В этой статье описываются стратегии секционирования данных в различных хранилищах данных Azure. Общие рекомендации по секционировании данных см. в статье Секционирование данных.
Секционирование базы данных SQL Azure
Одна база данных SQL имеет ограничение на объем содержащихся в ней данных. Пропускная способность ограничена архитектурными факторами и числом поддерживаемых одновременных подключений.
Эластичные пулы поддерживают горизонтальное масштабирование базы данных SQL. С помощью эластичных пулов можно секционировать данные в сегменты, которые распределены между несколькими базами данных SQL. Можно также добавлять или удалять сегменты по мере роста или уменьшения объема обрабатываемых данных. Кроме того, эластичные пулы помогают уменьшить количество конфликтов за счет распределения нагрузки между базами данных.
Каждый сегмент реализуется как база данных SQL. Сегмент может содержать более одного набора данных, называемого шардлетом. Каждая база данных хранит метаданные, которые описывают содержащиеся в ней шардлеты. Шардлет может быть отдельным элементом данных или группой элементов, которые совместно используют один и тот же ключ шардлета. Например, в приложении с несколькими клиентами ключом шардлета может быть идентификатор клиента, а все данные для клиента могут храниться в одном и том же шардлете.
Клиентские приложения отвечают за связывание набора данных с ключом шардлета. Отдельная База данных SQL выступает в качестве глобального диспетчера карт сегментов. Эта база данных содержит список всех сегментов и шардлетов в системе. Приложение подключается к базе данных диспетчера карты сегментов для получения копии карты сегментов. Оно локально кэширует карту сегментов и использует ее для маршрутизации запросов к данным в соответствующий сегмент. Эта функция скрыта за рядом API-интерфейсов, содержащихся в клиентской библиотеке эластичной базы данных, доступной для Java и .NET.
Дополнительные сведения об эластичных пулах см. в статье Развертывание с помощью Базы данных SQL Azure.
Можно реплицировать глобальную базу данных диспетчера карты сегментов для уменьшения задержки и повышения доступности. С помощью одной из ценовых категорий "Премиум" можно настроить активную георепликацию для непрерывного копирования данных в базы данных в разных регионах.
В качестве альтернативы можно использовать синхронизацию данных SQL Azure или Фабрику данных Azure для репликации базы данных диспетчера карты сегментов между регионами. Репликация этого типа запускается периодически и лучше подходит, если карта сегментов изменяется редко. Выбор ценовой категории "Премиум" при этом не требуется.
Эластичная база данных предоставляет две схемы для сопоставления данных и шардлетов и их хранения в сегментах.
Карта сегментов в виде списка связывает один ключ с шардлетом. Например, в мультитенантной системе данные для каждого клиента могут быть связаны с уникальным ключом и храниться в собственном шардлете. Чтобы обеспечить изоляцию, каждый шардлет может храниться в собственном сегменте.

Скачайте файл Visio этой схемы.
Карта сегментов в виде диапазона связывает набор связанных значений ключа с шардлетом. Например, можно группировать данные для набора клиентов (каждый из которых имеет собственный ключ) в пределах одного шардлета. Эта схема дешевле первой, так как клиенты совместно используют хранилище данных, хотя и с меньшей степенью изоляции.

Скачивание файла Visio этой схемы
Один сегмент может содержать данные для нескольких шардлетов. Например, можно использовать шардлеты в виде списка для хранения данных разных несмежных клиентов в одном сегменте. Можно также смешивать шардлеты в виде диапазона и шардлеты в виде списка в одном сегменте, хотя они будут использоваться с помощью разных карт. Этот подход показан на схеме ниже.

Скачайте файл Visio этой схемы.
Эластичные пулы позволяют добавлять и удалять сегменты в соответствии с изменением объема данных. Клиентские приложения могут создавать и удалять сегменты динамически, а также прозрачно обновлять диспетчер карты сегментов. Однако удаление сегмента является необратимой операцией, в ходе которой также необходимо удалить все данные этого сегмента.
Если приложению требуется разбить сегмент на два отдельных сегмента или объединить их, можно использовать средство разделения и объединения. Это средство работает как веб-служба Azure, безопасно перенося данные между сегментами.
Такая схема секционирования способна значительно повлиять на производительность системы. Она также может влиять на скорость добавления или удаления сегментов, а также повторного секционирования данных между сегментами. Примите во внимание следующее:
Группируйте используемые вместе данные в одном сегменте и избегайте операций с доступом к данным, хранящимся в нескольких сегментах. Сегмент сам является базой данных SQL, а межбазовые соединения должны выполняться на стороне клиента.
Хотя База данных SQL не поддерживает межбазовые соединения, вы можете использовать средства Эластичной базы данных для выполнения запросов к нескольким сегментам. При запросе к нескольким сегментам отдельные запросы направляются к каждой базе данных, а полученные результаты объединяются.
Не создавайте такую систему, в которой есть зависимости между сегментами. Ограничения целостности данных, триггеры и хранимые процедуры в одной базе данных не могут ссылаться на объекты в другой базе данных.
При наличии эталонных данных, которые часто используется при выполнении запросов, рассмотрите возможность репликации данных между сегментами. Такой подход может исключить необходимость в соединениях между базами данных. В идеальном случае такие данные должны быть статическими или медленно изменяющимися, чтобы максимально упростить репликацию и снизить вероятность устаревания данных.
Шардлеты, принадлежащие к одной карте сегментов, должны иметь одинаковую схему. В Базе данных SQL это не является обязательным, но управление данными и запросами становится очень сложным, если шардлеты имеют разные схемы. Вместо этого создайте отдельные карты сегментов для каждой схемы. Помните, что данные, принадлежащие к разным шардлетам, можно хранить в одном сегменте.
Транзакционные операции поддерживаются только для данных одного сегмента, но не между сегментами. Транзакции могут охватывать шардлеты при условии, что они являются частью одного сегмента. Таким образом, если в соответствии с вашей бизнес-логикой требуется выполнять транзакции, храните данные в одном сегменте или выбирайте итоговую согласованность.
Размещайте сегменты поближе к пользователям, которые обращаются к данным в этих сегментах. Эта стратегия помогает сократить задержку.
Избегайте смешения активных и относительно неактивных сегментов. Попробуйте равномерно распределить нагрузку по сегментам. Для этого может потребоваться хэшировать ключи сегментирования. При географическом распределении сегментов убедитесь, что хэшированные ключи соответствуют шардлетам, хранящимся в сегментах, которые находятся рядом с использующими эти данные пользователями.
Секционирование хранилища таблиц Azure
Хранилище таблиц Azure — это хранилище "ключ-значение", предназначенное для секционирования. Все сущности хранятся в секции, а секции управляются внутренне хранилищем таблиц Azure. Каждая сущность, хранящаяся в таблице, должна предоставить ключ, состоящий из двух компонентов:
Ключ секции. Это строковое значение, определяющее секцию, в которой хранилище таблиц Azure будет размещать сущность. Все сущности с одинаковым ключом секции хранятся в одной секции.
Ключ строки. Это строковое значение, определяющее сущность в секции. Все сущности в секции сортируются лексически в порядке возрастания с помощью этого ключа. Сочетание ключа секции и ключа строки должно быть уникальным для каждой сущности, а его длина не может превышать 1 КБ.
Если сущность добавляется в таблицу с ранее неиспользуемым ключом секции, хранилище таблиц Azure создает новую секцию для этой сущности. Другие сущности с одинаковым ключом секции будут храниться в одной секции.
Этот механизм эффективно реализует стратегию автоматического масштабирования. Каждая секция хранится на одном сервере в центре обработки данных Azure, чтобы обеспечить быстрое выполнение запросов, получающих данные из одной секции.
Корпорация Майкрософт опубликовала целевые показатели масштабируемости для службы хранилища Azure. Если для вашей системы высока вероятность превышения этих ограничений, рассмотрите возможность разделения сущностей на несколько таблиц. Используйте вертикальное секционирование и разделите поля на группы, которые, скорее всего, используются вместе.
На схеме ниже показан пример логической структуры для учетной записи хранения. Учетные записи хранения содержат три таблицы: сведения о клиенте, сведения о продукции и сведения о заказах.
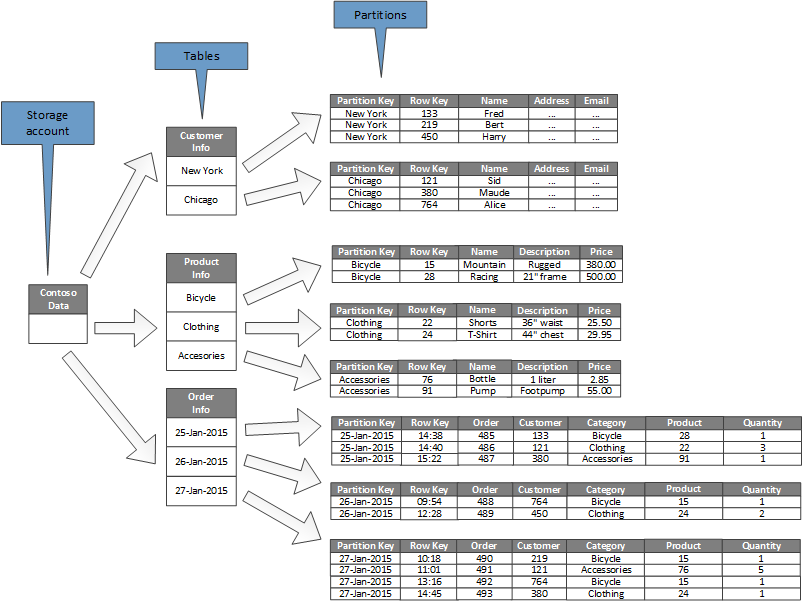
Каждая таблица содержит несколько секций.
- В таблице сведений о клиентах данные секционируются по городам, в которых находятся клиенты. Ключ строки содержит идентификатор клиента.
- В таблице сведений о продукции продукты секционированы по категориям, а ключ строки содержит номер продукта.
- В таблице сведений о заказах заказы секционируются по дате заказа, а ключ строки указывает время получения заказа. Все данные в каждой секции упорядочены с помощью ключа строки.
При разработке сущностей для хранилища таблиц Azure следует учитывать следующие моменты:
При выборе ключа секции и ключа строки необходимо учитывать способ доступа к данным. Необходимо выбрать сочетание ключа секции и ключа строки, которое поддерживает большинство запросов. Наиболее эффективные запросы будут получать данные, указав ключ секции и ключ строки. Запросы, которые определяют ключ секции и диапазон ключей строк, могут быть выполнены путем сканирования одной секции. Это относительно быстро, поскольку данные хранятся в порядке значений ключей строк. Если в запросах не указано, какую секцию сканировать, сканируются все секции.
Если у сущности есть один естественный ключ, используйте его в качестве ключа секции и укажите пустую строку в качестве ключа строки. Если сущность имеет составной ключ, состоящий из двух свойств, выберите наиболее медленно изменяющееся свойство в качестве ключа секции, а второе — в качестве ключа строки. Если сущность имеет более двух свойств ключа, используйте объединение свойств, чтобы указать ключи секций и строк.
Если вы регулярно выполняете запросы, которые ищут данные с помощью полей, отличных от ключей секций и строк, рассмотрите возможность реализации шаблона таблицы индекса или попробуйте использовать другое хранилище данных, которое поддерживает индексирование, например Azure Cosmos DB.
Если вы создаете ключи секций с помощью монотонной последовательности (например, "0001", "0002", "0003") и каждая секция содержит только ограниченный объем данных, хранилище таблиц Azure может физически группировать эти секции на одном сервере. При использовании службы хранилища Azure предполагается, что приложение, скорее всего, будет выполнять запросы к смежным секциям (запросы к диапазону) и что оно оптимизировано для такой ситуации. Но такой подход может привести к дисбалансу, так как все операции добавления новых сущностей, вероятно, будут выполняться относительно одного конца этого диапазона. Он также может снизить масштабируемость. Чтобы более равномерно распределить нагрузку, рассмотрите возможность хэширования ключа секции.
Хранилище таблиц Azure поддерживает транзакционные операции для сущностей, принадлежащих к одной секции. Приложение может выполнять несколько операций вставки, обновления, удаления или объединения как одну неделимую операцию, если число сущностей транзакции не превышает 100, а размер полезных данных запроса — 4 МБ. Операции, охватывающие несколько секций, не являются транзакционными и могут требовать реализации итоговой согласованности. Дополнительные сведения о хранилище таблиц и транзакциях см. в статье Performing Entity Group Transactions (Выполнение групповых транзакций для сущности).
Учитывайте свойства ключа секции:
Использование одного и того же ключа секции для каждой сущности приведет к созданию одной секции, хранящейся на одном сервере. В результате масштабирование секции будет затруднено, и нагрузка на одном сервере возрастет. Следовательно, этот подход применим только для хранения небольшого количества сущностей. Но он гарантирует, что все сущности смогут участвовать в транзакциях группы сущностей.
Использование уникального ключа секции для каждой сущности приведет к созданию службой хранилища таблиц отдельных секций для каждой сущности, в результате чего может появиться большое количество небольших секций. Этот подход лучше поддается масштабированию, чем подход с использованием одного ключа секции, но транзакции группы сущностей невозможны. Кроме того запросы, получающие более одной сущности, могут включать чтение с нескольких серверов. Но, если приложение выполняет запросы к диапазону, использование монотонной последовательности ключей секций может помочь оптимизировать такие запросы.
Совместное использование ключа секции в подмножестве сущностей позволяет группировать связанные сущности в одну секцию. Операции, включающие связанные сущности, можно выполнить с помощью транзакции группы сущностей, и запросы, получающие набор связанных сущностей, могут удовлетворяться путем доступа к одному серверу.
Дополнительные сведения см. в руководстве по проектированию таблиц служба хранилища Azure и стратегии масштабирования секционирования.
Секционирование хранилища BLOB-объектов Azure
Хранилище BLOB-объектов Azure позволяет хранить большие двоичные объекты. Используйте блочные BLOB-объекты в сценариях, где требуется быстро отправлять или скачивать большие объемы данных. Используйте страничные BLOB-объекты для приложений, требующих случайного, а не последовательного доступа к частям данных.
Каждый большой двоичный объект (блок или страница) хранится в контейнере в учетной записи служба хранилища Azure. Контейнеры можно использовать для группировки связанных BLOB-объектов с одинаковыми требованиями безопасности. Это группирование на логическом, а не на физическом уровне. Внутри контейнера каждый BLOB-объект имеет уникальное имя.
Ключ секции для большого двоичного объекта состоит из имен учетной записи, контейнера и большого двоичного объекта. Данные распределяются по диапазонам с помощью ключа секции, а затем эти диапазоны распределяются по системе. Большие двоичные объекты могут быть распределены по нескольким серверам для горизонтального увеличения масштаба доступа к ним, но один большой двоичный объект может обслуживаться только одним сервером.
Если в схеме именования используются метки времени или числовые идентификаторы, это может привести к чрезмерному трафику к одной секции, затрудняя эффективную балансировку нагрузки системой. Например, при ежедневных операциях с BLOB-объектом с меткой времени вида гггг-мм-дд, весь трафик такой операции направляется на один сервер секционирования. Вместо этого рекомендуется добавлять к именам трехзначный хэш в виде префикса. Дополнительные сведения см. в статье Соглашение об именовании секций.
Действия записи одного блока или страницы являются атомарными в отличие от операций, охватывающих блоки, страницы или BLOB-объекты. Если требуется обеспечить согласованность при выполнении операций записи всех блоков, страниц и BLOB-объектов, необходимо убрать блокировку записи с помощью аренды BLOB-объекта.
Секционирование очередей служба хранилища Azure
служба хранилища Azure очереди позволяют реализовать асинхронное обмен сообщениями между процессами. Учетная запись служба хранилища Azure может содержать любое количество очередей, и каждая очередь может содержать любое количество сообщений. Единственным ограничением является место, доступное в учетной записи хранения. Максимальный размер отдельного сообщения составляет 64 КБ. Если требуются сообщения большего размера, попробуйте использовать очереди служебной шины Azure.
Каждая очередь хранилища имеет уникальное имя в пределах учетной записи хранения, где она содержится. Очереди секций Azure основаны на имени. Все сообщения одной очереди хранятся в одной секции, управляемой одним сервером. Различными очередями могут управлять разные серверы, чтобы сбалансировать нагрузку. Выделение очередей для серверов является прозрачным для приложений и пользователей.
В приложении большого объема не используйте одну и ту же очередь хранилища для всех экземпляров приложения: этот подход может привести к тому, что на сервере образуется очередь, являющаяся горячей точкой. Используйте различные очереди для различных функциональных областей приложения. служба хранилища Azure очереди не поддерживают транзакции, поэтому перенаправление сообщений в разные очереди должно иметь мало влияния на согласованность обмена сообщениями.
Очередь служба хранилища Azure может обрабатывать до 2000 сообщений в секунду. Если необходимо обрабатывать сообщения с большей скоростью, рассмотрите возможность создания нескольких очередей. Например, в глобальном приложении создайте отдельные очереди хранилища в отдельных учетных записях хранения для обработки экземпляров приложений, работающих в каждом регионе.
Секционирование Служебной шины Azure
Служебная шина Azure использует брокер сообщений для обработки сообщений, отправленных в очередь или раздел служебной шины. По умолчанию все сообщения, отправленные в очередь или раздел, обрабатываются одним процессом брокера сообщений. Эта архитектура может ограничить общую пропускную способность очереди сообщений. Однако можно секционировать очереди или разделы при их создании. Это можно сделать, задав свойству EnablePartitioning описания очереди или раздела значение true.
Секционированная очередь или раздел делится на несколько фрагментов, для каждого из которых выполняется резервное копирование в отдельном хранилище сообщений и брокере сообщений. Служебная шина отвечает за создание этих фрагментов и управление ими. Когда приложение отправляет сообщение в секционированную очередь или раздел, служебная шина назначает сообщение фрагменту для этой очереди или раздела. Когда приложение получает сообщение из очереди или подписки, служебная шина проверяет каждый фрагмент на наличие следующего доступного сообщения и передает его приложению для обработки.
Эта структура позволяет распределять нагрузку между брокерами сообщений и хранилищами сообщений, повышая масштабируемость и доступность. Если брокер или хранилище сообщений для одного фрагмента временно недоступны, служебная шина может получить сообщения от одного из оставшихся доступных фрагментов.
Служебная шина присваивает сообщение фрагменту следующим образом.
Если сообщение относится к сеансу, все сообщения с одинаковым значением свойства SessionId отправляются в один и тот же фрагмент.
Если сообщение не относится к сеансу, но отправитель указал значение для свойства PartitionKey, все сообщения с тем же значением PartitionKey отправляются в тот же фрагмент.
Примечание.
Если значения заданы обоим свойствам (SessionId и PartitionKey), они должны быть одинаковыми, иначе сообщение будет отклонено.
Если свойства SessionId и PartitionKey для сообщения не заданы, но включен поиск повторяющихся данных, будет использоваться свойство MessageId. Все сообщения с тем же значением MessageId будут направляться в тот же фрагмент.
Если сообщения не содержат свойства SessionId, PartitionKey или MessageId, служебная шина назначает сообщения фрагментам по очереди. Если фрагмент недоступен, служебная шина перейдет к следующему. Таким образом, временная ошибка в инфраструктуре обмена сообщениями не вызовет сбой операции отправки сообщения.
При принятии решения о том, стоит ли и как именно секционировать очередь сообщений или раздел служебной шины, рекомендуется учитывать следующее.
Очереди и разделы служебной шины создаются в области пространства имен служебной шины. В настоящее время служебная шина обеспечивает до 100 секционированных очередей или разделов на пространство имен.
Каждое пространство имен служебной шины налагает квоты на доступные ресурсы, такие как количество подписок на раздел, количество параллельных запросов на отправку и получение в секунду, а также максимальное число одновременных подключений, которые можно установить. Эти квоты описаны в статье Квоты на служебную шину. Если предполагается, что эти значения будут превышены, создайте дополнительные пространства имен с собственными очередями и разделами и распределите работу по этим пространствам имен. Например, в глобальном приложении создайте отдельные пространства имен в каждом регионе и настройте экземпляры приложения на использование очередей и разделов в ближайшем пространстве имен.
Сообщения, отправленные в рамках транзакции, должны указать ключ секции. Это может быть свойство SessionId, PartitionKey или MessageId. Все сообщения, отправленные в рамках одной транзакции, должны указать один и тот же ключ секции, так как их должен обрабатывать один брокер сообщений. Невозможно отправить сообщения в различные очереди или разделы в рамках одной транзакции.
Невозможно настроить автоматическое удаление секционированной очереди или раздела, когда они становятся неактивными.
При построении межплатформенных или гибридных решений в настоящее время нельзя использовать секционированные очереди и расширенный протокол управления очередью сообщений (AMQP).
Секционирование Azure Cosmos DB
Azure Cosmos DB для NoSQL — это база данных NoSQL для хранения документов JSON. Документ в базе данных Azure Cosmos DB — это сериализованное JSON-представление объекта или другого фрагмента данных. Фиксированные схемы не применяются, за исключением того, что каждый документ должен содержать уникальный идентификатор.
Документы организованы в коллекции. Связанные документы можно группировать в коллекции. Например, в системе, которая хранит сообщения блогов, можно хранить содержимое каждой записи блога в виде документа в коллекции. Можно также создавать коллекции для каждого типа субъекта. Кроме того, в мультитенантном приложении, таком как система, где разные авторы управляют собственными блогами и записями, можно секционировать блоги по авторам и создавать отдельную коллекцию для каждого автора. Выделенное для коллекций дисковое пространство гибкое и может уменьшаться или увеличиваться по мере необходимости.
Azure Cosmos DB поддерживает автоматическое секционирование данных на основе ключа секции, определяемого приложением. Логический раздел — это секция, которая хранит все данные для значения ключа одной секции. Все документы с одинаковым значением ключа раздела помещаются в один логический раздел. Azure Cosmos DB распределяет значения в соответствии с хэшом ключа секции. Логическая секция имеет максимальный размер 20 ГБ. Следовательно, выбор ключа секции — это важное решение, которое принимается на этапе проектирования. Выберите свойство с широким диапазоном значений и шаблоны доступа. Дополнительные сведения см. в разделе Секционирование и масштабирование в Azure Cosmos DB.
Примечание.
Каждая база данных Azure Cosmos DB имеет уровень производительности, определяющий объем ресурсов, которые он получает. Каждый уровень производительности связан с ограничением частоты в виде единицы запроса (ЕЗ). Ограничение частоты RU определяет объем ресурсов, которые зарезервированы для этой коллекции и доступны для эксклюзивного использования этой коллекцией. Стоимость коллекции зависит от выбранного для нее уровня производительности. Чем выше уровень производительность (и ограничение частоты RU), тем выше стоимость. Уровень производительности коллекции можно настроить с помощью портала Azure. См. дополнительные сведения о единицах запросов в базе данных Azure Cosmos DB.
Если механизм секционирования, который предоставляет Azure Cosmos DB, недостаточно, может потребоваться сегментировать данные на уровне приложения. Коллекция документов предоставляет естественный механизм для секционирования данных в пределах отдельной базы данных. Самый простой способ реализации сегментирования — создание коллекции для каждого сегмента. Контейнеры — это логические ресурсы, которые могут охватывать один или несколько серверов. Контейнеры фиксированного размера имеют максимальное ограничение в 20 ГБ и 10 000 ЕЗ/с. Для контейнеров неограниченного размера максимальный размер хранилища не предусмотрен, но необходимо указать ключ секции. При сегментировании клиентское приложение должно направлять запросы в соответствующий сегмент, как правило, реализуя собственный механизм сопоставления на основе некоторых атрибутов данных, которые определяют ключ сегмента.
Все базы данных создаются в контексте учетной записи базы данных Azure Cosmos DB. Одна учетная запись может содержать несколько баз данных. Также она определяет, в каком регионе создаются эти базы данных. Кроме того, для каждой учетной записи отдельно настраивается управление доступом. Учетные записи Azure Cosmos DB можно использовать для геодоступных сегментов (коллекций в базах данных) рядом с пользователями, которым требуется доступ, и применять ограничения, чтобы только те пользователи могли подключаться к ним.
При выборе способа секционирования данных с помощью Azure Cosmos DB для NoSQL следует учитывать следующие моменты:
Ресурсы, доступные для базы данных Azure Cosmos DB, подвергаются ограничениям квоты учетной записи. Каждая база данных может содержать несколько коллекций, каждая из которых связана с уровнем производительности, который управляет ограничением частоты ЕЗ (зарезервированной пропускной способностью) для этой коллекции. Дополнительные сведения см. в статье Подписка Azure, границы, квоты и ограничения службы.
Каждый документ должен иметь атрибут, который используется для идентификации этого документа в пределах содержащей его коллекции. Этот атрибут отличается от ключа сегмента, который определяет, в какой коллекции содержится документ. Коллекция может содержать большое количество документов. Теоретически она ограничена только максимальной длиной идентификатора документа. Идентификатор документа может включать до 255 символов.
Все операции с документом выполняются в контексте транзакции. Транзакции выполняются в той коллекции, где содержится документ. Если произошел сбой операции, происходит откат выполняемой работы. Пока выполняется операция с документом, любые сделанные изменения подвергаются изоляции уровня моментальных снимков. Этот механизм гарантирует, что если, например, запрос на создание нового документа завершается ошибкой, другой пользователь, одновременно запрашивающий базу данных, не увидит частичный документ, который затем удаляется.
Запросы к базам данных также ограничиваются уровнем коллекции. Один запрос может получать данные только из одной коллекции. Если требуется получить данные из нескольких коллекций, необходимо запросить каждую коллекцию отдельно и объединить результаты в коде приложения.
Azure Cosmos DB поддерживает программируемые элементы, которые могут храниться в коллекции вместе с документами. Это хранимые процедуры, определяемые пользователем функции и триггеры (на языке JavaScript). Эти элементы могут получить доступ к любому документу в одной коллекции. Кроме того, эти элементы выполняются либо внутри области внешней транзакции (в случае триггера, срабатывающего в результате операций создания, удаления и замены документа), либо путем запуска новой транзакции (в случае хранимой процедуры, выполняемой в результате явного запроса клиента). Если код в программируемом элементе создает исключение, транзакция откатывается. Чтобы сохранить целостность и согласованность между документами, можно использовать хранимые процедуры и триггеры, но эти документы всегда должны быть частью одной коллекции.
В базах данных следует хранить такие коллекции, нагрузка на которые не превысит ограничения пропускной способности, установленных для соответствующего уровня производительности. См. дополнительные сведения о единицах запросов в базе данных Azure Cosmos DB. Если вы ожидаете, что нагрузка превысит эти ограничения, попробуйте распределить коллекции между базами данных в разных учетных записях, чтобы снизить нагрузку на каждую коллекцию.
Секционирование Поиска Azure
Возможность поиска данных часто является основным методом навигации и просмотра, который предоставляют многие веб-приложения. Она помогает пользователям быстро находить ресурсы (например продукты в приложении электронной коммерции) на основе сочетания условий поиска. Служба поиска Azure предоставляет возможности полнотекстового поиска по веб-содержимому и включает такие функции, как автозаполнение, предлагаемые запросы на основании совпадений и многогранная навигация. Дополнительные сведения см. в статье Что такое поиск Azure?
Служба поиска Azure хранит подлежащее поиску содержимое как документы JSON в базе данных. Можно определить индексы, которые указывают поля для поиска в этих документах, и предоставить эти определения службе поиска Azure. Когда пользователь отправляет поисковый запрос, служба поиска Azure использует соответствующие индексы для поиска совпадающих элементов.
Чтобы снизить количество конфликтов, можно разделить хранилища, используемые службой поиска Azure, на 1, 2, 3, 4, 6 или 12 секций, и каждую секцию реплицировать до 6 раз. Произведение числа секций и числа реплик называется единицей поиска (SU). Один экземпляр службы поиска Azure может содержать не более 36 единиц поиска (база данных с 12 секциями поддерживает не более 3 реплик).
Плата взимается за каждую единицу поиска, выделенную для службы. При увеличении объема содержимого для поиска или скорости запросов поиска можно добавить единицы поиска в существующий экземпляр службы поиска Azure для обработки дополнительной нагрузки. Сама служба поиска Azure отвечает за равномерное распределение документов по секциям. Сейчас стратегии секционирования вручную не поддерживаются.
Каждая секция может содержать не более 15 миллионов документов или занимать не более 300 ГБ дискового пространства (в зависимости от того, какое значение ниже). Можно создать до 50 индексов. Производительность службы зависит от сложности документов, доступных индексов и эффектов задержки в сети. В среднем одна реплика (1 единица поиска) должна уметь обрабатывать 15 запросов в секунду (QPS), хотя рекомендуется выполнить тестирование производительности со своими данными, чтобы получить более точные показатели пропускной способности. Дополнительные сведения см. в статье Ограничения Поиска Azure.
Примечание.
В документах для поиска можно хранить ограниченный набор типов данных: строки, логические значения, числовые данные, данные даты и времени и географические данные. Дополнительные сведения см. на странице Поддерживаемые типы данных (служба поиска Azure) на веб-сайте Майкрософт.
Вы можете лишь частично контролировать то, как служба поиска Azure секционирует данные для каждого экземпляра службы. Однако в глобальной среде можно повысить производительность и снизить задержку и количество конфликтов за счет секционирования самой службы одним из следующих способов.
Создайте экземпляр службы поиска Azure в каждом географическом регионе и убедитесь в том, что клиентские приложения направляются к ближайшему доступному экземпляру. Эта стратегия требует своевременной репликации всех обновлений содержимого для поиска во всех экземплярах службы.
Создайте два уровня службы поиска Azure:
- локальную службу в каждом регионе, которая содержит наиболее часто применяемые пользователями этого региона данные. Пользователи могут направлять запросы в локальную службу для получения быстрых, но ограниченных результатов.
- Глобальная служба, которая включает в себя все данные. Пользователи могут направлять запросы в глобальную службу для получения менее быстрых, но более полных результатов.
Этот подход наиболее эффективен при значительных региональных различиях в данных, по которым выполняется поиск.
Секционирование Кэша Azure для Redis
Кэш Azure для Redis предоставляет службу общего кэша в облаке, которая основана на хранилище данных Redis типа "ключ-значение". Как понятно из названия, Кэш Azure для Redis создан как решение для кэширования. Поэтому его следует использовать только для хранения временных данных, а не как постоянное хранилище данных. Приложения, использующие Кэш Azure для Redis, должны иметь возможность продолжать работу, даже если кэш недоступен. Кэш Azure для Redis поддерживает первичную или вторичную репликацию для обеспечения высокой доступности, но в настоящее время максимальный размер кэша ограничен 53 ГБ. Если требуется больше места, необходимо создать дополнительные кэши. См. сведения на странице с ценами на Azure Cache for Redis.
Секционирование хранилища данных Redis включает в себя разбиение данных по экземплярам службы Redis. Каждый экземпляр представляет одну секцию. Кэш Azure для Redis абстрагирует службы Redis за фасадом и не раскрывает их напрямую. Самый простой способ реализации секционирования — создание нескольких экземпляров Кэша Azure для Redis и распределение данных между ними.
Каждый элемент данных можно связать с идентификатором (ключом секции), который указывает, в каком кэше его следует хранить. Логика клиентского приложения может использовать этот идентификатор для перенаправления запросов в соответствующую секцию. Эта схема очень проста, но при изменении схемы секционирования (например, если создаются дополнительные экземпляры Кэша Azure для Redis) может потребоваться изменение конфигурации клиентских приложений.
Собственный Redis (не Кэш Azure для Redis) поддерживает серверную часть секционирования на основе кластеризации Redis. При таком подходе данные делятся поровну между серверами с помощью механизма хэширования. На каждом сервере Redis хранятся метаданные, описывающие диапазон содержащихся в секции хэш-ключей, а также сведения о хэш-ключах, которые находятся в секциях на других серверах.
Клиентские приложения просто отправляют запросы на любой сервер-участник Redis (скорее всего, на ближайший). Сервер Redis проверяет запрос клиента. Если его можно разрешить локально, сервер выполняет запрошенную операцию. В противном случае он перенаправляет запрос на соответствующий сервер.
Эта модель реализуется с помощью кластеризации Redis и более подробно описана на странице Учебник по кластерам Redis на веб-сайте Redis. Кластеризация Redis прозрачна для клиентских приложений. В кластер можно добавлять дополнительные серверы Redis (а также повторно секционировать данные) без необходимости перенастройки клиентов.
Внимание
Кэш Azure для Redis в настоящее время поддерживает кластеризацию Redis только на уровне "Премиум".
Дополнительные сведения о реализации секционирования с помощью Redis см. на странице Partitioning: how to split data among multiple Redis instances (Секционирование: распределение данных между несколькими экземплярами Redis) на веб-сайте Redis. В оставшейся части этого раздела предполагается, что вы реализуете секционирование на стороне клиента или через прокси-сервер.
При выборе способа секционирования данных с помощью Кэша Azure для Redis учитывайте следующие моменты.
Кэш Azure для Redis не предназначен для работы в качестве постоянного хранилища данных, поэтому, какую бы схему секционирования вы ни выбрали, код приложения должен быть готов извлекать данные из источника, не являющегося кэшем.
Часто используемые данные необходимо размещать в одной секции. Redis — это эффективное хранилище типа ключ-значение, которое предоставляет несколько значительно оптимизированных механизмов для структурирования данных. Механизмы могут быть следующими:
- простые строки (двоичные данные длиной до 512 МБ);
- агрегатные типы, такие как списки (которые могут выступать в качестве очередей и стеков);
- наборы (упорядоченные и неупорядоченные);
- хэши (которые могут группировать связанные поля, например элементы, представляющие поля в объекте).
Агрегатные типы позволяют связывать несколько взаимосвязанных значений с одним ключом. Ключ Redis определяет список, набор или хэш, а не элементы данных, которые он содержит. Все эти типы доступны в Кэше Azure для Redis и описаны на странице Data types (Типы данных) на веб-сайте Redis. Например, в части системы электронной коммерции, отслеживающей размещенные клиентами заказы, подробные сведения о каждом клиенте могут храниться в хэше Redis, зашифрованном с помощью идентификатора клиента. Каждый хэш может содержать коллекцию идентификаторов заказов клиента. Отдельный набор Redis может содержать заказы, опять же структурированные как хэши, зашифрованные с помощью идентификатора заказа. Эта структура показана на рис. 8. Обратите внимание, что Redis не реализует какую-либо форму целостности данных, поэтому разработчик сам должен обеспечить связь между клиентами и заказами.
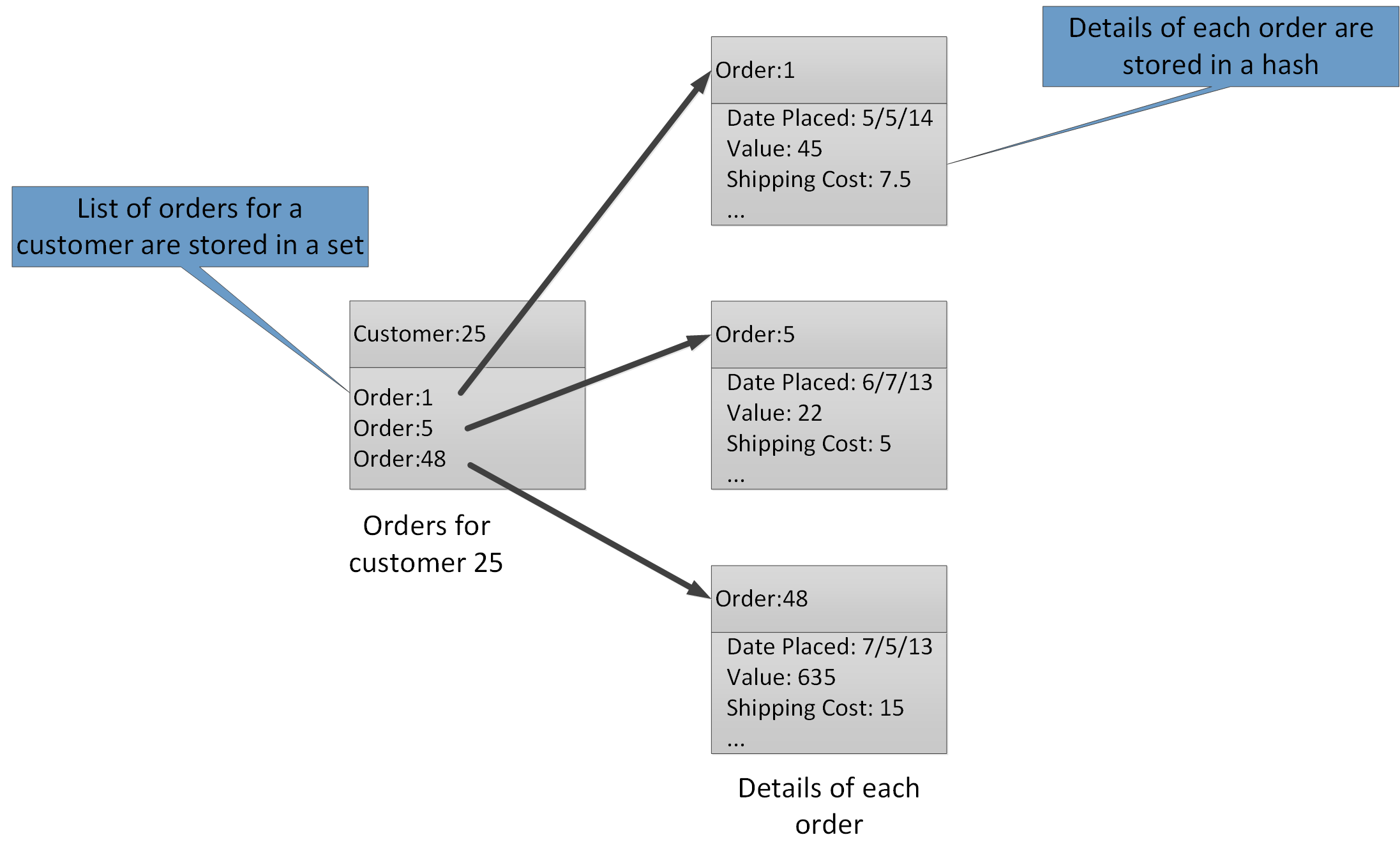
Рис. 8. Предлагаемая структура в хранилище Redis для записи заказов клиентов и сведений о них.
Примечание.
В Redis все ключи являются значениями двоичных данных (например строки Redis) и могут содержать до 512 МБ данных. В теории ключ может содержать почти любую информацию. Однако рекомендуется использовать согласованный контекст именования ключей, согласно которому имя должно описывать тип данных и определять сущность, но не быть слишком длинным. Распространенный подход — использовать ключи в формате "entity_type: ID". Например, можно использовать "customer: 99", чтобы указать ключ для клиента с идентификатором 99.
Можно реализовать вертикальное секционирование, сохраняя связанные сведения в различных агрегатах в одной базе данных. Например, в приложении электронной коммерции можно хранить часто используемые сведения о продуктах в одном хэше Redis, а реже используемые сведения — в другом. Оба хэша могут использовать один и тот же идентификатор продукта как часть ключа. Например, product:nn (где nn — идентификатор продукта) для сведений о продукте и product_details: nn для подробного описания. Эта стратегия позволяет сократить объем данных, к которым обращается большинство запросов.
Перераспределение хранилища данных Redis является сложной задачей, которая требует много времени. Кластеризация Redis может секционировать данные автоматически, но эта возможность не поддерживается в Кэше Azure для Redis. Таким образом, при разработке схемы секционирования попытайтесь оставить достаточно свободного места в каждой секции, чтобы учесть ожидаемый со временем рост данных. Однако помните, что Кэш Azure для Redis предназначен для временного кэширования данных, а также что у данных, хранящихся в кэше, может быть ограниченное время существования, указанное как значение срока жизни (TTL). Для относительно временных данных значение TTL должно быть коротким, но для статических данных значение TTL может быть гораздо большим. Не следует хранить большие объемы долгоживущих данных в кэше, если эти данные, скорее всего, переполнят кэш. Можно указать политику вытеснения, согласно которой Кэш Azure для Redis будет удалять данные, если места осталось мало.
Примечание.
При использовании Кэша Azure для Redis вы указываете максимальный размер кэша (от 250 МБ до 53 ГБ), выбирая соответствующую ценовую категорию. Однако после создания Кэша Azure для Redis нельзя увеличить (или уменьшить) его размер.
Пакеты и транзакции Redis не могут охватывать несколько подключений, поэтому все данные, затрагиваемые пакетом или транзакцией, должны храниться в одной базе данных (в одном сегменте).
Примечание.
Последовательность операций в транзакции Redis не обязательно является неделимой. Команды, которые составляют транзакцию, проверяются и добавляются в очередь перед выполнением. Если на этом этапе возникает ошибка, вся очередь удаляется. Однако после успешной отправки транзакции команды в очереди будут выполняться последовательно. Если какая-либо из команд завершается ошибкой, прерывается только эта команда. Все предыдущие и последующие команды выполняются по очереди. Дополнительные сведения см. на странице Transactions (Транзакции) на веб-сайте Redis.
Redis поддерживает ограниченное число атомарных операций. Единственными операциями такого типа, которые поддерживают несколько ключей, являются MGET и MSET. Операции MGET возвращают коллекцию значений для указанного списка ключей, а операции MSET сохраняют коллекцию значений для указанного списка ключей. Если необходимо использовать эти операции, пары ключ-значение, на которые ссылаются команды MSET и MGET, должны храниться в той же базе данных.
Секционирование Azure Service Fabric
Azure Service Fabric — это платформа микрослужб, которая предоставляет в облаке среду выполнения для распределенных приложений. Service Fabric поддерживает гостевые исполняемые файлы .NET, службы с отслеживанием состояния и без него, а также контейнеры. Службы с отслеживанием состояния предоставляют надежные коллекции для долгосрочного хранения данных в формате "ключ — значение" в кластере Service Fabric. Дополнительные сведения о стратегиях секционирования ключей в надежной коллекции см . в рекомендациях и рекомендациях по надежным коллекциям в Azure Service Fabric.
Следующие шаги
В статье Общие сведения о Service Fabric содержится обзор службы Azure Service Fabric.
В статье Секционирование служб Reliable Services в Service Fabric содержатся дополнительные сведения о надежных службах в Azure Service Fabric.
Секционирование Центров событий Azure
Центры событий Azure предназначены для потоковой передачи данных в больших объемах. В них реализована встроенная поддержка секционирования, которая обеспечивает горизонтальное масштабирование. Каждый потребитель считывает только определенный раздел потока сообщений.
Издателю событий известен только ключ секции, но не сама секция, в которой публикуются события. Благодаря разделению ключа и секции отправителю не нужно располагать избыточными сведениями о последующей обработке и хранении событий. (Также есть возможность отправлять события напрямую в определенную секцию, но обычно так делать не следует.)
Выбирать число секций следует с учетом долгосрочной перспективы. Создав концентратор событий, вы уже не сможете изменить число секций.
Следующие шаги
Дополнительные сведения об использовании секций в Центрах событий см. в статье Что такое Центры событий?
См. также дополнительные сведения о доступности и согласованности в Центрах событий.