Примечание
Для доступа к этой странице требуется авторизация. Вы можете попробовать войти или изменить каталоги.
Для доступа к этой странице требуется авторизация. Вы можете попробовать изменить каталоги.
Пользовательский голос — это функция преобразования речи в текст, которая позволяет создавать однообразный, настраиваемый, искусственный голос для ваших приложений. С помощью пользовательского голоса вы можете создать очень естественно звучащий голос для вашего бренда или персонажей, предоставив образцы человеческой речи в качестве данных для точной настройки.
Внимание
Пользовательский доступ к голосовой связи ограничен на основе критериев соответствия и использования. Запросите доступ в форме приема.
Изначально текст в речь можно использовать со стандартными голосами для каждого поддерживаемого языка. Стандартные голоса хорошо подходят для большинства сценариев преобразования текста в речь, если не требуется уникальный голос.
Пользовательский голос основан на нейронной технологии преобразования текста в речь и многоязычной, многоголосой, универсальной модели. Вы можете создавать искусственные голоса, богатые стилями речи, или адаптируемые кросс-языки. Реалистичный и естественно звучащий голос, созданный на заказ, может представлять бренды, олицетворять машины и позволять пользователям взаимодействовать с приложениями в естественной манере. См. поддерживаемые языки для пользовательского голоса.
Как это работает?
Чтобы создать пользовательский голос, используйте Speech Studio для отправки записанного звука и соответствующих сценариев, обучения модели и развертывания голоса в настраиваемой конечной точке.
Создание отличного пользовательского голоса требует тщательного контроля качества на каждом шаге, от подготовки голосовой разработки и подготовки данных до развертывания модели голоса в вашей системе.
Прежде чем приступить к работе в Speech Studio, ознакомьтесь с некоторыми рекомендациями.
- Проектирование лица голоса, представляющего ваш бренд с помощью краткого документа persona. В этом документе определяются такие элементы, как характеристики голоса и образ, с которым связан голос. Это помогает управлять процессом создания пользовательской голосовой модели, включая определение сценариев, выбор таланта голоса, обучения и настройки голосовой связи.
- Выберите сценарий записи, чтобы представить пользовательские сценарии для голоса. К примеру, при создании бота для обслуживания клиентов можно использовать фразы из разговоров с ботами в качестве сценария записи. Включите в свои сценарии различные типы предложений, включая утверждения, вопросы и восклицания.
Ниже приведен обзор действий по созданию пользовательского голоса в Speech Studio:
- Создайте проект для хранения данных, голосовых моделей, тестов и конечных точек. Каждый проект зависит от страны или региона и языка. Если вы собираетесь создать несколько голосов, рекомендуется создать проект для каждого голоса.
- Настройте талант голоса. Прежде чем вы сможете точно настроить профессиональный голос, необходимо отправить запись согласия диктора. Заявление диктора — это аудиозапись, на которой диктор зачитывает заявление о том, что он дает согласие на использование его речевых данных для профессиональной подстройки голоса.
- Подготовьте данные точной настройки в правильном формате. Рекомендуется записывать аудио в профессиональной студии звукозаписи, чтобы обеспечить оптимальное соотношение “сигнал/шум”. Качество голосовой модели сильно зависит от данных тонкой настройки. Требуются постоянная громкость, скорость речи, высота тона и последовательность в выразительных манерах речи.
- Обучение голосовой модели. Выберите по крайней мере 300 речевых фрагментов, чтобы создать пользовательский голос. При загрузке автоматически выполняется серия проверок качества данных. Чтобы создать высококачественные модели голоса, следует исправить ошибки и отправить данные еще раз.
- Проверьте голос. Подготовьте тестовые сценарии для своей модели голоса, которые охватывают различные варианты использования ваших приложений. Рекомендуется использовать скрипты, входящие и не входящие в набор обучающих данных, чтобы провести более широкую проверку качества для различного содержимого.
- Развертывание и использование голосовой модели в приложениях.
Вы можете настраивать, регулировать и использовать пользовательский голос так же, как и стандартный. Преобразуйте текст в речь в режиме реального времени или создайте звуковое содержимое в автономном режиме с помощью ввода текста. Вы используете REST API, пакет SDK службы "Речь" или "Речь".
Совет
Ознакомьтесь с примерами кода в репозитории пакета SDK службы "Речь" на сайте GitHub , чтобы узнать, как использовать пользовательский голос в приложении.
Стиль и характеристики модели обученного голоса зависят от стиля и качества записей голосового таланта, используемого для обучения. Тем не менее, можно внести некоторые корректировки с помощью SSML (языка разметки синтеза речи) при выполнении вызовов API к модели голоса для генерации синтетической речи. SSML — это язык разметки, используемый для обмена данными с текстом в службу распознавания речи для преобразования текста в звук. Корректировки включают изменение высоты звука, скорости, интонации и коррекцию произношения. Если модель голоса построена с использованием нескольких стилей, SSML также можно использовать для переключения стилей.
Последовательность компонентов
Пользовательский голос состоит из трех основных компонентов: текстового анализатора, нейронной акустической модели и нейронного вокодера. Чтобы преобразовать текст в естественно звучащую искусственную речь, его сначала вводят в анализатор текста, который предоставляет выходные данные в виде последовательности фонем. Фонема — это базовая единица звукового строя языка, которая служит для различения слов на определенном языке. Последовательность фонем определяет произношение слов в тексте.
После этого последовательность фонем передается в нейронную акустическую модель для прогнозирования характеристик звучания, которые определяют речевые сигналы. Акустические характеристики включают тембр, стиль и скорость речи, интонации и систему ударений. На заключительном этапе нейронный вокодер преобразует характеристики звучания в звуковые волны, создавая искусственный голос.
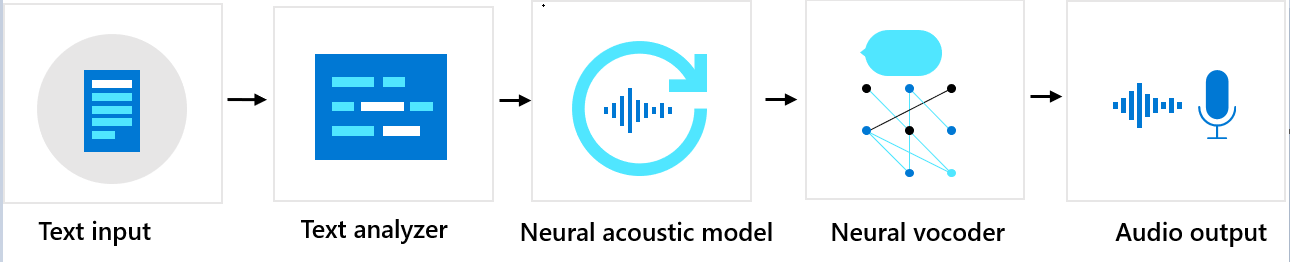
Нейронный текст для голосовых моделей обучен с помощью глубоких нейронных сетей на основе образцов записей человеческих голосов. Дополнительные сведения см. в этой записи блога Microsoft. Подробнее об обучении нейронного вокодера см. в этой записи блога Microsoft.
Ответственное применение ИИ
Система ИИ включает не только технологию, но и людей, которые используют ее, людей, пострадавших от нее, и среды, в которой она развернута. Ознакомьтесь с заметками о прозрачности, чтобы узнать об использовании и развертывании ответственного искусственного интеллекта в системах.
- Заметка о прозрачности и варианты использования пользовательского голоса
- Характеристики и ограничения использования пользовательского голоса
- Ограниченный доступ к пользовательскому голосу
- Рекомендации по ответственному развертыванию искусственной голосовой технологии
- Раскрытие информации о таланте голоса
- Рекомендации по проектированию раскрытия информации
- Шаблоны проектирования раскрытия информации
- Кодекс поведения для интеграции речи с текстом
- Данные, конфиденциальность и безопасность для пользовательского голоса