть три типа узлов.
- Синий узел, соответствующий временному ряду с реальным значением метрики.
- Серый узел, соответствующий виртуальному временному ряду без значения метрики, является логическим узлом.
- Красный узел, который соответствует наиболее затронутым временным рядам текущего инцидента.
Для каждого узла ненормальное состояние обозначается цветом границы узла.
- Красная граница означает, что во временном ряду, соответствующем метке времени инцидента, зафиксирована аномалия.
- Граница другого цвета означает, что во временном ряду, соответствующем метке времени инцидента, не зафиксированы аномалии.
Режим отображения
Существует два режима отображения дерева диагностики: отображение только ряда аномалий или отображение основных пропорций.
- Режим отображения только ряда аномалий позволяет клиенту сосредоточиться на текущих аномалиях, зафиксированных в разных рядах, и диагностировать первопричину затронутых рядов.
- Режим отображения основных пропорций позволяет клиенту проверять ненормальное состояние основных пропорций поверх затронутых рядов. В этом режиме в дереве отображаются оба ряда с обнаруженными аномалиями и рядами без аномалий. Но лучше сосредоточиться на важных рядах.
Параметры анализа
Показывать дельта-отношение
"Дельта-отношение" — это процентная доля текущего узла по сравнению с разностным родительским узлом. Формула выглядит так:
(реальное значение текущего узла – ожидаемое значение текущего узла) / (реальное значение родительского узла – ожидаемое значение родительского узла) * 100 %
Используется для анализа основного вклада разностного родительского узла.
Показывать долю значения
"Доля значения" — это процент текущего значения узла по сравнению со значением родительского узла. Формула выглядит так:
(реальное значение текущего узла / реальное значение родительского узла) * 100 %
Используется для вычисления доли текущего узла в целом.
Используя дерево диагностики, клиенты могут определять первопричину текущего инцидента в определенном измерении. Это значительно упрощает работу для клиента, исключая необходимость просматривать каждую отдельную аномалию или выполнять сводку по различным измерениям, чтобы найти вклад в основную аномалию.
Шаг 3. Просмотр аналитики диагностики между метриками с помощью графа метрик
Иногда трудно проанализировать проблему, проверив аномальное состояние одной метрики, и необходимо связать несколько метрик вместе. Клиенты могут настроить график метрик, на котором указаны отношения между метриками. Сведения о том, как создать граф метрик, см. здесь.
Проверка состояния аномалии в измерении первопричины на графе метрик
При использовании приведенного выше результата перекрестной диагностики измерений первопричина ограничена конкретным значением измерения. Используйте граф метрик и примените фильтр по измерению проанализированной первопричины, чтобы проверить состояние аномалии в других метриках.
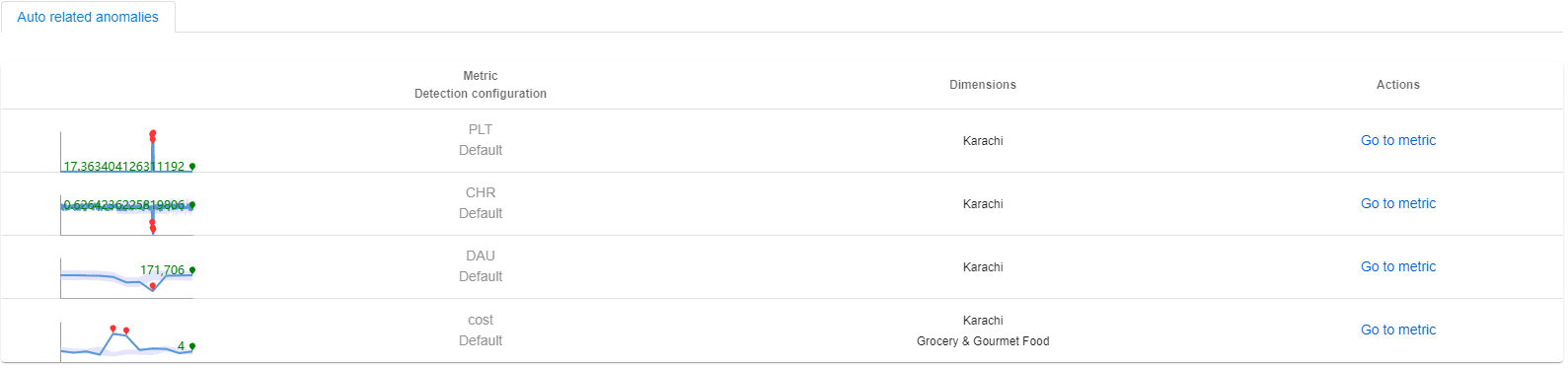
Например, если имеется инцидент, зафиксированный для метрик revenue. Самый верхний затронутый ряд находится в глобальном регионе с "region" = "SUM". При использовании диагностики между измерениями первопричина находилась в "region" = "Karachi". Существует предварительно настроенный граф метрик, включающий метрики "revenue", "cost", "DAU", "PLT (page load time)" и "CHR (cache hit rate)".
Помощник по метрикам автоматически отфильтрует граф метрик по измерению первопричины "region" = "Karachi" и отобразит состояние аномалии для каждой метрики. Анализируя связь между метриками и состоянием аномалии, клиенты могут получить дополнительные сведения о первопричине.

Автоматические связанные аномалии
Применяя фильтр измерения первопричины к графу метрик, аномалии для каждой метрики в метке времени текущего инцидента будут автоматически связаны. Эти аномалии должны быть связаны с идентифицированной первопричиной текущего инцидента.