Руководство по секционированием данных
Во многих крупномасштабных решениях данные делятся на секции , которыми можно управлять и получать доступ отдельно. Секционирование помогает улучшить масштабируемость, уменьшить количество конфликтов и оптимизировать производительность. Оно также способно обеспечить механизм для разделения данных по шаблону использования. Например, можно архивировать старые данные в хранилище более низкой ценовой категории.
Однако стратегия секционирования должна быть тщательно выбрана, чтобы максимально увеличить преимущества, свести к минимуму негативные последствия.
Замечание
В этой статье термин разделение данных означает процесс физического разделения данных на отдельные участки хранилищ данных. Это не то же самое, что секционирование таблиц SQL Server.
Почему данные секционирования?
Повышение масштабируемости. При масштабировании одной системы базы данных она в конечном итоге достигнет физического ограничения оборудования. Если разделить данные по нескольким секциям, каждый размещен на отдельном сервере, можно масштабировать систему почти на неопределенный срок.
Повышение производительности. Операции доступа к данным для каждой секции выполняются по меньшему объему данных. Правильное выполнение секционирования может сделать систему более эффективной. Операции, влияющие на несколько секций, могут выполняться параллельно.
Повышение безопасности. В некоторых случаях можно разделить конфиденциальные и нечувствительные данные в разные секции и применить различные элементы управления безопасностью к конфиденциальным данным.
Обеспечивает гибкость работы. Секционирование предоставляет множество возможностей для операций тонкой настройки, повышения эффективности администрирования и минимизации затрат. Например, можно определить различные стратегии управления, мониторинга, резервного копирования и восстановления, а также других административных задач на основе важности данных в каждой секции.
Сопоставляйте хранилище данных с шаблоном использования. Секционирование позволяет развертывать каждую секцию в другом типе хранилища данных на основе затрат и встроенных функций, которые предлагает хранилище данных. Например, большие двоичные данные могут храниться в хранилище BLOB-объектов, а более структурированные данные могут храниться в базе данных документов. Дополнительные сведения см. в разделе "Выбор правильного хранилища данных".
Повышение доступности. Разделение данных между несколькими серверами позволяет избежать одной точки сбоя. Если один экземпляр завершается ошибкой, данные в этом разделе недоступны. Операции с другими секциями могут продолжаться. Для управляемых платформ как службы хранилища данных (PaaS) это решение менее актуально, так как эти службы предназначены со встроенной избыточностью.
Проектирование секций
Существует три типичных стратегии секционирования данных:
горизонтальное секционирование (часто называется сегментированием). В этой стратегии каждая секция является отдельным хранилищем данных, но все секции имеют одну схему. Каждая секция называется сегментом и содержит определенное подмножество данных, например все заказы для определенного набора клиентов.
Вертикальное секционирование. В этой стратегии каждая секция содержит подмножество полей для элементов в хранилище данных. Поля разделяются по их шаблону использования. Например, часто используемые поля можно поместить в один вертикальный раздел, а реже используемые поля — в другой.
Функциональное секционирование. В этой стратегии данные агрегируются в соответствии с тем, как он используется в каждом ограниченном контексте в системе. Например, система электронной коммерции может хранить данные счета в одной секции и данных инвентаризации продуктов в другом.
Эти стратегии можно объединить, и мы рекомендуем учитывать их все при разработке схемы секционирования. Например, можно разделить данные на сегменты, а затем использовать вертикальное секционирование для дальнейшего разделения данных в каждом сегменте.
Горизонтальное секционирование (сегментирование)
На рисунке 1 показана горизонтальная секционирование или сегментирование. В этом примере данные инвентаризации продуктов делятся на сегменты на основе ключа продукта. Каждый сегмент содержит данные для непрерывного диапазона ключей сегментов (A-G и H-Z), упорядоченных в алфавитном порядке. Сегментирование распределяет нагрузку на большее количество компьютеров, что снижает результаты и повышает производительность.
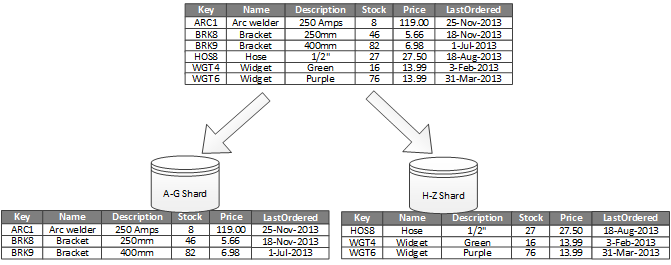
Рис. 1. Горизонтально секционирование (сегментирование) данных на основе ключа секции.
Наиболее важным фактором является выбор ключа сегментирования. После работы системы может быть трудно изменить ключ. Ключ должен обеспечить секционирование данных для равномерного распределения рабочей нагрузки по сегментам.
Осколки не обязательно должны быть одного размера. Более важно сбалансировать количество запросов. Некоторые сегменты могут быть очень большими, но каждый элемент имеет небольшое количество операций доступа. Другие сегменты могут быть меньше, но к каждому элементу обращается гораздо чаще. Также важно убедиться, что один сегмент не превышает пределы масштабирования (с точки зрения емкости и обработки ресурсов) хранилища данных.
Избегайте создания горячих секций, которые могут повлиять на производительность и доступность. Например, использование первой буквы имени клиента приводит к несбалансированному распределению, так как некоторые буквы являются более распространенными. Вместо этого используйте хэш идентификатора клиента для более равномерного распределения данных между секциями.
Выберите ключ сегментирования, который минимизирует все будущие требования, чтобы разделить большие сегменты, объединить небольшие сегменты в более крупные секции или изменить схему. Эти операции могут быть очень трудоемкими, и может потребоваться использование одного или нескольких сегментов в автономном режиме во время их выполнения.
Если сегменты реплицируются, возможно, можно сохранить некоторые реплики в сети, а другие — разделить, объединить или перенастроить. Однако системе может потребоваться ограничить операции, которые можно выполнить во время перенастройки. Например, данные в репликах могут быть помечены как доступные только для чтения, чтобы предотвратить несоответствия данных.
Дополнительные сведения о горизонтальном секционирование см. в шаблоне сегментирования.
Вертикальное секционирование
Наиболее распространенное использование вертикального секционирования заключается в сокращении затрат на операций ввода-вывода и производительности, связанных с получением элементов, к которым часто обращаются. На рисунке 2 показан пример вертикальной секционирования. В этом примере различные свойства элемента хранятся в разных секциях. Одна секция содержит данные, к которым чаще обращаются, включая название продукта, описание и цену. Другая секция содержит данные инвентаризации: количество акций и дата последнего заказа.
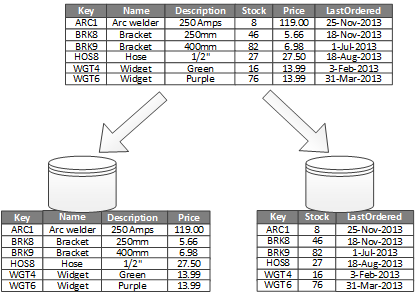
Рис. 2. Вертикально секционирование данных по его шаблону использования.
В этом примере приложение регулярно запрашивает имя продукта, описание и цену при отображении сведений о продукте клиентам. Количество акций и дата последнего заказа хранятся в отдельной секции, так как эти два элемента обычно используются вместе.
Другие преимущества вертикальной секционирования:
Относительно медленно перемещаемые данные (название продукта, описание и цена) можно отделить от более динамических данных (уровень акций и дата последнего заказа). Медленное перемещение данных является хорошим кандидатом для приложения для кэширования в памяти.
Конфиденциальные данные можно хранить в отдельном разделе с дополнительными элементами управления безопасностью.
Вертикальное секционирование может уменьшить объем необходимого параллельного доступа.
Вертикальное секционирование работает на уровне сущности в хранилище данных, частично нормализуя сущность, чтобы преобразовать ее из широкого элемента в набор узких элементов. Он идеально подходит для хранилищ данных, ориентированных на столбцы, таких как HBase и Cassandra. Если данные в коллекции столбцов вряд ли изменятся, можно также использовать хранилища столбцов в SQL Server.
Функциональное секционирование
Если можно определить ограниченный контекст для каждой отдельной бизнес-области в приложении, функциональное секционирование — это способ повышения производительности изоляции и доступа к данным. Другое распространенное использование функционального разделения используется для того, чтобы разделить данные для чтения и записи от данных только для чтения. На рисунке 3 показан обзор функционального секционирования, в котором данные инвентаризации отделены от данных клиента.
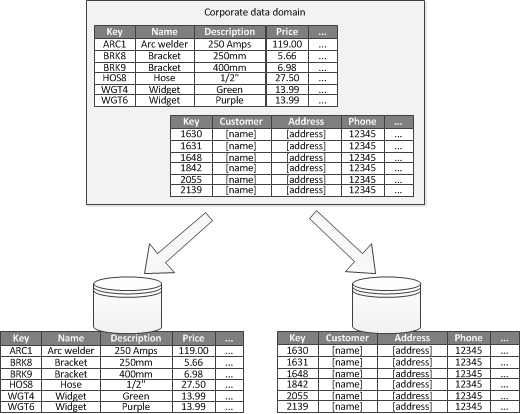
Рис. 3. Функционально секционирование данных по ограниченному контексту или поддомену.
Эта стратегия секционирования может помочь сократить конкуренцию за доступ к данным в разных частях системы.
Проектирование секций для масштабируемости
Важно учитывать размер и рабочую нагрузку для каждой секции и сбалансировать их, чтобы данные распределялись для достижения максимальной масштабируемости. Однако необходимо также секционировать данные таким образом, чтобы оно не превышало пределы масштабирования одного хранилища секций.
Выполните следующие действия при проектировании секций для масштабируемости:
- Анализируйте приложение, чтобы понять шаблоны доступа к данным, такие как размер результирующий набор, возвращаемый каждым запросом, частота доступа, внутренняя задержка и требования к вычислительной обработке на стороне сервера. Во многих случаях некоторые крупные сущности будут требовать большую часть ресурсов обработки.
- Используйте этот анализ для определения текущих и будущих целевых показателей масштабируемости, таких как размер данных и рабочая нагрузка. Затем распределяйте данные по секциям в соответствии с целевым объектом масштабируемости. Для горизонтального секционирования важно выбрать правильный ключ сегментов, чтобы убедиться, что распределение даже. Дополнительные сведения см. в шаблоне сегментирования.
- Убедитесь, что каждая секция имеет достаточно ресурсов для обработки требований к масштабируемости с точки зрения размера и пропускной способности данных. В зависимости от хранилища данных может быть ограничение на объем дискового пространства, мощности обработки или пропускной способности сети на секцию. Если требования, скорее всего, превышают эти ограничения, может потребоваться уточнить стратегию секционирования или разделить данные дальше, возможно, объединение двух или более стратегий.
- Отслеживайте систему, чтобы убедиться, что данные распределяются должным образом и что секции могут обрабатывать нагрузку. Фактическое использование не всегда соответствует прогнозируемому анализу. В этом случае может быть возможно перебалансировать секции или изменить некоторые части системы, чтобы получить необходимый баланс.
Некоторые облачные среды выделяют ресурсы с точки зрения границ инфраструктуры. Убедитесь, что ограничения выбранной границы предоставляют достаточно места для любого ожидаемого роста объема данных с точки зрения хранения данных, мощности обработки и пропускной способности.
Например, если вы используете хранилище таблиц Azure, существует ограничение на объем запросов, которые могут обрабатываться одной секцией в определенный период времени. (Дополнительные сведения см. в статье о целевых показателях масштабируемости и производительности службы хранилища Azure.) Для занятого сегмента может потребоваться больше ресурсов, чем одна секция может обрабатывать. В этом случае может потребоваться повторное распределение нагрузки сегментом. Если общий размер или пропускная способность этих таблиц превышает емкость учетной записи хранения, может потребоваться создать дополнительные учетные записи хранения и распространить таблицы по этим учетным записям.
Проектирование секций для производительности запросов
Производительность запросов часто можно повысить, используя небольшие наборы данных и выполняя параллельные запросы. Каждая секция должна содержать небольшую долю всего набора данных. Это сокращение объема может повысить производительность запросов. Однако секционирование не является альтернативой для разработки и настройки базы данных соответствующим образом. Например, убедитесь, что у вас есть необходимые индексы.
Выполните следующие действия при проектировании секций для производительности запросов:
Изучите требования и производительность приложения:
- Используйте бизнес-требования для определения критически важных запросов, которые всегда должны выполняться быстро.
- Отслеживайте систему, чтобы определить все запросы, выполняющиеся медленно.
- Найдите, какие запросы выполняются чаще всего. Даже если один запрос имеет минимальную стоимость, совокупное потребление ресурсов может быть значительным.
Секционирование данных, вызывающих низкую производительность:
- Ограничьте размер каждого раздела, чтобы время отклика запроса оставалось в пределах цели.
- Если вы используете горизонтальное секционирование, создайте ключ сегментов, чтобы приложение было легко выбрать нужную секцию. Это запрещает запросу сканировать каждую секцию.
- Рассмотрим расположение перегородки. По возможности попробуйте сохранить данные в секциях, которые географически близки к приложениям и пользователям, к которым он обращается.
Если сущность имеет требования к пропускной способности и производительности запросов, используйте функциональное секционирование на основе этой сущности. Если это по-прежнему не соответствует требованиям, примените горизонтальное секционирование. В большинстве случаев достаточно одной стратегии секционирования, но в некоторых случаях это более эффективно для объединения обоих стратегий.
Рассмотрите возможность параллельного выполнения запросов между секциями, чтобы повысить производительность.
Проектирование секций для доступности
Секционирование данных может повысить доступность приложений, гарантируя, что весь набор данных не является одной точкой сбоя и что отдельные подмножества набора данных можно управлять независимо.
Рассмотрим следующие факторы, влияющие на доступность:
Как критически важны данные для бизнес-операций. Определите, какие данные являются критически важными бизнес-данными, такими как транзакции, и какие данные являются менее критически важными операционными данными, такими как файлы журналов.
Рекомендуется хранить критически важные данные в высокодоступных секциях с соответствующим планом резервного копирования.
Создайте отдельные процедуры управления и мониторинга для различных наборов данных.
Поместите данные с одинаковым уровнем критическости в той же секции, чтобы их можно было создать вместе на соответствующей частоте. Например, секциям, которые содержат данные транзакций, может потребоваться создать резервную копию чаще, чем секции, в которые хранятся данные журнала или трассировки.
Как управлять отдельными секциями. Проектирование секций для поддержки независимого управления и обслуживания обеспечивает несколько преимуществ. Рассмотрим пример.
Если раздел выходит из строя, его можно восстановить независимо, без приложений, обращающихся к данным в других разделах.
Секционирование данных по географической области позволяет выполнять запланированные задачи обслуживания в нерабочее время для каждого расположения. Убедитесь, что секции не слишком большие, чтобы предотвратить завершение планового обслуживания в течение этого периода.
Следует ли реплицировать критически важные данные между секциями. Эта стратегия может повысить доступность и производительность, но также может привести к проблемам согласованности. Требуется время для синхронизации изменений с каждой репликой. В течение этого периода различные секции будут содержать разные значения данных.
Рекомендации по проектированию приложений
Секционирование упрощает проектирование и разработку системы. Рассмотрите возможность секционирования в качестве основной части проектирования системы, даже если система изначально содержит только одну секцию. Если вы используете секционирование как затруднение, это будет более сложно, так как у вас уже есть динамическая система для поддержания:
- Необходимо изменить логику доступа к данным.
- Может потребоваться перенести большие объемы существующих данных, чтобы распределить их по секциям.
- Пользователи ожидают, что смогут продолжать использовать систему во время миграции.
В некоторых случаях секционирование не считается важным, так как начальный набор данных мал и может легко обрабатываться одним сервером. Это может быть верно для некоторых рабочих нагрузок, но многие коммерческие системы должны расширяться по мере увеличения числа пользователей.
Кроме того, это не только большие хранилища данных, которые пользуются преимуществами секционирования. Например, небольшое хранилище данных может быть сильно доступ к сотням одновременных клиентов. Секционирование данных в этой ситуации может помочь сократить количество разных операций и повысить пропускную способность.
При разработке схемы секционирования данных следует учитывать следующие моменты:
Свести к минимуму операции доступа к данным между секциями. По возможности сохраняйте данные для наиболее распространенных операций базы данных в каждой секции, чтобы свести к минимуму операции доступа к данным между секциями. Запросы между секциями могут быть более длительными, чем запросы в одной секции, но оптимизация секций для одного набора запросов может негативно повлиять на другие наборы запросов. Если необходимо выполнить запрос между секциями, свести к минимуму время запроса, выполнив параллельные запросы и агрегируя результаты в приложении. (Этот подход может оказаться невозможным в некоторых случаях, например, когда результат из одного запроса используется в следующем запросе.)
Рассмотрите возможность репликации статических ссылочных данных. Если запросы используют относительно статические справочные данные, такие как таблицы почтового кода или списки продуктов, рассмотрите возможность репликации этих данных во всех разделах, чтобы уменьшить отдельные операции подстановки в разных секциях. Этот подход также может снизить вероятность того, что эталонные данные становятся "горячим" набором данных с большим трафиком из всей системы. Однако существует дополнительная стоимость, связанная с синхронизацией любых изменений в эталонных данных.
Сведите к минимуму соединения между разделами. По возможности свести к минимуму требования к целостности ссылок между вертикальными и функциональными секциями. В этих схемах приложение отвечает за поддержание целостности ссылок между секциями. Запросы, которые объединяют данные между несколькими секциями, неэффективны, так как приложение обычно должно выполнять последовательные запросы на основе ключа, а затем внешнего ключа. Вместо этого рассмотрите возможность репликации или отмены нормализации соответствующих данных. Если требуется объединение между секциями, запустите параллельные запросы по секциям и присоединяйте данные в приложении.
Объятия конечной согласованности. Оцените, является ли на самом деле требованием строгой согласованности. Распространенный подход в распределенных системах заключается в реализации конечной согласованности. Данные в каждой секции обновляются отдельно, а логика приложения гарантирует успешное завершение обновлений. Он также обрабатывает несоответствия, которые могут возникать из запроса данных во время выполнения последовательной операции.
Рассмотрим, как запросы находят правильную секцию. Если запрос должен сканировать все секции, чтобы найти необходимые данные, это значительно влияет на производительность, даже если выполняется несколько параллельных запросов. При вертикальном и функциональном секционирование запросы могут естественно указать секцию. Горизонтальное секционирование с другой стороны может затруднить поиск элемента, так как каждый сегмент имеет одну и ту же схему. Обычное решение для поддержания карты, используемой для поиска расположения сегментов для определенных элементов. Эта карта может быть реализована в логике сегментирования приложения или поддерживаться хранилищем данных, если она поддерживает прозрачное сегментирование.
Рекомендуется периодически перебалансировать сегменты. С горизонтальной секционированием сегменты перебалансирования могут помочь равномерно распределять данные по размеру и по рабочей нагрузке, чтобы свести к минимуму горячие точки доступа, повысить производительность запросов и обойти ограничения физического хранилища. Однако это сложная задача, которая часто требует использования пользовательского инструмента или процесса.
Репликация секций. При репликации каждой секции она обеспечивает дополнительную защиту от сбоя. Если одна реплика завершается ошибкой, запросы можно направлять к рабочей копии.
Если вы достигнете физических ограничений стратегии секционирования, возможно, потребуется расширить масштабируемость до другого уровня. Например, если секционирование находится на уровне базы данных, может потребоваться найти или реплицировать секции в нескольких базах данных. Если секционирование уже находится на уровне базы данных, а физические ограничения являются проблемой, это может означать, что необходимо найти или реплицировать секции в нескольких учетных записях размещения.
Избегайте транзакций, обращаюющихся к данным в нескольких секциях. Некоторые хранилища данных реализуют согласованность транзакций и целостность для операций, которые изменяют данные, но только если данные находятся в одной секции. Если вам нужна поддержка транзакций в нескольких секциях, вам, вероятно, потребуется реализовать это как часть логики приложения, так как большинство систем секционирования не обеспечивают встроенную поддержку.
Для всех хранилищ данных требуются некоторые действия по управлению и мониторингу. Задачи могут варьироваться от загрузки данных, резервного копирования и восстановления данных, реорганизации данных и обеспечения правильности и эффективности работы системы.
Рассмотрим следующие факторы, влияющие на оперативное управление:
Как реализовать соответствующие задачи управления и эксплуатации при секционирования данных. Эти задачи могут включать резервное копирование и восстановление, архивацию данных, мониторинг системы и другие административные задачи. Например, поддержание логической согласованности во время операций резервного копирования и восстановления может быть проблемой.
Как загрузить данные в несколько секций и добавить новые данные, поступающие из других источников. Некоторые средства и служебные программы могут не поддерживать сегментированные операции с данными, например загрузку данных в правильную секцию.
Как архивировать и удалять данные регулярно. Чтобы предотвратить чрезмерный рост секций, необходимо регулярно архивировать и удалять данные (например, ежемесячно). Может потребоваться преобразовать данные в соответствие с другой схемой архива.
Как найти проблемы с целостностью данных. Рассмотрите возможность выполнения периодического процесса для поиска любых проблем целостности данных, таких как данные в одной секции, которая ссылается на отсутствующую информацию в другой. Процесс может попытаться устранить эти проблемы автоматически или создать отчет для проверки вручную.
Перебалансирование секций
По мере развития системы может потребоваться настроить схему секционирования. Например, отдельные секции могут начать получать непропорциональное количество трафика и становиться горячим, что приводит к чрезмерному конфликту. Или вы могли бы недооценивать объем данных в некоторых секциях, что приводит к превышению пределов емкости некоторых секций.
Некоторые хранилища данных, такие как Azure Cosmos DB, могут автоматически перебалансировать секции. В других случаях перебалансирование является административной задачей, состоящей из двух этапов:
Определите новую стратегию секционирования.
- Какие секции необходимо разделить (или, возможно, объединить)?
- Что такое новый ключ секции?
Перенос данных из старой схемы секционирования в новый набор секций.
В зависимости от хранилища данных вы можете перенести данные между секциями во время их использования. Это называется миграцией через Интернет. Если это невозможно, может потребоваться сделать секции недоступными при перемещении данных (автономная миграция).
Автономная миграция
Автономная миграция обычно проще, так как она снижает вероятность возникновения спорных проблем. Концептуально автономная миграция работает следующим образом:
- Пометьте секцию в автономном режиме.
- Перемещайте и разделяйте данные в новые разделы.
- Проверьте данные.
- Перенесите новые секции в режим "в сети".
- Удалите старый раздел.
При необходимости можно пометить секцию как доступную только для чтения на шаге 1, чтобы приложения по-прежнему могли считывать данные во время перемещения.
Миграция через Интернет
Миграция через Интернет является более сложной для выполнения, но менее разрушительной. Процесс аналогичен автономной миграции, за исключением того, что исходная секция не помечена как автономная. В зависимости от детализации процесса миграции (например, элемента по элементам и сегментам), код доступа к данным в клиентских приложениях может потребоваться обрабатывать чтение и запись данных, которые хранятся в двух расположениях, исходной секции и новой секции.
Дальнейшие действия
- Узнайте о стратегиях секционирования для определенных служб Azure. Дополнительные сведения см. в стратегиях секционирования данных.
- Целевые показатели масштабируемости и производительности службы хранилища Azure
Связанные ресурсы
Следующие шаблоны проектирования могут иметь отношение к вашему сценарию:
Шаблон сегментирования описывает некоторые распространенные стратегии сегментирования данных.
Шаблон таблицы индексов показывает, как создавать вторичные индексы по данным. Приложение может быстро получить данные с помощью запросов, не ссылающихся на первичный ключ коллекции.
В шаблоне материализованного представления описывается создание предварительно заполненных представлений, которые суммируют данные для поддержки быстрых операций запросов. Этот подход может оказаться полезным в секционируемом хранилище данных, если секции, содержащие суммированные данные, распределяются по нескольким сайтам.