Руководство. Создание и развертывание copilot вопросов и ответов с помощью потока запросов в Azure AI Studio
Внимание
Некоторые функции, описанные в этой статье, могут быть доступны только в предварительной версии. Эта предварительная версия предоставляется без соглашения об уровне обслуживания, и мы не рекомендуем ее для рабочих нагрузок. Некоторые функции могут не поддерживаться или их возможности могут быть ограничены. Дополнительные сведения см. в статье Дополнительные условия использования Предварительных версий Microsoft Azure.
В этом руководстве по Azure AI Studio вы используете генерируемый ИИ и поток запросов для создания, настройки и развертывания copilot для вашей розничной компании с именем Contoso. Ваша розничная компания специализируется на открытом кемпинге шестеренки и одежды.
Copilot должен ответить на вопросы о ваших продуктах и услугах. Он также должен отвечать на вопросы о ваших клиентах. Например, копилот может ответить на такие вопросы, как "Сколько стоит походная обувь TrailWalker?" и "Сколько следуокуок походной обуви купил Даниэль Уилсон?".
Последовательность действий будет следующей:
- Добавьте данные на площадку чата.
- Создайте поток запроса с игровой площадки.
- Настройка потока запросов с помощью нескольких источников данных.
- Оцените поток с помощью набора данных оценки вопросов и ответов.
- Разверните поток для потребления.
Необходимые компоненты
Подписка Azure — создайте бесплатную учетную запись.
Центр AI Studio, проект и развернутая модель чата Azure OpenAI. Выполните краткое руководство по созданию этих ресурсов, если вы еще не сделали этого.
Подключение azure AI служба для индексирования образца продукта и данных клиента.
Вам нужна локальная копия данных продукта и клиента. Репозиторий Azure-Samples/aistudio-python-quickstart-sample на сайте GitHub содержит примеры сведений о розничных клиентах и продуктах, которые относятся к этому сценарию руководства. Клонируйте репозиторий или скопируйте файлы из 1-customer-info и 3-product-info.
Добавьте данные и повторите попытку модели чата
В кратком руководстве по игровой площадке AI Studio (это необходимое условие для работы с этим руководством), вы можете наблюдать, как модель реагирует без данных. Теперь вы добавите данные в модель, чтобы ответить на вопросы о продуктах.
Для выполнения этого раздела потребуется локальная копия данных продукта. Репозиторий Azure-Samples/aistudio-python-quickstart-sample на сайте GitHub содержит примеры сведений о розничных клиентах и продуктах, которые относятся к этому сценарию руководства. Клонируйте репозиторий или скопируйте файлы из 3-product-info.
Внимание
Функция "Добавить данные " на игровой площадке Azure AI Studio не поддерживает использование виртуальной сети или частной конечной точки на следующих ресурсах:
- Поиск с использованием ИИ Azure
- Azure OpenAI
- ресурс хранилища;
Выполните следующие действия, чтобы добавить данные на площадку чата, чтобы помочь помощнику ответить на вопросы о продуктах. Вы не изменяете развернутую модель. Данные хранятся отдельно и безопасно в подписке Azure.
Перейдите к проекту в Azure AI Studio.
Выберите "Чат на площадке">в левой области.
Выберите развернутую модель чата в раскрывающемся списке развертывания .
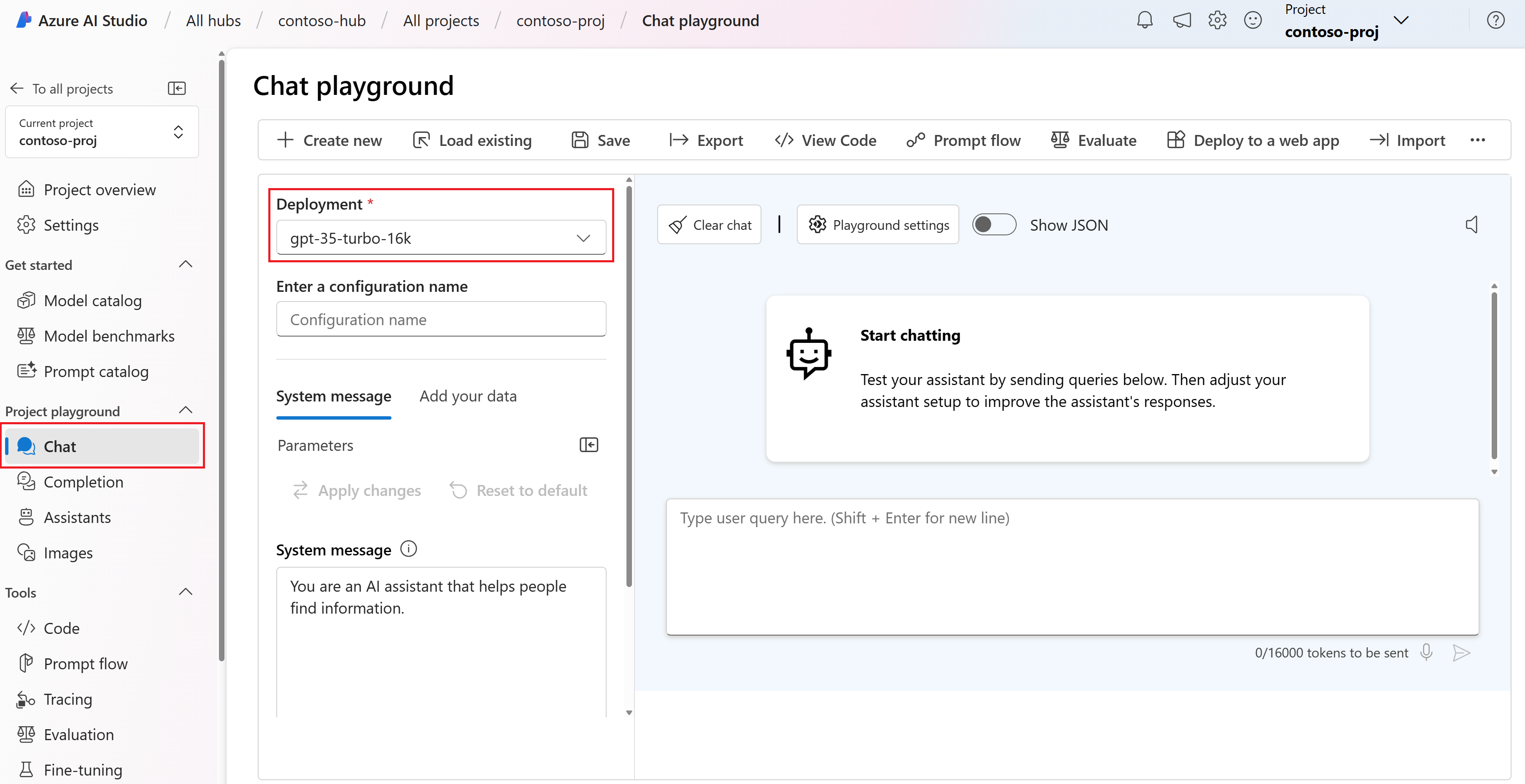
В левой части игровой площадки чата нажмите кнопку "Добавить данные>+ Добавить новый источник данных".
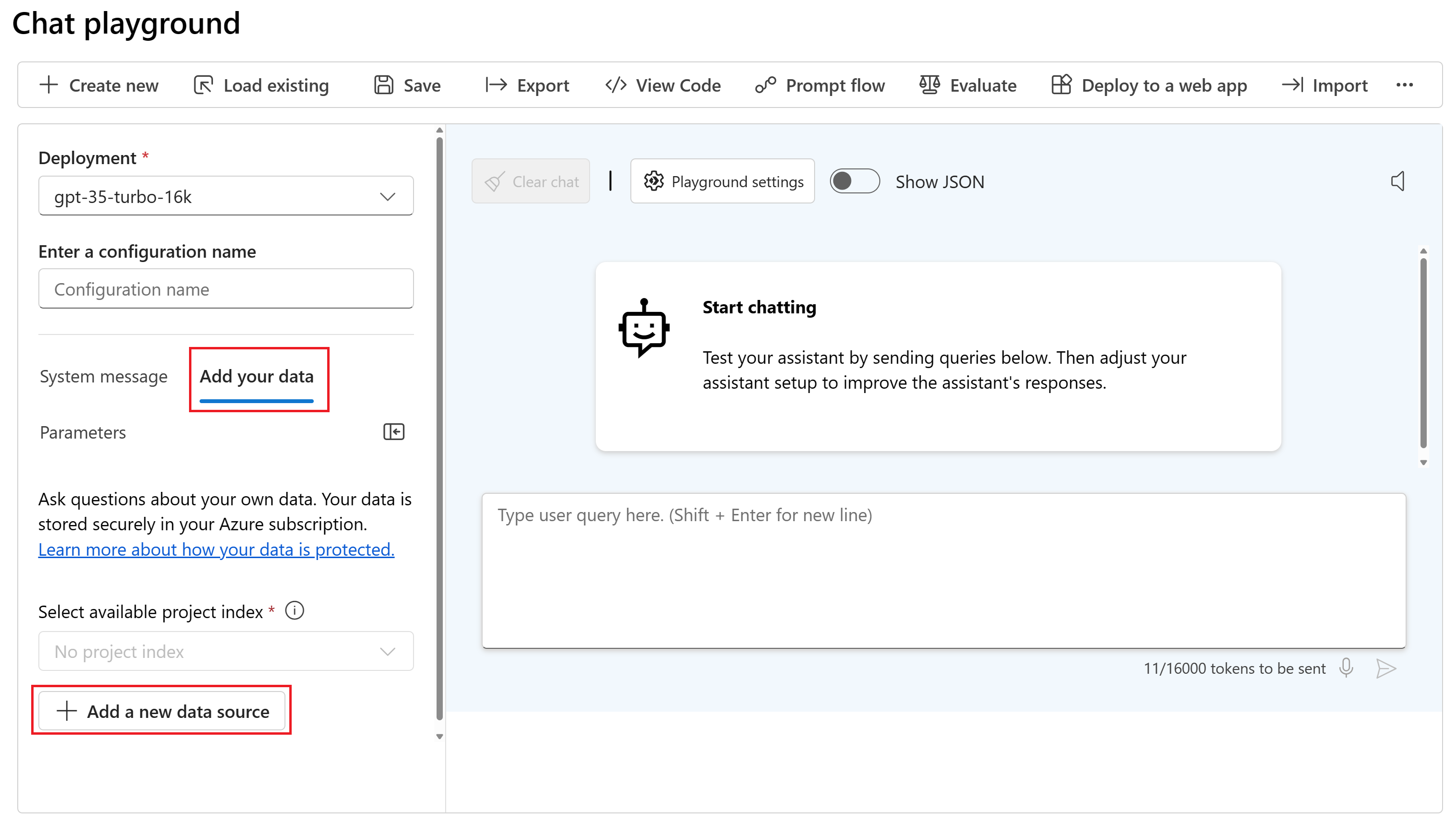
В раскрывающемся списке источника данных выберите " Отправить файлы".
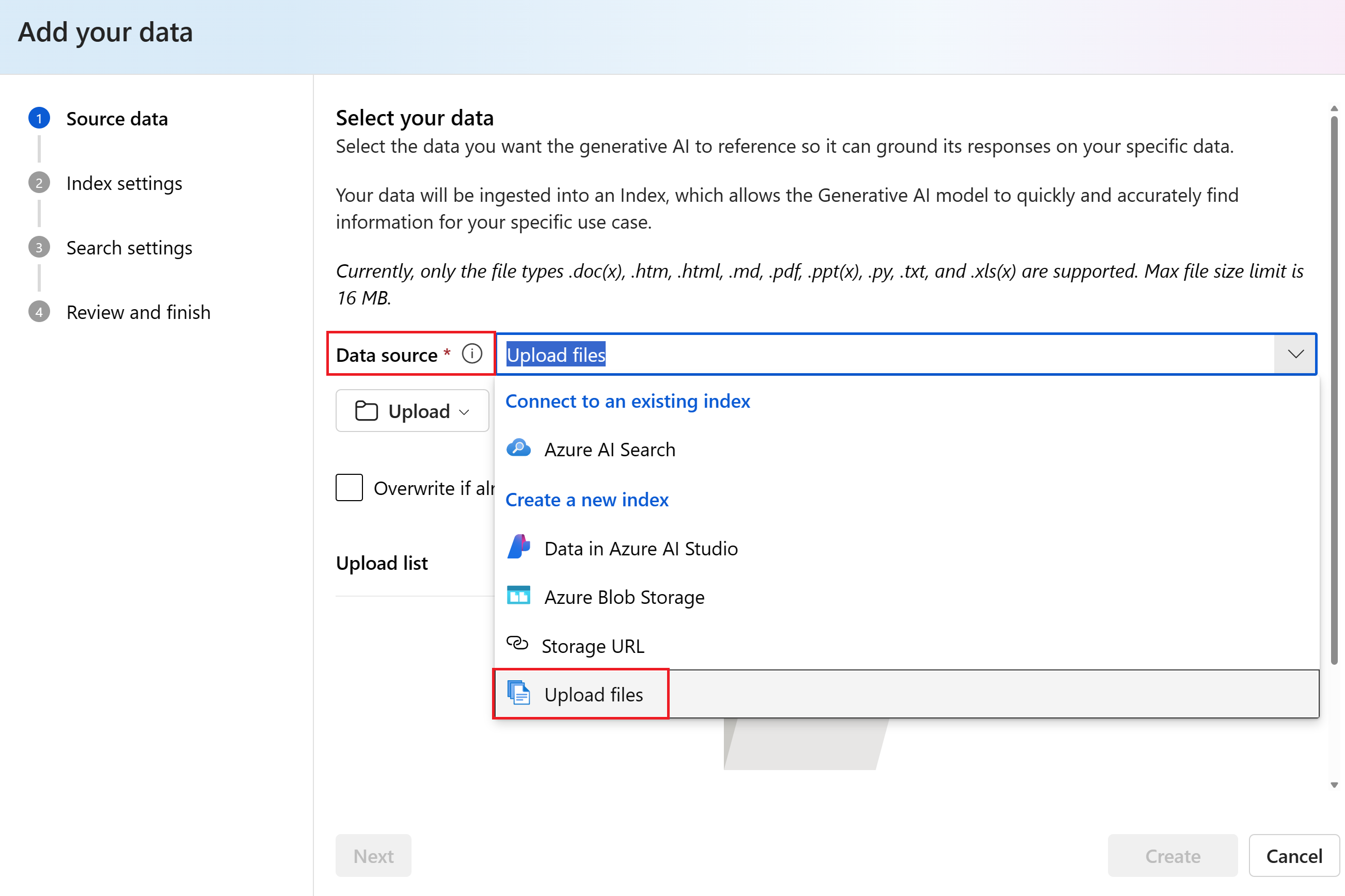
Выберите "Отправить>файлы", чтобы просмотреть локальные файлы.
Выберите файлы, которые нужно отправить. Выберите файлы сведений о продукте (3-product-info), скачанные или созданные ранее. Добавьте все файлы. Вы не сможете добавлять дополнительные файлы позже в том же сеансе игровой площадки.
Выберите " Отправить ", чтобы отправить файл в учетную запись хранения BLOB-объектов Azure. Затем выберите Далее.
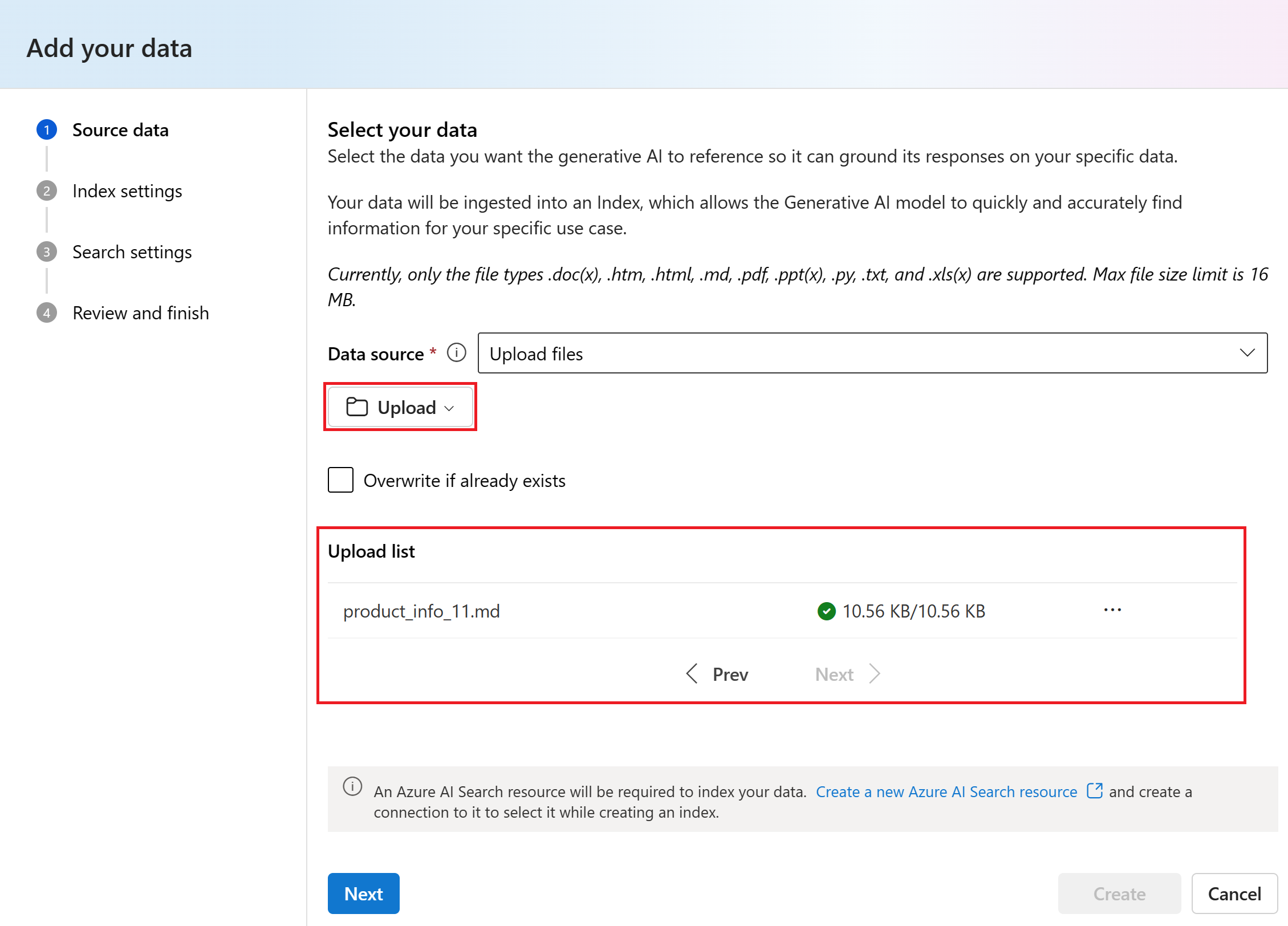
Выберите служба ИИ Azure. В этом примере выберите "Подключить другой ресурс поиска ИИ Azure" в раскрывающемся списке "Выбор ИИ Azure" служба . Если у вас нет ресурса поиска, его можно создать, нажав кнопку "Создать новый ресурс поиска ИИ Azure". Затем вернитесь к этому шагу, чтобы подключиться и выбрать его.
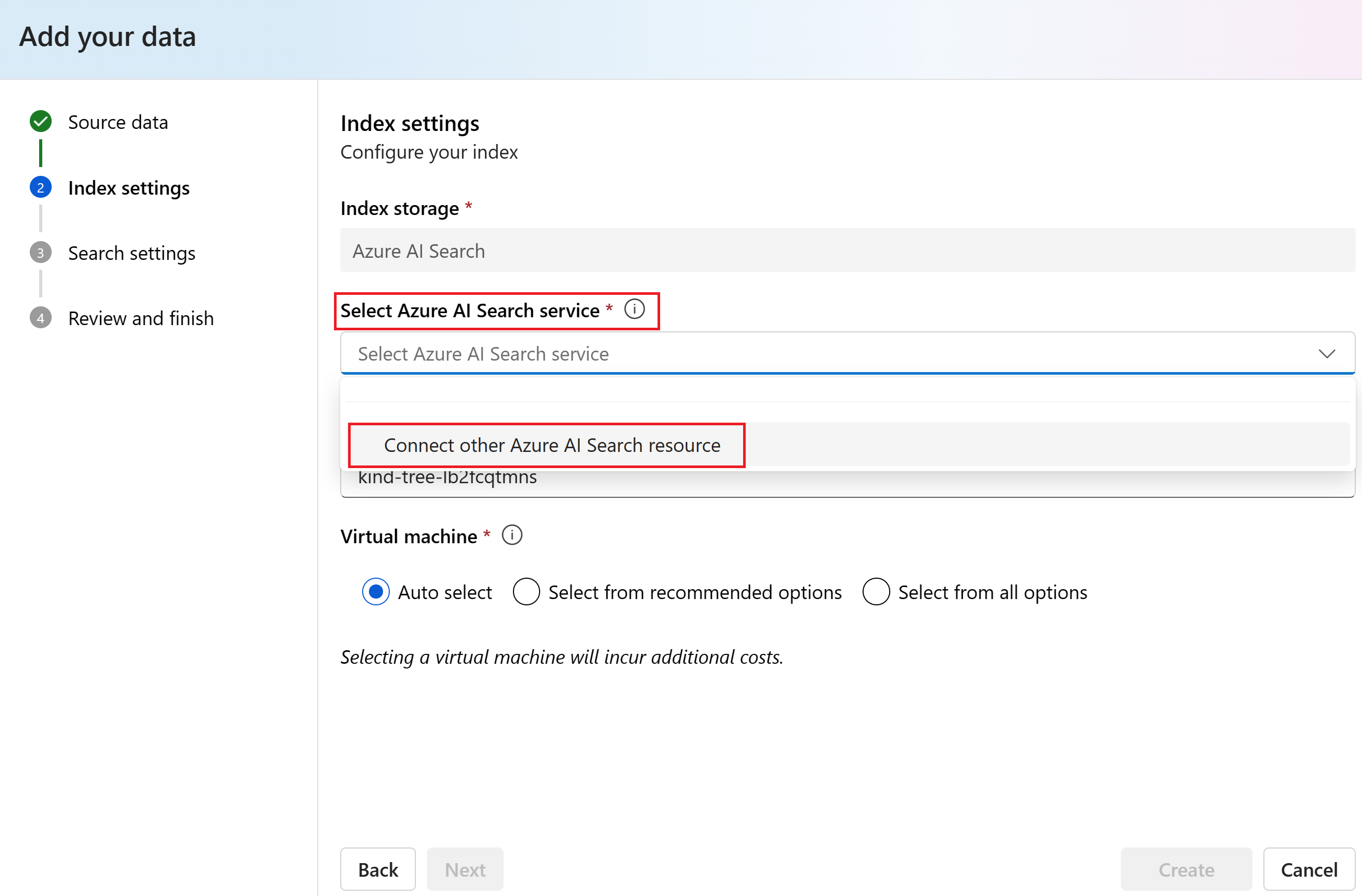
Найдите служба ИИ Azure и нажмите кнопку "Добавить подключение".
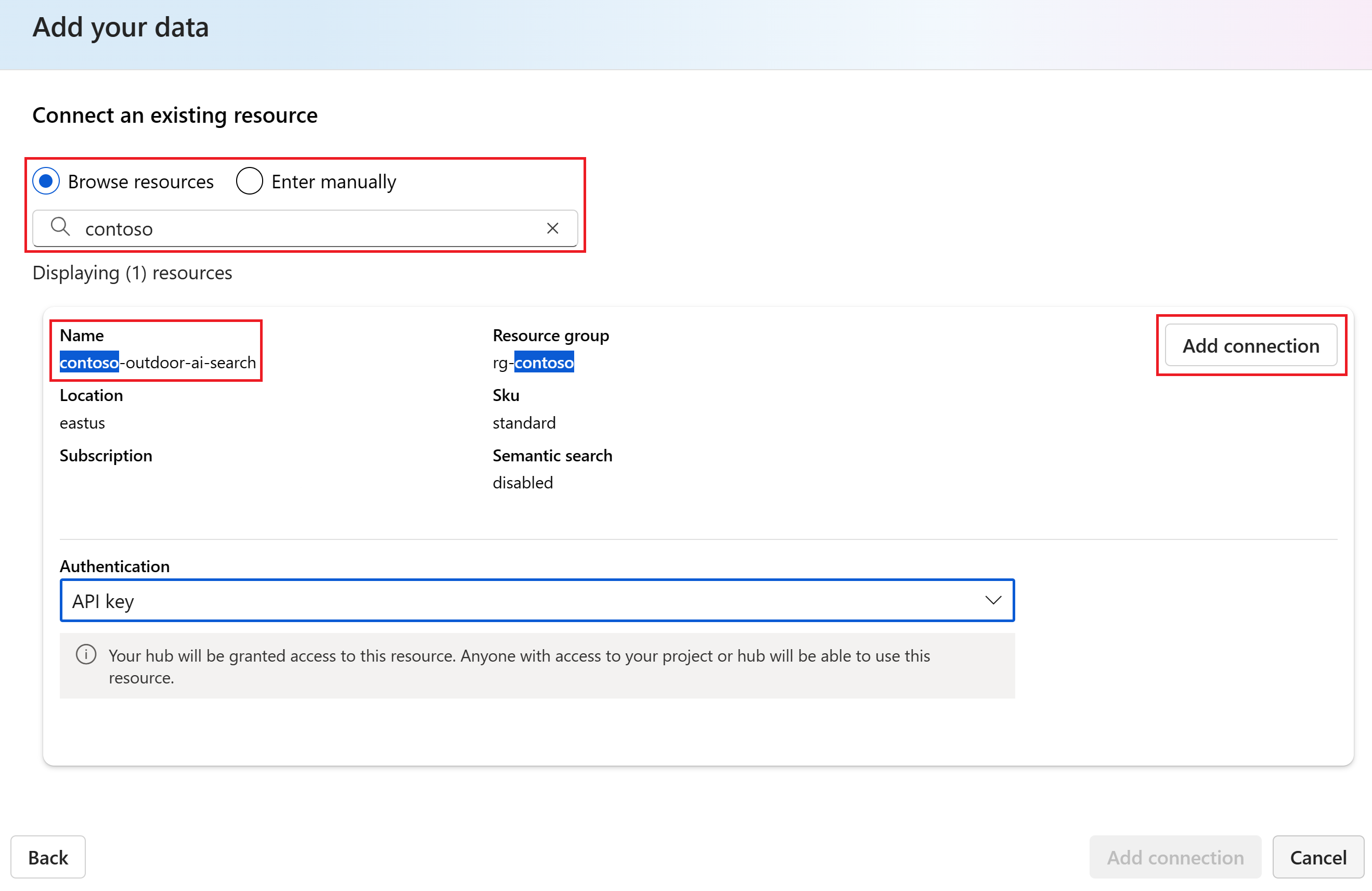
В поле "Индекс" введите сведения о продукте и нажмите кнопку "Далее".
На странице параметров поиска в разделе "Векторные параметры" установите флажок "Добавить векторный поиск" в этот ресурс поиска. Этот параметр помогает определить, как модель реагирует на запросы. Затем выберите Далее.
Примечание.
Если добавить векторный поиск, дополнительные параметры будут доступны здесь для дополнительной стоимости.
Проверьте параметры и нажмите Создать.
На детской площадке вы увидите, что прием данных выполняется. Этот процесс может занять несколько минут. Прежде чем продолжить, подождите, пока не увидите имя источника данных и индекса вместо состояния.
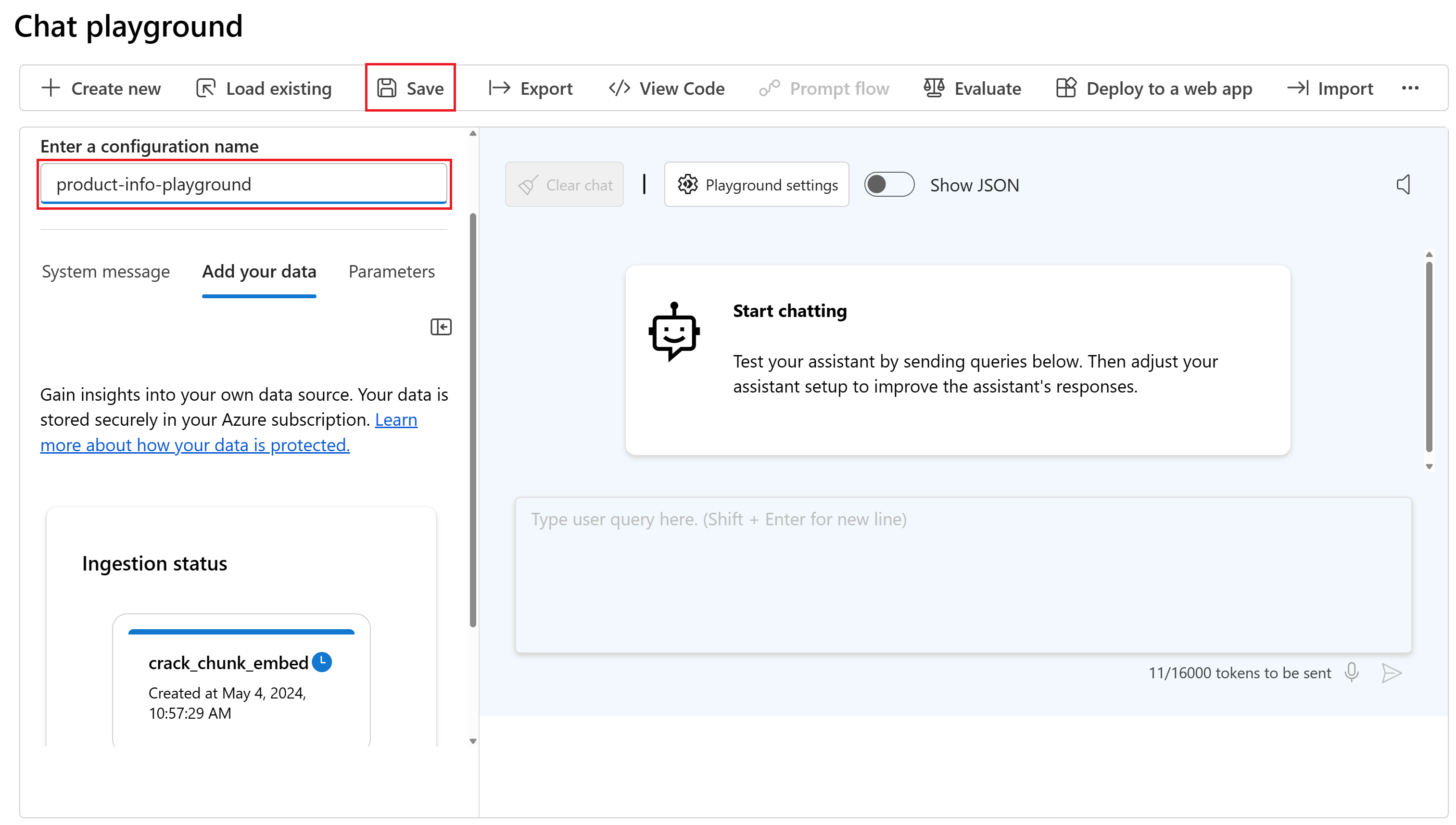
Введите имя конфигурации игровой площадки и нажмите кнопку "Сохранить".> Все элементы конфигурации сохраняются по умолчанию. Элементы включают развертывание, системное сообщение, сообщение безопасности, параметры, добавленные данные, примеры и переменные. Сохранение конфигурации с тем же именем сохранится в предыдущей версии.
Теперь вы можете общаться с моделью, задавая тот же вопрос, что и раньше ("Сколько это походная обувь TrailWalker"), и на этот раз он использует информацию из данных для создания ответа. Чтобы просмотреть используемые данные, можно развернуть кнопку ссылок .








Создание потока запроса с игровой площадки
Теперь вы можете спросить: "Как можно дополнительно настроить этот copilot?" Может потребоваться добавить несколько источников данных, сравнить различные запросы или производительность нескольких моделей. Поток запросов служит исполняемым рабочим процессом, упрощающим разработку приложения ИИ на основе LLM. Она предоставляет комплексную платформу для управления потоком данных и обработкой в приложении. Вы используете поток запросов для оптимизации сообщений, отправленных в модель чата copilot.
В этом разделе описано, как перейти к потоку запросов с игровой площадки. Вы экспортируете среду чата для игровой площадки, включая подключения к добавленным данным. Далее в этом руководстве вы оцениваете поток, а затем развертываете поток для потребления.
Примечание.
Изменения, внесенные в поток запросов, не применяются назад для обновления среды игровой площадки.
Вы можете создать поток запроса на игровой площадке, выполнив следующие действия.
Перейдите к проекту в AI Studio.
Выберите "Чат на площадке">в левой области.
Так как мы используем собственные данные, необходимо выбрать команду "Добавить данные". У вас уже должен быть индекс с именем product-info , созданный ранее на игровой площадке чата. Выберите его в раскрывающемся списке "Выбрать доступный индекс проекта". В противном случае сначала создайте индекс с данными продукта, а затем вернитесь к этому шагу.
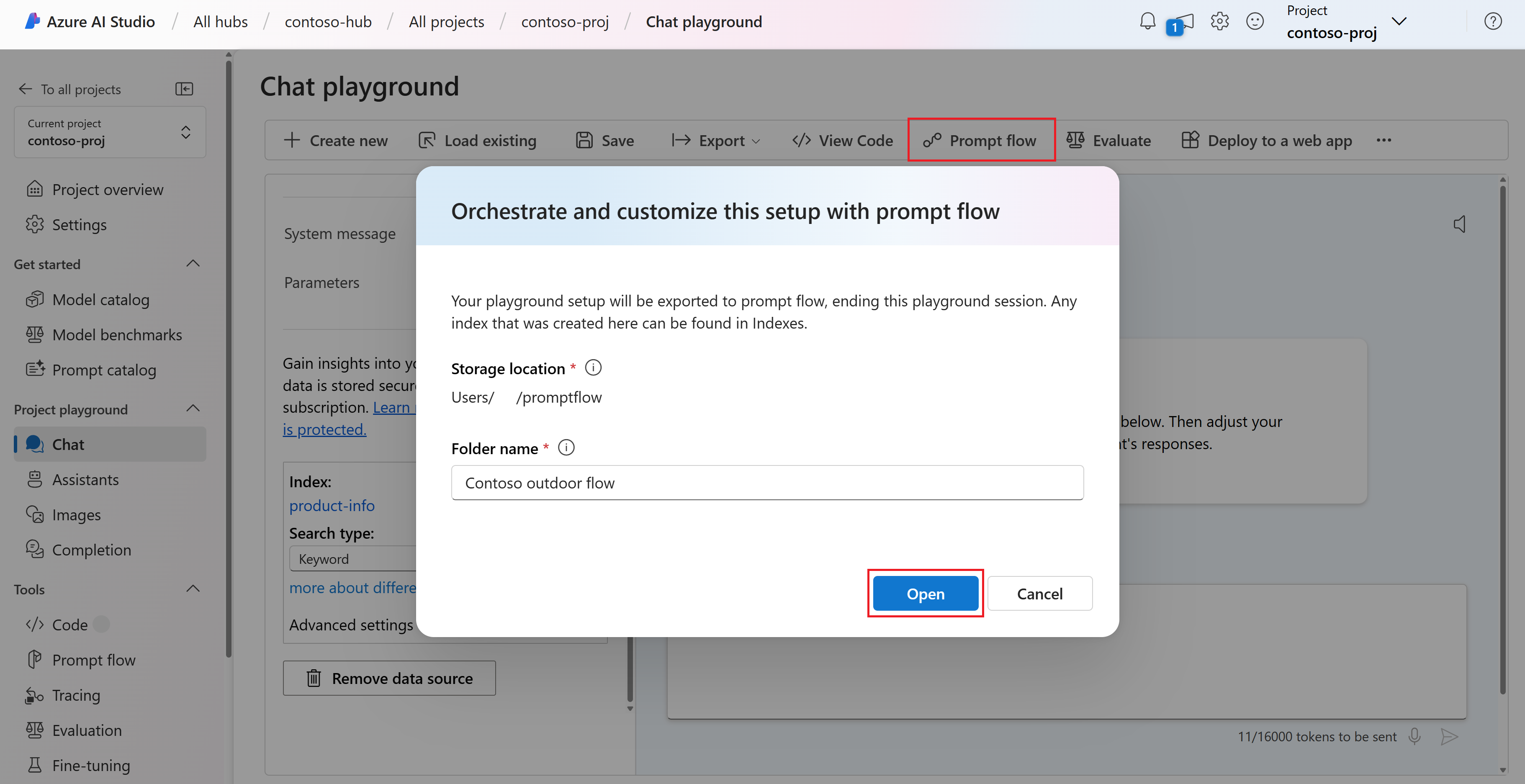
Выберите поток запроса из меню над областью сеанса чата.
Введите имя папки для потока запроса. Щелкните Открыть. Ai Studio экспортирует среду чата для игровой площадки для запроса потока. Экспорт включает подключения к добавленным данным.

В потоке узлы занимают центральное место, представляющее определенные инструменты с уникальными возможностями. Эти узлы обрабатывают обработку данных, выполнение задач и алгоритмические операции с входными и выходными данными. Подключая узлы, вы создаете простую цепочку операций, которые управляют потоком данных через приложение. Дополнительные сведения см . в средствах потока запросов.
Для упрощения настройки узла и тонкой настройки визуальное представление структуры рабочего процесса предоставляется с помощью графа DAG (ациклический граф). На этом графике показана связь и зависимости между узлами, обеспечивающая четкий обзор всего рабочего процесса. Узлы в графе, показанные здесь, представляют собой интерфейс чата для игровой площадки, экспортируемый для потока запроса.

В потоке запросов также должно появиться следующее:
- Кнопка "Сохранить": вы можете сохранить поток запроса в любое время, нажав кнопку "Сохранить" в верхнем меню. Не забудьте периодически сохранять поток запросов при внесении изменений в этом руководстве.
- Кнопка запуска сеанса вычислений. Для запуска потока запроса необходимо запустить вычислительный сеанс. Вы можете запустить сеанс позже в руководстве. Затраты на вычислительные экземпляры возникают во время их выполнения. Дополнительные сведения см. в статье о создании сеанса вычислений.

Вы можете вернуться к потоку запроса в любое время, выбрав поток запроса из инструментов в меню слева. Затем выберите созданную ранее папку потока запроса.

Настройка потока запросов с помощью нескольких источников данных
ранее на игровой площадке чата AI Studio вы добавили данные для создания одного индекса поиска, содержащего данные продукта для компании Contoso copilot. До сих пор пользователи могут только узнать о продуктах с такими вопросами, как "Сколько стоит походная обувь TrailWalker?". Но они не могут получить ответы на такие вопросы, как "Сколько Следуокер походные обувь купил Даниэль Уилсон?" Чтобы включить этот сценарий, мы добавим еще один индекс с информацией о клиенте в поток.
Создание индекса сведений о клиенте
Чтобы продолжить, вам потребуется локальная копия примеров сведений о клиенте. Дополнительные сведения и ссылки на примеры данных см. в предварительных требованиях.
Следуйте этим инструкциям по созданию нового индекса. Вы вернетесь к потоку запросов далее в этом руководстве, чтобы добавить сведения о клиенте в поток. Вы можете открыть новую вкладку в браузере, чтобы выполнить эти инструкции, а затем вернуться к потоку запроса.
Перейдите к проекту в AI Studio.
Выберите индекс в меню слева. Обратите внимание, что у вас уже есть индекс с именем product-info , созданный ранее на игровой площадке чата.
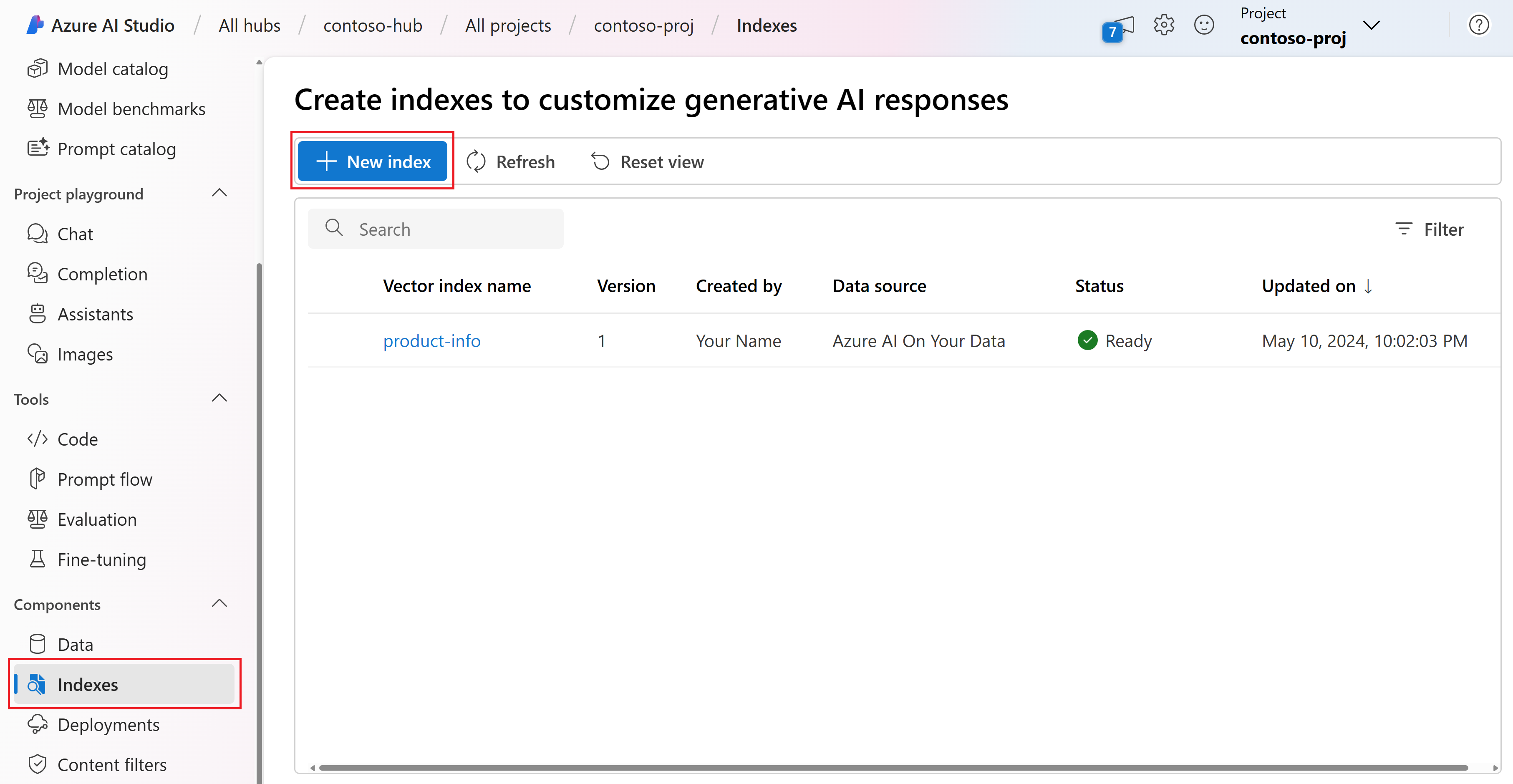
Выберите +Создать индекс. Вы перейдете в мастер создания индекса .
На странице "Исходные данные " выберите "Отправить файлы " в раскрывающемся списке источника данных. Затем выберите "Отправить>файлы", чтобы просмотреть локальные файлы.
Выберите файлы сведений о клиенте, скачанные или созданные ранее. См. предварительные требования. Затем выберите Далее.
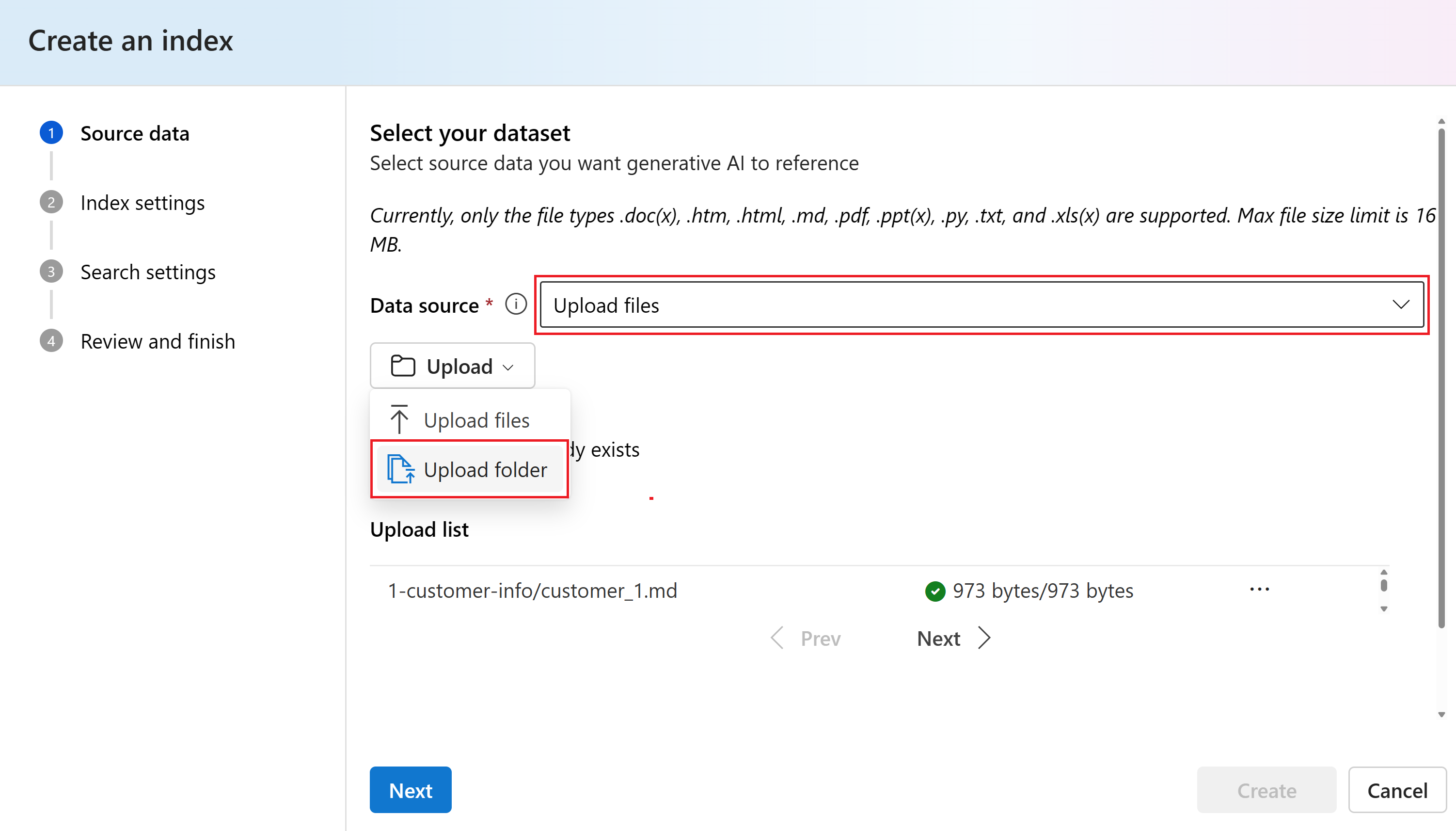
Выберите то же подключение azure AI служба (contosooutdooraisearch), которое использовалось для индекса сведений о продукте. Затем выберите Далее.
Введите сведения о клиенте для имени индекса.
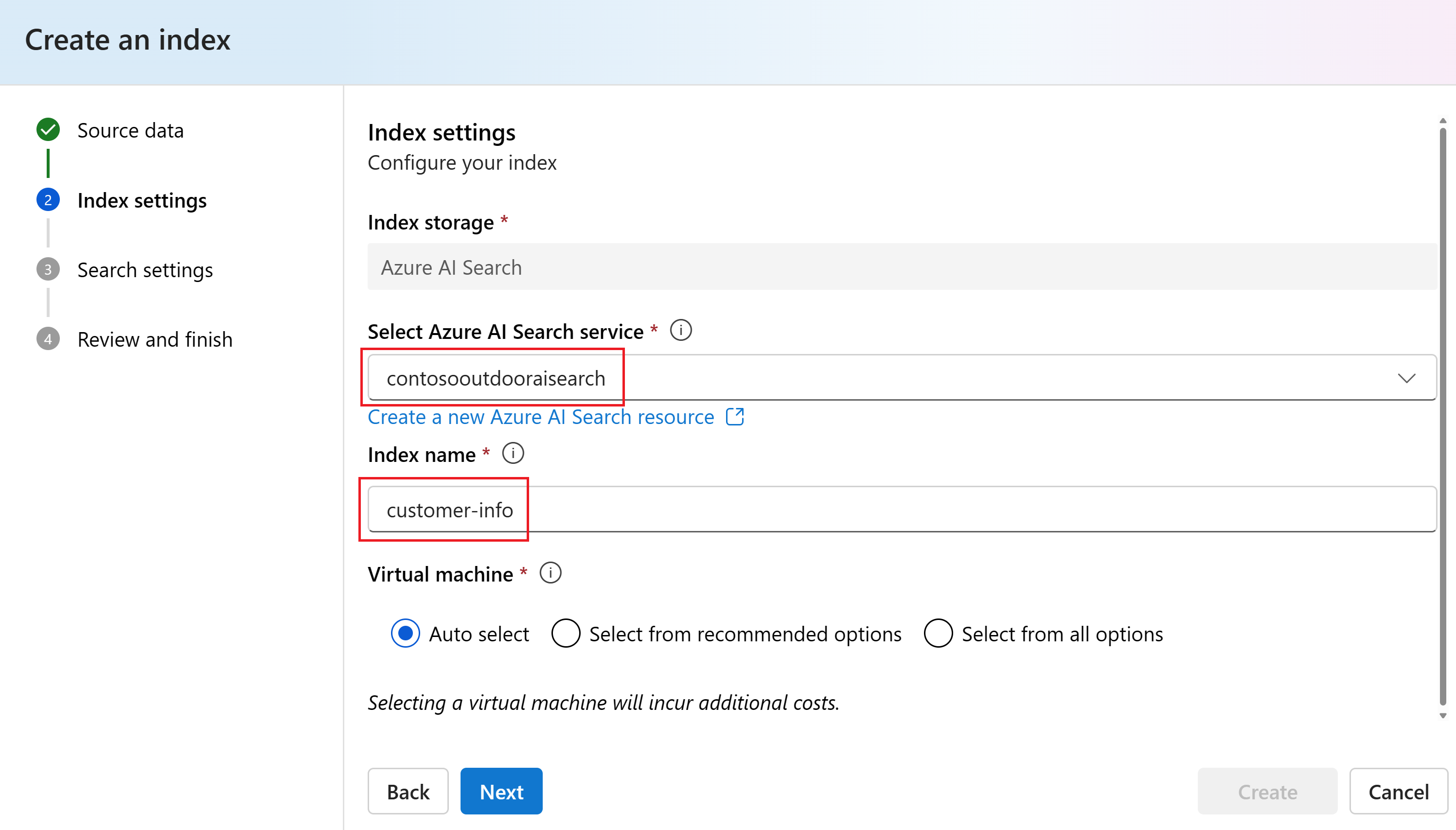
Выберите виртуальную машину для запуска заданий индексирования. Параметр по умолчанию — "Автоматический выбор". Затем выберите Далее.
На странице параметров поиска в разделе "Векторные параметры" установите флажок "Добавить векторный поиск" в этот ресурс поиска. Этот параметр помогает определить, как модель реагирует на запросы. Затем выберите Далее.
Примечание.
Если добавить векторный поиск, дополнительные параметры будут доступны здесь для дополнительной стоимости.
Просмотрите введенные сведения и нажмите кнопку "Создать".
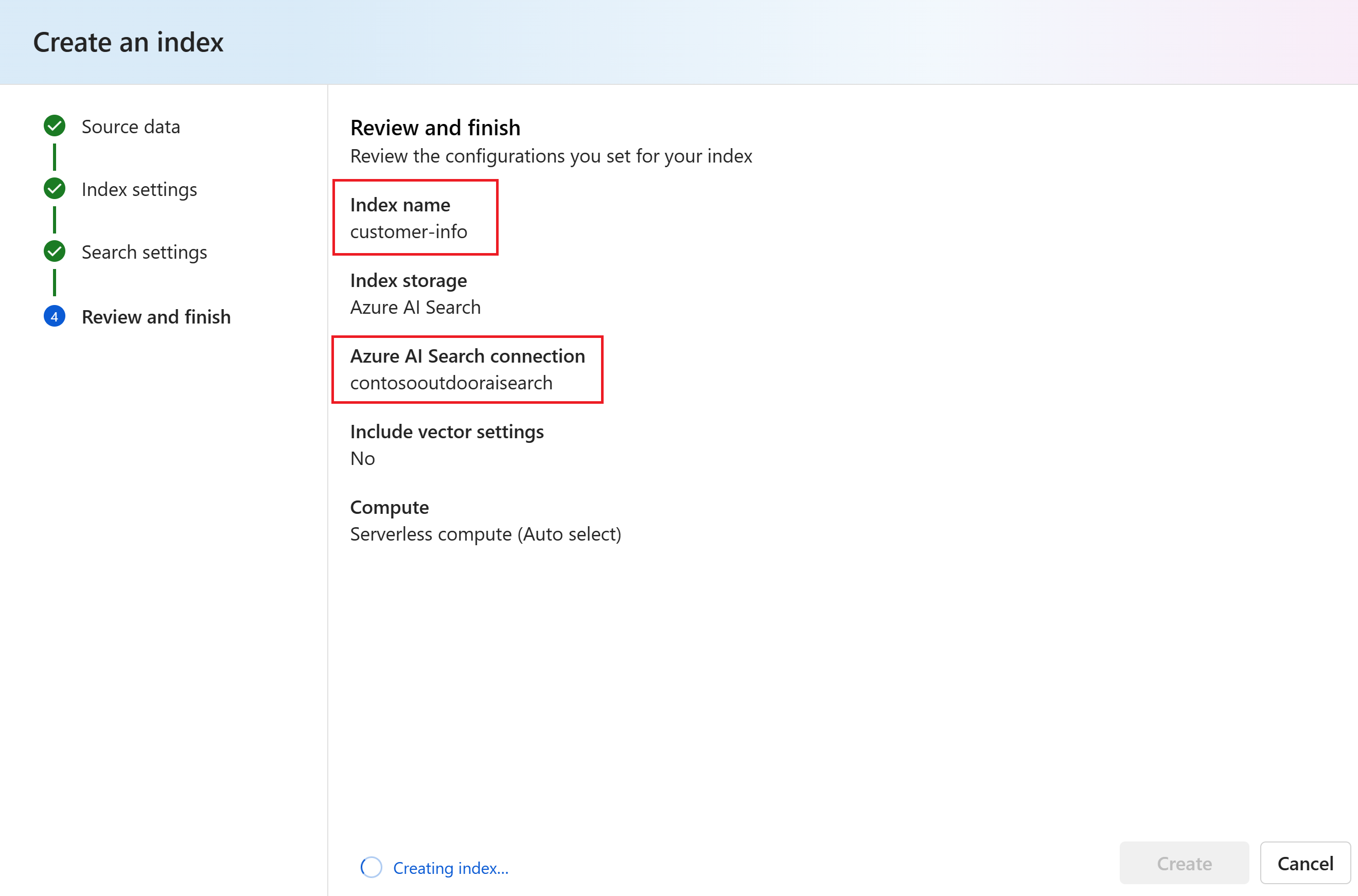
Примечание.
Вы используете индекс сведений о клиенте и подключение contosooutdooraisearch к служба Azure AI в потоке запросов далее в этом руководстве. Если введенные имена отличаются от указанных здесь имен, обязательно используйте имена, введенные в остальной части руководства.
Вы перейдете на страницу сведений об индексе, где можно просмотреть состояние создания индекса.
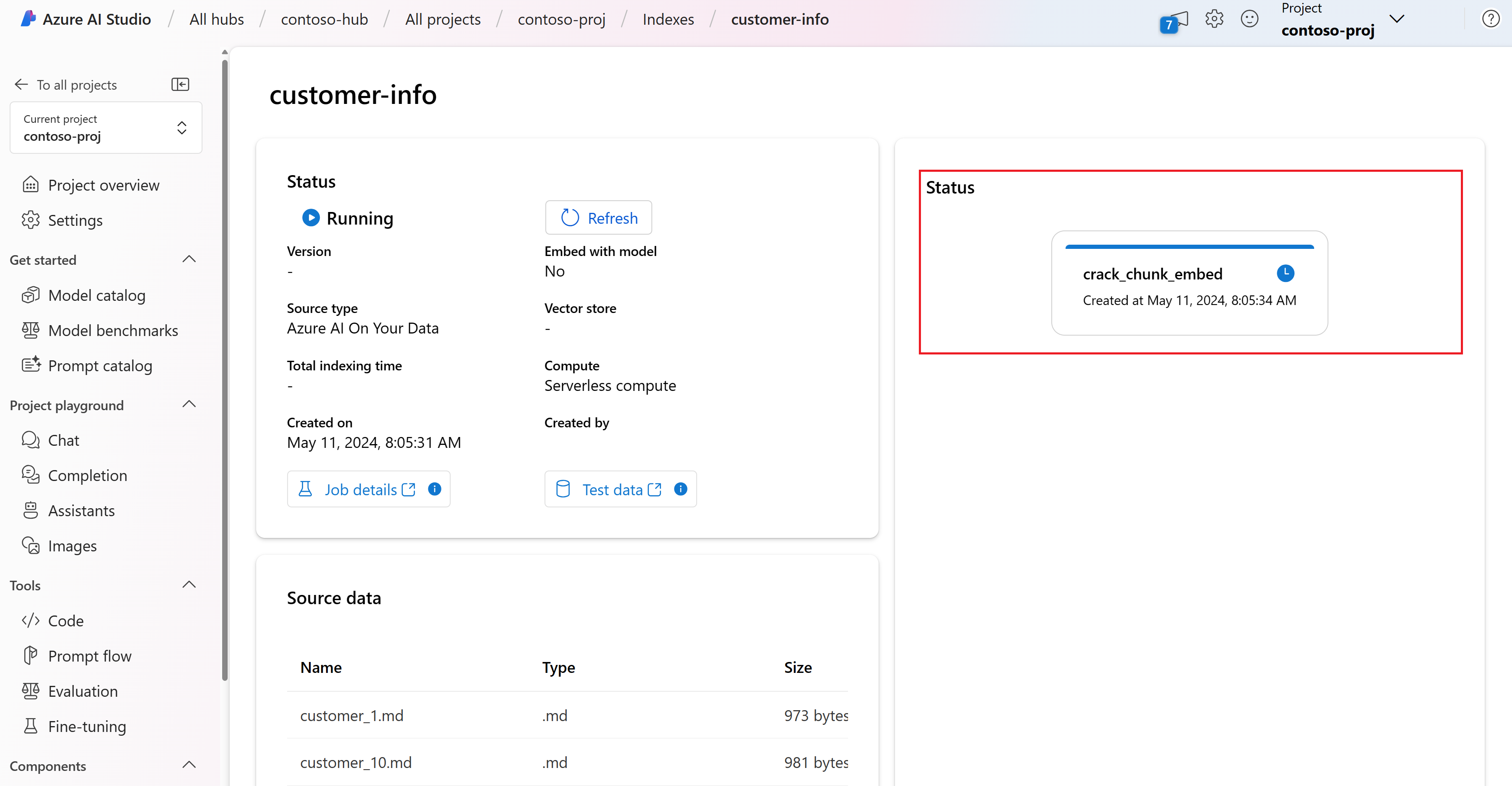





Дополнительные сведения о создании индекса см. в разделе "Создание индекса".
Создание вычислительного сеанса, необходимого для потока запросов
После создания индекса вернитесь в поток запроса и запустите сеанс вычислений. Поток запросов требует запуска вычислительного сеанса.
- Перейдите к своему проекту.
- Выберите поток запроса из меню "Сервис " в меню слева. Затем выберите созданную ранее папку потока запроса.
- Выберите "Пуск сеанса вычислений" в верхнем меню.
Чтобы создать вычислительный экземпляр и сеанс вычислений, также можно выполнить действия, описанные в руководстве по созданию вычислительного сеанса.
Чтобы завершить остальную часть учебника, убедитесь, что сеанс вычислений запущен.
Внимание
Плата взимается за вычислительные экземпляры во время их выполнения. Чтобы избежать ненужных затрат Azure, приостанавливайте вычислительный экземпляр, если вы не работаете в потоке запросов. Дополнительные сведения см. в статье о запуске и остановке вычислений.
Добавление сведений о клиентах в поток
После создания индекса вернитесь в поток запроса и выполните следующие действия, чтобы добавить сведения о клиенте в поток:
Убедитесь, что у вас запущен сеанс вычислений. Если у вас его нет, см . раздел "Создание сеанса вычислений" в предыдущем разделе.
Выберите +Другие инструменты в верхнем меню, а затем выберите "Поиск индекса" из списка инструментов.
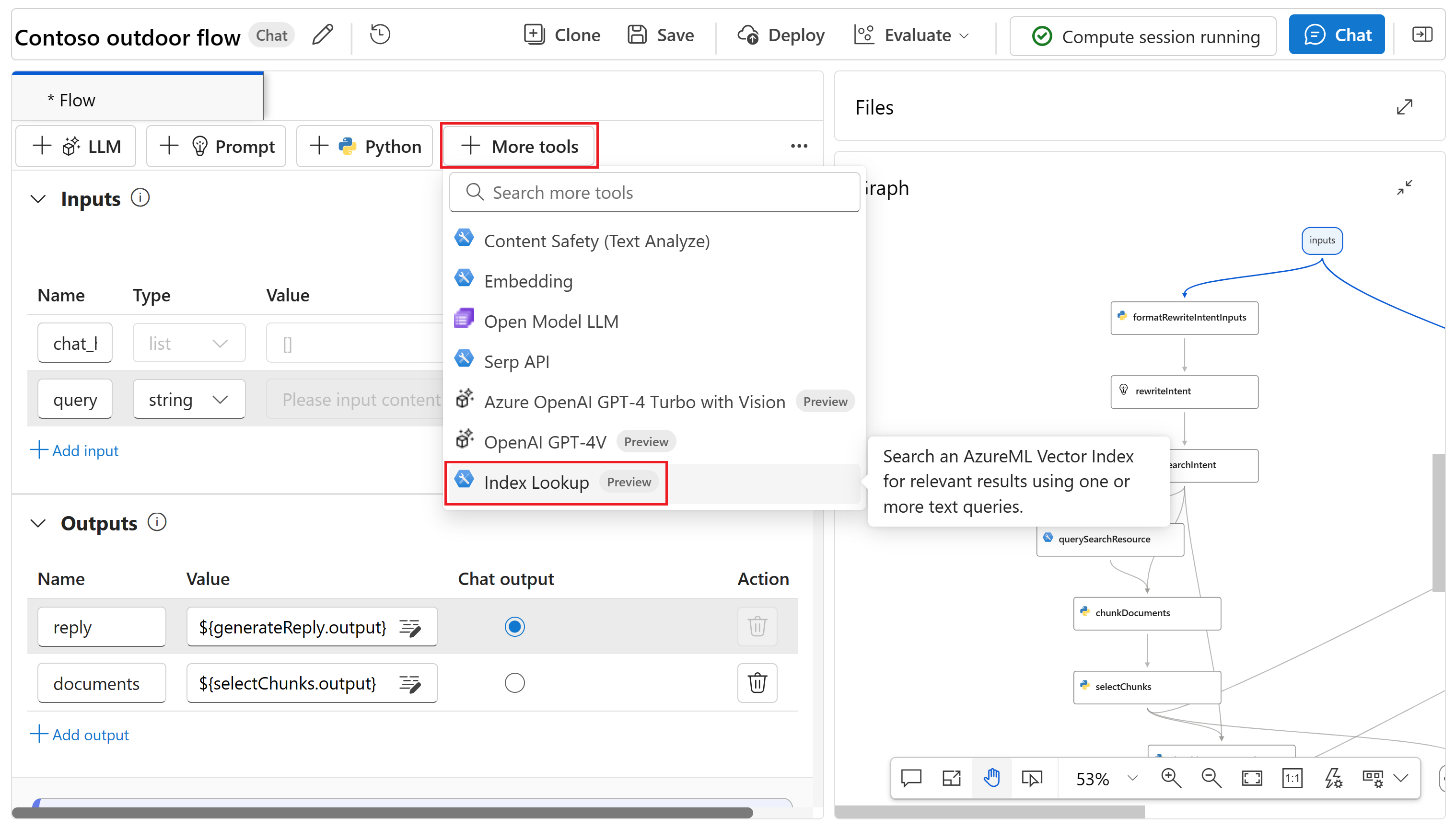
Назовите новый запрос узлаCustomerIndex и нажмите кнопку "Добавить".
Выберите текстовое поле mlindex_content в узле queryCustomerIndex.

Откроется диалоговое окно "Создать ". Это диалоговое окно используется для настройки узла queryCustomerIndex для подключения к индексу сведений о клиенте.
Для значения index_type выберите поиск по искусственному интеллекту Azure.
Введите или выберите следующие значения:
Имя. Значение acs_index_connection Имя подключения azure AI служба (например, contosooutdooraisearch) acs_index_name сведения о клиенте acs_content_field content acs_metadata_field meta_json_string semantic_configuration azuremldefault embedding_type Не допускается Нажмите кнопку Save (Сохранить), чтобы сохранить настройки.
Выберите или введите следующие значения для узла queryCustomerIndex :
Имя. Значение Запросов ${extractSearchIntent.output} query_type Ключевое слово topK 5 Узел queryCustomerIndex подключен к узлу extractSearchIntent в графе.
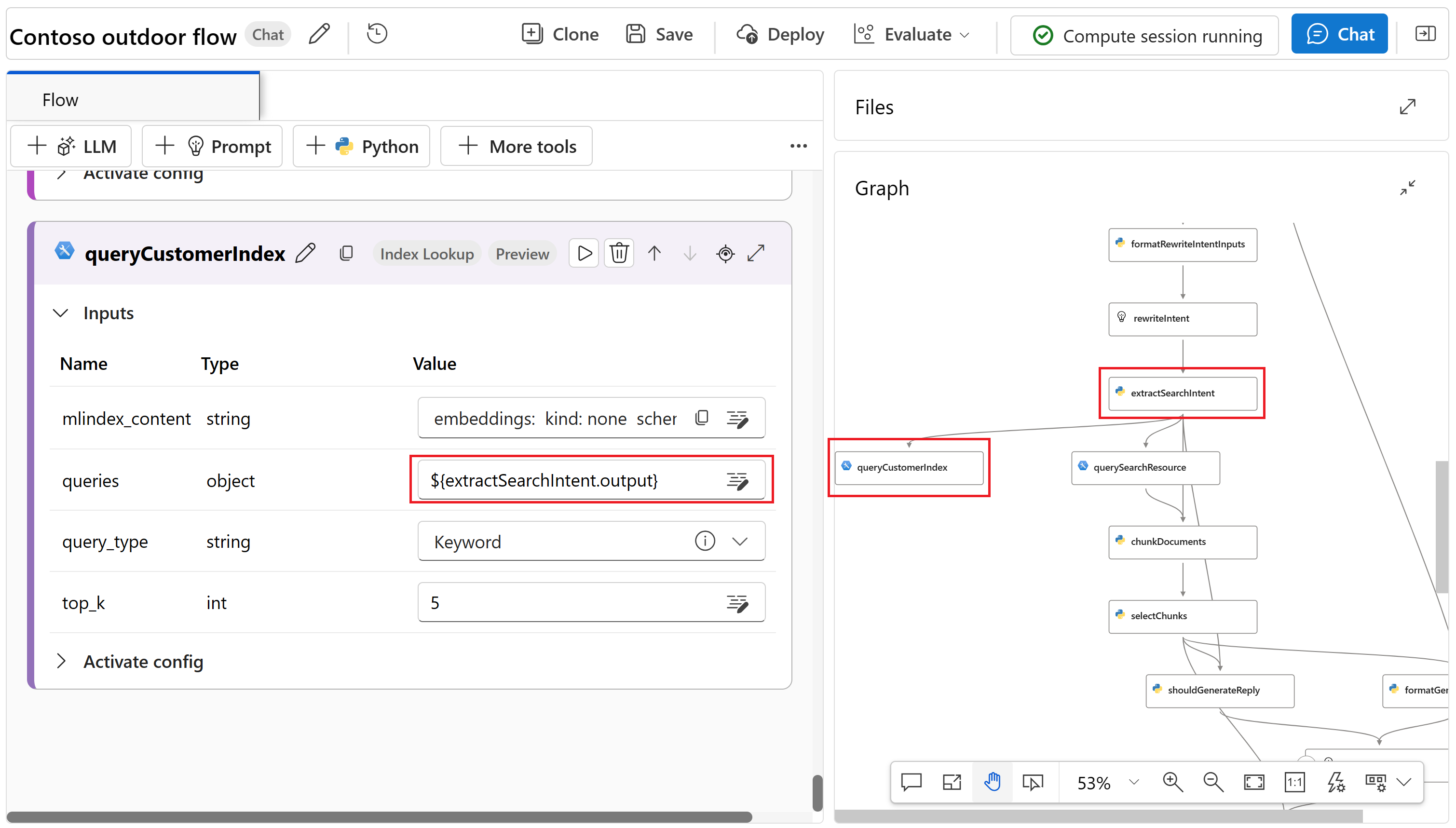
Нажмите кнопку "Сохранить " в верхнем меню, чтобы сохранить изменения. Не забудьте периодически сохранять поток запросов при внесении изменений.



Подключение сведений о клиенте к потоку
В следующем разделе вы агрегируете сведения о продукте и клиенте, чтобы вывести его в формате, который может использовать большая языковая модель. Но сначала необходимо подключить сведения о клиенте к потоку.
Щелкните значок многоточия рядом с + Другие инструменты , а затем выберите режим необработанного файла, чтобы переключиться в режим необработанного файла. Этот режим позволяет копировать и вставлять узлы в графе.
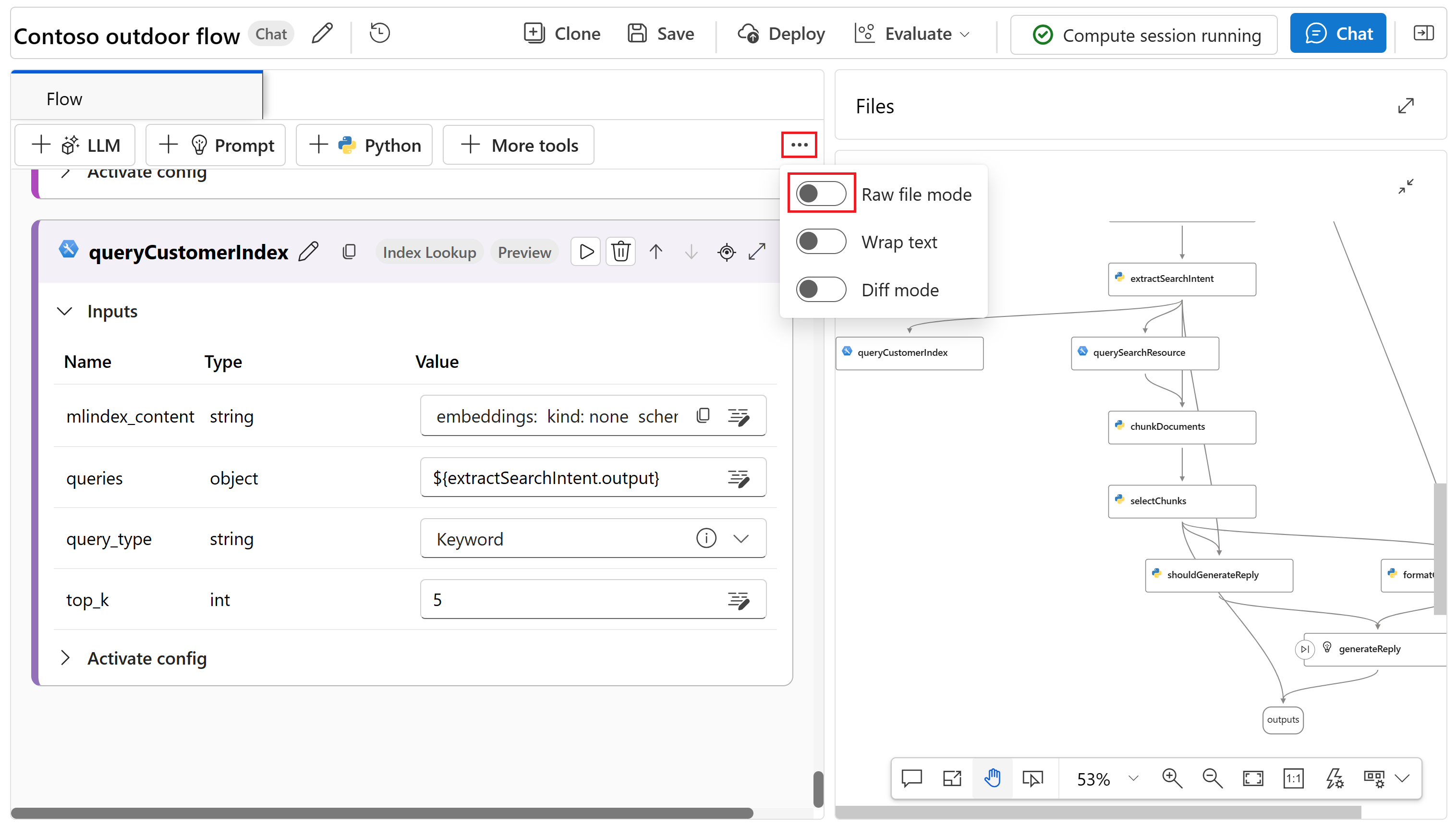
Замените все экземпляры querySearchResource на queryProductIndex в графе. Мы переименуем узел, чтобы лучше отразить, что он получает сведения о продукте и контрастирует с узлом queryCustomerIndex , добавленным в поток.
Переименуйте и замените все экземпляры chunkDocuments на chunkProductDocuments в графе.
Переименуйте и замените все экземпляры selectChunks на selectProductChunks в графе.
Скопируйте и вставьте узлы chunkProductDocuments и selectProductChunks , чтобы создать аналогичные узлы для сведений о клиенте. Переименуйте новые узлы chunkCustomerDocuments и selectCustomerChunks соответственно.
В узле chunkCustomerDocuments замените входные
${queryProductIndex.output}данные${queryCustomerIndex.output}.В узле selectCustomerChunks замените входные
${chunkProductDocuments.output}данные${chunkCustomerDocuments.output}.Нажмите кнопку "Сохранить " в верхнем меню, чтобы сохранить изменения.
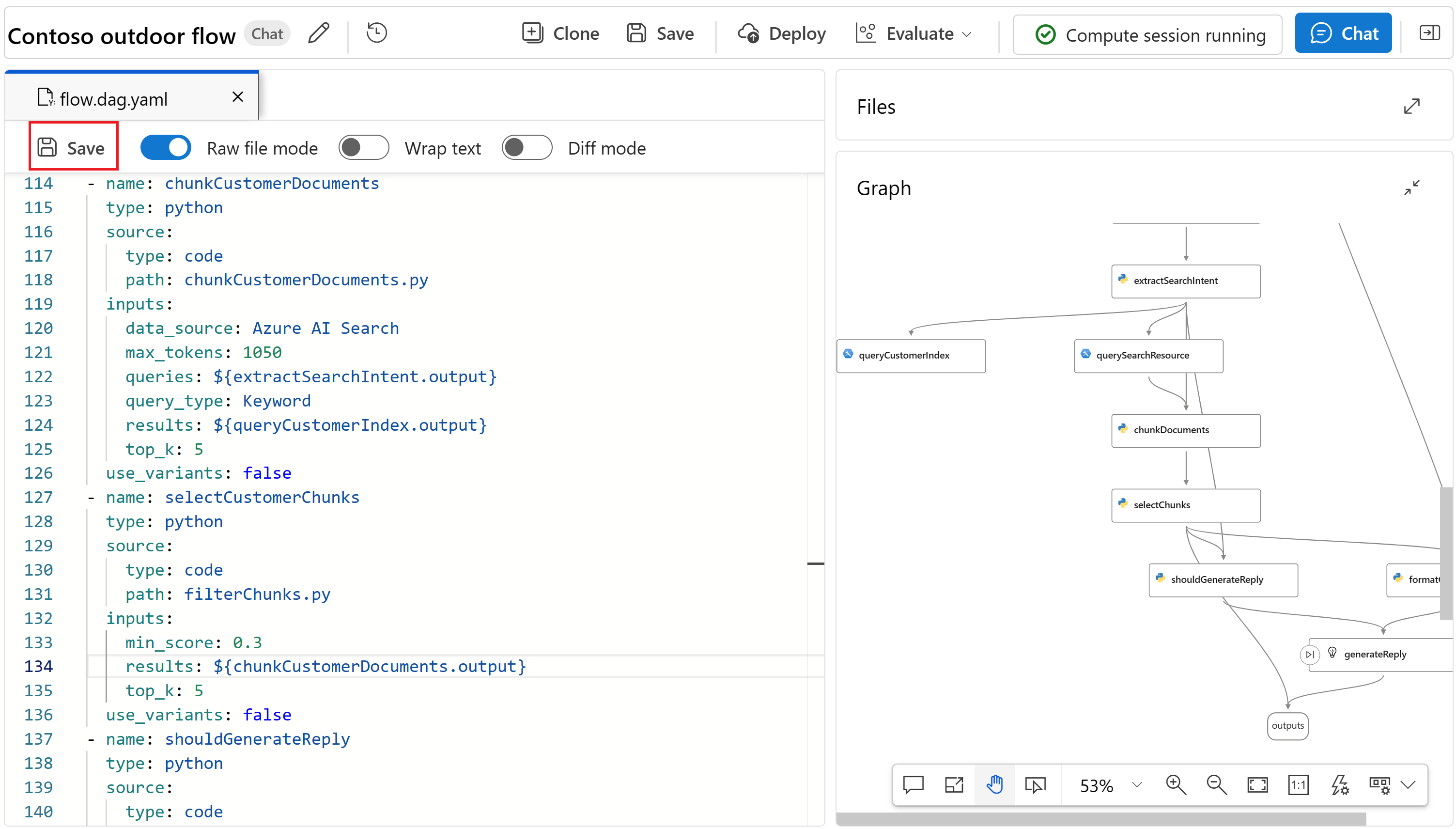
К настоящему моменту
flow.dag.yamlфайл должен включать узлы (среди прочего), которые выглядят примерно так:- name: chunkProductDocuments type: python source: type: code path: chunkProductDocuments.py inputs: data_source: Azure AI Search max_tokens: 1050 queries: ${extractSearchIntent.output} query_type: Keyword results: ${queryProductIndex.output} top_k: 5 use_variants: false - name: selectProductChunks type: python source: type: code path: filterChunks.py inputs: min_score: 0.3 results: ${chunkProductDocuments.output} top_k: 5 use_variants: false - name: chunkCustomerDocuments type: python source: type: code path: chunkCustomerDocuments.py inputs: data_source: Azure AI Search max_tokens: 1050 queries: ${extractSearchIntent.output} query_type: Keyword results: ${queryCustomerIndex.output} top_k: 5 use_variants: false - name: selectCustomerChunks type: python source: type: code path: filterChunks.py inputs: min_score: 0.3 results: ${chunkCustomerDocuments.output} top_k: 5 use_variants: false

Статистические сведения о продукте и клиенте
На этом этапе поток запроса использует только сведения о продукте.
- extractSearchIntent извлекает намерение поиска из вопроса пользователя.
- queryProductIndex извлекает сведения о продукте из индекса сведений о продукте.
- Средство LLM (для больших языковых моделей) получает отформатированный ответ через узлы selectProductDocuments>selectProductChunks formatGeneratedReplyInputs.>
Необходимо подключить и агрегировать сведения о продукте и клиенте, чтобы вывести его в формате, который может использовать средство LLM . Выполните следующие действия, чтобы агрегировать сведения о продукте и клиенте:
Выберите Python из списка инструментов.
Присвойте средству агрегирование и нажмите кнопку "Добавить".
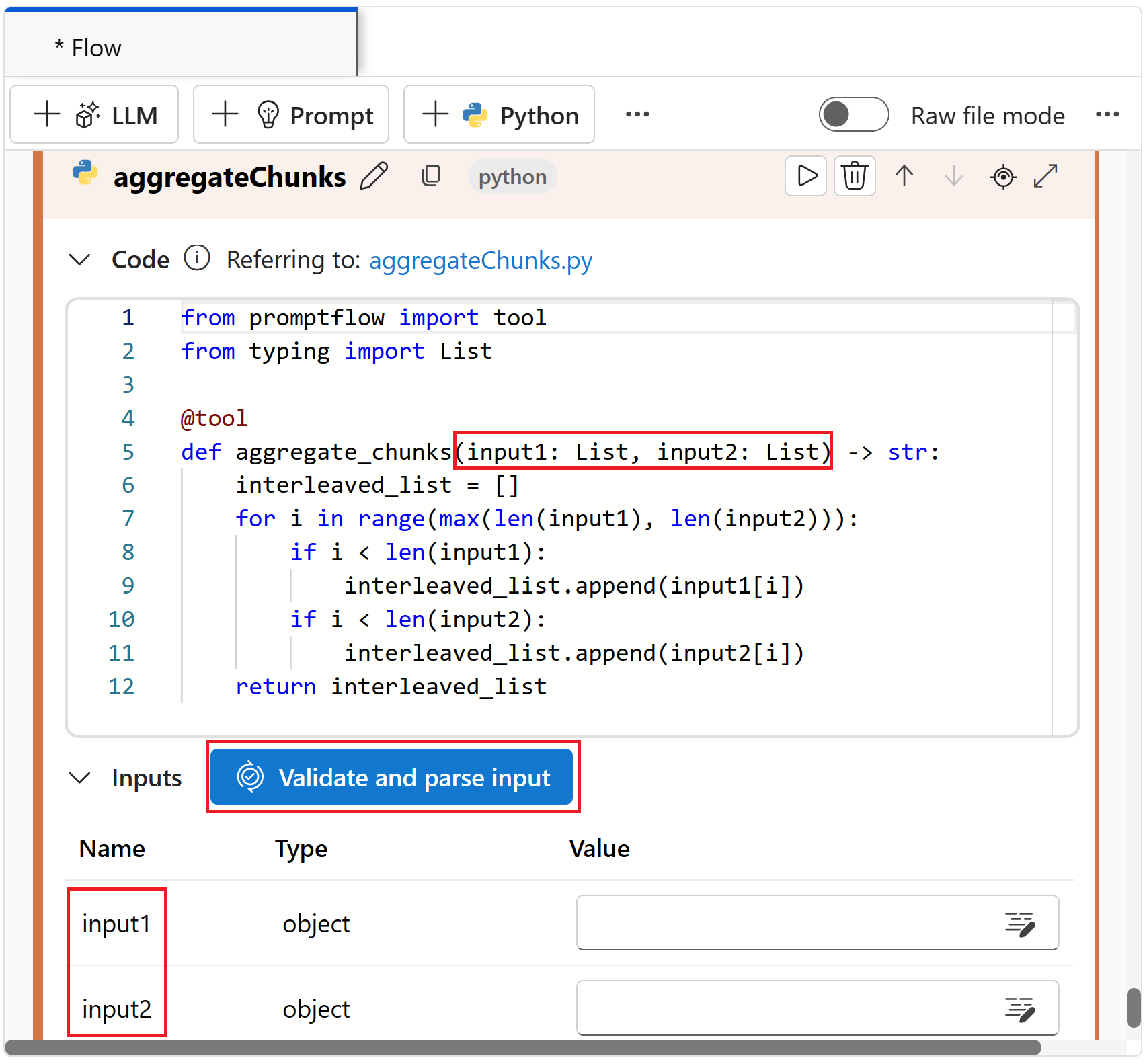
Скопируйте и вставьте следующий код Python, чтобы заменить все содержимое в блоке кода aggregateChunks .
from promptflow import tool from typing import List @tool def aggregate_chunks(input1: List, input2: List) -> str: interleaved_list = [] for i in range(max(len(input1), len(input2))): if i < len(input1): interleaved_list.append(input1[i]) if i < len(input2): interleaved_list.append(input2[i]) return interleaved_listНажмите кнопку "Проверить и проанализировать входные данные", чтобы проверить входные данные для узла агрегатных элементов. Если входные данные допустимы, поток запроса анализирует входные данные и создает необходимые переменные для использования в коде.
Измените узел aggregateChunks , чтобы подключить сведения о продукте и клиенте. Задайте входные данные следующими значениями:
Имя. Тип значение input1 список ${selectProductChunks.output} input2 список ${selectCustomerChunks.output} 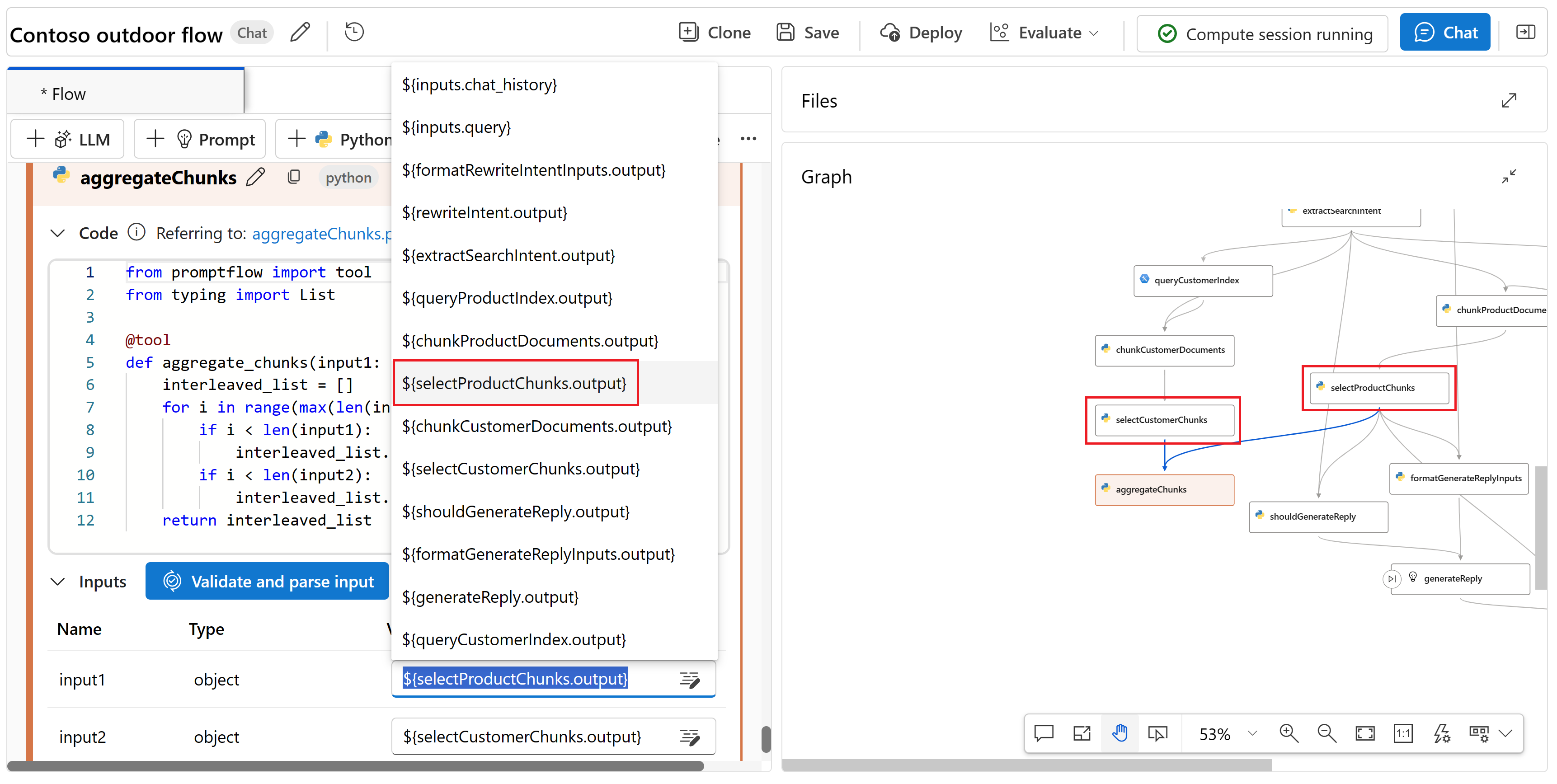
Выберите узел shouldGenerateReply из графа. Выберите или введите
${aggregateChunks.output}входные данные блоков .Выберите узел formatGenerateReplyInputs из графа. Выберите или введите
${aggregateChunks.output}входные данные блоков .Выберите узел выходных данных из графа. Выберите или введите
${aggregateChunks.output}входные данные блоков .Нажмите кнопку "Сохранить " в верхнем меню, чтобы сохранить изменения. Не забудьте периодически сохранять поток запросов при внесении изменений.


Теперь в графе отображается узел aggregateChunks . Узел подключает сведения о продукте и клиенте, чтобы вывести его в формате, который может использовать средство LLM .

Поток запросов чата с информацией о продукте и клиенте
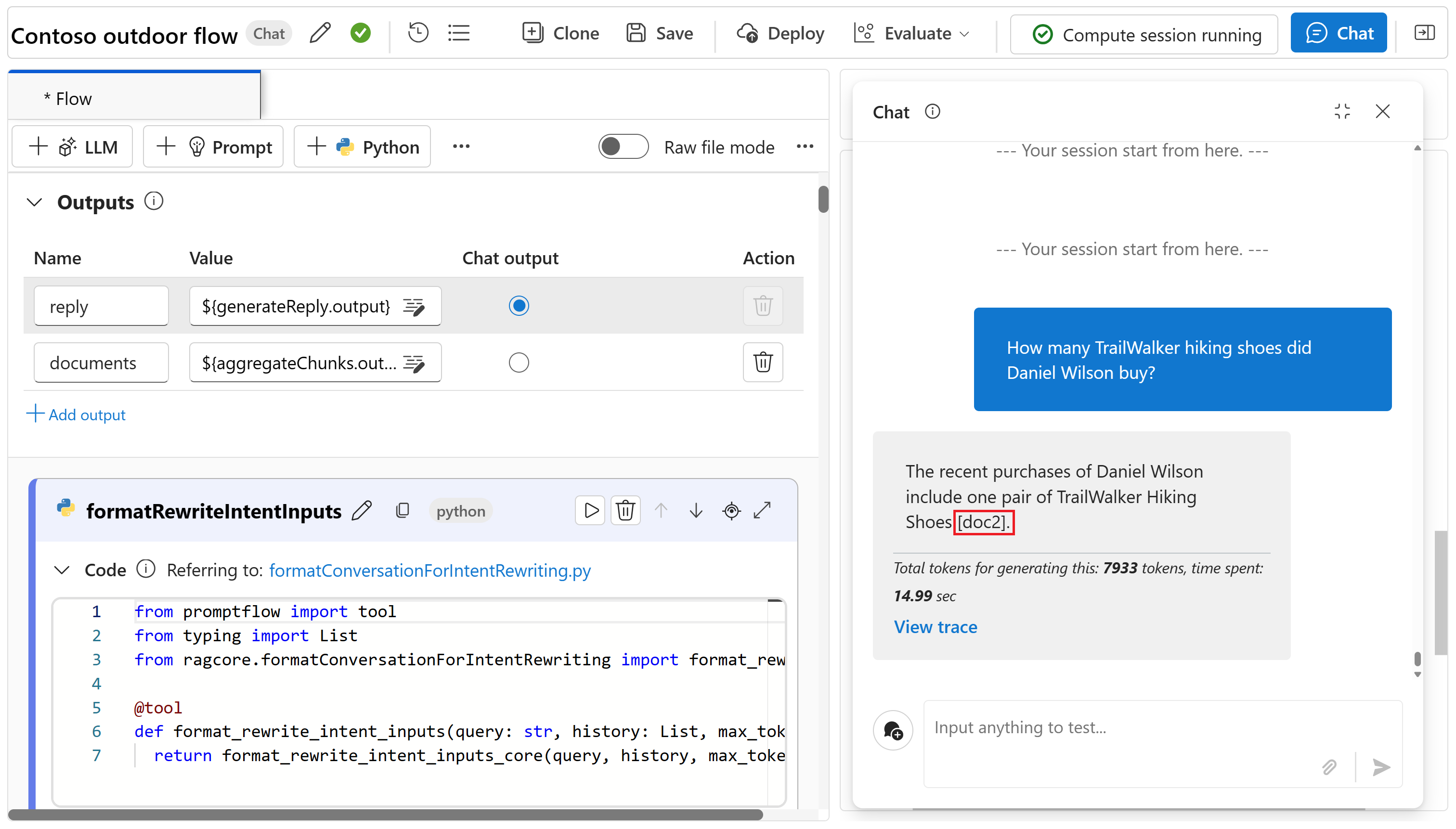
К настоящему моменту у вас есть сведения о продукте и клиенте в потоке запросов. Вы можете поговорить с моделью в потоке запроса и получить ответы на такие вопросы, как "Сколько Тропуакер походной обуви купил Даниэль Уилсон?" Прежде чем перейти к более формальной оценке, вы можете при необходимости общаться с моделью, чтобы узнать, как она отвечает на ваши вопросы.
Перейдите к предыдущему разделу с выбранным узлом выходных данных. Убедитесь, что выходные данные ответа имеют переключатель вывода чата. В противном случае полный набор документов возвращается в ответ на вопрос в чате.
Выберите "Чат" в верхнем меню в потоке запросов, чтобы попробовать чат.
Введите "Сколько Тропукер походных обуви купил Даниэль Уилсон?", а затем выберите значок стрелки вправо, чтобы отправить.
Примечание.
Для реагирования модели может потребоваться несколько секунд. Вы можете ожидать, что время отклика будет быстрее при использовании развернутого потока.
Ответ — это то, что вы ожидаете. Модель использует сведения о клиенте для ответа на этот вопрос.

Оценка потока с помощью набора данных оценки вопросов и ответов
В AI Studio необходимо оценить поток перед развертыванием потока для потребления.
В этом разделе вы используете встроенную оценку для оценки потока с помощью набора данных оценки вопросов и ответов. Встроенная оценка использует метрики с поддержкой ИИ для оценки потока: заземления, релевантности и оценки извлечения. Дополнительные сведения см . в встроенных метрик оценки.
Создание оценки
Вам нужен набор данных оценки вопросов и ответов, содержащий вопросы и ответы, относящиеся к вашему сценарию. Создайте файл локально с именем qa-evaluation.jsonl. Скопируйте и вставьте следующие вопросы и ответы ("truth") в файл.
{"question": "What color is the CozyNights Sleeping Bag?", "truth": "Red", "chat_history": [], }
{"question": "When did Daniel Wilson order the BaseCamp Folding Table?", "truth": "May 7th, 2023", "chat_history": [] }
{"question": "How much does TrailWalker Hiking Shoes cost? ", "truth": "$110", "chat_history": [] }
{"question": "What kind of tent did Sarah Lee buy?", "truth": "SkyView 2 person tent", "chat_history": [] }
{"question": "What is Melissa Davis's phone number?", "truth": "555-333-4444", "chat_history": [] }
{"question": "What is the proper care for trailwalker hiking shoes?", "truth": "After each use, remove any dirt or debris by brushing or wiping the shoes with a damp cloth.", "chat_history": [] }
{"question": "Does TrailMaster Tent come with a warranty?", "truth": "2 years", "chat_history": [] }
{"question": "How much did David Kim spend on the TrailLite Daypack?", "truth": "$240", "chat_history": [] }
{"question": "What items did Amanda Perez purchase?", "truth": "TrailMaster X4 Tent, TrekReady Hiking Boots (quantity 3), CozyNights Sleeping Bag, TrailBlaze Hiking Pants, RainGuard Hiking Jacket, and CompactCook Camping Stove", "chat_history": [] }
{"question": "What is the Brand for TrekReady Hiking Boots", "truth": "TrekReady", "chat_history": [] }
{"question": "How many items did Karen Williams buy?", "truth": "three items of the Summit Breeze Jacket", "chat_history": [] }
{"question": "France is in Europe", "truth": "Sorry, I can only truth questions related to outdoor/camping gear and equipment", "chat_history": [] }
Теперь, когда у вас есть набор данных оценки, вы можете оценить поток, выполнив следующие действия.
Выберите "Оценить>встроенную оценку" в верхнем меню в потоке запросов.
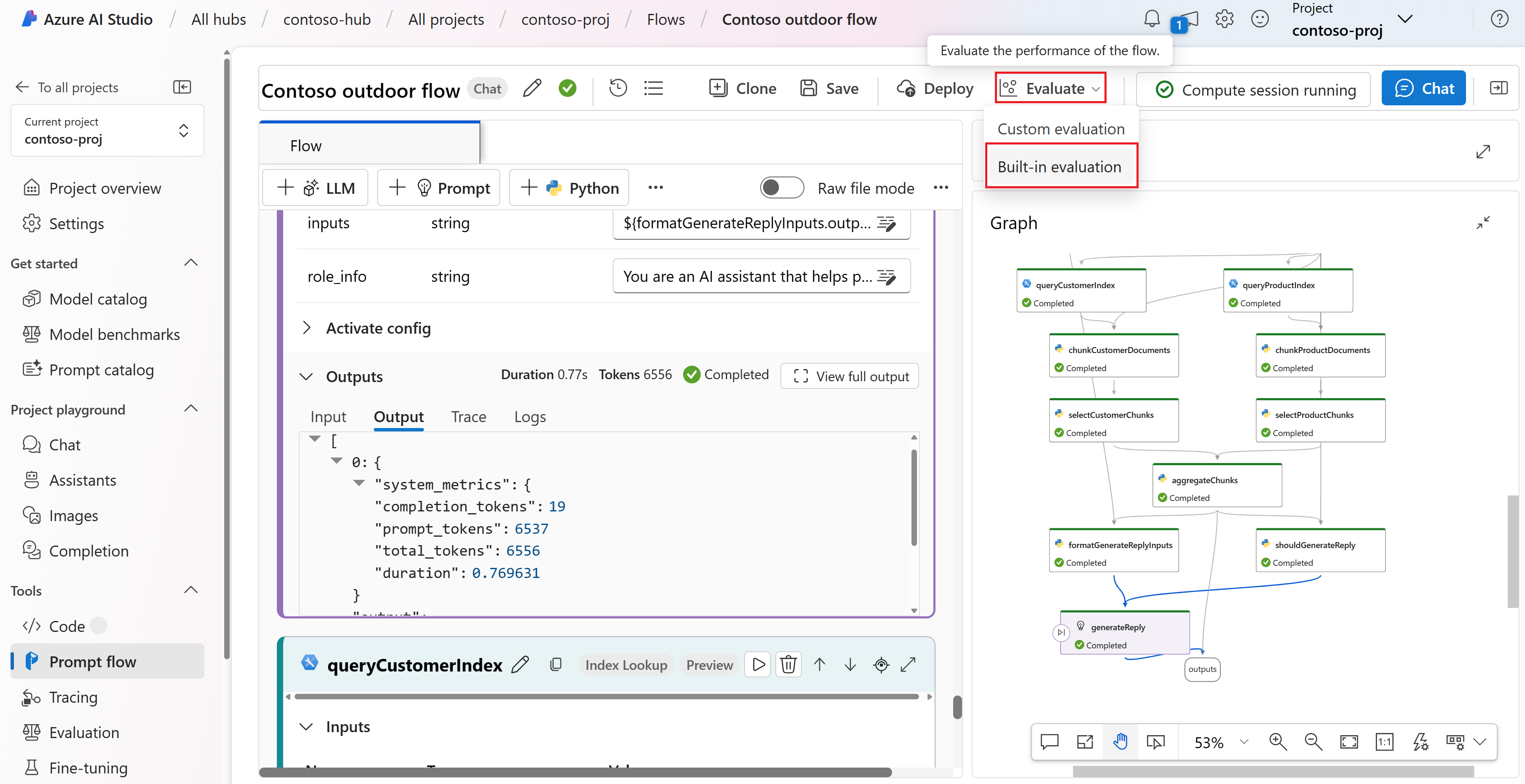
Вы перейдете в мастер создания новой оценки .
Введите имя для оценки и выберите сеанс вычислений.
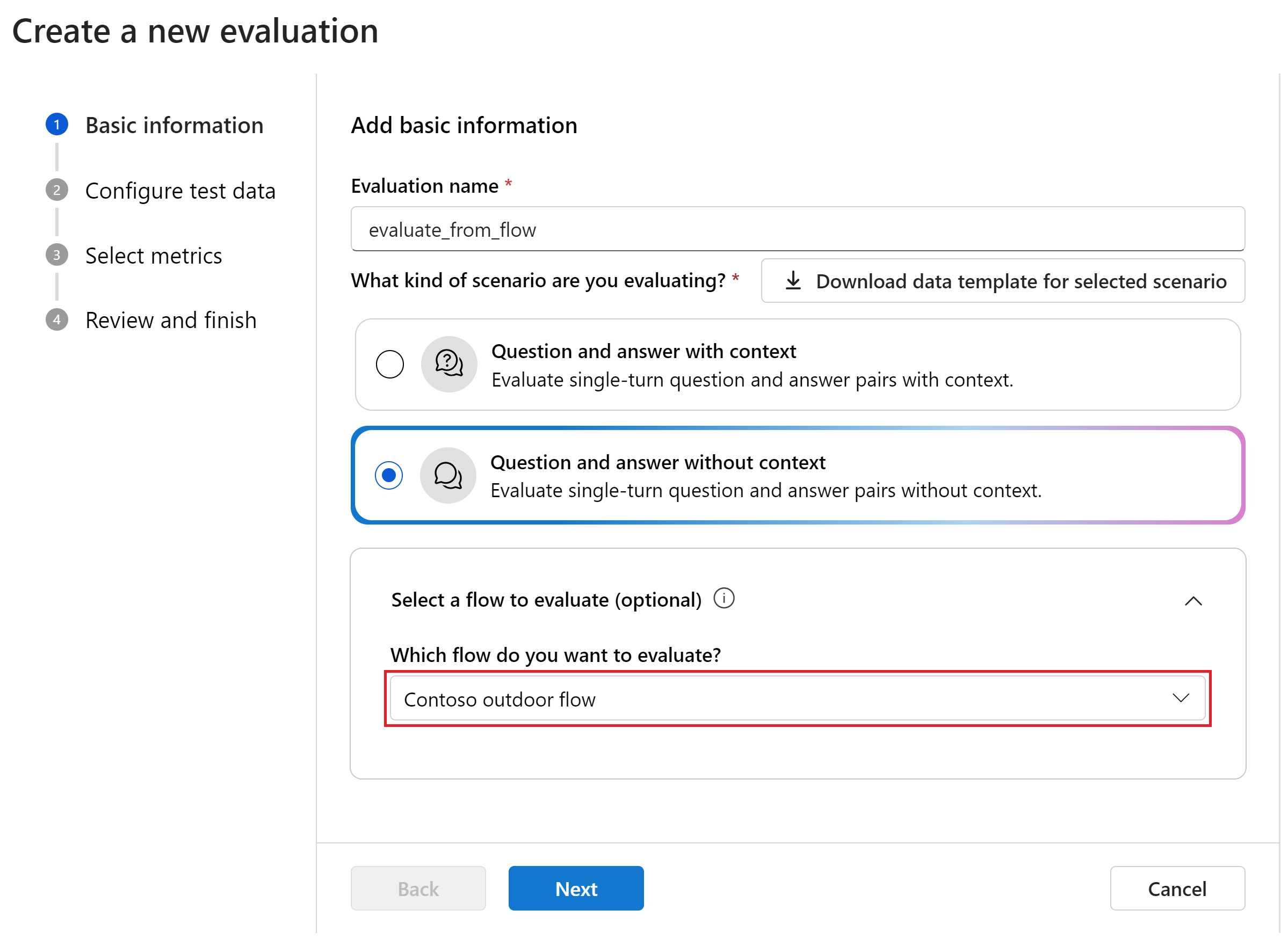
Выберите вопрос и ответ без контекста из параметров сценария.
Выберите поток для оценки. В этом примере выберите открытый поток Contoso или любой из именованных потоков. Затем выберите Далее.
Выберите " Добавить набор данных" на странице "Настройка тестовых данных ".
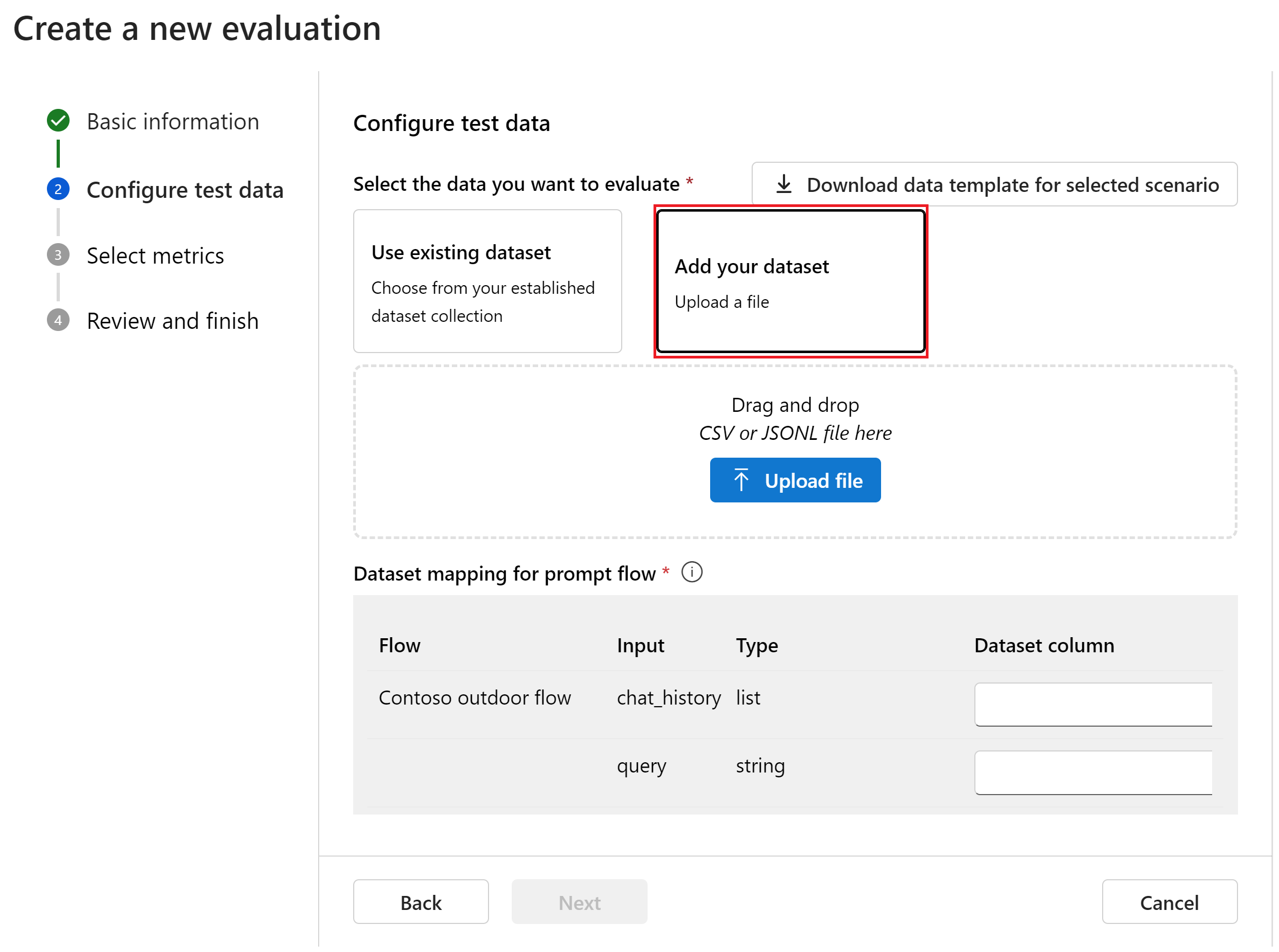
Выберите "Отправить файл", просмотреть файлы и выбрать созданный ранее файл qa-evaluation.jsonl .
После отправки файла необходимо настроить столбцы данных в соответствии с необходимыми входными данными для выполнения пакетного запуска, создающего выходные данные для оценки. Введите или выберите следующие значения для каждого сопоставления набора данных для потока запроса.
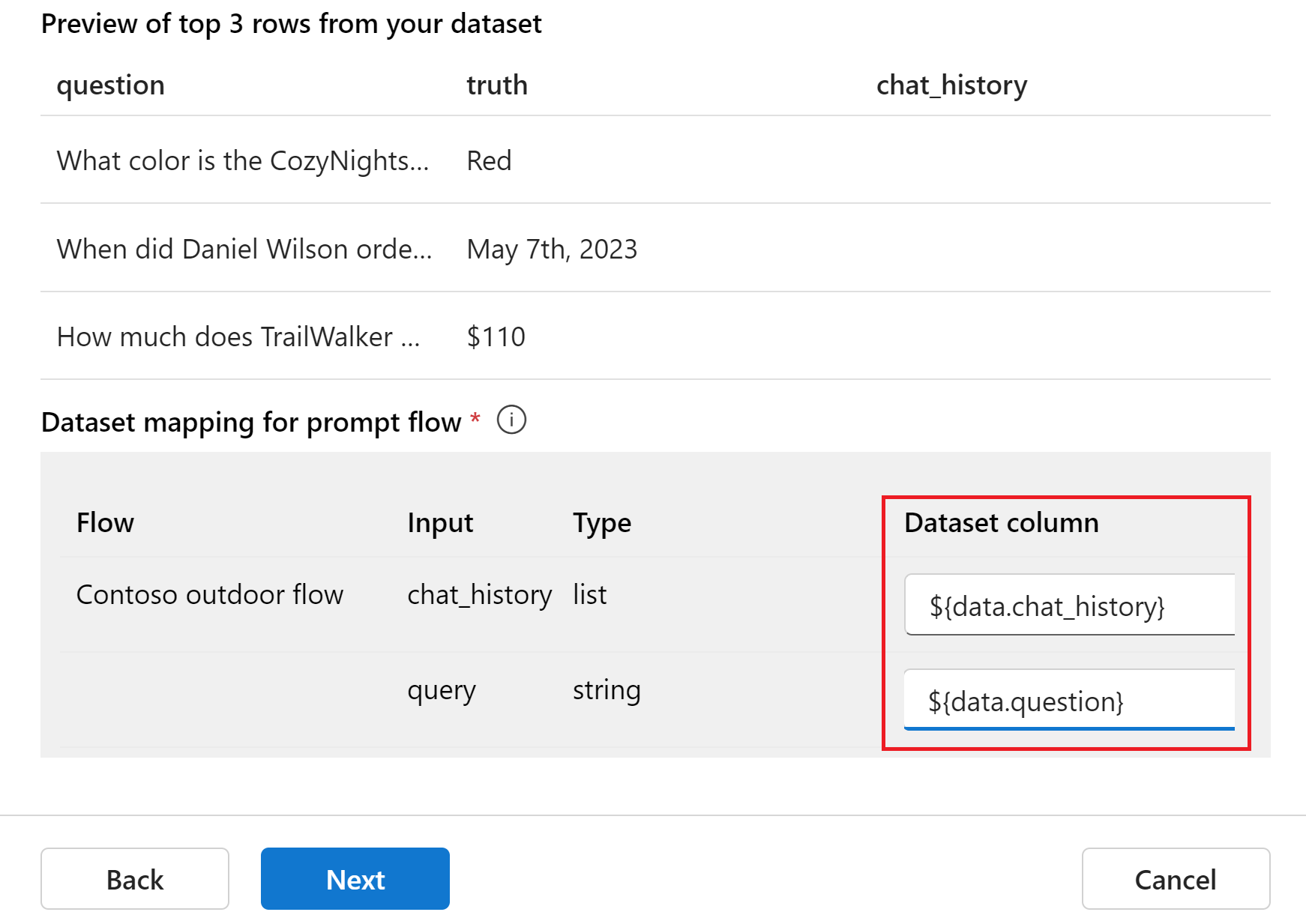
Имя Описание Тип Источник данных chat_history Журнал чата список ${data.chat_history} query Запрос строка ${data.question} Выберите Далее.
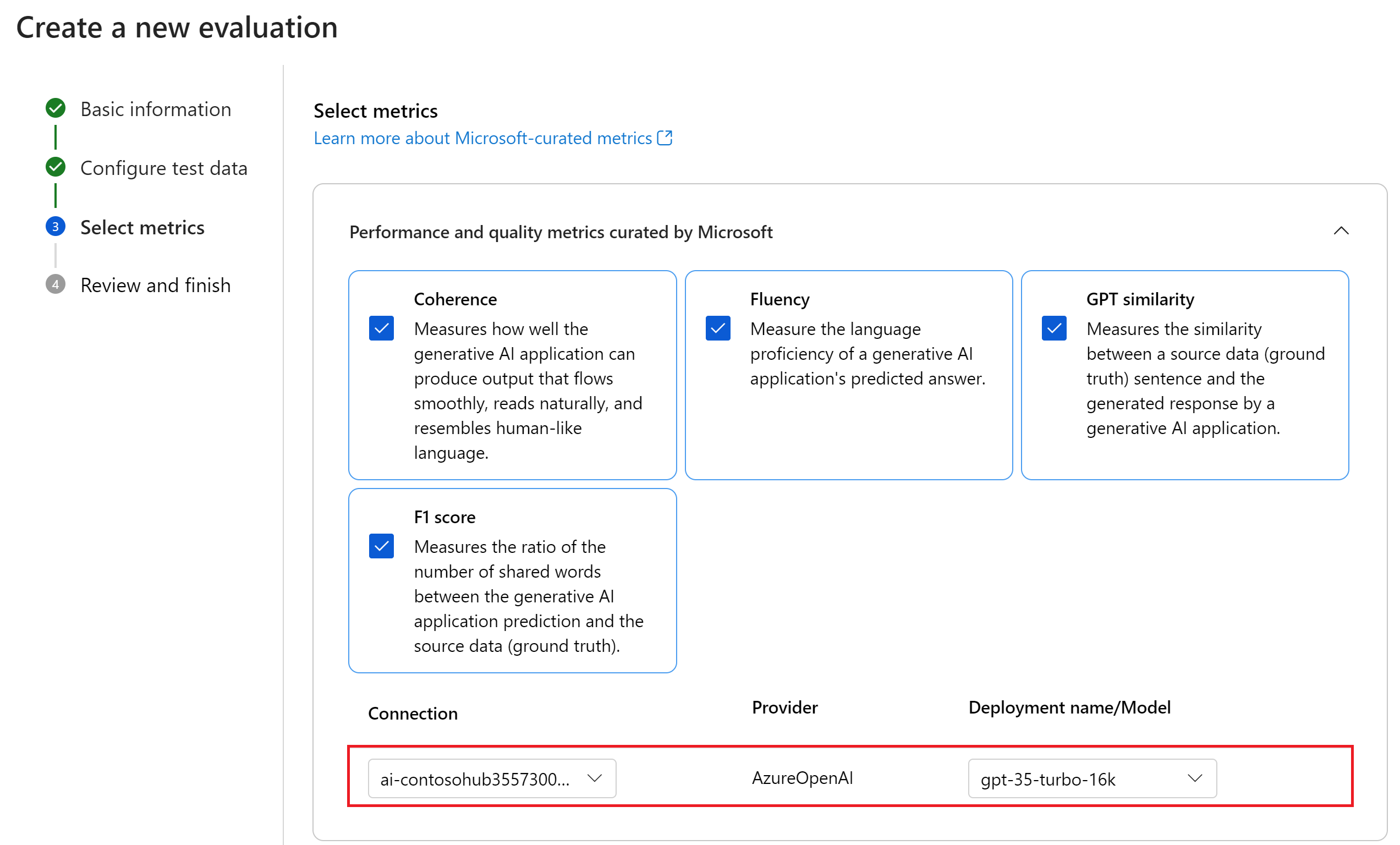
Выберите метрики, которые вы хотите использовать для оценки потока. В этом примере выберите "Согласованность", "Fluency", "GPT" и "F1".
Выберите соединение и модель для оценки. В этом примере выберите gpt-35-turbo-16k. Затем выберите Далее.
Примечание.
Для выполнения вычисления необходимо вызвать другую модель GPT с помощью ИИ. Для повышения производительности используйте модель, которая поддерживает по крайней мере 16k токенов, таких как gpt-4-32k или gpt-35-turbo-16k model. Если вы ранее не развернули такую модель, вы можете развернуть другую модель, выполнив действия, описанные в кратком руководстве по игровой площадке чата AI Studio. Затем вернитесь к этому шагу и выберите развернутую модель.
Необходимо настроить столбцы данных для сопоставления необходимых входных данных для создания метрик оценки. Введите следующие значения, чтобы сопоставить набор данных со свойствами оценки:
Имя Описание Тип Источник данных вопрос Запрос, запрашивающий конкретные сведения. строка ${data.question} ответ Ответ на вопрос, созданный моделью в качестве ответа. строка ${run.outputs.reply} Документы Строка с контекстом из извлеченных документов. строка ${run.outputs.documents} Выберите Далее.
Просмотрите сведения об оценке и нажмите кнопку "Отправить". Вы перейдете на страницу оценки метрик.





Просмотр состояния и результатов оценки
Теперь вы можете просмотреть состояние оценки и результаты, выполнив следующие действия.
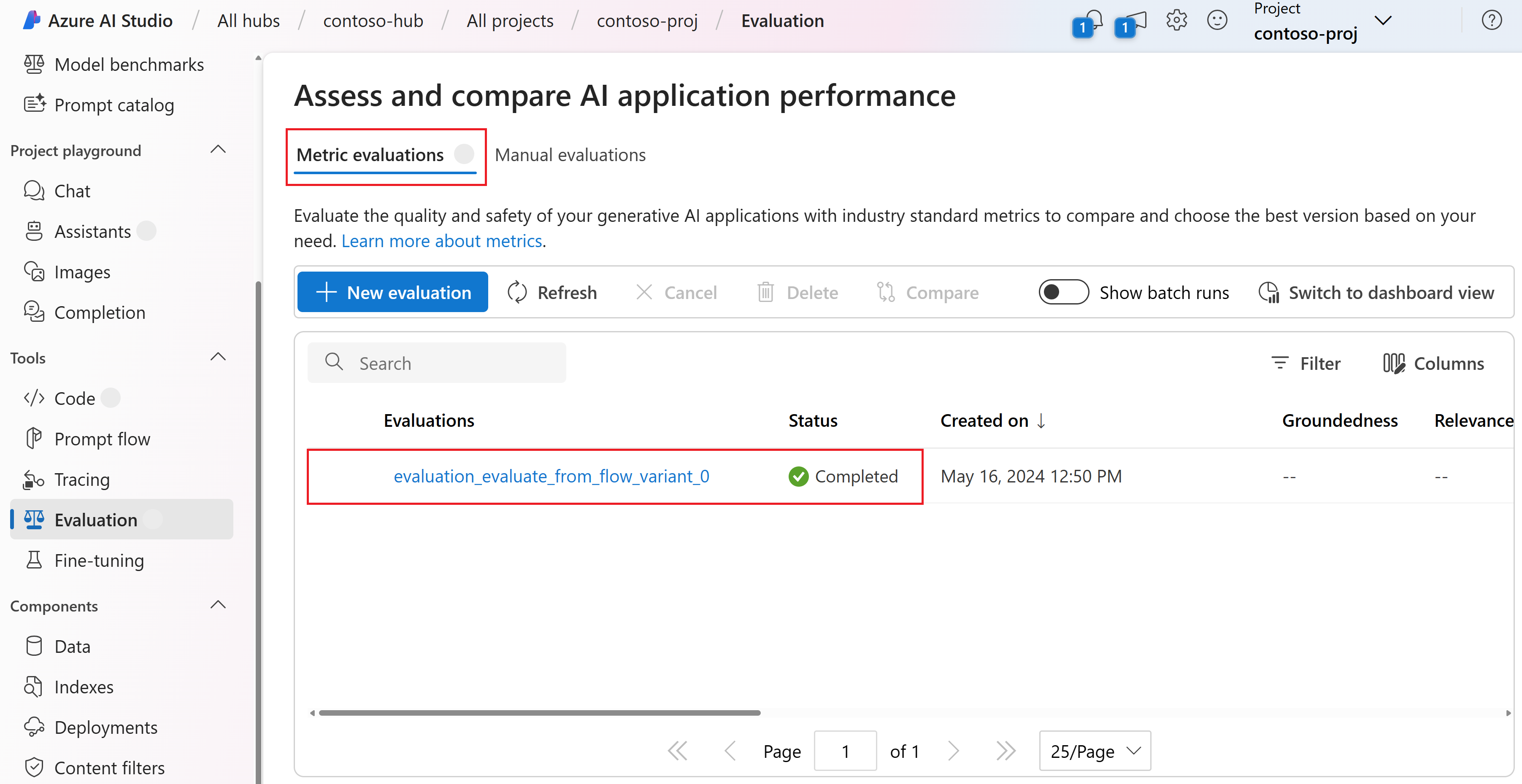
После создания оценки, если вы еще не перейдете к оценке. На странице оценки метрик вы увидите состояние оценки и выбранные метрики. Возможно, потребуется выбрать "Обновить" через пару минут, чтобы просмотреть состояние "Завершено ".
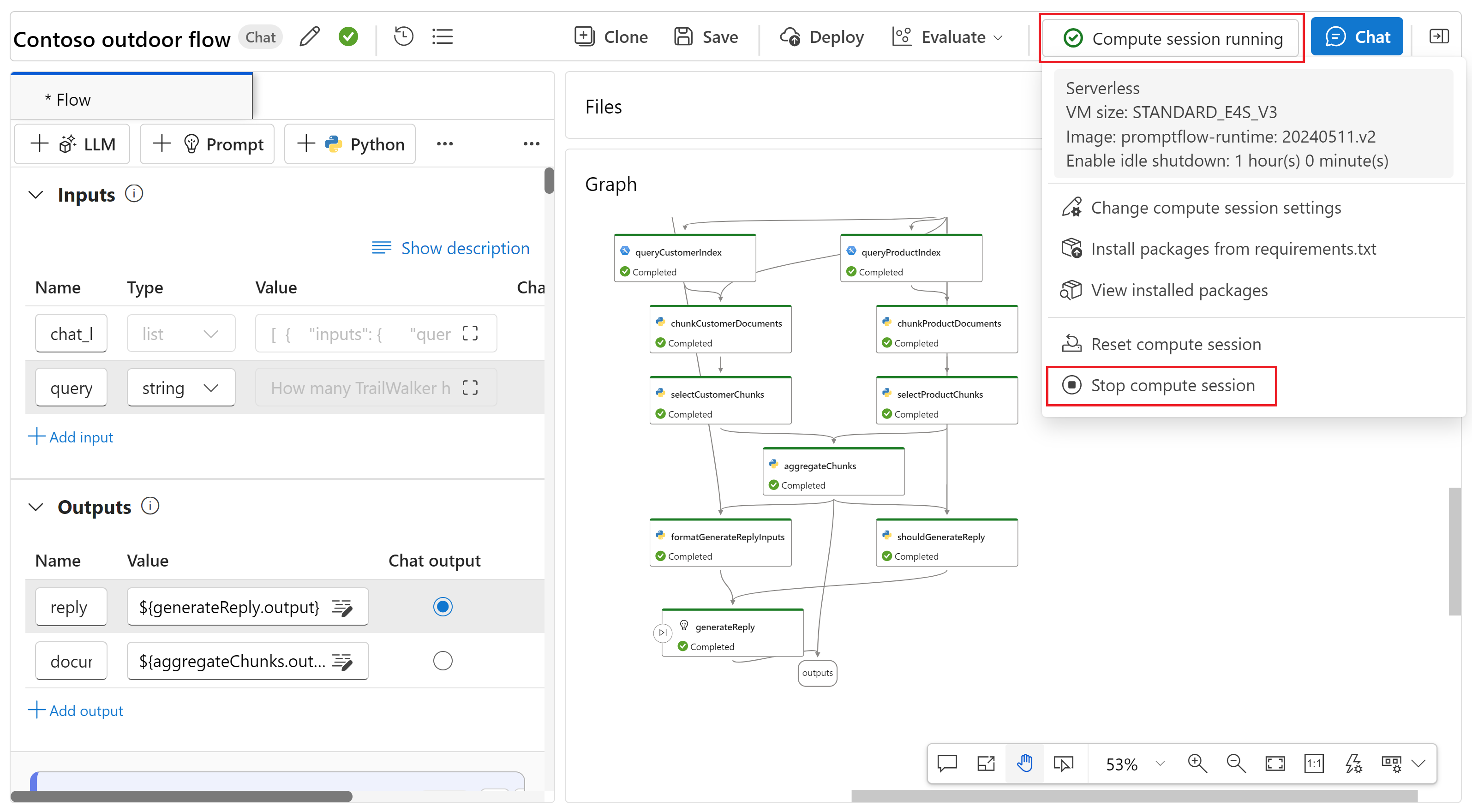
Остановите сеанс вычислений в потоке запросов. Перейдите к потоку запроса и выберите "Сеанс вычислений", на котором выполняется>сеанс остановки вычислений в верхнем меню.
Совет
После завершения оценки не требуется сеанс вычислений для выполнения остальной части этого руководства. Вы можете остановить вычислительный экземпляр, чтобы избежать ненужных затрат Azure. Дополнительные сведения см. в статье о запуске и остановке вычислений.
Выберите имя оценки (например , evaluation_evaluate_from_flow_variant_0), чтобы просмотреть метрики оценки.
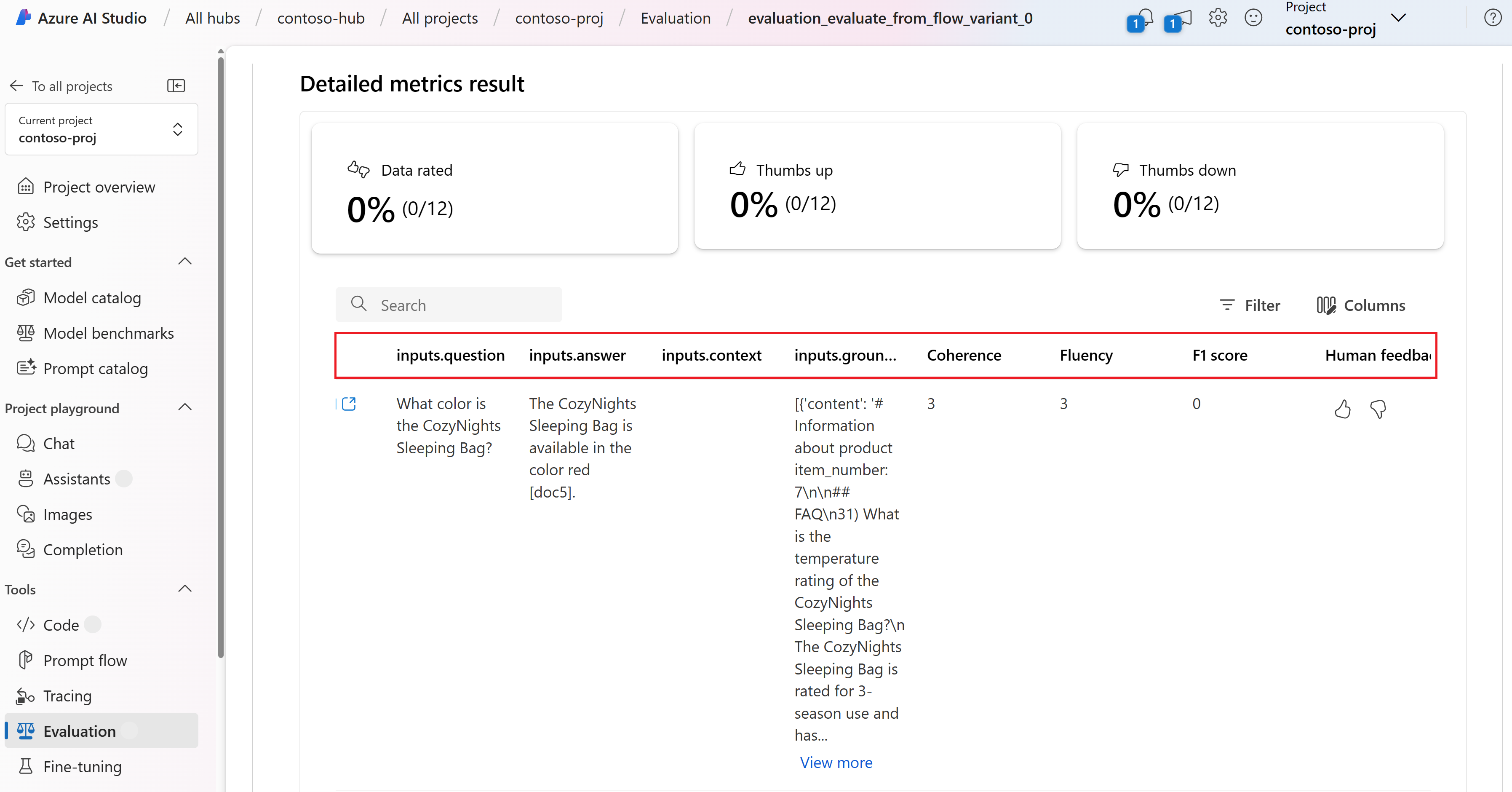



Дополнительные сведения см. в разделе "Просмотр результатов оценки".
Развертывание потока
Теперь, когда вы создали поток и завершили оценку на основе метрик, пришло время создать конечную точку в Интернете для вывода в режиме реального времени. Это означает, что развернутый поток можно использовать для ответа на вопросы в режиме реального времени.
Выполните следующие действия, чтобы развернуть поток запроса в качестве сетевой конечной точки из AI Studio.
Подготовь поток запроса к развертыванию. Если у вас нет одного, ознакомьтесь с предыдущими разделами или как создать поток запроса.
Необязательно. Выберите чат , чтобы проверить правильность работы потока. Рекомендуется протестировать поток перед развертыванием.
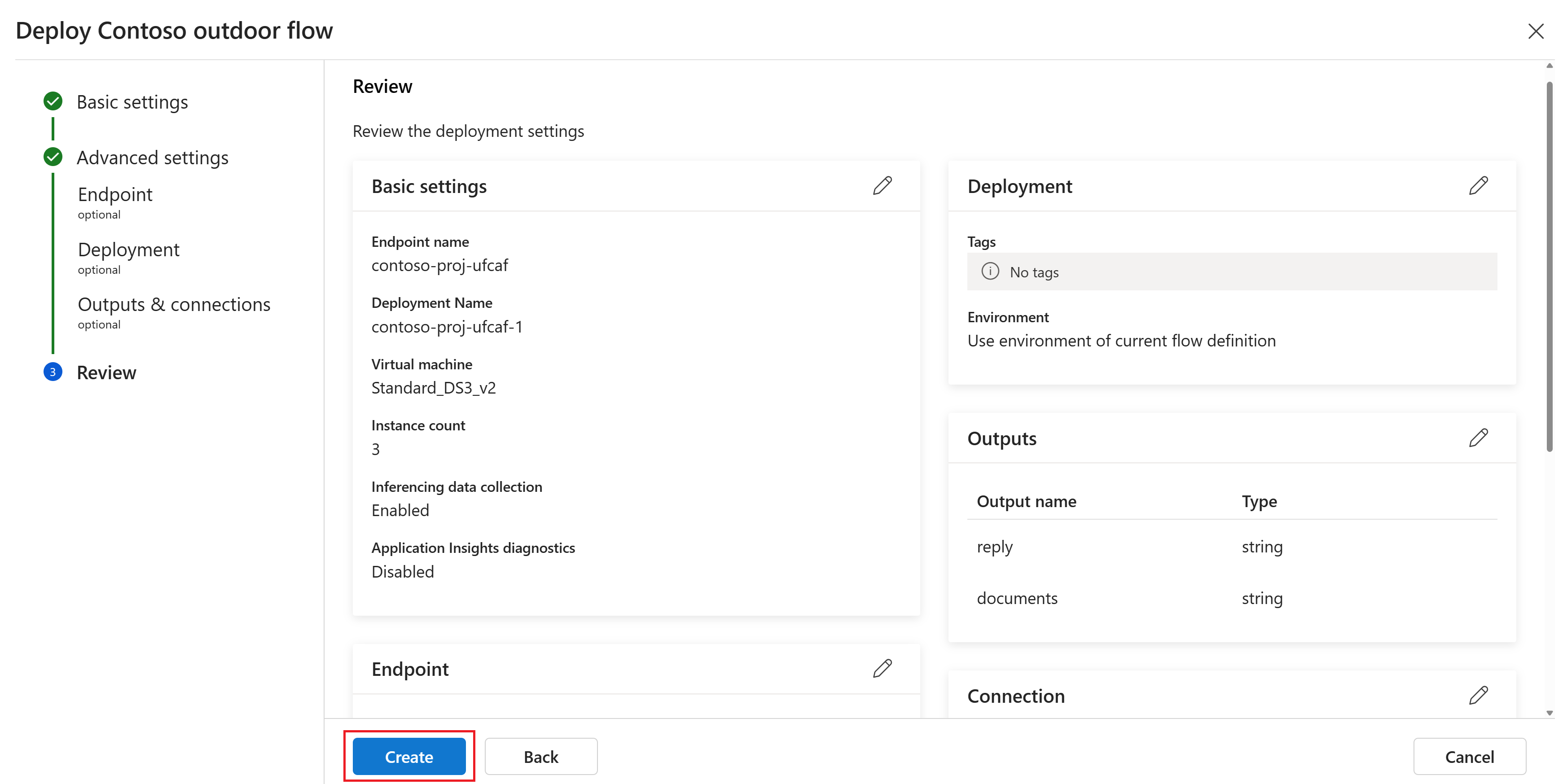
Выберите "Развернуть " в редакторе потоков.
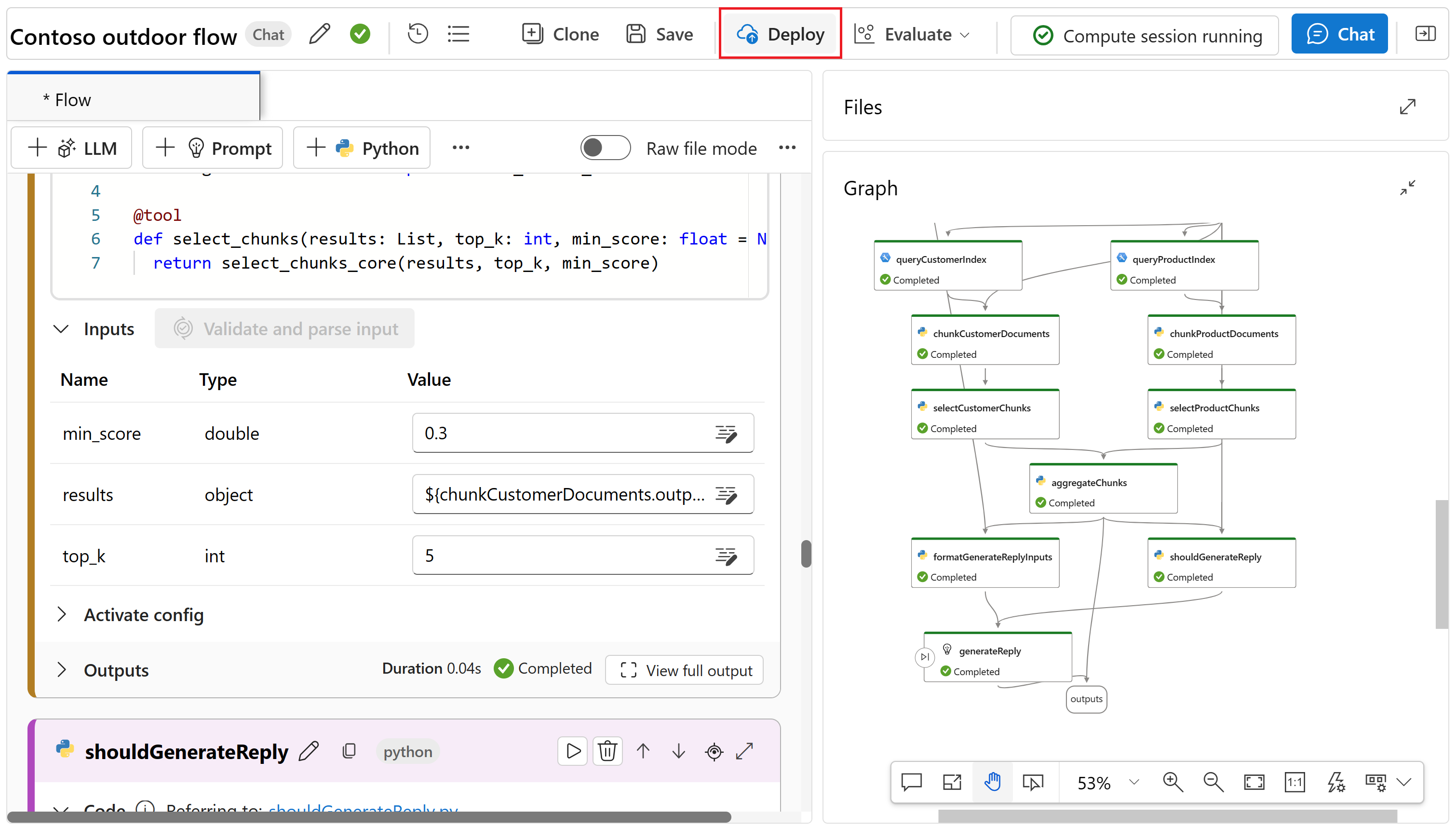
Укажите запрошенные сведения на странице "Основные параметры " в мастере развертывания. Нажмите кнопку "Далее ", чтобы перейти к страницам расширенных параметров.
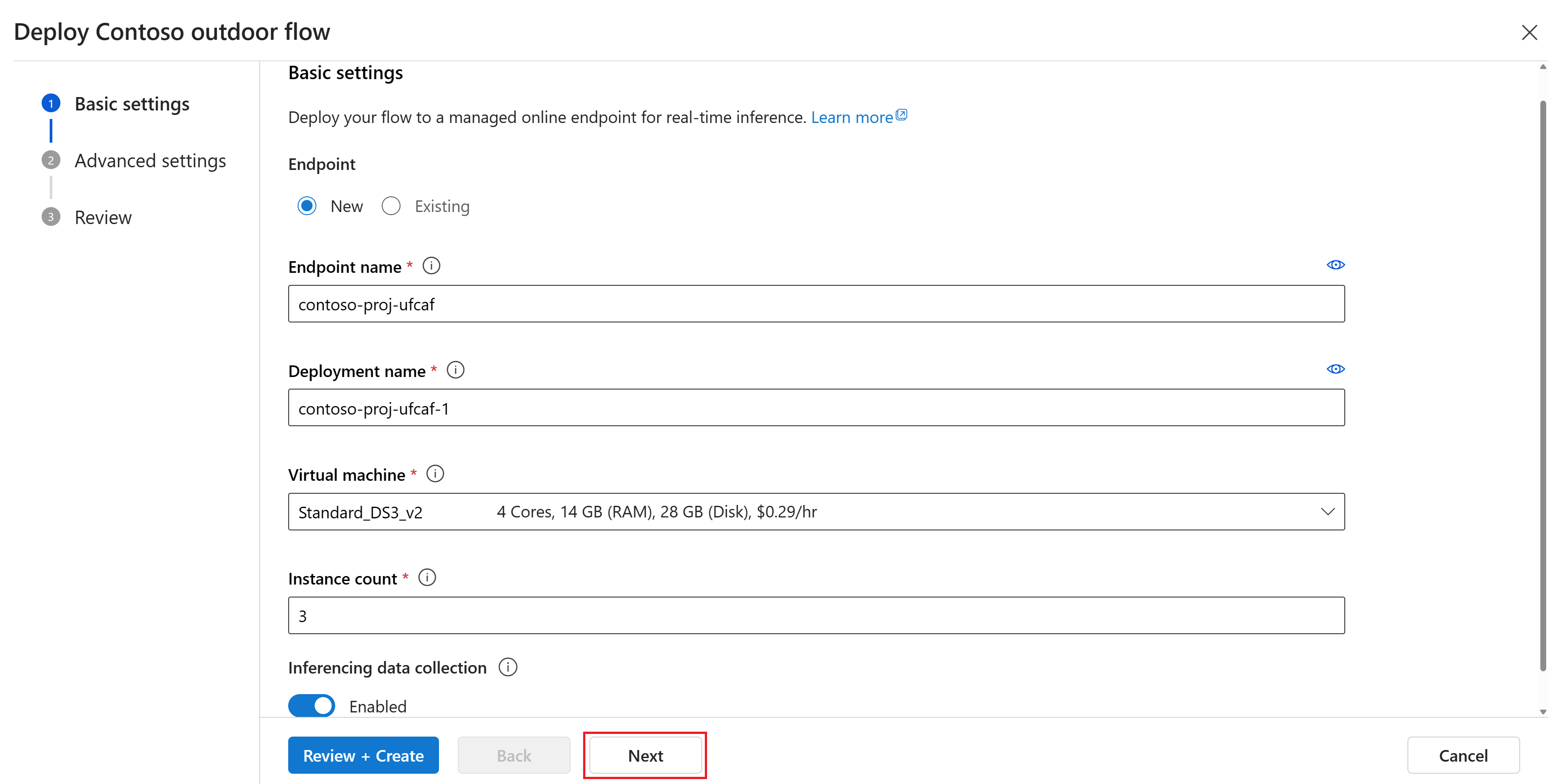
На странице "Дополнительные параметры — конечная точка" оставьте параметры по умолчанию и нажмите кнопку "Далее".
На странице "Дополнительные параметры " Развертывание" оставьте параметры по умолчанию и нажмите кнопку "Далее".
На странице "Дополнительные параметры " Выходные данные и подключения" убедитесь, что все выходные данные выбраны в разделе "Включен в ответ конечной точки".
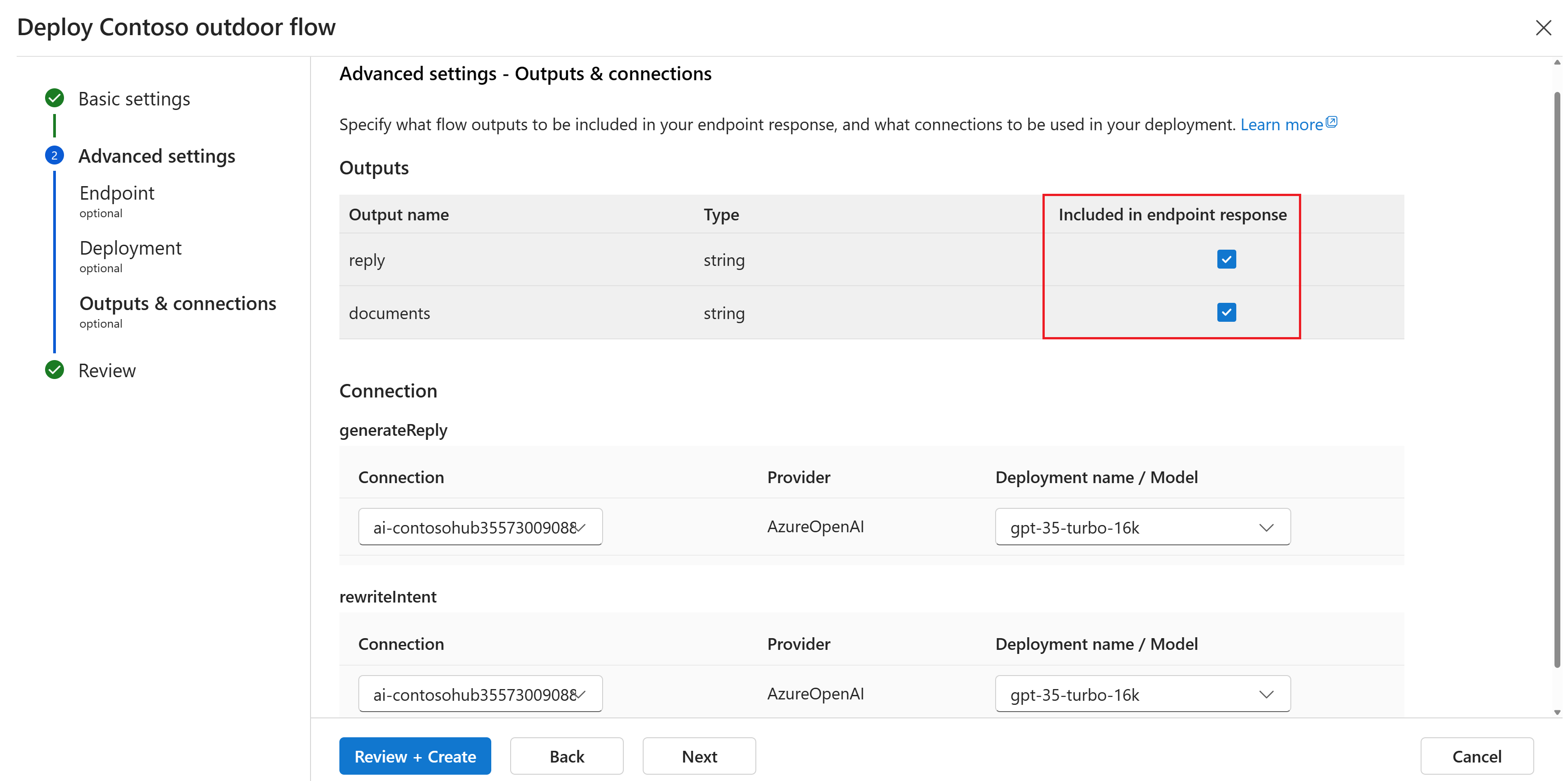
Выберите "Рецензирование и создание", чтобы просмотреть параметры и создать развертывание.
Выберите "Создать", чтобы развернуть поток запроса.




Дополнительные сведения см. в статье о развертывании потока.
Использование развернутого потока
Приложение copilot может использовать развернутый поток запросов для ответа на вопросы в режиме реального времени. Для использования развернутого потока можно использовать конечную точку REST или пакет SDK.
Чтобы просмотреть состояние развертывания в AI Studio, выберите "Развертывания" в области навигации слева.
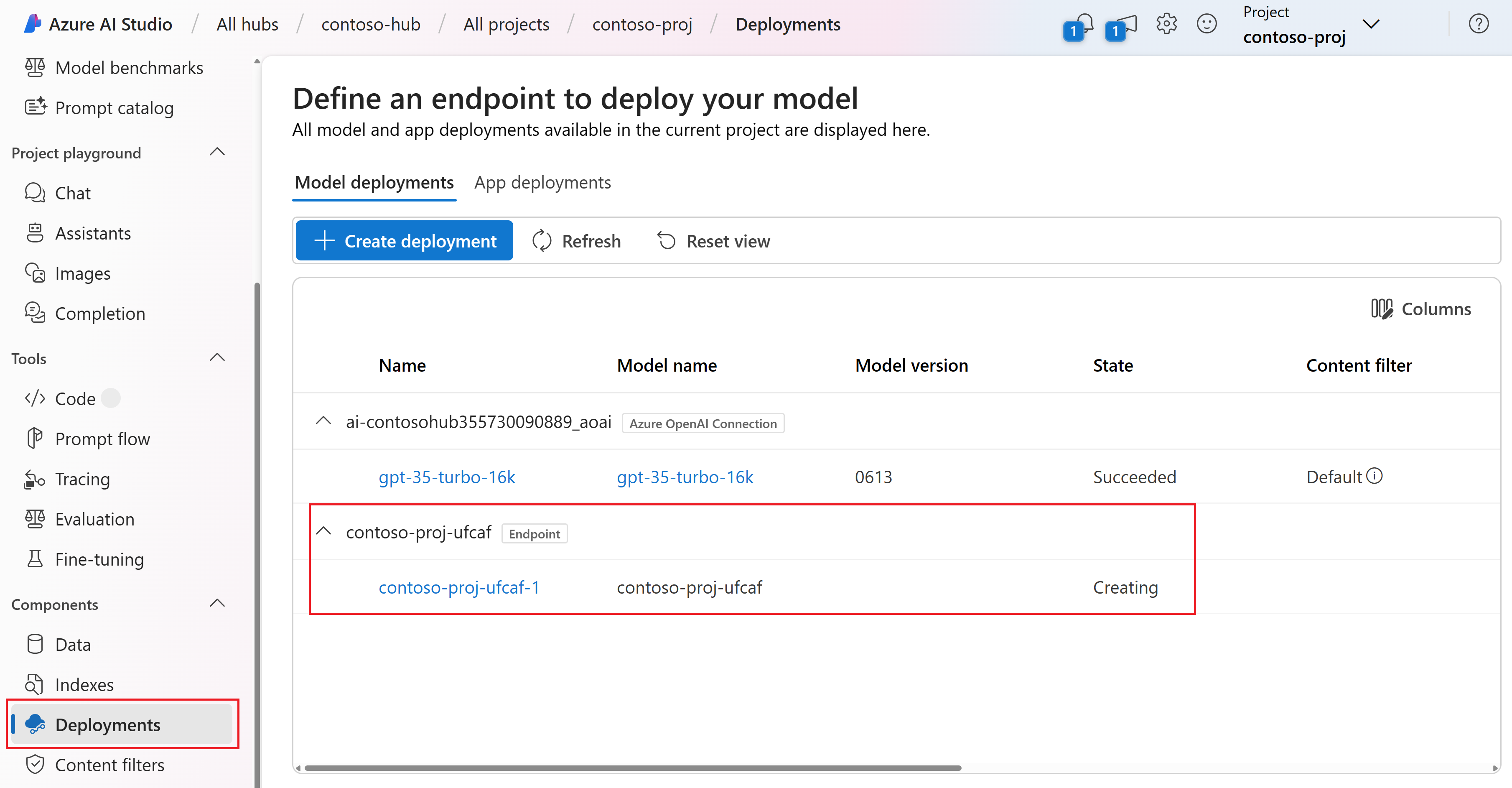
После успешного создания развертывания можно выбрать развертывание для просмотра сведений.
Примечание.
Если отображается сообщение "В настоящее время эта конечная точка не имеет развертываний" или состояние по-прежнему обновляется, возможно, потребуется выбрать "Обновить " через пару минут, чтобы увидеть развертывание.
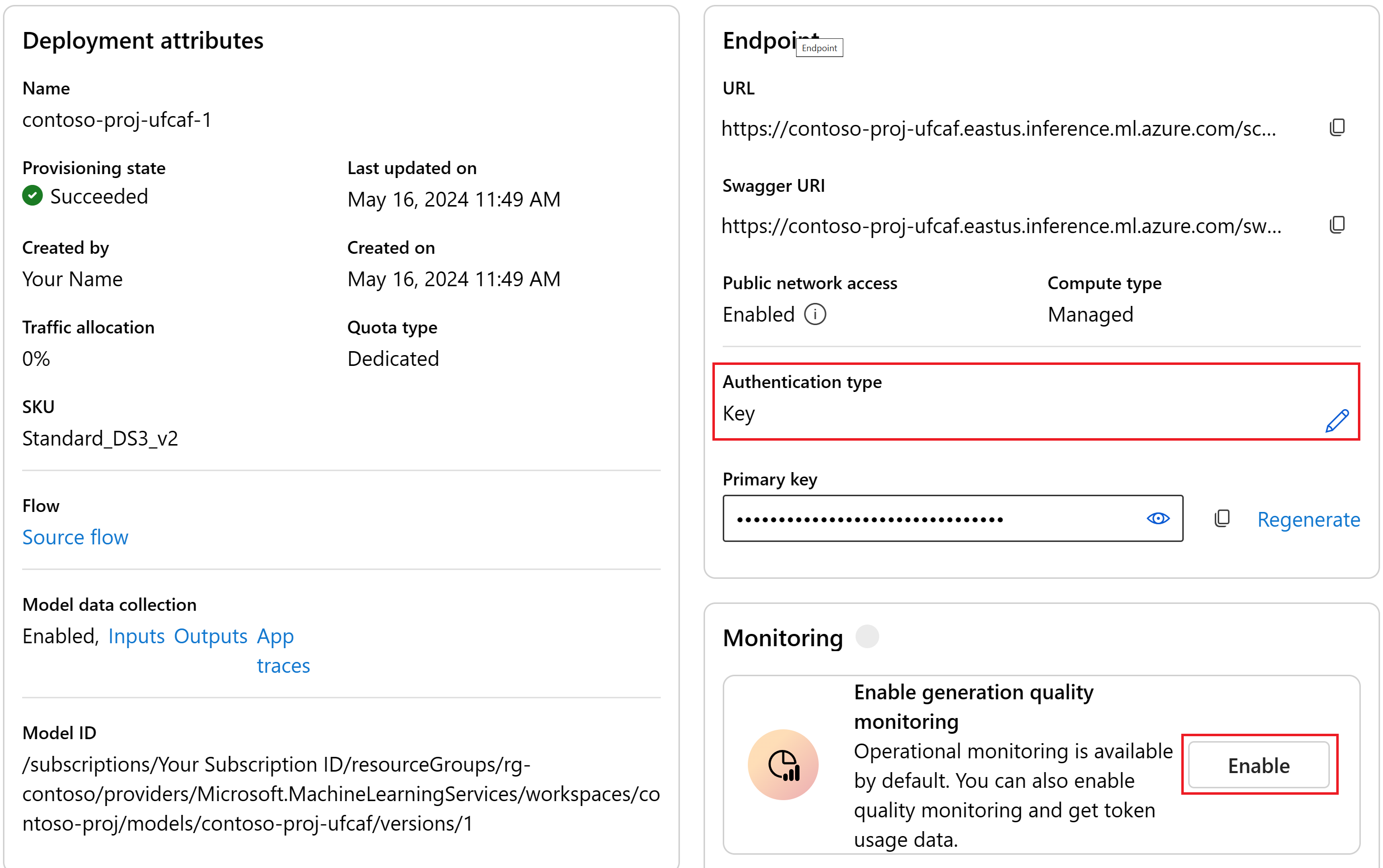
При необходимости на странице сведений можно изменить тип проверки подлинности или включить мониторинг.
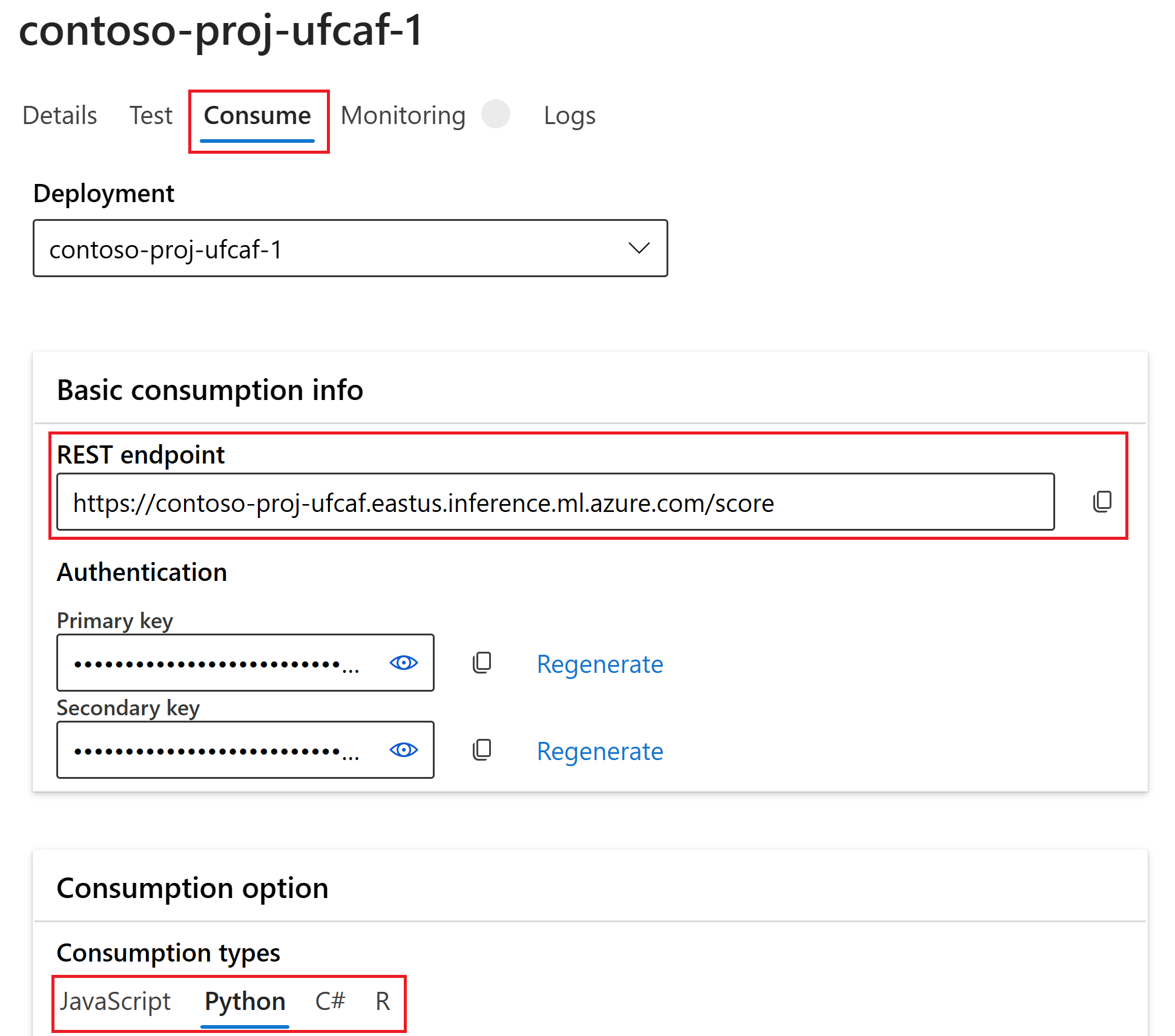
Выберите вкладку "Использование ". Вы можете просмотреть примеры кода и конечную точку REST для приложения copilot, чтобы использовать развернутый поток.



Очистка ресурсов
Чтобы избежать ненужных затрат Azure, следует удалить ресурсы, созданные в этом руководстве, если они больше не нужны. Для управления ресурсами можно использовать портал Azure.
Вы также можете остановить или удалить вычислительный экземпляр в AI Studio по мере необходимости.
Следующие шаги
- Дополнительные сведения о потоке запросов.
- Развертывание корпоративного веб-приложения чата.
Обратная связь
Ожидается в ближайшее время: в течение 2024 года мы постепенно откажемся от GitHub Issues как механизма обратной связи для контента и заменим его новой системой обратной связи. Дополнительные сведения см. в разделе https://aka.ms/ContentUserFeedback.
Отправить и просмотреть отзыв по