Устранение узких мест производительности в Azure Databricks
Примечание.
В этой статье используется библиотека открытый код, размещенная на сайте GitHubhttps://github.com/mspnp/spark-monitoring:
Исходная библиотека поддерживает Azure Databricks Runtimes 10.x (Spark 3.2.x) и более ранних версий.
Databricks внесли обновленную версию для поддержки Azure Databricks Runtimes 11.0 (Spark 3.3.x) и выше в l4jv2 ветви по адресу: https://github.com/mspnp/spark-monitoring/tree/l4jv2
Обратите внимание, что выпуск 11.0 не совместим обратно из-за различных систем ведения журнала, используемых в Databricks Runtimes. Не забудьте использовать правильную сборку для среды выполнения Databricks. Библиотека и репозиторий GitHub находятся в режиме обслуживания. Нет планов для дальнейших выпусков, и поддержка проблем будет максимальной. Для получения дополнительных вопросов о библиотеке или стратегии мониторинга и ведения журнала сред Azure Databricks обратитесь в службу azure-spark-monitoring-help@databricks.comмониторинга и ведения журнала.
В этой статье описывается использование панелей мониторинга для поиска узких мест производительности при выполнении заданий Spark в Azure Databricks.
Azure Databricks — это служба аналитики на основе Apache Spark, которая упрощает и ускоряет разработку и развертывание аналитики больших данных. Мониторинг и устранение проблем производительности очень важны при выполнении рабочих нагрузок Azure Databricks. Для обнаружения распространенных проблем с производительностью полезно использовать визуализации мониторинга на основе данных телеметрии.
Необходимые компоненты
Чтобы настроить панели мониторинга Grafana, показанные в этой статье, сделайте следующее:
Настройте кластер Databricks для отправки данных телеметрии в рабочую область Log Analytics с помощью библиотеки мониторинга Azure Databricks. Подробнее см. в файле сведений на сайте GitHub.
Разверните Grafana на виртуальной машине. См. статью Визуализация метрик Azure Databricks с помощью панелей мониторинга.
Развернутая панель мониторинга Grafana включает набор визуализаций временных рядов. Каждый граф представляет собой график временных рядов для метрик, связанных с заданием Apache Spark, этапами задания и задачами, составляющими каждый такой этап.
Общие сведения о производительности Azure Databricks
В основе Azure Databricks лежит Apache Spark — распределенная вычислительная система общего назначения. Код приложения, называемый заданием, выполняется в кластере Apache Spark, который назначается диспетчером кластеров. Как правило, задание — это единица вычислений высшего уровня. Задание представляет собой полную операцию, выполняемую приложением Spark. Типичная операция включает чтение данных из источника, применение преобразований данных и запись результатов в хранилище или другое место назначения.
Задания разбиваются на этапы. Задание перемещается по этапам последовательно, то есть последующие этапы должны ожидать завершения предыдущих этапов. Этапы содержат группы идентичных задач, которые могут выполняться параллельно на нескольких узлах кластера Spark. Задачи — это наименьшая единица выполнения, осуществляемая в подмножестве данных.
В следующих разделах описаны некоторые визуализации панели мониторинга, которые полезны для устранения проблем производительности.
Задержка задания и этапа
Задержка задания — это длительность выполнения задания с момента запуска до завершения. Она отображается как процентили выполнения задания в кластере с идентификатором приложения, чтобы обеспечить визуализацию выбросов. На следующем графике показан журнал заданий, в котором 90 процентиль достигается за 50 секунд, хотя 50-й процентиль регулярно достигается примерно за 10 секунд.
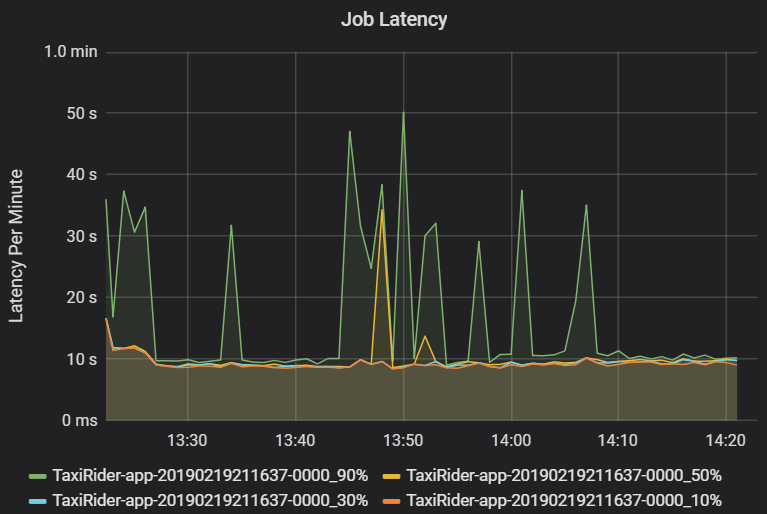
Исследуйте выполнение заданий по кластеру и приложению для поиска пиковых нагрузок в задержке. Определив кластеры и приложения с высокой задержкой, переходите к анализу задержки этапа.
Задержка этапа также отображается в виде процентилей, чтобы обеспечить визуализацию выбросов. Задержка этапа разбивается по имени кластера, приложения и этапа. Определяйте пики в задержке задач на графике, чтобы выяснить, какие задачи оттягивают выполнение этапа.
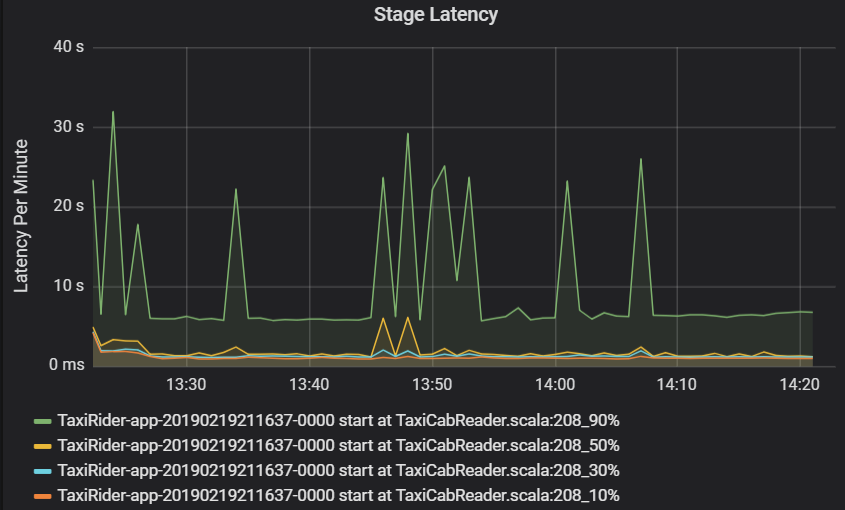
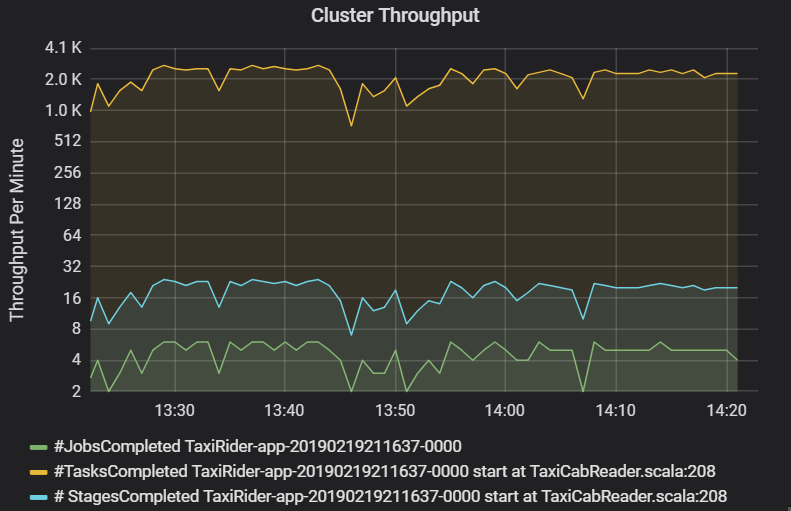
На графике пропускной способности кластера показано количество заданий, этапов и задач, выполненных в минуту. Это помогает понять рабочую нагрузку с точки зрения относительного количества этапов и задач для каждого задания. Здесь можно увидеть, что в минуту выполняется 2–6 заданий и около 12–24 этапов.
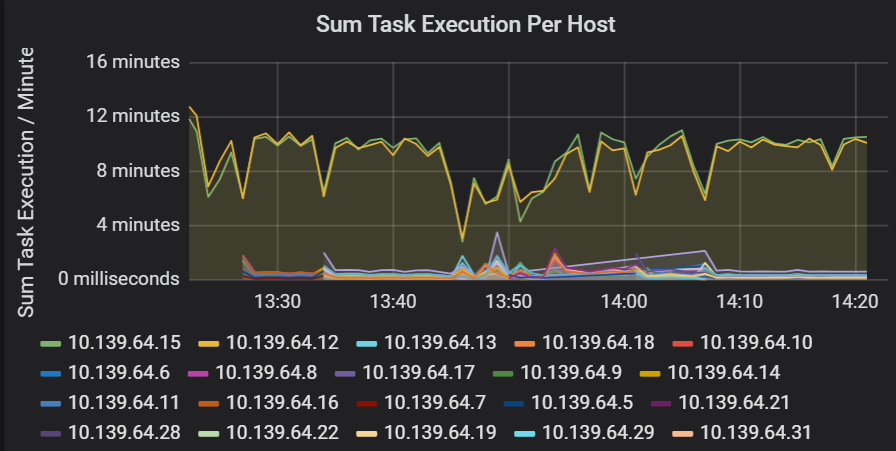
Суммарная задержка времени выполнения задач
Эта визуализация показывает суммарную задержку выполнения задачи на узле, работающем в кластере. Используйте этот граф для обнаружения задач, которые выполняются медленно из-за замедленной работы узла в кластере, или нерационального выделения задач исполнителям. На следующем графике большинство узлов имеют суммарное время выполнения задачи около 30 секунд. Однако у двух узлов суммарное время выполнения задачи составляет порядка 10 минут. Либо узлы работают слишком медленно, либо число задач, выделяемых каждому исполнителю, подобрано неправильно.
Количество задач, выделяемых на исполнителя, показывает, что двум исполнителям назначено непропорциональное число задач, из-за чего возникает узкое место.
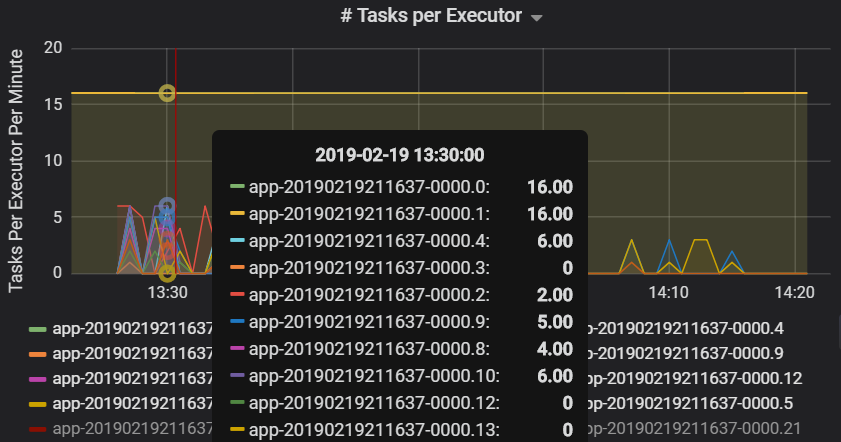
Метрики задач на этап
Визуализация метрик задачи увидеть, из чего состоят затраты на выполнение задачи. Эту функцию можно использовать для просмотра относительного времени, затраченного на выполнение таких задач, как сериализация и десериализация. Эти данные могут подсказать возможности для оптимизации, такие как передача переменных с помощью широковещания, чтобы избежать доставки данных. Метрики задач также показывают размер поступающих в случайном порядке данных для задачи, а также время чтения и записи в случайном порядке. Если эти значения высоки, значит, по сети перемещается большой объем данных.
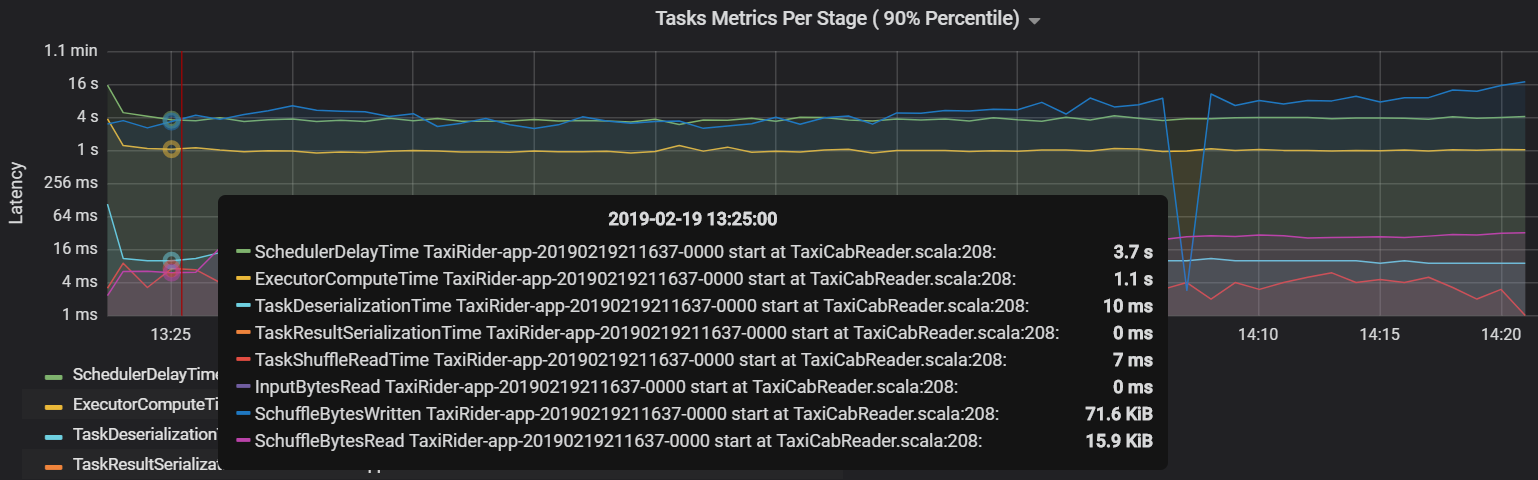
Другая метрика задачи — это задержка планировщика, которая показывает время, затрачиваемое на планирование задачи. В идеале это значение должно быть ниже времени вычислений исполнителя, т. е. времени, фактически затраченного на выполнение задачи.
На следующем графике видно, что время задержки планировщика (3,7 с) превышает время вычислений исполнителя (1,1 с). Это означает, что на ожидание планирования задач тратится больше времени, чем на их выполнение.
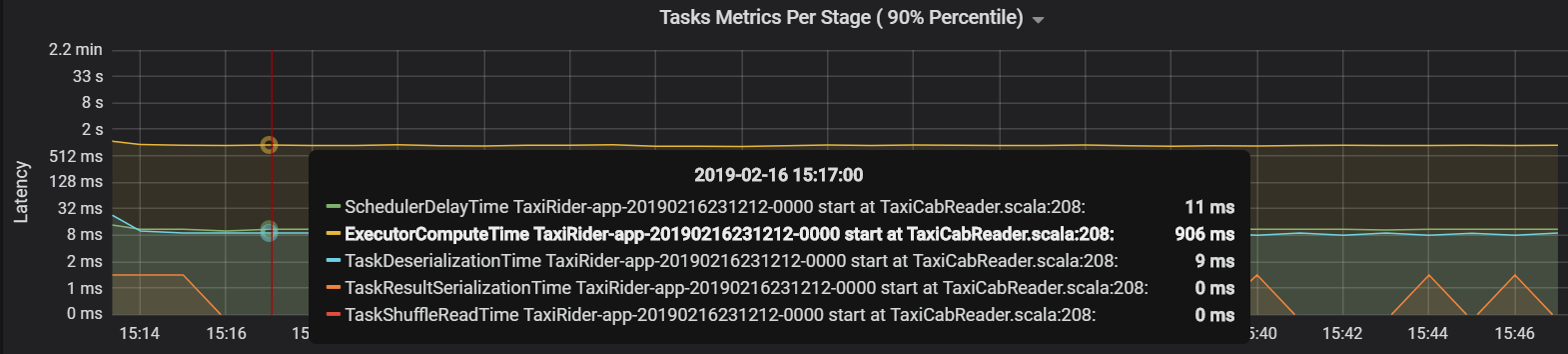
В данном случае причиной проблемы стало обилие секций, что привело к чрезмерной нагрузке. Сокращение количества секций позволило сократить время задержки планировщика. На следующем графике видно, что большая часть времени тратится на выполнение задачи.
Пропускная способность и задержка потоковой передачи
Пропускная способность потоковой передачи напрямую связана со структурированной потоковой передачей. Есть две важные метрики, характеризующие пропускную способностью потоковой передачи: количество входных строк в секунду и количество обработанных строк в секунду. Если количество входных строки в секунду превышает количество обработанных, значит, система обработки потока работает медленнее. Кроме того, если входные данные поступают из Центров событий или Kafka, то количество входных строк в секунду должно соответствовать скорости приема данных на стороне внешнего интерфейса.
У двух заданий может быть одинаковая пропускная способность кластера, но совершенно разные метрики потоковой передачи. На следующем снимке экрана показаны две разные рабочие нагрузки. Они похожи с точки зрения пропускной способности кластера (задания, этапы и количество задач в минуту). Но второе выполнение обрабатывает 12000 строк в секунду, а первое — только 4000 тысячи.
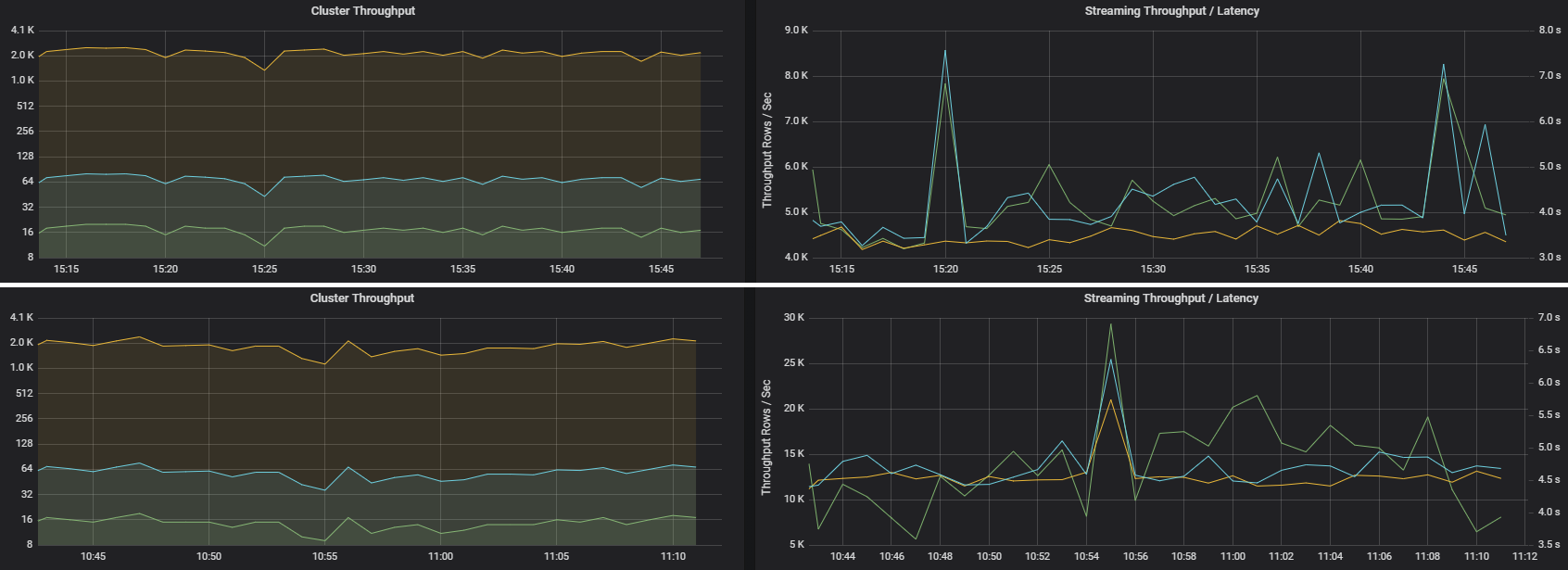
Пропускная способность потоковой передачи часто является лучшей бизнес-метрикой, чем пропускная способность кластера, поскольку она измеряет количество обработанных записей данных.
Потребление ресурсов на исполнителя
Эти метрики помогают понять, какую работу выполняет каждый исполнитель.
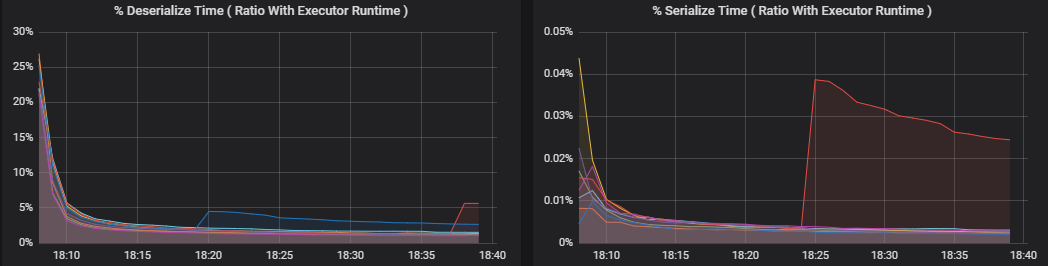
Процентные метрики измеряют время, затрачиваемое исполнителем на различные процессы, выраженное в виде соотношения затраченного времени к общему времени вычислений исполнителя. Эти метрики перечислены ниже.
- Время сериализации (%)
- Время десериализации (%)
- Время использования ЦП исполнителя (%)
- Время использования машины Java (%)
Эти визуализации показывают, насколько каждая из этих метрик влияет на общее время обработки исполнителя.
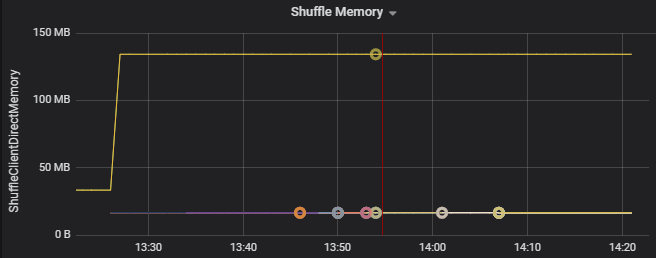
Метрики перетасовки — это метрики, связанные с перетасовыванием данных между исполнителями.
- Ввод-вывод в случайном порядке
- Использование памяти в случайном порядке
- Использование файловой системы
- Использование диска
Распространенные узкие места производительности
Два распространенных узких места производительности в Spark — это отставание задач и неоптимальное количество секций, используемых случайным образом.
Отставание задач
Этапы задания выполняются последовательно, при этом запуск более поздних этапов возможен только после завершения более ранних этапов. Если одна задача выполняет случайно выделенную секцию медленнее, чем это делают другие задачи, все задачи в кластере должны дожидаться окончания медленной задачи. Только после этого этап будет завершен. Это может произойти по следующим причинам:
Узел или группа узлов работают с медленно. Признаки: высокая задержка задачи, этапа или задания и низкая пропускная способность кластера. Суммарная задержка задач на узлах будет распределяться неравномерно. Однако потребление ресурсов будет равномерно распределяться между исполнителями.
Задачам необходимо выполнить ресурсоемкий агрегат (неравномерное распределение данных). Признаки: высокая задержка задач, этапов, заданий или низкая пропускная способность кластера, но сумма задержек на узел распределена равномерно. Потребление ресурсов будет равномерно распределяться между исполнителями.
Если секции имеют неравный размер, то более крупная секция может привести к несбалансированному выполнению задачи (отклонение секций). Признаки: высокое потребление ресурсов исполнителем по сравнению с другими исполнителями, работающими в кластере. Все задачи, осуществляемые этим исполнителем, будут выполняться медленно и задерживать этап выполнения в конвейере. Такие этапы называются барьерными.
Неоптимальное количество секций, используемых случайным образом
Во время структурированного запроса потоковой передачи назначение задачи исполнителю требует от кластера больших затрат ресурсов. Если размер данных в случайном порядке не оптимален, задержка для задачи отрицательно повлияет на пропускную способность и задержку. Если секций слишком мало, то ядра кластера будут недостаточно загружены, что может снизить эффективность обработки. И наоборот, если секций слишком много, придется потратить немало времени на управление небольшим числом задачам.
Используйте метрики потребления ресурсов для устранения неравномерного распределения секций и нерационального выделения исполнителей в кластере. Если секции распределены неравномерно, исполнитель будет потреблять больше ресурсов, чем другие исполнители в кластере.
Например, на приведенном ниже графике видно, что первые два исполнителя используют для перетасовывания в 90 раз больше памяти, чем остальные.
Следующие шаги
- Мониторинг Azure Databricks в рабочей области Azure Log Analytics
- Путь Обучение. Создание решений машинного обучения и управление ими с помощью Azure Databricks
- Документация по Azure Databricks
- Общие сведения о службе Azure Monitor
Связанные ресурсы
- Мониторинг Azure Databricks
- Send Azure Databricks application logs to Azure Monitor (Отправка журналов приложения Azure Databricks в Azure Monitor)
- Use dashboards to visualize Azure Databricks metrics (Визуализация метрик Azure Databricks с помощью панелей мониторинга)
- Современная архитектура аналитики с помощью Azure Databricks
- Прием, ETL (извлечение, преобразование, загрузка) и потоковые конвейеры обработки с помощью Azure Databricks
Обратная связь
Ожидается в ближайшее время: в течение 2024 года мы постепенно откажемся от GitHub Issues как механизма обратной связи для контента и заменим его новой системой обратной связи. Дополнительные сведения см. в разделе https://aka.ms/ContentUserFeedback.
Отправить и просмотреть отзыв по